






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
“这个新皮肤的上线时间到底怎么查?”
上周在游戏社群里,小王看着满屏的皮肤爆料贴正发愁。作为王者荣耀的资深玩家,他尝试过手动整理皮肤数据,但官网复杂的交互设计和动态加载机制让这个想法举步维艰。
直到他发现了Python+Selenium这对黄金搭档——通过自动化浏览器操作,像真实玩家一样点击查看每个皮肤详情;利用XPath元素定位,精准提取图片地址和数据信息;最后借助Pandas将数百个皮肤信息整理成结构化数据。
现在,我们将完整复现这个技术探索过程。跟着本文一步步操作,你不仅能获得最新的皮肤图鉴,更重要的是掌握一套破解动态网页的爬虫方法论。
“本文你将收获:✔️Selenium多窗口控制技巧 ✔️XPath高级定位方法 ✔️反爬对抗实战经验”
提示:以下是本篇文章正文内容,下面案例可供参考
一、项目背景
王者荣耀作为现象级手游,其精美的英雄皮肤深受玩家喜爱。本文将使用Python+Selenium+XPath技术,教大家如何自动抓取官网最新皮肤数据并保存到本地,实现一个简单的爬虫实战项目。
二、技术栈
• Selenium:自动化浏览器操作
• XPath:精准定位网页元素
• Pandas:数据存储与导出
• Requests:图片下载
三、环境准备
windows+python+pycharm+chorme
# 安装必要库
pip install selenium pandas requests openpyxl
# 使用镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ 包名
# 下载对应版本ChromeDriver
# https://registry.npmmirror.com/binary.html?path=chrome-for-testing/
四、网页分析
访问王者荣耀皮肤列表页,通过开发者工具分析页面结构:
https://pvp.qq.com/coming/v2/skin-list.shtml
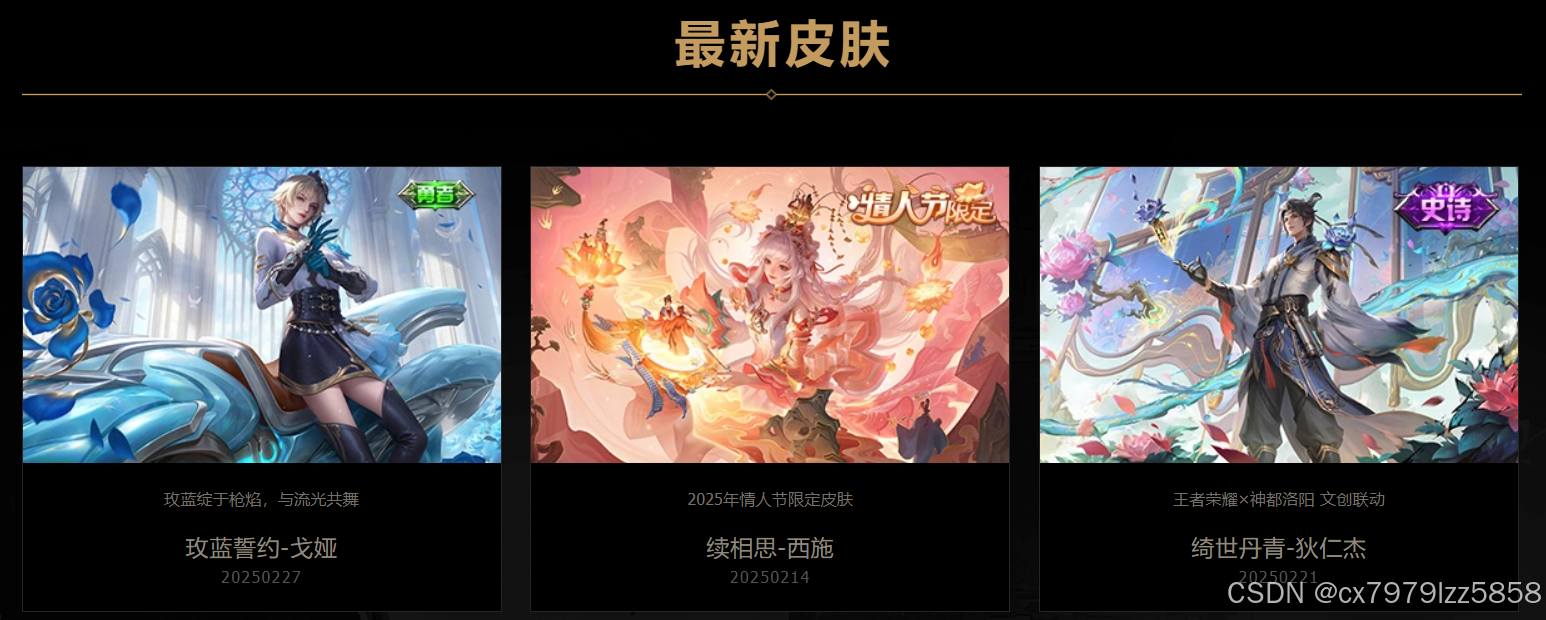
键盘F12或单机鼠标右键选择检查
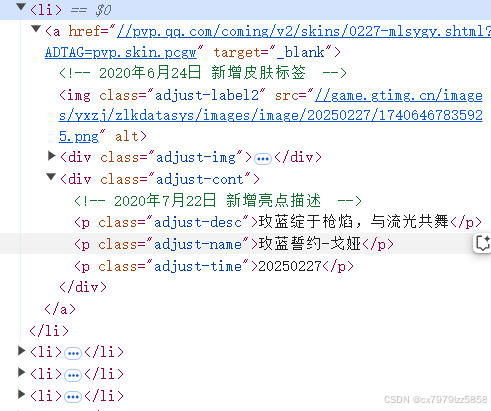
访问王者荣耀每个皮肤详情页,以第一个玫蓝誓约戈娅为例
https://pvp.qq.com/coming/v2/skins/0227-mlsygy.shtml?ADTAG=pvp.skin.pcgw

我们需要获取图片的下载链接和皮肤的品质标签
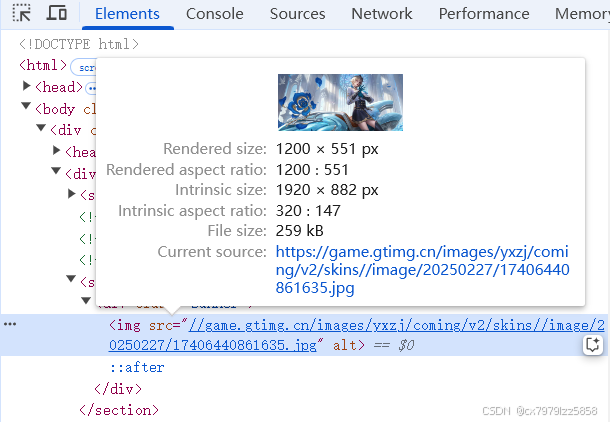
关键元素定位策略:
皮肤时间:/html/body//p[@class=“adjust-time”]
皮肤图片链接:/html/body/div[1]/div/section[2]/div/img
皮肤品质标签图片链接://*[@id=“showSkin”]/div/img
皮肤名称://*[@id=“showSkin”]/div/div[2]/span[1]
英雄名称://*[@id=“showSkin”]/div/div[2]/span[2]
五、代码实现(核心逻辑讲解)
5.1 浏览器初始化
代码如下(示例):
# 配置浏览器选项
options = webdriver.ChromeOptions()
options.add_argument(f'user-agent={random.choice(USER_AGENTS)}')
options.add_experimental_option("detach", True) # 保持浏览器不关闭
# 初始化驱动
driver = webdriver.Chrome(service=service, options=options)
5.2 反爬策略
# 添加随机请求头
USER_AGENTS = [...] # 多个浏览器标识
# 禁用自动化特征
options.add_argument('--disable-blink-features=AutomationControlled')
5.3 数据抓取流程
for i in range(2): # 演示抓取前2个,可改为len(time_elements)
# 定位时间元素并点击
time_element = driver.find_element(By.XPATH, ...)
time_element.click()
# 切换标签页
driver.switch_to.window(driver.window_handles[-1])
# 提取详细信息
img_url = driver.find_element(...).get_attribute('src')
# ...其他元素提取
# 关闭子窗口
driver.close()
driver.switch_to.window(driver.window_handles[0])
5.4 数据存储
# 创建保存目录
os.makedirs("最新皮肤001", exist_ok=True)
# 下载图片
response = requests.get(img_url)
with open(save_path, "wb") as f:
f.write(response.content)
# Excel存储
df = pd.DataFrame(data)
df.to_excel("最新皮肤001.xlsx", index=False)
六、常见问题解决
6.1 元素定位失败
使用相对XPath路径代替绝对路径
添加显式等待:WebDriverWait(driver, 10).until(…)
6.2 反爬检测
定期更新Cookie
使用代理IP池
添加随机操作间隔
6.3 多窗口处理
使用window_handles管理窗口句柄
操作完成后及时关闭无用标签页
七、完整代码
from selenium.webdriver.chrome.service import Service
import random
import pandas as pd
import os
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
service = Service('chromedriver.exe')
options = webdriver.ChromeOptions()
# 可选:为了进一步模拟真实用户行为,可以添加一些其他的配置
options.add_argument('--disable-gpu') # 禁用GPU加速
# 添加伪装请求头,设置用户代理
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101Firefox/91.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
]
options.add_argument(f'user-agent={random.choice(USER_AGENTS)}')
Cookies = [
'__mta=42753434.1633656738499.1634781127005.1634781128998.34; uuid_n_v=v1; _lxsdk_cuid=17c5d879290c8-03443510ba6172-6373267-144000-17c5d879291c8; uuid=60ACEF00317A11ECAAC07D88ABE178B722CFA72214D742A2849B46660B8F79A8; _lxsdk=60ACEF00317A11ECAAC07D88ABE178B722CFA72214D742A2849B46660B8F79A8; _csrf=94b23e138a83e44c117736c59d0901983cb89b75a2c0de2587b8c273d115e639; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1634716251,1634716252,1634719353,1634779997; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1634781129; _lxsdk_s=17ca07b2470-536-b73-84%7C%7C12'
]
options.add_argument(f'cookie={Cookies}')
# 禁用自动化栏
options.add_experimental_option('excludeSwitches',['enable-automation'])
# 反爬虫特征处理
options.add_argument('--disable-blink-features=AutomationControlled')
# 不关闭网页
options.add_experimental_option("detach", True)
# 禁用浏览器正在被自动化程序控制的提示
options.add_argument('--disable-infobars')
# 创建设备对象
driver = webdriver.Chrome(service=service, options=options)
# 打开网址
driver.get('https://pvp.qq.com/coming/v2/skin-list.shtml')
time.sleep(2)
data = []
# name_elements = driver.find_elements(By.XPATH,value='/html/body//p[@class="adjust-name"]')
for i in range (2):
time_elements = driver.find_elements(By.XPATH, value='/html/body//p[@class="adjust-time"]')
for time_element in time_elements:
stime = time_element.text
print(stime)
# for name_element in name_elements:
# name = name_element.text
# print(name)
# 点击元素
time_element.click()
time.sleep(1)
# 切换到新标签页
driver.switch_to.window(driver.window_handles[-1])
time.sleep(1)
img_element = driver.find_element(By.XPATH,value='/html/body/div[1]/div/section[2]/div/img')
img_url = img_element.get_attribute('src')
print(img_url)
grade_element = driver.find_element(By.XPATH,value='//*[@id="showSkin"]/div/img')
grade_url = grade_element.get_attribute('src')
print(grade_url)
name_element = driver.find_element(By.XPATH,value='//*[@id="showSkin"]/div/div[2]/span[1]')
name = name_element.text
print(name)
heroname_element = driver.find_element(By.XPATH,value='//*[@id="showSkin"]/div/div[2]/span[2]')
heroname = heroname_element.text
print(heroname)
# 关闭新标签页
driver.close()
# 切换回初始页面
driver.switch_to.window(driver.window_handles[0])
# 设置图片保存路径
save_path = os.path.join("最新皮肤001",f"{stime}{name}{heroname}.jpg")
# 发送请求下载图片
response = requests.get(img_url)
with open(save_path, "wb") as f:
f.write(response.content)
# 将数据添加到列表中
data.append({
"Time": stime,
"Skin Name": name,
"Hero Name": heroname,
"Skin Grade": grade_url,
"Image Link": img_url # 这里保存的是图片的路径,Excel 中将以链接形式显示
})
# 创建 DataFrame
df = pd.DataFrame(data)
# 保存为 Excel 文件
excel_path = "最新皮肤001.xlsx"
df.to_excel(excel_path, index=False)
注意事项:
- 需定期检查目标网站结构变化
- 遵守网站robots.txt协议
- 控制请求频率避免被封禁
八、效果展示
PyCharm运行结果如下
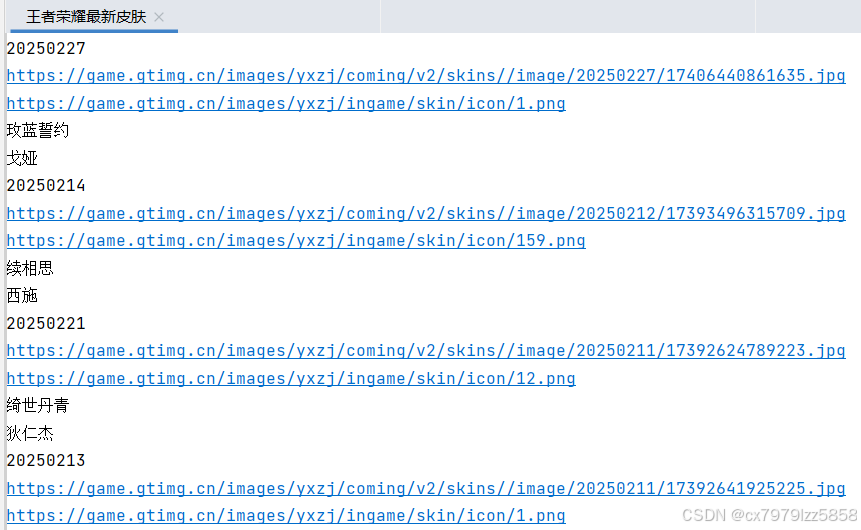
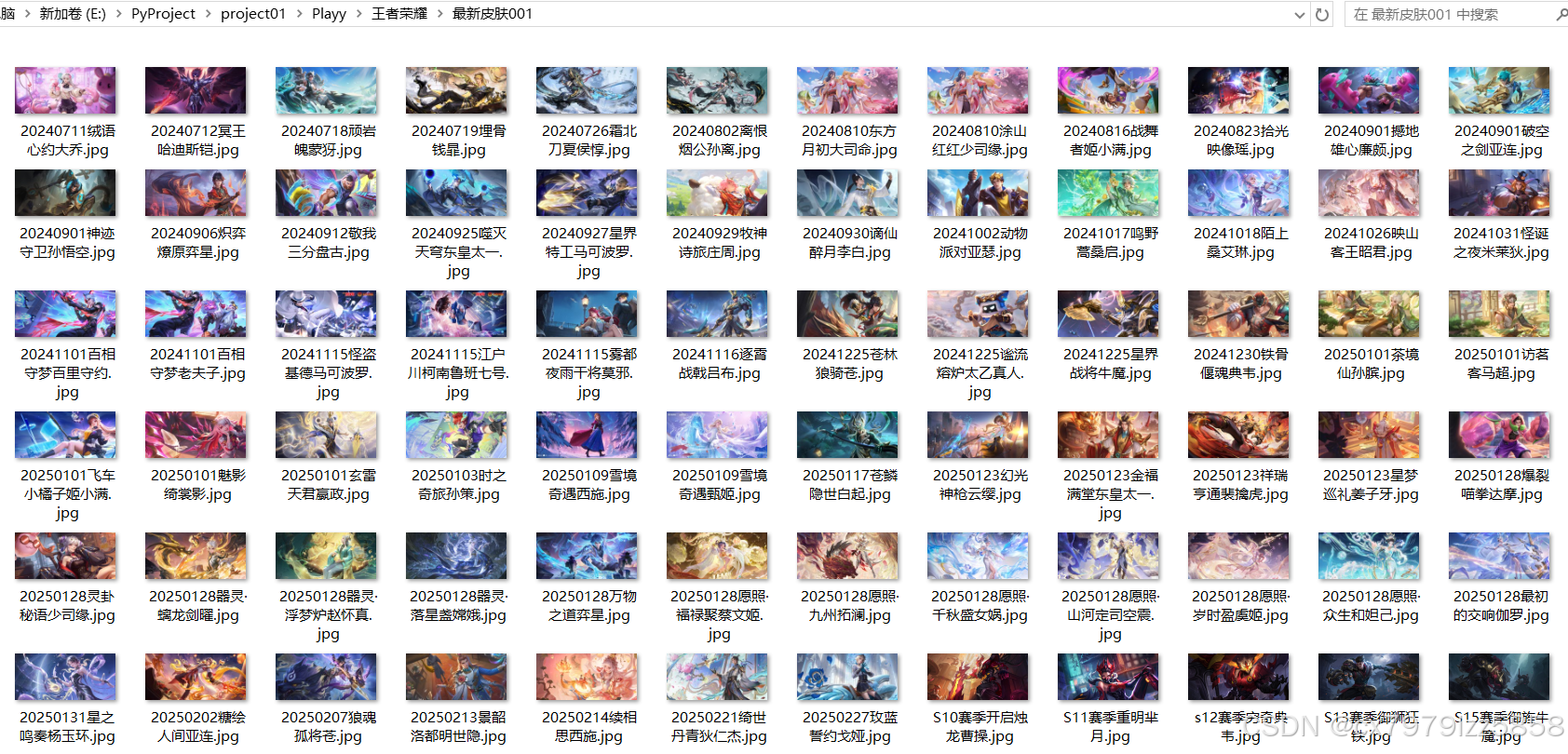
英雄皮肤图片保存到本地:
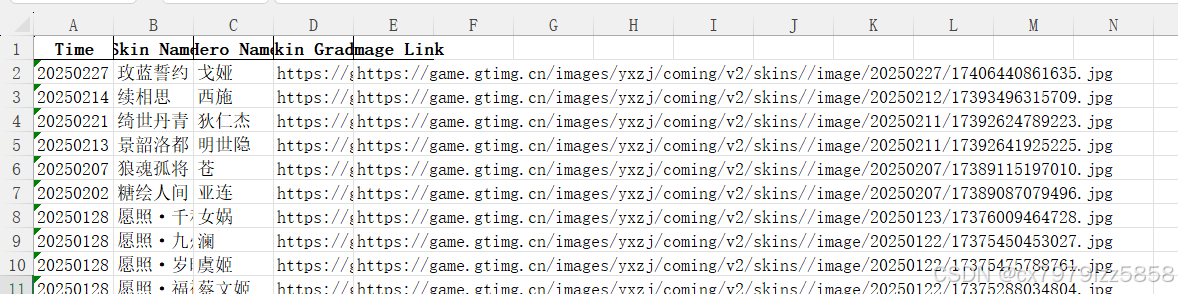
保存到Excel文件:
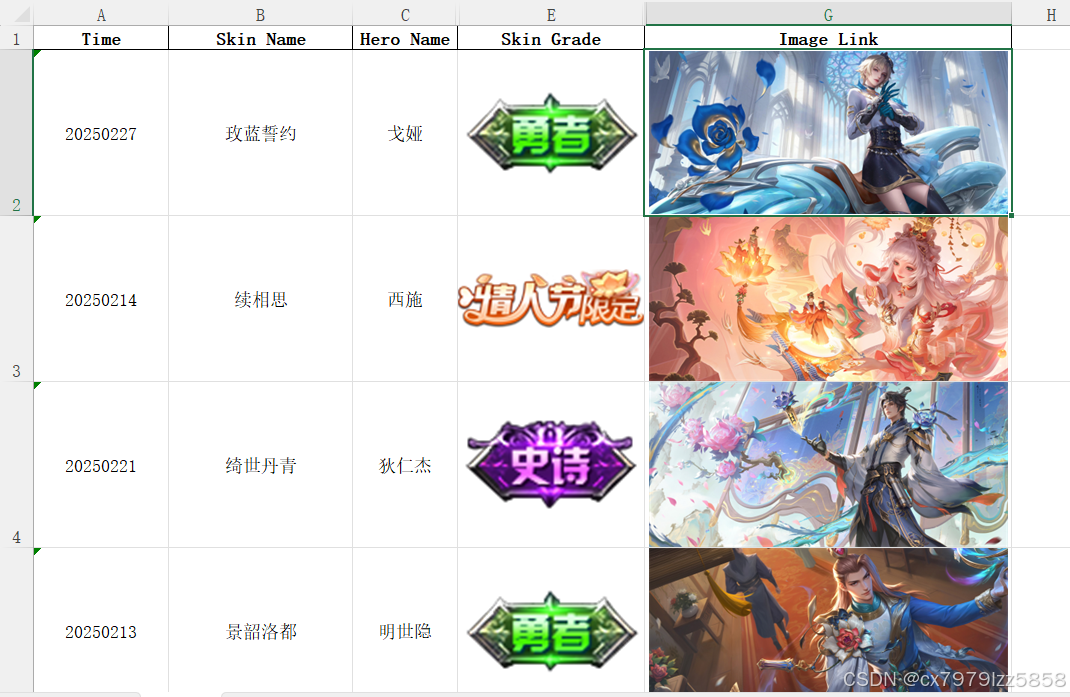
在Excel中将图片链接转换为图片,使用IMAGE()函数
声明:本教程仅用于学习交流,请勿用于商业用途。皮肤数据版权归属腾讯公司所有。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









