





强化学习 视频讲解
您可能已经听说过Google DeepMind的AlphaGo计划,该计划在2015年击败了2个单打的专业Go播放器时吸引了重大新闻。后来,改进的AlphaGo的发展继续击败了9个单盘(最高排名)的专业Go播放器在2016年,并在2017年5月成为世界排名第一的围棋选手。新一代软件AlphaZero在2017年末比AlphaGo强大得多,不仅学习了围棋,而且还学会了象棋和将棋(日式象棋) 。
AlphaGo和AlphaZero都依靠强化学习进行训练。 他们还使用深度神经网络作为强化学习网络的一部分,以预测结果概率。
在本文中,我将解释一些关于强化学习,强化学习的用法以及它在更高层次上的工作方式。 我不会深入研究数学,马尔可夫决策过程或所用算法的细节。 然后,我将回到AlphaGo和AlphaZero。
什么是强化学习?
机器学习分为三种:无监督学习,监督学习和强化学习。 这些都擅长解决不同的问题。
无监督学习可在没有标签的完整数据集上工作,擅长揭示数据中的结构。 它用于群集,降维,特征学习和密度估计等任务。
在完整的标记数据集上工作的监督学习擅长为离散数据创建分类模型,为连续数据创建回归模型。 由监督学习产生的机器学习或神经网络模型通常用于预测,例如回答“该借款人违约的概率是多少?” 或“下个月我们应该库存多少个小部件?”
强化学习训练的演员或代理人回应以最大化某个值的方式的环境 。 用更具体的术语更容易理解。
例如,AlphaGo为了学习玩(动作)围棋(环境)游戏,首先学会了从大量历史游戏数据中模拟人类围棋玩家(徒弟学习)。 然后,通过与自己的独立实例进行大量的围棋游戏,通过反复试验(强化学习)改善了游戏体验。
请注意,AlphaGo不会像dan(黑带)级别的人类玩家那样尝试最大化获胜的规模。 它还不会像新手玩家那样尝试优化即时位置。 AlphaGo将最终获胜的估计概率最大化,以确定其下一步行动。 不管赢得一石还是五十石。
强化学习应用
学习玩围棋,将棋和国际象棋等棋盘游戏并不是应用强化学习的唯一领域。 另外两个领域是玩视频游戏和教导机器人独立执行任务。
2013年,DeepMind发表了一篇有关通过强化学习直接从高维感官输入中学习控制策略的论文 。 应用程序是来自Arcade Learning Environment的七个Atari 2600游戏。 卷积神经网络经过Q-learning(一种用于强化学习训练的常见方法)的变型训练,在六个游戏中都优于以前的所有方法,在三个方法上都超过了人类专家。
卷积神经网络的输入是原始像素,其输出是估计未来收益的价值函数。 基于卷积神经网络的值函数比更常见的线性值函数效果更好。 当输入是图像时,选择卷积神经网络就不足为奇了,因为卷积神经网络旨在模拟视觉皮层。
从那以后,DeepMind将这方面的研究扩展到了实时策略游戏《星际争霸II》。 AlphaStar程序通过与自己对战来学习StarCraft II ,以至于几乎可以击败顶级玩家,至少在Protoss vs Protoss游戏中。 (神族是星际争霸中的外星种族之一。)
机器人控制是用深度强化学习方法(即强化学习和深度神经网络)攻击的另一个问题,其中深度神经网络通常是经过训练以从视频帧中提取特征的卷积神经网络。 但是,使用真实的机器人进行培训非常耗时。 为了减少训练时间,许多研究从模拟开始,然后在物理无人机,机器狗,人形机器人或机械手臂上尝试其算法。
强化学习的工作原理
我们已经讨论过强化学习涉及代理与环境的交互。 环境可能具有许多状态变量 。 代理根据策略执行操作,这可能会更改环境状态。 环境或训练算法可以发送代理奖励或惩罚以实施强化。 这些可以修改构成学习的政策。
作为背景,这是理查德·贝尔曼(Richard Bellman)在1950年代初探索的场景,他开发了动态编程来解决最佳控制和马尔可夫决策过程问题。 动态编程是用于各种应用程序的许多重要算法的核心 ,而Bellman方程在很大程度上是强化学习的一部分。
奖励立即表明有什么好处。 值 ,而另一方面,指定了是从长远来看好。 通常,国家的价值是未来奖励的预期总和。 行动选择(政策)需要根据长期价值而不是直接的回报来计算。
有效的强化学习政策需要平衡贪婪或剥削(追求当前政策认为将具有最高价值的行动),而不是探索 ,随机推动的行动,这可能有助于改善政策。 有很多算法可以控制这种情况,有些算法使用探索时间的一小部分ε,有些算法从纯粹的探索开始,随着学习策略的增强,逐渐收敛到几乎纯洁的贪婪。
有很多用于强化学习的算法,既包括基于模型的算法(例如动态编程),也包括无模型的算法(例如Monte Carlo)。 无模型方法对于实际的强化学习更有用,因为它们是从经验中学习的,并且精确的模型往往很难创建。
如果您想通过强化学习算法和理论进入杂草丛生,并且对Markov决策过程感到满意,我将推荐Richard S. Sutton和Andrew G. Barto撰写的《 强化学习:入门》 。 您需要2018年修订的第二版。
AlphaGo和AlphaZero
我之前提到过,AlphaGo通过对人类围棋游戏数据库进行培训来开始学习围棋。 该引导程序以合理的强度发挥了其基于深度神经网络的价值功能。
对于AlphaGo培训的下一步,它与自己进行了很多对抗,并使用游戏结果更新了其价值和政策网络中的权重。 这使得该计划的实力超越了大多数人类围棋运动员。
在玩游戏的每一步中,AlphaGo都会将其价值函数应用于该位置处的每一合法步,从而根据获胜的可能性对它们进行排名。 然后,它从价值最高的棋局产生的棋盘位置运行蒙特卡罗树搜索算法,并根据这些前瞻搜索选择最有可能获胜的棋局。 它使用获胜概率来加权它对搜索每个移动树的关注程度。
后来的AlphaGo Zero和AlphaZero程序跳过了针对人类游戏数据库的培训。 除了游戏规则和强化学习外,他们一开始就没有包bag。 一开始他们玩的是随机动作,但在从数百万对自己的比赛中学习之后,他们的表现确实不错。 AlphaGo Zero在三天内通过赢得100场比赛达到0胜过AlphaGo Lee的实力,在21天内达到了AlphaGo Master的水平,并在40天内超过了所有旧版本。
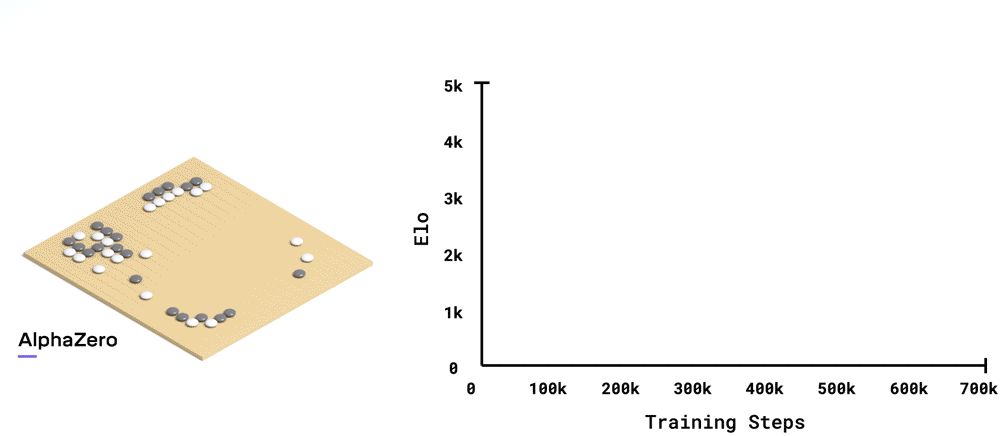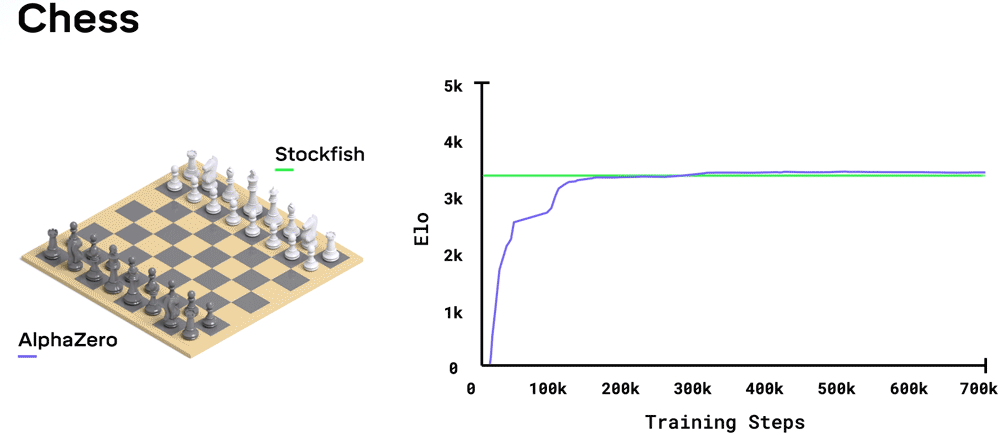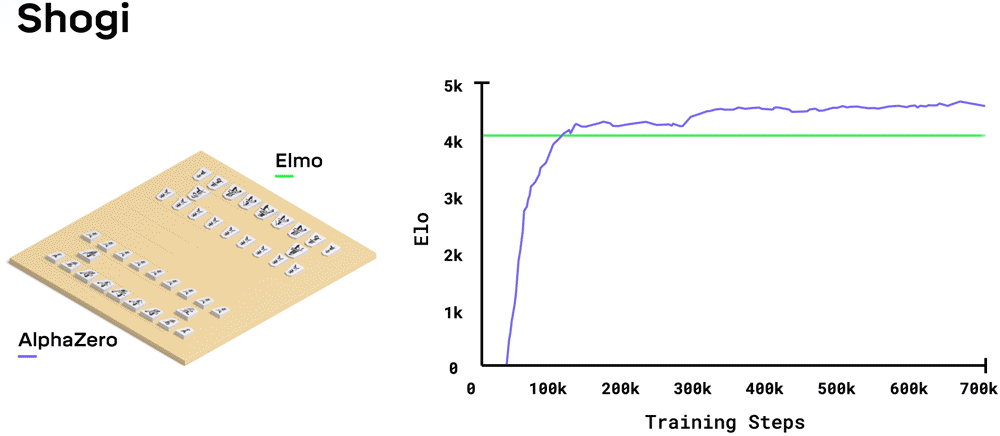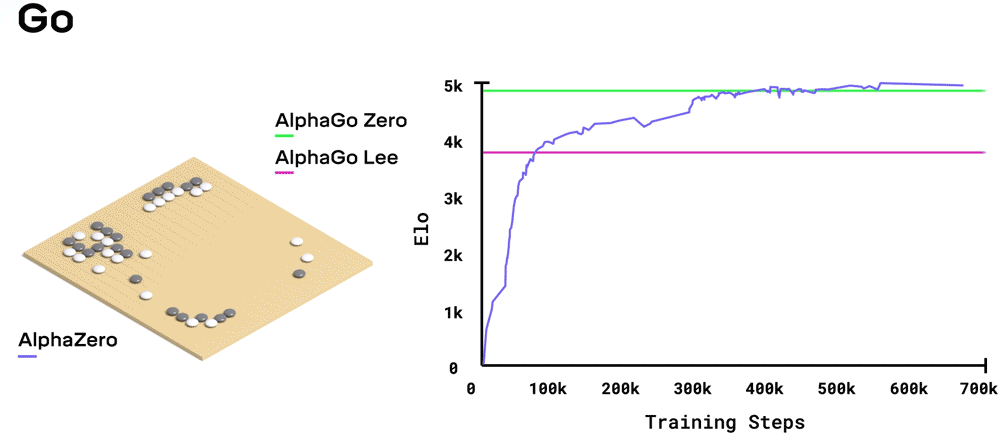
正如我前面提到的,AlphaZero是从AlphaGo Zero推广而来的,用来学习象棋和将棋以及围棋。 根据DeepMind的说法, AlphaZero神经网络所需的强化学习训练的数量取决于游戏的样式和复杂性,在多个TPU上运行,国际象棋大约需要9个小时,将棋需要12个小时,围棋需要13天。 在国际象棋中,AlphaZero的指导比传统的国际象棋程序要好得多,从而减少了搜索所需的树形空间。 对于最强大的手工国际象棋引擎Stockfish,AlphaZero的每个决策只需要评估10,000个动作,而每个决策则可以评估10,000,000个动作。
这些棋盘游戏不容易掌握,而且AlphaZero的成功充分说明了强化学习的功能,神经网络价值和策略功能以及引导性的蒙特卡洛树搜索。 它还说明了研究人员的技能以及TPU的功能。
与玩棋盘游戏或视频游戏相比,机器人控制是一个更难的AI问题。 一旦您必须处理物理世界,意外的事情就会发生。 尽管如此,在演示级别上已经取得了进展,目前最强大的方法似乎涉及到强化学习和深度神经网络。
翻译自: https://www.infoworld.com/article/3400876/reinforcement-learning-explained.html
强化学习 视频讲解















 3649
3649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}