





将机器学习视为神奇的黑匣子是很诱人的。 输入数据; 得出预测。 但是,这里没有魔术,只有数据和算法,以及通过算法处理数据而创建的模型。
如果您要通过机器学习从数据中得出可行的见解,那将有助于该过程成为一个黑匣子。 您对框内的内容了解得越多,就越能理解流程如何将数据转换为预测的每个步骤,并且预测功能越强大。
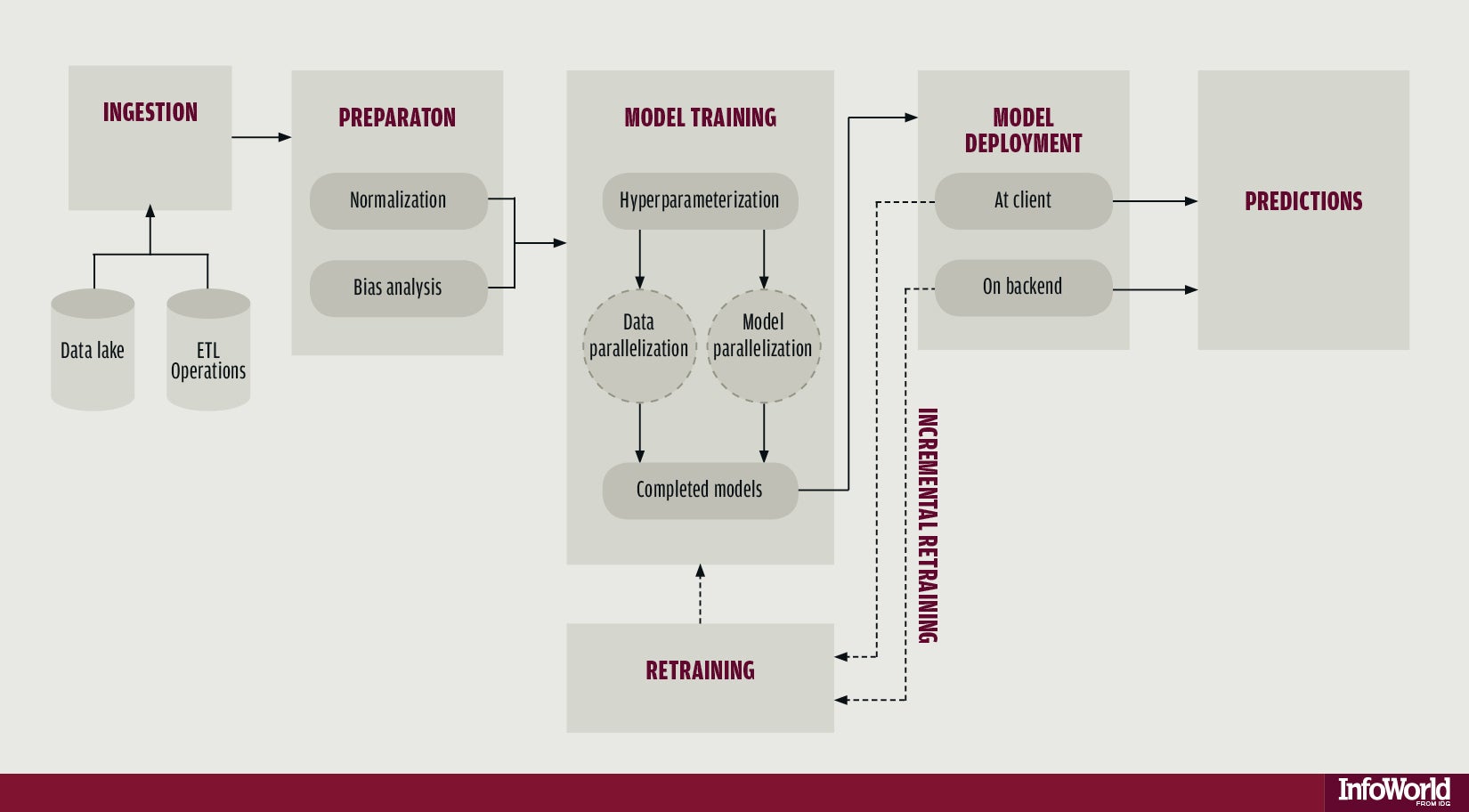
Devops的人们谈论“ 构建管道 ”,以描述如何将软件从源代码转移到部署。 就像开发人员拥有代码流水线一样,数据科学家也拥有数据流经其机器学习解决方案的流水线。 掌握管道的组合方式是从内到外了解机器学习本身的有力方法。
相关视频:机器学习管道
 IDG
IDG
机器学习的数据源和摄取
机器学习流水线包括四个阶段 ,如Wikibon Research分析师George Gilbert所述:
- 摄取数据
- 准备数据(包括数据探索和治理)
- 训练模型
- 服务预测
机器学习流程需要从两件事开始:要训练的数据和执行训练的算法。 数据将以以下两种形式之一出现:
- 您已经在某处收集和聚集的实时数据,您计划使用这些数据进行定期更新的预测。
- 一个“冻结”数据集,即您正在下载和使用的数据集,或者是通过ETL操作从现有数据源派生的。
对于冻结的数据,通常只执行一种处理:使用它训练模型,部署模型,并根据需要定期更新模型(如果有的话)。
但是对于实时数据或“流式”数据,您有两种选择关于如何从数据生成模型和结果。 第一种选择是将数据保存在某个地方,即数据库,“数据湖”,然后在其上执行分析。 第二种选择是在数据进入时根据流数据训练模型。
流数据的培训也采取两种形式 ,如机器学习解决方案提供商BigML的Charles Parker所述。 一种情况是,您要向模型提供常规的新鲜数据流以进行预测,但并没有对基础模型进行太多调整。 另一种情况是您经常使用新数据来训练全新模型,因为较旧的数据不那么相关。
这就是为什么尽早选择算法很重要的原因。 一些算法支持增量重新训练,而另一些则必须使用新数据从头开始重新训练。 如果您将一直在流式传输新数据以重新训练模型,则需要使用支持增量重新训练的算法。 例如, Spark Streaming支持此用例。
机器学习的数据准备
有了要训练的数据源后,下一步就是确保可以将其用于训练。 确保使用的数据一致性的总称是标准化。
实际数据可能很嘈杂。 如果数据是从数据库中提取的,则可以对数据进行一定程度的标准化。 但是,许多机器学习应用程序也可能直接从数据湖或其他异构源中提取数据,这些数据并不一定要进行标准化以用于生产用途。
Python Machine Learning的作者Sebastian Raschka详细撰写了有关规范化 ,以及如何针对某些常见类型的数据集实现规范化的文章 。 他使用的示例是以Python为中心的,但是基本概念可以通用。
某些机器学习环境使规范化成为一个明确的步骤。 例如,Microsoft的Azure机器学习Studio具有一个离散的“ 规范化数据 ”模块,可以将其添加到给定的数据实验中。
是否总是需要规范化? 麻省理工学院AI博士候选人Franck Dernoncourt在对Stack Overflow主题的详细探讨中并不总是这样 。 但正如他所说,“它很少疼。” 他指出,重要的是要知道针对特定用例进行标准化的优势。 对于人工神经网络,不需要标准化,但可以使用标准化。 但是,对于使用K均值聚类算法构建模型,规范化至关重要。
“ 从数据中学习”一书的合著者Malik Magdon-Ismail认为,当人们不愿进行标准化时,“ 数据的规模具有重要意义 ”是其中之一。 例如:“如果收入在信贷批准中的重要性是债务的两倍,那么收入的大小应是债务的两倍。”
在数据获取和准备阶段要注意的另一点是,如何通过数据,数据的归一化或两者同时将偏差引入模型。 机器学习中的偏见具有现实世界的后果 ; 它有助于知道如何找到并克服这种偏见 , 而这种偏见可能会存在。 永远不要假定干净 (可读,一致)的数据是无偏数据。
训练机器学习模型
建立数据集后,接下来就是训练过程,在训练过程中,数据将用于生成可以从中进行预测的模型。 通常,在找到最适合您数据的算法之前,您将尝试许多不同的算法。
超参数
我在前面提到过,您对算法的选择不仅取决于要解决的问题的类型,还取决于您是否希望对一批数据立即进行全部训练的模型还是对增量进行训练的模型。 训练模型的另一个关键方面是如何调整训练以提高所得模型的精度,即所谓的超参数化。
机器学习模型的超参数是一种设置,用于控制如何从算法生成结果模型。 例如,K均值聚类算法根据数据的相似性将数据组织成组。 因此,K均值算法的一个超参数将是要搜索的簇数。
通常,超参数的最佳选择来自对算法的经验。 有时,您需要尝试一些变体,看看哪些变体会为您的问题集带来可行的结果。 也就是说,对于某些算法实现, 自动调整超参数已成为可能。
例如,用于机器学习的Ray框架具有超参数优化功能 。 Google Cloud ML Engine提供了用于训练作业的超参数调整选项 。 名为FAR-HO的软件包为TensorFlow提供了超参数优化工具。
并行性
许多用于模型训练的库可以利用并行性,它通过在多个CPU,GPU或节点之间分布计算来加快训练过程。 如果您可以使用并行训练的硬件,请使用它。 对于每个其他计算设备,加速通常接近线性。
您用来执行培训的机器学习框架可能支持并行培训。 例如,MXNet库使您可以并行训练模型 。 MXNet还支持用于并行训练, 数据并行和模型并行的两种关键方法。
Google Brain小组成员Alex Krizhevsky在有关并行化网络训练的论文中解释了数据并行性与模型并行性之间的区别 。 使用数据并行性,“不同的工人在不同的数据示例上训练[模型]…[但是]必须同步模型参数(或参数梯度)以确保他们正在训练一致的模型。” 换句话说,尽管您可以拆分数据以在多个设备上训练,但必须使每个节点生成的模型彼此同步,以免产生明显不同的预测结果。 TensorFlow可以这种方式使用 ,并具有用于在节点之间同步数据的不同策略。
使用模型并行性,“不同的工人训练模型的不同部分”,但是每当“由一名工人训练的模型部分需要另一名工人训练的模型部分的输出”时,工人就必须保持同步。 当训练模型涉及相互反馈的多层时,通常使用这种方法,例如递归神经网络。
值得学习如何使用这两种方法来组装管道,因为许多框架(例如Torch框架 )现在都支持这两种方法。
部署机器学习模型
吉尔伯特(Gilbert)在他的论文“ 机器学习管道:中文构建模块 ”中指出,管道的最后一个阶段是部署训练好的模型,即“预测并服务”阶段。 在这里,针对输入数据运行训练后的模型以生成预测。 例如,对于人脸识别系统,传入的数据可以是爆头或自拍,并具有根据从其他人脸照片得出的模型进行的预测。
云部署
在何处以及如何提供此预测构成了管道的另一部分。 最常见的情况是通过RESTful API从云实例提供预测。 从云服务的所有明显优势都在这里发挥作用。 例如,您可以启动更多实例以满足需求。
使用云托管的模型,您还可以将更多管道保存在同一位置-训练数据,训练有素的模型和预测基础结构。 数据不必四处移动,因此一切都更快。 由于可以在相同的环境中对模型进行再培训和部署,因此可以更快地完成模型的增量再培训。
客户端设备部署
有时在客户端上部署模型并从那里提供预测是有意义的。 这种方法的最佳选择是带宽有限的移动应用程序,以及不能保证或不保证网络连接的任何应用程序。
一个警告是,在本地计算机上进行的预测质量可能会更低。 由于本地存储的限制,部署模型的大小可能会更小,进而可能影响预测质量。 也就是说,在诸如智能手机之类的适度设备上部署高精度模型变得越来越可行 ,这主要是通过在精度与速度之间进行稍微权衡来实现的。 值得一看的是所讨论的应用程序,并查看是否定期更新的本地部署模型提供了可接受的准确性。 如果是这样,那么即使没有数据连接,该应用程序也可以提供预测。
将模型部署到客户端指向另一个绊脚石。 因为您可以在很多地方部署模型,所以部署过程可能很复杂 。 从任何一种训练有素的模型到任何一种目标硬件,操作系统或应用程序平台,都没有一致的途径。 尽管使用机器学习模型开发应用程序的实践日渐增多,但毫无疑问,这种复杂性不可能很快消失,尽管找到一致的部署管道的压力无疑会增加。
今天和明天的机器学习管道
术语管道意味着从一端到另一端的单向不间断的流动。 实际上,机器学习流程更具周期性:数据进入,用于训练模型,然后评估模型的准确性,并随着新数据的到来和数据含义的演变对模型进行重新训练。
目前,我们别无选择,只能将机器学习管道视为需要个人关注的离散阶段。 并不是因为每个阶段在功能上都不同,而是因为所有这些部分的端到端集成方式很少。 换句话说,实际上没有管道,只是我们倾向于将一系列活动视为管道。
机器学习的数据平台项目
但是,有一些项目正在聚在一起,试图满足对真正管道的需求。 有些是数据平台供应商现有工作的产物。
例如,Hadoop供应商MapR提供了分布式深度学习快速入门解决方案 -结合了MapR Hadoop分发的一年期,六节点许可,具有CPU / GPU支持的集成神经网络库以及专业咨询服务。
Hortonworks最近宣布了一种使用容器跨Hortonworks Data Platform(HDP)集群部署TensorFlow的方法。 使用HDP构建的端到端机器学习管道仍然必须手工组装,但是容器的使用将使管道的整体组装更加容易。
同样,MapR正在通过微服务模型为数据科学项目创建生命周期 。 其中大部分围绕使用容器和Kubernetes来组织和编排训练和预测工作负载,以及使用Kubernetes卷驱动程序进一步将计算与存储分开。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









