






前言
今天我们讲讲MySQL索引为什么会失效,很多文章和培训机构的教程,都只会告诉你,在什么情况下索引会失效。
在讲之前,还是先把一些什么情况下索引会失效的结论罗列一下,然后大家结合我讲的原理再来体会一下,就会发现那些结论没必要记。
- 没有查询条件,或者查询条件没有建立索引(相当于废话)
- 表的数据量比较大,且查询结果集是原表中的大部分数据,应该是25%以上,这时走不走索引效率都很低。所以这种情况数据库系统不会走索引
- 索引本身失效,统计数据不真实
- 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例如:
mysql> desc select * from city where id-99=1;
- 隐式转换导致索引失效:例如创建表时指定tel列的数据类型为字符串,添加数据’111’,在查找时,select * from test where tel=111;查询条件却是数字,这时系统内部先会通过函数对数字111转换为字符串’111’进行查询,虽然查询的结果都一样,但是因为使用数字111,系统内部使用了函数转换,所以索引失效
- !=,not in 不走索引(辅助索引),但是主键列索引来说” !=,not in“走索引
- like “%aa” 百分号在最前面,索引失效
- 联合索引,没有遵循最佳左前缀法则、范围查询右边失效
好,下面开始装逼!!!

单值索引B树图
单值索引在B树的结构里,一个节点只存一个键值
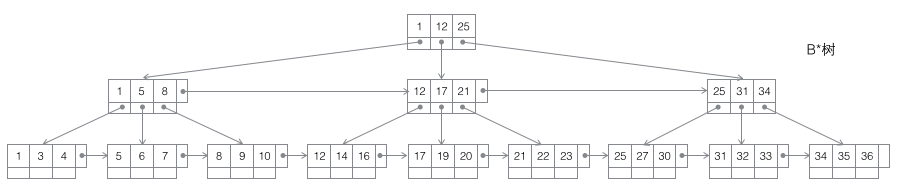
联合索引
开局一张图,由数据库的a字段和b字段(或更多的字段)组成一个联合索引‘

从本质上来说,联合索引也是一个B树,和单列索引不同的是。联合索引的B树种一个节点的键值个数不再是1个,而是大于一个。
a、b字段排序分析
- a顺序:1,1,2,2,3,3 (是上图叶子节点种黄色的数字)
- b顺序:1,2,1,4,1,2 (是上图叶子节点种黑色的数字)
大家可以发现a字段是有序排列的,b字段是无序排列的(因为B*树只能选择一个字段来构建有序的树)。仔细观察又会发现,在a相等的情况下,比如左起的第一个叶子节点和第二个叶子节点,a的值都为1,b字段键值为1的排在了键值为2的前面。这样看,b字段也是有序的。
大家想想平时编程种我们要对两个字段排序,是不是先按照第一个字段进行排序,如果第一个字段出现了相等的情况,就用第二个字段排序。这个排排序方式同样被用到了B*树中。
好,下面对文章开头的那些结论各个击破!!!

- 联合索引中,不遵循最佳左前缀法则会使索引失效
先举一个遵循最佳左前缀法则的例子
db01 [(none)]>select * from testTable where a=1 and b=2;
分析如下:
首先a字段在B*树上使有序的,所以我们可以通过二查找法来定位到a=1的位置,其次在a确定的情况下,b字段的键值使相对有序的。因为有序,所以同样可以通过二分法查找到b=2的位置
再来举一个不遵循最佳左前缀的例子
db01 [(none)]>select * from testTable where b=2;
分析如下:
我们来回想一下b有序的前提:在a确定的情况下
现在a字段都没了,那b字段肯定是不能确定顺序的,在一个无序的B*树上是无法用二分查找来定位b字段的
网友死扛的例子:
使用一张表的k1、k2、k3、k4建立联合索引(k1,k2,k3,k4)
db01 [(none)]>select * from testTable1 where k2='bb' and k3='cc' and k4='dd' and k1='aa';
经过网友explain查看执行计划后,说此SQL语句没有遵循最佳左前缀法则依旧走索引
分析如下:
在数据查询前,优化器会按照建立联合索引时的顺序讲查询条件进行排列。所以即使你写的SQL语句表面上没有遵循最佳左前缀法则,
但是你的SQL语句会在MySQL的SQL层被改写,由于排序后满足最佳左前缀法则,所以此SQL语句走索引。
tip:若是排序后不满足最佳前缀法则,那么不连续部分的索引就会失效。
如排序后为(k1、k3、k4),那么k3、k4两个字段的索引就会失效。针对这种情况,可以将k1、k3、k4三个字段重新建立索引,这样就可以满足最佳前缀法则,三个字段都会走索引
- 联合索引中,范围查询右边失效原理(针对查询条件中出现">"、"<"、">="、"<="的情况)
举例:
db01 [(none)]>select * from testTable where a>1 and b=2;
分析如下:
首先a字段在B*树上是有序的,所以可以用二分查找法定位到1,然后将所有大于1的数据取出来,a可以用到索引。
b有序的前提是a字段的键值的确定值,那么现在a字段的值是取大于1的,a字段可能有10个大于1的键值,也有可能有100个。
在B*树中a字段键值大于1的那部分,b字段是无序的(a>1是,b字段的顺序为1、4、1、2),所以b字段在B*树中无法用二分查找法来查询,所以b字段用不到索引
优化方法:
1.将需要> < >= <= like 这种情况的查询列放在联合索引的最后面;
2.将需要> < >= <= like 这种情况的查询条件放最后面。
tip:
若是和已有的联合索引有冲突,例如,系统还是走老的联合索引,可以根据使用频率来考虑是否删除一些联合索引。
show index from 表名; 来查看表中的哪些列属于哪些联合索引。
- like索引失效原理
举例:
where name like "a%"
where name like "%a%"
where name like "%a"
我们先来了解一下%的用途:
-%放在右边,叫前缀,代表查询以"a"开头的数据,如:abc
-两个%%,叫中缀,代表查询数据中包含"a"的数据,如:cab、cba、abc
-%放在左边,叫后缀,代表查询以"a"结尾的数据,如:cba
为什么%放在右边有时能用到索引:
没错,这里依然是最佳左前缀法则的概念。和开局一张图一样,B*树存储字符串也是按照首字母的大小进行排序的,第一个字母相同就按照第二个字母的大小排序,然后依次类推。
开始分析:
%放在右边--->由于B*树存储字符串也是按照首字母的大小进行排序的,前缀匹配又是匹配首字母,所以可以在B*树上进行有序的查找,所以可以用到索引
%放在左边--->是匹配字符串尾部的数据,我们上面说了排序规则,单独的尾部数据是没有顺序的,所以也就不能走索引a
- !=,not in 不走索引(辅助索引),但是主键列索引来说” !=,not in“走索引
建立辅助索引的列,不能保证其键值的唯一性,所以查询不等的键值,需要全表扫面以确定查询数据的精确性
主键列的值是唯一的,通过B*树的排列也是顺序的,所以只要二分查找到不等的键值,就完成了查询
总结
细说了几个不好理解的结论,其余的简单结论大家自己看看就明白了,我这里也不再赘述了。
好了,来到了本篇博客的重点部分了:
参考文章:https://www.zhihu.com/question/421944348















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









