





nosql数据库做数据备份
在过去的十年中, 分布式数据库已经变得有趣和有吸引力,因为在全球开展业务的公司需要具有水平可扩展性和全球覆盖范围的事务数据库。 但是,地理分布和低事务延迟之间存在着本质上的张力:光速限制了远程节点之间的传输时间。
 信息世界
信息世界
为了在写入事务中实现高吞吐量,许多NoSQL数据库都通过禁止跨分区事务或将其一致性保证从强(同步事务)降为最终(异步事务)来削弱了对事务的支持。 大多数数据库对事务使用两阶段提交方案,当节点的地理分布时,这会增加事务等待时间。 但是,许多最近的分布式数据库都将Paxos或Raft方案用于基于仲裁的事务共识,这降低了事务等待时间。
[ 同样在InfoWorld上:最好的NoSQL数据库 | 最好的分布式关系数据库 | 最好的图形数据库
FaunaDB是一个分布式的,高度一致的OLTP NoSQL数据库,它符合ACID并提供了多模型接口。 它具有主动-主动式体系结构,可以跨越云以及大陆。 FaunaDB通过单个查询支持文档,关系,图形和时间数据集。 除了其自己的FQL查询语言外,该产品还支持GraphQL,并计划在将来使用SQL。
FaunaDB是第一个使用Calvin跨分片事务处理协议的数据库,该协议允许单阶段提交而无需依赖时钟且不会丢失一致性。 FaunaDB还将Raft共识系统用于单个分片。 在讨论FaunaDB体系结构时,我们将更详细地解释这些内容。
在全球分布的NoSQL数据库领域,FaunaDB的竞争包括Azure Cosmos DB ,Amazon DocumentDB,Amazon DynamoDB和YugaByte DB 。 Google Cloud Spanner和CockroachDB是其全球分布的关系数据库竞争对手。
FaunaDB架构
FaunaDB声称在每一层都有架构创新。 最大的创新可能是使用Calvin作为分布式交易协议,而不是Google Spanner或更旧的Google Percolator协议。
卡尔文最初是由Abadi等人在2012年的一篇论文中描述的。 耶鲁大学:
卡尔文(Calvin)是一个实用的事务调度和数据复制层,它使用确定性排序保证来显着降低与分布式事务相关的通常令人望而却步的竞争成本。 与以前的确定性数据库系统原型不同,Calvin支持基于磁盘的存储,在商用机器集群上几乎线性地扩展,并且没有单点故障。 通过复制事务输入而不是效果,Calvin还能够支持多个一致性级别,包括跨地理位置遥远的副本的基于Paxos的强一致性,而不会增加事务吞吐量。
换句话说,使用Calvin进行分布式事务处理,即使在没有时钟同步的全局分布式集群中,也可以给FaunaDB单阶段提交和保证严格的可序列化性的选项。 除此之外,FaunaDB可以实现低写入延迟(平均不到200毫秒)和99.99%的正常运行时间。 Fauna表示:“ Calvin的使用还使FaunaDB可以实现无主控架构。 利用集群中的副本,在地理位置上分布在许多位置,FaunaDB提供了主动-主动事务,使应用程序可以在全球范围内横向扩展,而无需一行代码。
FaunaDB实现了半结构化,无模式,对象关系数据模型,该模型是关系,文档,面向对象和图范式的超集。 数据模型允许执行约束,创建索引以及跨多个文档实体进行联接。 它还提供了由多种不同编程语言的驱动程序介导的多语言API。 简而言之,FaunaDB数据模型允许您以统一的方式处理数据库。
[ InfoWorld上的NoSQL数据库评论: Azure Cosmos DB , Couchbase Server , DataStax Enterprise , MongoDB , YugaByte DB ]
相比之下,Azure Cosmos DB实现了单独的关系,文档和图形层,每个层都有自己的查询语言和API。 类似地,YugaByte DB实现了单独的关系,宽列和键值插件。
FaunaDB使用令牌提供管理和应用程序级别的身份和安全性。 您可以通过API服务器或直接从移动设备,浏览器和嵌入式应用程序安全地访问数据库。
FaunaDB经过了广泛的Jepson测试,并修复了测试期间出现的大约19个问题后,获得了飞跃的效果。 Jepson “致力于提高分布式数据库,队列,共识系统等的安全性。” 关于FaunaDB的Jepson报告中的其中一项陈述总结了数据库的事务架构:
FaunaDB基于对交易系统的同行评审研究,将Calvin的跨分片交易协议与Raft的针对单个分片的共识系统相结合。 我们认为FaunaDB的方法从根本上来说是合理的...基于Calvin的系统如FaunaDB可能在分布式数据库领域中扮演重要的未来角色。
 IDG
IDG
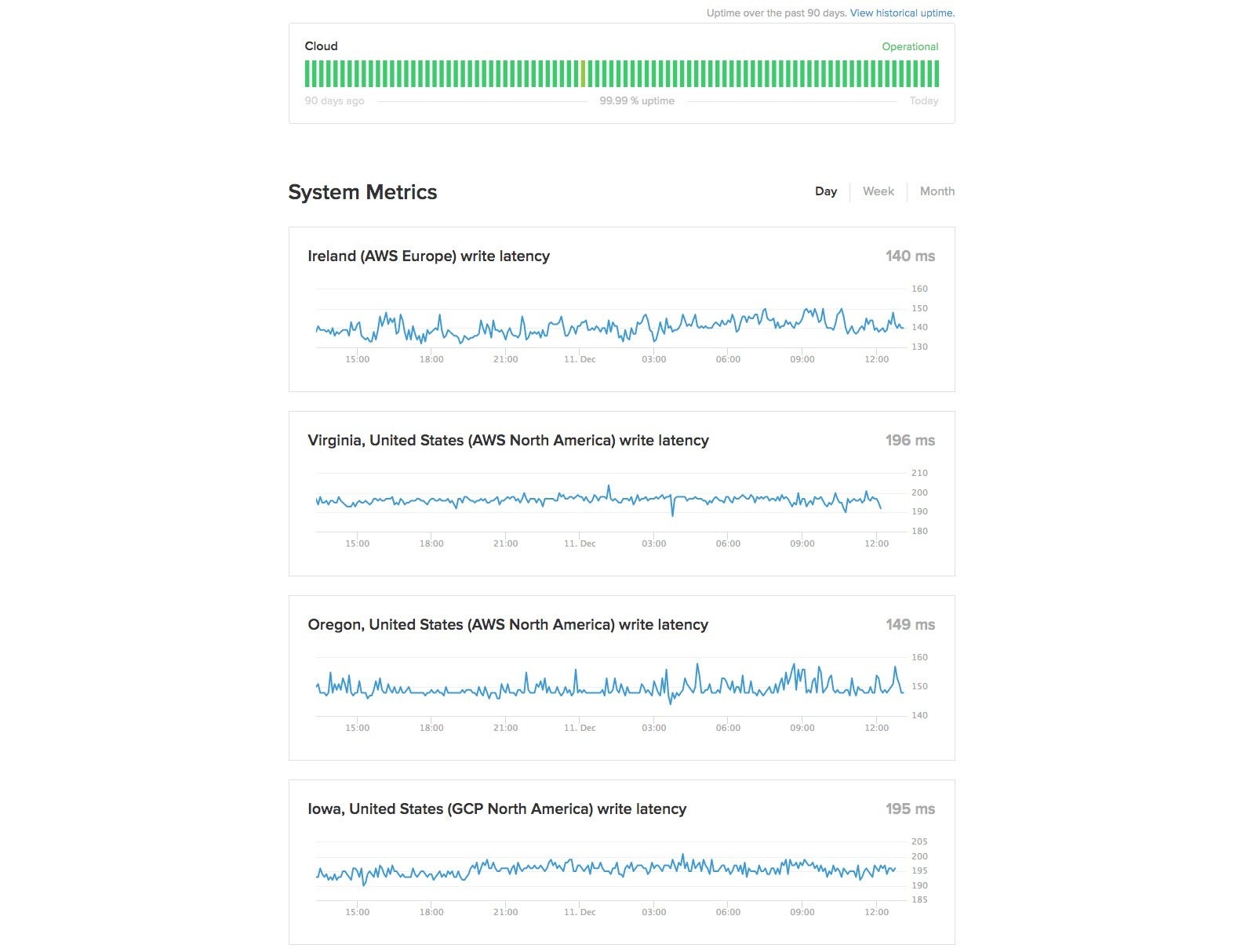
FaunaDB的公共云状态为一天。 有三个亚马逊地区(东海岸,西海岸和欧洲)和一个Google地区(中西部)。 这反映了云群集上的所有活动,而不仅仅是我的活动。
FaunaDB查询语言和驱动程序
FaunaDB当前支持两种查询语言,即它自己的FQL和开源GraphQL 。 FQL的功能更强大,但GraphQL由于在Facebook,GitHub和其他知名科技公司中的使用而具有更大的吸引力。
测试针对FaunaDB的查询的最简单方法是使用FaunaDB Shell或FaunaDB Web控制台 。 您将在下面的“快速入门”部分中看到它们都在起作用。
FQL (动物查询语言)是一种面向表达式的语言,具有功能编程语言的某些特征。 FQL主要在FaunaDB提供的架构类型上运行,其中包括文档,集合,索引,集合和数据库。 如果将FQL概念与SQL概念进行比较 ,则FaunaDB文档对应于关系行,集合对应于表,数据库对应于模式,FaunaDB索引对应于SQL索引和实例化视图。 FaunaDB集是已排序的元组组。
以下是FQL查询的示例,该查询使用Map函数在集合“帖子”中创建多个博客帖子,该函数将Lambda函数串行应用于数组的每个成员。
Map(
[
"My cat and other marvels",
"Pondering during a commute",
"Deep meanings in a latte"
],
Lambda("post_title",
Create(
Collection("posts"), { data: { title: Var("post_title") } }
)
)
)GraphQL是一种开源数据查询和操作语言,它提供声明性架构定义和可组合的查询语法。 以下是针对有关《星球大战》电影的数据库进行GraphQL查询的示例。
 IDG
IDG
左边是一个示例GraphQL查询,右边是返回数据的开头。 请注意,数据具有与查询相同的形状。
FQL可通过9种编程语言的驱动程序获得。 每个驱动程序都可以在其语言的标准库导入界面中作为导入使用。 例如,JavaScript驱动程序作为NPM软件包提供,并通过var fdb = require('faunadb')导入。
所有的语言驱动程序都是开源的 。 Android,Scala和Java绑定共享一个通用的JVM驱动程序。
 IDG
IDG
FaunaDB当前具有9种受支持的编程语言特定的驱动程序。 它们适用于Android,C#,Go,Java,JavaScript,Python,Ruby,Scala和Swift。
FaunaDB用例
Fauna已为实时消费者应用程序,金融服务,游戏开发以及零售和电子商务创建了白皮书 。 在2018年的技术白皮书中,Fauna根据客户的使用情况描述了成功的FaunaDB应用程序模式。 作为分布式应用程序后端; 用于具有多租户和QoS的SaaS; 整合传统的孤岛; 合并应用程序; 在全球范围内分发数据; 统一内部部署和云数据; 并管理跨工作负载对共享数据的访问。
[ InfoWorld上SQL数据库评论: Azure Cosmos DB , CockroachDB , Google Cloud Spanner和YugaByte DB ]
FaunaDB的另一个常见用例是作为JAMstack应用程序的存储层。 JAMstack是一种现代架构,避免使用Web服务器来支持JavaScript,API和标记。 JAMStack应用程序经常使用Netlify (一个用于自动化现代Web项目的多合一平台), React (用于构建用户界面JavaScript库), Gatsby (发出React.js的网站生成器), Jekyll (一个基于Ruby的网站)生成器(以Markdown文档开头), Hugo (基于Go的快速站点生成器)或Nuxt (生成Vue.js的站点生成器)。
FQL快速入门
FQL快速入门可以在本地Fauna命令行外壳程序或FaunaDB控制台中的Web Shell中运行。
 IDG
IDG
FaunaDB Web Shell具有与可下载的Fauna命令行Shell基本相同的功能。 选择数据库后,即可在控制台中找到外壳程序。
我在Mac终端中进行了FQL快速入门。 为了清楚起见,我添加了一些本教程中未显示的探索性命令。 我还解决了文档中一两个明显的小遗漏,例如使用了会话中的实际帖子ID而不是文档中的ID。
martinheller@Martins-Retina-MacBook ~ %fauna help
faunadb shell
VERSION
fauna-shell/0.9.8 darwin-x64 node-v12.6.0
USAGE
$ fauna [COMMAND]
COMMANDS
add-endpoint
autocomplete display autocomplete installation instructions
cloud-login
create-database
create-key
default-endpoint
delete-database
delete-endpoint
delete-key
eval
help display help for fauna
list-databases
list-endpoints
list-keys
run-queries
shell
martinheller@Martins-Retina-MacBook ~ % fauna list-databases
listing databases
my_app
main_ledger
martinheller@Martins-Retina-MacBook ~ % fauna create-database my_db
creating database my_db
created database 'my_db'
To start a shell with your new database, run:
fauna shell 'my_db'
Or, to create an application key for your database, run:
fauna create-key 'my_db'
martinheller@Martins-Retina-MacBook ~ % fauna shell 'my_db'
Starting shell for database my_db
Connected to https://db.fauna.com
Type Ctrl+D or .exit to exit the shell
my_db> CreateCollection({ name: "posts" })
{
ref: Collection("posts"),
ts: 1573056452245000,
history_days: 30,
name: 'posts'
}
my_db> CreateIndex({
... name: "posts_by_title",
... source: Collection("posts"),
... terms: [{ field: ["data", "title"] }]
... })
{
ref: Index("posts_by_title"),
ts: 1573056468580000,
active: true,
serialized: true,
name: 'posts_by_title',
source: Collection("posts"),
terms: [ { field: [ 'data', 'title' ] } ],
partitions: 1
}
my_db> Create(
... Collection("posts"),
... { data: { title: "What I had for breakfast .." } }
... )
{
ref: Ref(Collection("posts"), "248300322187903506"),
ts: 1573056490060000,
data: { title: 'What I had for breakfast ..' }
}
my_db> Map(
... [
... "My cat and other marvels",
... "Pondering during a commute",
... "Deep meanings in a latte"
... ],
... Lambda("post_title",
..... Create(
....... Collection("posts"), { data: { title: Var("post_title") } }
....... )
..... )
... )
[
{
ref: Ref(Collection("posts"), "248300337888232978"),
ts: 1573056505030000,
data: { title: 'My cat and other marvels' }
},
{
ref: Ref(Collection("posts"), "248300337888234002"),
ts: 1573056505030000,
data: { title: 'Pondering during a commute' }
},
{
ref: Ref(Collection("posts"), "248300337888231954"),
ts: 1573056505030000,
data: { title: 'Deep meanings in a latte' }
}
]
my_db> Get( Ref(Collection("posts"), "248300322187903506"))
{
ref: Ref(Collection("posts"), "248300322187903506"),
ts: 1573056490060000,
data: { title: 'What I had for breakfast ..' }
}
my_db> Get( Ref(Collection("posts"), "248300337888231954"))
{
ref: Ref(Collection("posts"), "248300337888231954"),
ts: 1573056505030000,
data: { title: 'Deep meanings in a latte' }
}
my_db> Get(
... Match(
..... Index("posts_by_title"),
..... "My cat and other marvels"
..... )
... )
{
ref: Ref(Collection("posts"), "248300337888232978"),
ts: 1573056505030000,
data: { title: 'My cat and other marvels' }
}
my_db>GraphQL快速入门
我在控制台中在线完成了GraphQL快速入门。 我不认为Fauna为其命令行客户端添加了GraphQL功能,并且我看不出有任何理由使用第三方GraphQL客户端应用程序。
快速入门的GraphQL应用程序是一个简单的待办事项。 模式如下。 您需要创建此文件或将其下载到计算机以进行下一步。
type Todo {
title: String!
completed: Boolean
}
type Query {
allTodos: [Todo!]
todosByCompletedFlag(completed: Boolean!): [Todo!]
}您可以在顶层仪表板的FaunaDB控制台中启动该教程。
 IDG
IDG
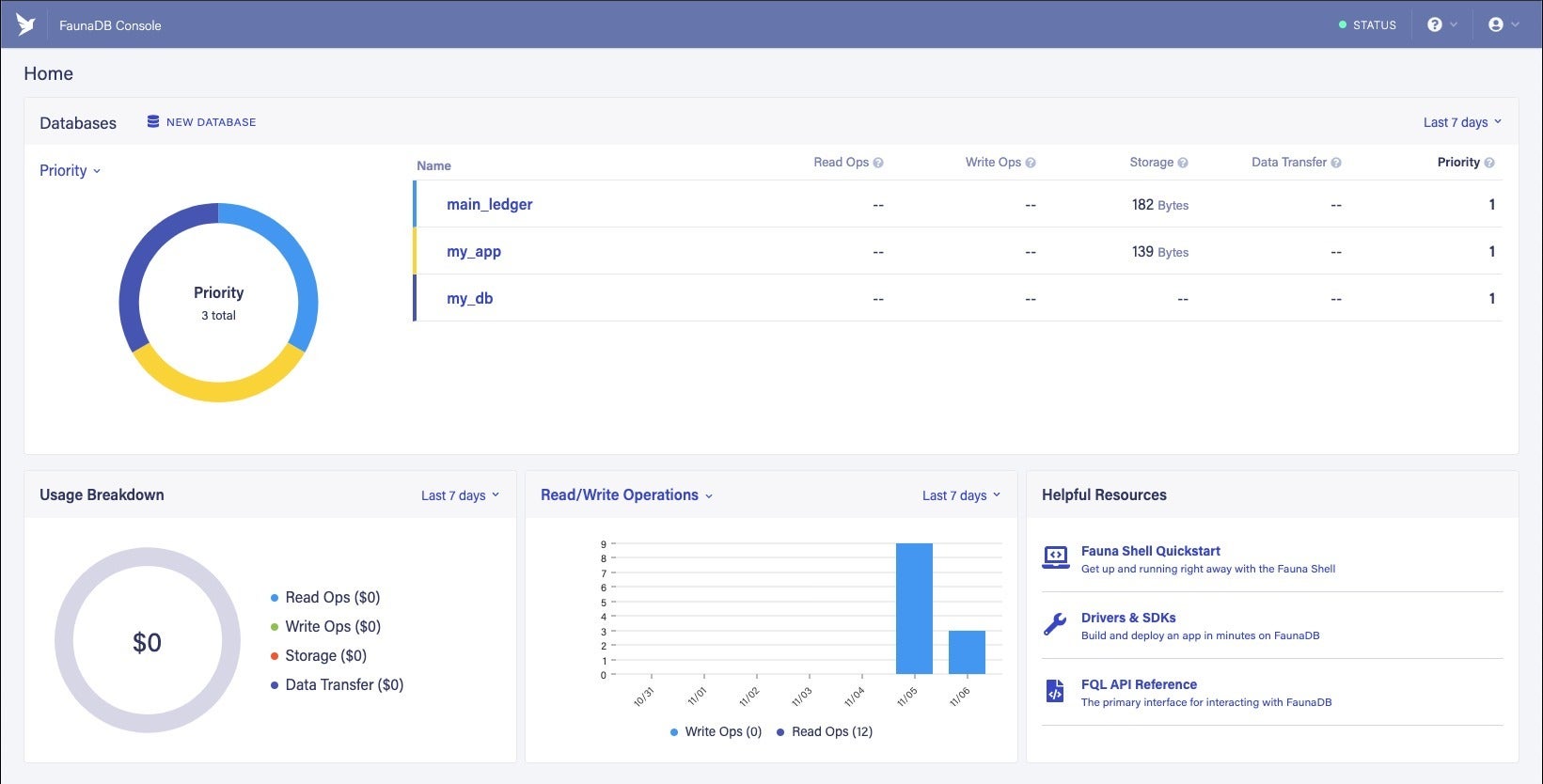
FaunaDB控制台向您显示数据库和使用情况,并提供创建新数据库的链接。
从那里,您创建一个数据库。
 IDG
IDG
创建数据库只需要设置数据库名称即可。 对于我的用例而言,优先级并不重要。
翻译自: https://www.infoworld.com/article/3489459/faunadb-review-fast-nosql-database-for-global-scale.html
nosql数据库做数据备份















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









