






1.前言:
Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里是一样的。
2.规划网络:
用一台虚拟机模拟6个节点,一台机器6个节点,创建出3 master、3 salve 环境。虚拟机是 CentOS7 ,ip地址192.168.226.66
3.创建目录节点
首先在 192.168.159.34 机器上 /usr/redis/目录下创建 redis_cluster 目录;
mkdir redis_cluster
![]()
4.创建目录
在 redis_cluster 目录下,创建名为7001、7002,7003、7004、7005,7006的目录
mkdir 7001 7002 7003 7004 7005 7006

5.将 redis.conf 拷贝到这六个目录中,
echo ./7002 ./7003 ./7004 ./7005 ./7006 | xargs -n 1 cp -v /usr/java/redis_cluster/7001/redis.conf
并修改配置文件中的端口号为对应的文件名
代码如下:
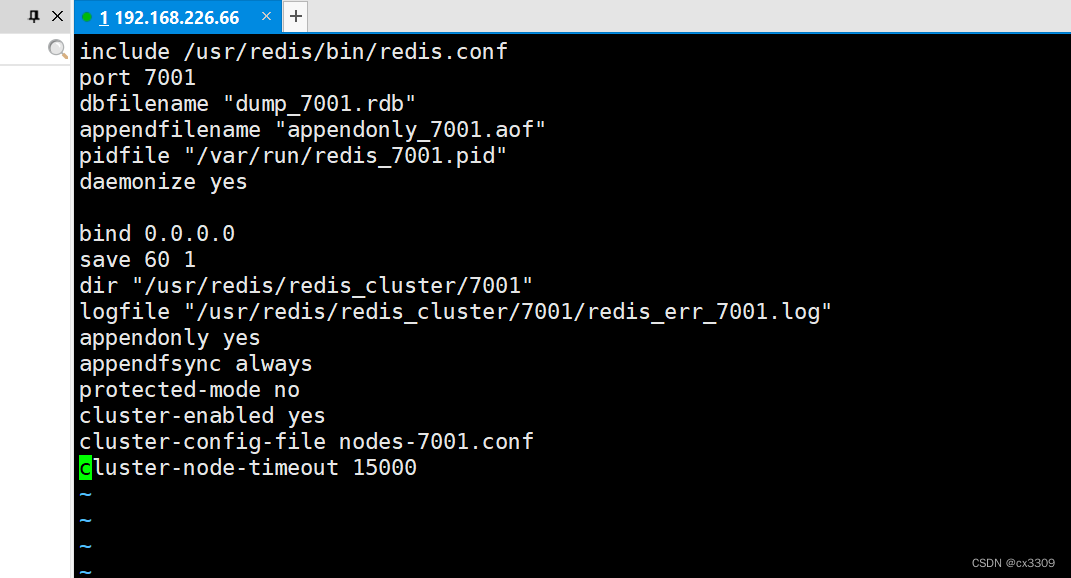
include /usr/redis/bin/redis.conf
port 7002
dbfilename "dump_7002.rdb"
appendfilename "appendonly_7002.aof"
pidfile "/var/run/redis_7002.pid"
daemonize yes
bind 0.0.0.0
save 60 1
dir "/usr/redis/redis_cluster/7002"
logfile "/usr/redis/redis_cluster/7002/redis_err_7002.log"
appendonly yes
appendfsync always
protected-mode no
cluster-enabled yes
cluster-config-file nodes-7002.conf
cluster-node-timeout 15000
另外需要注意的是集群配置一般不要设置密码!!!
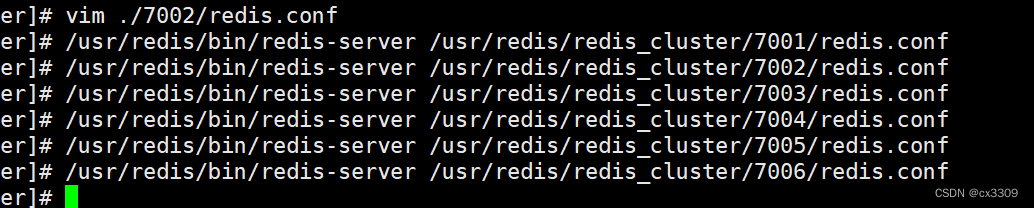
6.启动redis
使用 六个配置文件
代码:/usr/redis/bin/redis-server /usr/redis/redis_cluster/7006/redis.conf

7.创建redis的集群
redis-cli --cluster create 集群节点 --cluster-replicas 1
1代表的是主从的比例是1:1
三主三从
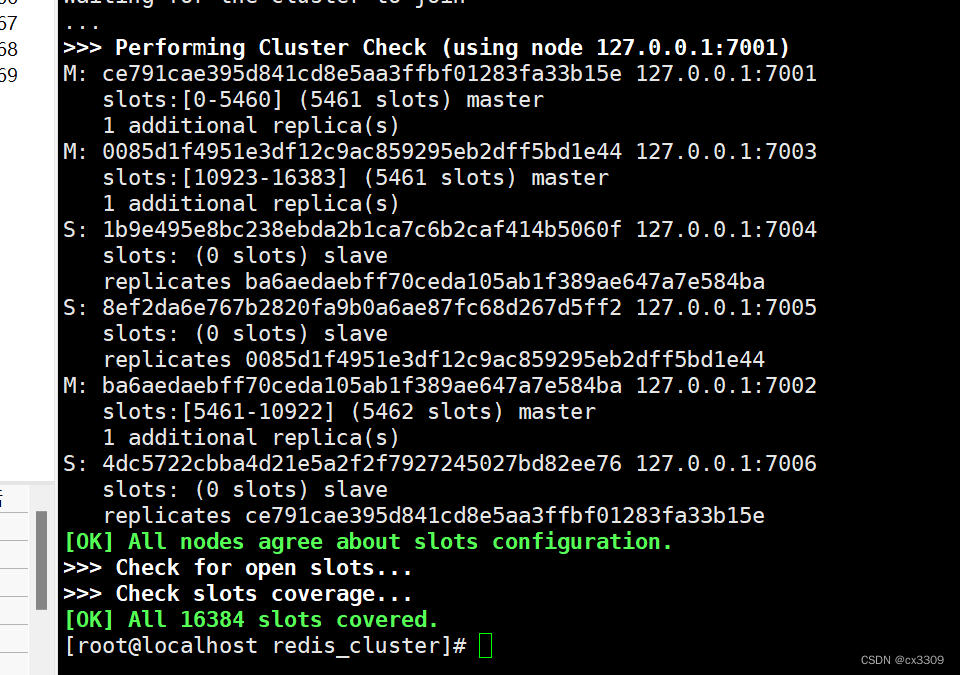
m:主s:从
8.使用cli连接redis集群
redis-cli -c -h 127.0.0.1 -p 7001
查看集群的节点的信息 :cluster nodes
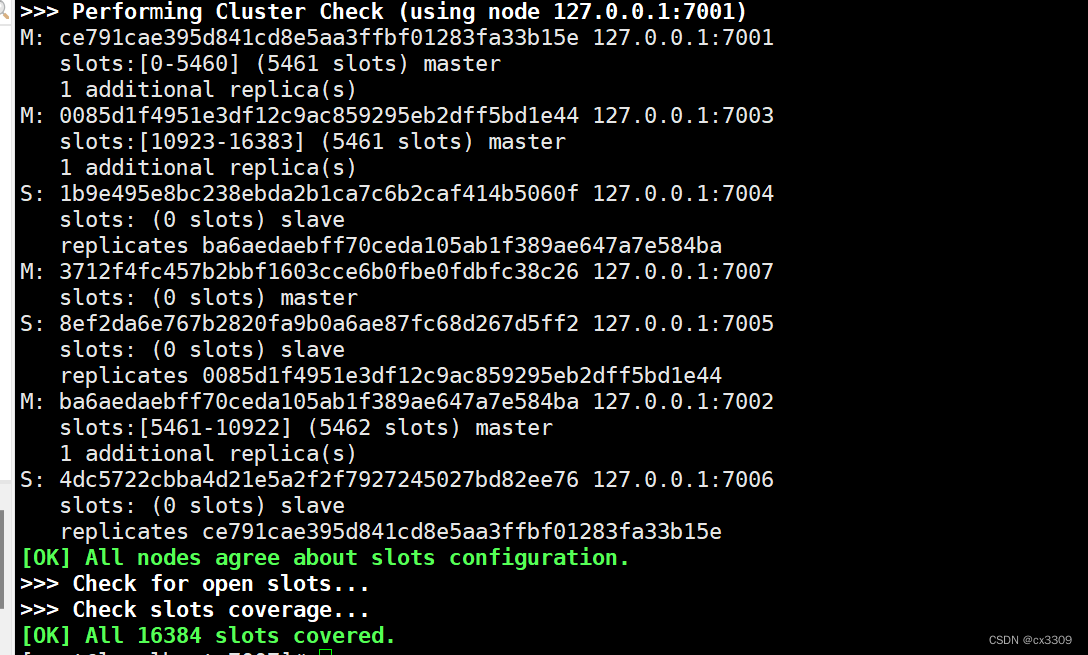
9.检查集群的状态
./redis-cli --cluster check 127.0.0.1:7001
replicates 后面的id是主节点的id
10.配置主节点
1.创建目录

2.复制配置文件

配置操作同上
3.启动节点
redis-cli --cluster add-node 新节点 集群节点
4.添加成功
添加成功后7007 设置成主节点 默认slots=0
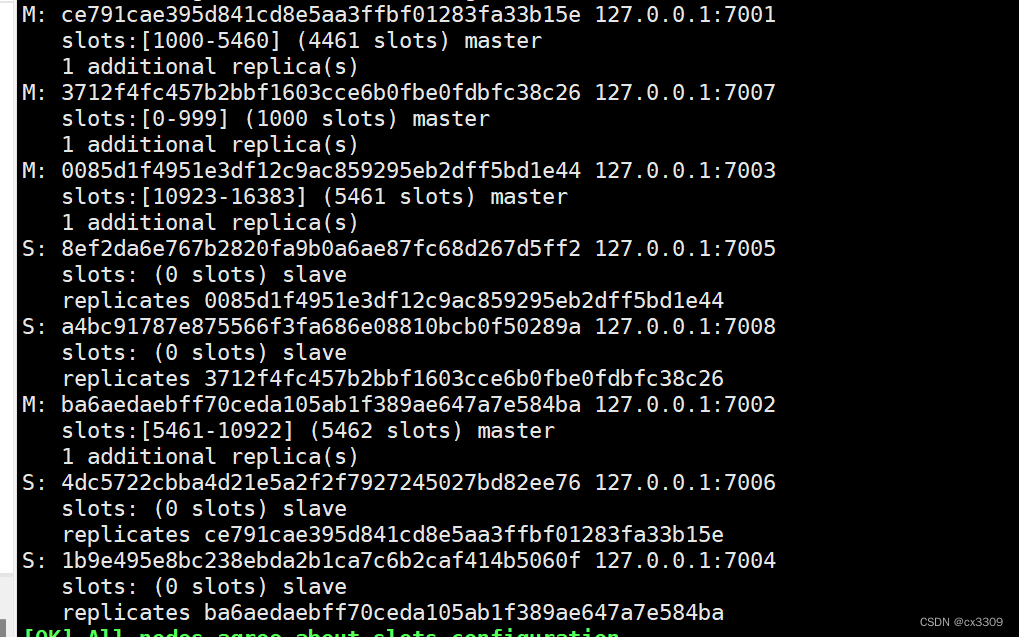
11.slots
1.slots的概念:
slots对于Redis集群而言,就是一个存放数据的地方,就是一个槽。对于每一个Master而言,会存在一个slot的范围,而Slave则没有。在Redis集群中,依然是Master可以读、写,而Slave只读
主节点的写操作在slots中存着。
刚添加的主节点还不能使用,因为没有分配slots
slots数量是一定的共有16384(0-16384)个
不止可以放16384个数据,其处理方式类似于hashmap
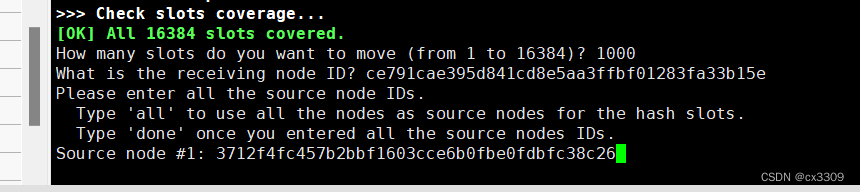
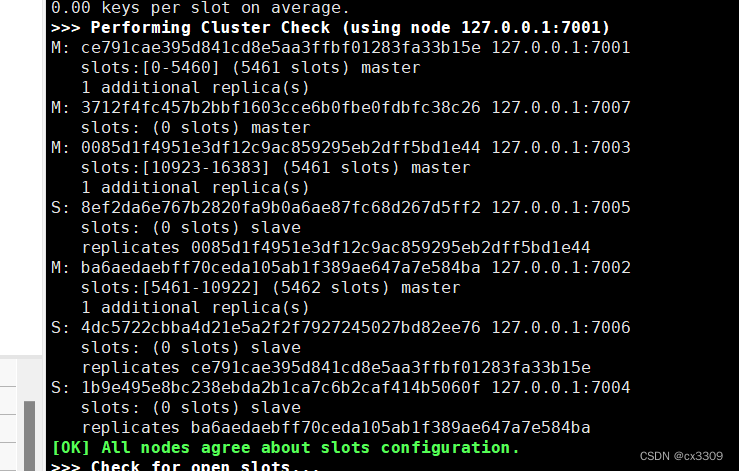
2.重新分配
/usr/redis/bin/redis-cli --cluster reshard 集群节点
拿出来多少slots,这里我选择的是1000
![]()
这里选择的是把拿出来的给谁
![]()
这就是主节点id

这里选择的是从哪个主节点拿

选择all的话会从现有的主节点中各取一点。
12.配置从节点
只有配好slots的主节点才能配从节点
redis-cli --cluster add-node 新节点 集群节点 --cluster-slave --cluster-master-id 主节点的id
操作同上,先创建目录,再复制redis.conf文件,修改redis.conf文件
启动操作同上;
启动成功

添加从节点
/usr/redis/bin/redis-cli --cluster add-node 添加从节点 集群节点 --cluster-slave --cluster-master-id 要添加到哪个主节点的id
添加成功
13.删除节点
/usr/redis/bin/redis-cli --cluster del-node 集群节点 节点id
1.删除从节点

如果主节点还有slots就会报错

需要将slots重新分配出去才能删除
分配
成功
然后就可以删除了

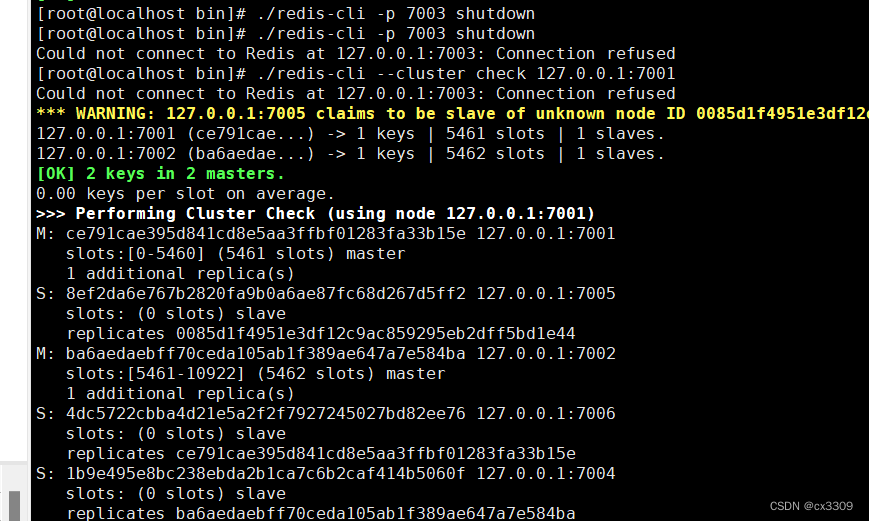
14.关闭集群
重要:集群关闭的时候一定不要用kill,如果kii集群里的信息会被破坏!!!
1.逐个关闭
/usr/redis/bin/redis-cli -p 7001 shutdown
/usr/redis/bin/redis-cli -p 7002 shutdown
......
2.shell脚本关闭
如果集群启动就关闭,如果集群关闭就启动

脚本代码如下:
#!/bin/bash
l=ps -ef|grep -v grep|grep redis|wc -l
k=`find /usr/redis/redis_cluster -name redis.conf`
if [[ l<=3 ]]
then
echo "集群开始启动"
for i in $k
do
/usr/redis/bin/redis-server $i
done
echo "集群启动成功"
elif [[ l>3 ]]
then
echo "集群开始关闭"
for k in $(ps -ef | grep redis-server | grep -v "redis-server 0.0.0.0:6379" | grep -v "grep" | awk '{print $9}' | cut -d ':' -f 2)
do
/usr/redis/bin/redis-cli -h 127.0.0.1 -p $k shutdown
done
echo "集群关闭成功"
fi
15.在集群中录入值
设置值时会计算slot的值来决定放入哪个节点中
取值时也一样会切换到你放数据的那个节点中

不在一个slot下的键值,是不能使用mget,mset等多键操作。因为一组数据可能有多个slot的

可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。(按组分配插槽)

取值也要加{}

整体的可以

16.主节点宕机
主节点宕机
该主节点的从节点变成主节点,且继承主节点的slots

若主节点重启,则变成原来自己子节点的子节点

17.redis集群有点
有一个宕机不影响其他使用
实现扩容
分摊压力
无中心配置 相对简单
18.redis的不足
多键操作不被支持的
多键的redis事务是不被支持的
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
19.redis的应用问题
1.缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
1.问题描述
key对应的数据在数据库并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据库,从而可能压垮数据库。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。

2.解决方案
(1) 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟
(2) 设置可访问的名单(白名单):
使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
(3) 采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
(4) 进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
2.缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
1.问题描述
key对应的数据存在,但在redis中没有过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。

2.解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
解决问题:
(1)预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
(2)实时调整:现场监控哪些数据热门,实时调整key的过期时长
(3)使用锁:
(1) 就是在缓存失效的时候(判断拿出来的值为空),不是立即去加载数据库。
(2) 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
(3) 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
(4) 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。

3.缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
1.问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,击穿则是某一个key正常访问

缓存失效瞬间

2.解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
解决方案:
(1) 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列:
5000 1000
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









