






使用sparkstreaming计算uv并存入redis集群
首先数据是通过flume存入kafka的待分析数据(\t隔开):

需求就是记录不同ip访问次数,相同的ip不累加,简单来说就是记录不同用户的访问量uv
kafka和redis集群的配置
application.conf

util类
ConfUtil

RedisPoolUtil

scala代码

计算总uv

这里的重点是我计算uv使用的是HyperLogLog方案,而不是sql语句或者bitmap方案因为若要计算很多页面的UV,用bitmap还是比较费空间的,N个页面就得有N个500M.这时候HyperLogLog结构就是一个比较好的选择.HyperLogLog是一种基数统计算法,计算结果是近似值, 12 KB 内存就可以计算2^64 个不同元素的基数.但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
这是redis命令行查找

这里是java的mongodb查询uv
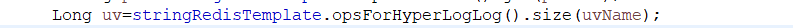
参考资料:
用Spark Streaming实时计算海量用户UV.
SparkSQL 实现UV & PV计算.
spark状态stream统计uv(updateStateByKey).















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









