







数据挖掘的常见方法
基本概念
数据挖掘就是从大量的、不完全的、有噪声的、模糊的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。确切地说,作为一门广义的面向应用的交叉学科,数据挖掘集成了许多学科中成熟的工具和技术,包括数据仓库技术、统计学、机器学习、模型识别、人工智能、神经网络等等。
过程模型
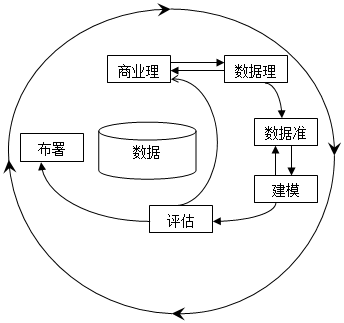
对企业来说,数据挖掘就是在“数据矿山”中找到蕴藏的“知识金块”,帮助企业减少不必要投资的同时提高资金回报。目前应用最为广泛的数据挖掘过程模型是CRISP-DM(跨行业数据挖掘过程标准,Cross-IndustryStandard Process for Data Mining)。CRISP-DM将整个数据挖掘期分为6个阶段:商业理解(BusinessUnderstanding)、数据理解(DataUnderstanding)、数据准备(Data preparation)、建模(Modeling)、评估(Evaluation)、布署(Deployment)。CRISP-DM数据挖掘过程模型如下图:
常用方法
数据挖掘中大部分方法都不是专为解决某个问题而特制的,方法之间也不互相排斥。不能说一个问题一定要采用某种方法,别的就不行。一般来说,针对某个特定的数据分析课题,并不存在所谓的最好的方法,在最终决定选取哪种模型或方法之前,各种模型都试一下,然后再选取一个较好的。各种方法在不同的数据环境中,优劣会有所不同。
数据挖掘的方法主要有:关联分析、聚类分析、预测、时序模式分析和偏差分析等。
常见和应用最广泛的算法和模型有:
1、传统统计方法:抽样技术、多元统计分析和统计预测方法等。
2、可视化技术:用图表等方式把数据特征直观地表述出来。
3、决策树:利用一系列规则划分,建立树状图,用树形结构来表示决策集合,可用于分类和预测,常用的算法有CART、CHAID、ID3、C4.5、C5.0等。
4、人工神经网络:模拟人的神经元功能,从结构上模仿生物神经网络,经过输入层、隐藏层、输出层等,对数据进行调整、计算,最后得到结果,是一种通过训练来学习的非线性预测模型,可以完成分类、聚类、特征挖掘、回归分析等多种数据挖掘任务。
5、遗传算法:基于自然进化理论,在生物进化的概念基础上设计的一种优化技术,它包括基因组合、交叉、变异和自然选择等一系列过程,通过这些过程以达到优化的目的,模拟基因联合、突变、选择等过程的一种优化技术。
6、关联规则挖掘算法:关联规则是描述数据之间存在关系的规则,形式为“A1∧A2∧…∧An→B1∧B2∧…∧Bn”。一般分为两个步骤:第一步,求出频繁数据项集;第二步,用频繁数据项集产生关联规则。
7、最近邻技术:这种技术通过已辨别历史记录的组合来辨别新的记录,它可以用来做聚类和偏差分析。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









