







1.公司介绍
淘天集团是阿里巴巴集团全资拥有的业务集团,全球领先的科技商业公司。淘天集团以淘宝 APP 为主要服务载体,构建国内国际供给、线上线下场景、远场近场履约相结合的商业矩阵,汇聚数十万全球和中国品牌、上千万中小商家及内容创作者,满足 9 亿中国消费者多元化、个性化、品质化的生活需求。
淘天集团拥有淘宝、天猫、1688、闲鱼等商业品牌,并通过天猫国际、淘宝直播、天猫超市、淘宝买菜、阿里妈妈等业务,提供进口、直播、超市、买菜、数字营销等服务。按 GMV 计算,淘宝是中国最大的数字零售平台;由天猫首创的双 11 全球狂欢季,已经成为全球最大的购物节之一。未来三年,淘天集团将全力实施用户为先、生态繁荣、科技驱动三大战略,在继续服务最大规模消费者和商家的同时,逐步升级为一个一站式的消费及生活平台。
也就是说,“淘天”就是“淘宝”+“天猫”的结合。
2.面试背景
“面试岗位:Java 开发工程师
面试时间:2023.10.28
”
3.面试问题
-
为什么要用 Redis?有预估 QPS 的提升幅度吗?
-
Redis 内存不够用怎么办?
-
是否定义、设计过业务模型?
-
百万级用户规模服务上线的话需要做什么?
-
JVM 怎么创建一个对象?
-
有哪些场景会触发类的加载?
-
双亲委派机制,如果不按这种会有什么问题?
-
线程状态,一个线程包含哪些信息?
-
线程池执行任务的过程?
-
线程同步有哪些策略和类,有没有实测过关键字的性能?
-
SpringBoot 搭建的 Web 服务处理过程?
-
有没有看过开源框架的源码,举一个例子讲讲?
4.答案解析
问题1:为什么要用 Redis?有预估 QPS 的提升幅度吗?
答案解析思路:为什么用 Redis?回答 Redis 的优势即可。QPS(Queries Per Second,每秒钟查询次数)的问题可以使用 Redis 性能测试报告中的数据即可。Redis 优势有以下几个:
-
基于内存:Redis 是一种基于内存的数据存储系统,所有的数据都存储在内存中。相比传统的磁盘存储系统,内存访问速度更快,这使得 Redis 能够在毫秒级别快速地读取和写入数据。
-
单线程模型:Redis 使用单线程模型来处理客户端请求。这可能听起来似乎效率不高,但实际上,这种设计有助于避免多线程的竞争条件和锁开销。Redis 通过非阻塞的方式处理多个客户端请求,每个请求的执行时间很短,因此在单线程下,Redis 能够处理大量的并发请求。
-
高效数据结构:Redis 提供了多种高效的数据结构,如哈希表、有序集合等。这些数据结构的实现都经过了优化,使得 Redis 在处理这些数据结构的操作时非常高效。
-
非阻塞 I/O:Redis 使用了非阻塞 I/O 模型,这意味着当进行磁盘读写或者网络通信时, Redis 不会等待数据的返回,而是继续处理其他请求。这样可以充分利用 CPU 的时间,提高整体的吞吐量。
答案加分项:除了官方的性能测试数据之后,还可以使用 Redis 自带的性能测试工具 redis-benchmark l来对当前环境下的 Redis 做性能测试和预测,但也需要注意,网络带宽和网络延迟可能是 Redis 操作最大的性能瓶颈。
问题2:Redis 内存不够用怎么办?
答案解析思路:Redis 内存不够用时,会触发 Redis 内存淘汰策略。早期版本的 Redis 有以下 6 种淘汰机制(也叫做内存淘汰策略):
-
noeviction:不淘汰任何数据,当内存不足时,新增操作会报错,Redis 默认内存淘汰策略;
-
allkeys-lru:淘汰整个键值中最久未使用的键值;
-
allkeys-random:随机淘汰任意键值;
-
volatile-lru:淘汰所有设置了过期时间的键值中最久未使用的键值;
-
volatile-random:随机淘汰设置了过期时间的任意键值;
-
volatile-ttl:优先淘汰更早过期的键值。
在 Redis 4.0 版本中又新增了 2 种淘汰机制:
-
volatile-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值;
-
allkeys-lfu:淘汰整个键值中最少使用的键值。
其中 allkeys-xxx 表示从所有的键值中淘汰数据,而 volatile-xxx 表示从设置了过期键的键值中淘汰数据。所以,现在 Redis 的版本中有 8 种内存淘汰策略。
答案扩展:当然你还可以通过设置 Redis 的最大运行内存来尽量避免这个问题,它的设置步骤
-
打开 Redis 的配置文件:在 Redis 的安装目录下找到 redis.conf 文件,使用文本编辑器打开该文件。
-
找到并修改 maxmemory 参数:在配置文件中,搜索并找到名为"maxmemory"的参数,该参数控制 Redis 的最大内存限制。默认情况下,该参数被注释掉,即 Redis 不会限制内存使用。
-
设置 maxmemory 的值:取消注释 "maxmemory" 参数,并将其值设置为期望的运行内存大小。值可以使用单位 K、M、G 来表示,如"1G"表示 1GB 内存。确保设置的内存大小合理,不要超过可用物理内存的限制。
-
配置内存淘汰策略:在 Redis 超过设置的最大内存限制时,需要根据配置的策略来决定如何清理数据。找到并修改"maxmemory-policy"参数,可以选择使用的内存逐出策略,如 volatile-lru、allkeys-lru、volatile-random 等。
-
保存配置文件:保存对 redis.conf 文件的修改。
-
重启 Redis 服务:重新启动 Redis 服务,使新的配置生效。
问题3:是否定义、设计过业务模型?
答案解析思路:这个问题看似“高大上”,但其实非常简单。所谓的业务模型就是将需求转换成程序之后,设计的数据库和数据表,所以在开发中你一定定义过或设计过业务模型。
在软件开发过程中,业务模型是一种抽象表示,用于描述系统中涉及的业务实体、其属性和关系,以及业务流程。
定义和设计业务模型的过程涉及以下几个方面:
-
理解业务需求:首先,需要与业务团队密切合作,深入了解业务需求。这包括了解业务流程、业务规则以及业务参与者之间的关系。
-
分析业务实体:根据业务需求,将业务实体抽象成模型中的类或对象。这些实体可能包括产品、用户、订单等,每个实体都有相应的属性和行为。
-
建立关系和依赖:在业务模型中,不同实体之间可能存在关系和依赖,如一对一、一对多、多对多等关系。需要根据业务需求,确定和定义这些关系。
-
设计业务逻辑:根据业务需求,确定业务模型中的行为和业务逻辑。这些逻辑可以通过方法、规则或者流程来表示,以实现业务的各种操作和处理。
-
持久化与数据模型:将业务模型映射到数据模型,用于在持久化介质(如数据库)中存储和检索数据。这涉及选择合适的数据结构和数据库设计,以及确保业务模型与数据模型的一致性。
在设计数据库的整个过程中,要遵循数据库的“三范式”。
“数据库的三范式是指关系型数据库设计中的三个规范化级别,用于优化数据存储和查询的效率,提高数据的一致性和可维护性。
这三个范式分别是:
第一范式(1NF):第一范式要求关系表中的每个属性(列)都是原子的,不可再分的。每个属性都应该包含单一的值,不允许存在重复的属性或属性中包含多个值。这样可以避免数据冗余和数据的不一致性。
第二范式(2NF):第二范式在满足第一范式的基础上,进一步要求表中的非主键属性完全依赖于主键属性。也就是说,表中不存在非主键属性对部分主键属性进行冗余的情况。通过将数据分解为更小的表和使用关联关系,可以减少数据冗余,并确保数据的一致性。
第三范式(3NF):第三范式在满足第二范式的基础上,进一步要求表中的非主键属性之间互不依赖。也就是说,表中的每个非主键属性只依赖于主键或其他非主键属性,不会存在传递依赖的情况。通过进一步的数据分解和建立外键关系,可以消除冗余数据和数据的多次更新。
遵循三范式的设计原则能够提高数据库的数据结构和查询效率,并减少数据冗余和依赖问题,从而提高数据库的性能和可维护性。但需要注意,在实际设计中需要根据具体的业务需求和查询需求进行灵活的取舍和权衡,不一定要求严格遵守三范式。
问题4:百万级用户规模服务上线的话需要做什么?
答案解析思路:百万级用户规模在上线的时候,主要考虑的是高可用和容错的处理。因为你的业务更新不能影响用户的正常使用,并且要做好上线前测试、以及灰度发布、备份及回滚等准备工作。
百万级用户规模需要考虑的主要内容有以下几方面:
-
架构设计与扩展性规划:确保服务具备良好的扩展性和可伸缩性,以应对大量用户的访问请求。这涉及到合理的系统架构设计、使用水平扩展和垂直扩展等技术手段。
-
性能测试和优化:进行全面的性能测试,模拟高并发、大数据量等场景,发现和解决系统瓶颈和性能问题。通过优化数据库查询、缓存使用、代码逻辑等方面,提高系统的响应速度和稳定性。
-
高可用和容错处理:确保服务在面对故障或意外情况时也能保持高可用性,不影响用户体验,所以尽量选择用户使用频率最低的时间段来更新,比如凌晨 3 点到 5 点之间。采用负载均衡、故障转移、备份恢复等机制,对关键系统组件进行容错处理。
-
安全性保障:加强系统的安全性,保护用户数据和隐私。进行安全性评估和漏洞扫描,采用合适的身份认证、访问控制、数据加密等技术手段,预防和防范潜在的安全威胁。
-
监控和日志记录:建立全面的系统监控和日志记录机制,及时发现和解决系统故障和异常。监控系统的性能指标、错误日志、访问日志等,保持对系统运行状态的实时了解,为及时处理问题提供依据。
-
客户支持和用户反馈:建立用户支持渠道,及时处理用户反馈和问题。通过建立客户服务团队、在线帮助文档、用户反馈收集等方式,积极跟进用户需求和问题,不断优化产品和服务。
问题5:JVM 怎么创建一个对象?
答案解析思路:JVM 创建对象的过程,其实就是 JVM 类加载的过程。
JVM 类加载可以分为以下几个阶段:
-
加载
-
链接
-
验证
-
准备
-
解析
-
-
初始化
具体内容如下。
① 加载
加载(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载 Class Loading 是不同的,一个是加载 Loading 另一个是类加载 Class Loading,所以不要把二者搞混了。在加载 Loading 阶段,Java 虚拟机需要完成以下 3 件事:
-
通过一个类的全限定名来获取定义此类的二进制字节流;
-
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构;
-
在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口。
② 验证
验证是连接阶段的第一步,这一阶段的目的是确保 Class 文件的字节 流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信 息被当作代码运行后不会危害虚拟机自身的安全。验证选项:
-
文件格式验证
-
字节码验证
-
符号引用验证...
③ 准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。比如此时有这样一行代码:
“public static int value = 123;
”
它是初始化 value 的 int 值为 0,而非 123。④ 解析
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
⑤ 初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
答案扩展:你除了可以按照书本的方式去解释类加载的过程(加载 -> 验证 -> 准备 -> 解析 -> 初始化),你还可以选择使用比较通俗的方式来回答此问题,比如以下这样:JVM 创建一个对象的流程主要有以下这些步骤:
-
类加载:首先,JVM 会通过类加载器加载对象所属的类。类加载器将字节码文件加载到内存中,并解析生成类的结构信息。
-
内存分配:在 JVM 的堆内存中分配对象的空间。堆是 Java 运行时数据区域之一,用于存储对象实例。
-
初始化属性:为对象的属性分配内存,并进行初始值赋值。这包括对象的成员变量、实例变量以及与对象相关的其他信息。
-
执行构造方法:调用对象的构造方法进行对象的初始化。构造方法在对象创建过程中被调用,用于完成对象的初始化工作,可以设置初始状态、初始化成员变量等。
-
返回引用:创建对象后,JVM 将返回一个指向该对象的引用。通过这个引用,可以在程序中操作和访问该对象。
但需要注意的是,JVM 在内存分配和对象创建过程中可能会做一些优化,如对象的重叠分配、内存预分配等技术手段,以提高对象创建的效率和性能。
问题6:有哪些场景会触发类的加载?
答案解析:在 Java 中,会触发类的加载的主要场景包括以下几种:
-
创建类的实例:当通过关键字
new创建一个类的实例时,JVM 需要加载该类以创建对应的对象。 -
访问类的静态变量或静态方法:当访问一个类的静态变量或调用静态方法时,JVM 需要加载该类以获取对应的静态成员。
-
调用类的静态成员所在的类被加载:当访问一个类的静态成员,而该类的静态成员所在的类还没有被加载时,JVM 需要先加载该静态成员所在的类。
-
使用反射机制:当使用反射机制进行类的动态加载和操作时,JVM 会在运行时加载相应的类。
-
类型转换:当进行类型转换时(如将一个父类对象强制转换为子类对象),JVM 需要加载目标类型所对应的类。
需要注意的是,类的加载是按需进行的,即在运行时根据实际需要来加载。JVM 会采用懒加载的策略,尽可能避免不必要的类加载和资源消耗。
小结
文章内容篇幅以及作者精力的原因,所以咱们把淘天的面试题分为上、下两篇来完成,希望各位老铁多多体谅和包涵。个人能力有限,如有回答不正确或不完整之处,欢迎大家评论区留言指正和补充。
5.面试问题
-
为什么要用 Redis?有预估 QPS 的提升幅度吗?
-
Redis 内存不够用怎么办?
-
是否定义、设计过业务模型?
-
百万级用户规模服务上线的话需要做什么?
-
JVM 怎么创建一个对象?
-
有哪些场景会触发类的加载?
-
如果不使用双亲委派会有什么问题?
-
一个线程包含哪些线程状态?
-
线程池执行任务的过程?
-
线程同步有哪些策略和类?有没有实测过关键字的性能?
-
SpringBoot 搭建的 Web 服务处理过程?
-
有没有看过开源框架的源码,举一个例子讲讲?
6.答案解析
如果不使用双亲委派会有什么问题?
答:双亲委派模型指的是,当一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最 终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无 法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
自 JDK 1.2 以来,Java 一直保持着三层类加载器、双亲委派的类加载架构器,如下图所示:
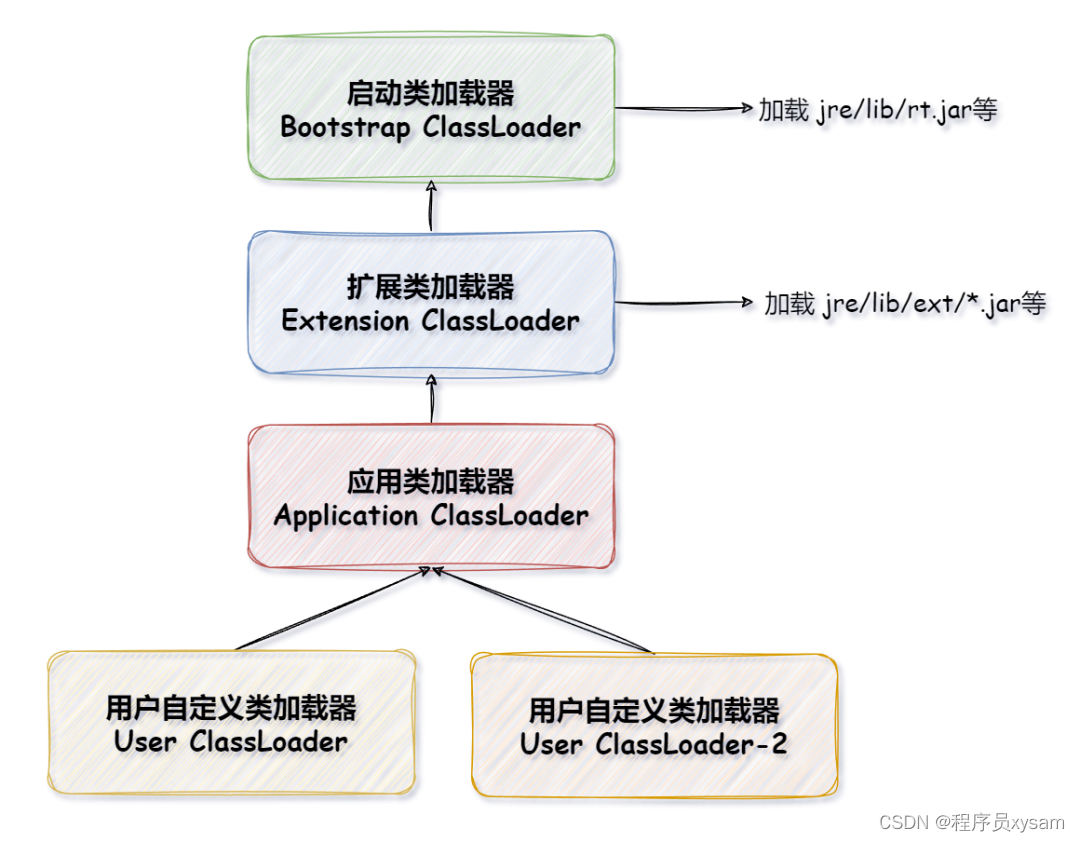
其中:
-
启动类加载器:加载 JDK 中 lib 目录中 Java 的核心类库,即$JAVA_HOME/lib目录。扩展类加载器。加载 lib/ext 目录下的类;
-
应用程序类加载器:加载我们写的应用程序;
-
自定义类加载器:根据自己的需求定制类加载器。
如果不使用双亲委派模型,可能存在以下问题:
-
安全性问题:双亲委派模型可以通过从上层类加载器向下层加载器委派类加载请求来提高安全性。如果没有双亲委派机制,那些由上层类加载器加载的核心类可能会被替换成恶意代码,从而导致安全漏洞。
-
资源浪费问题:没有双亲委派机制,每个类加载器都有自己的类加载搜索路径和加载规则。这可能导致同一个类被不同的类加载器重复加载,造成资源的浪费。
-
类冲突问题:在没有双亲委派机制的情况下,不同的类加载器可以独立加载相同的类。这可能导致类的冲突和不一致性,因为同一个类在不同的类加载器中会有多个版本存在,最终导致类的不一致问题。
双亲委派模型是保证 Java 应用程序的稳定性和安全性的重要机制,使用双亲委派模型能够避免类的冲突、提高安全性、节省资源,并保证类的一致性。
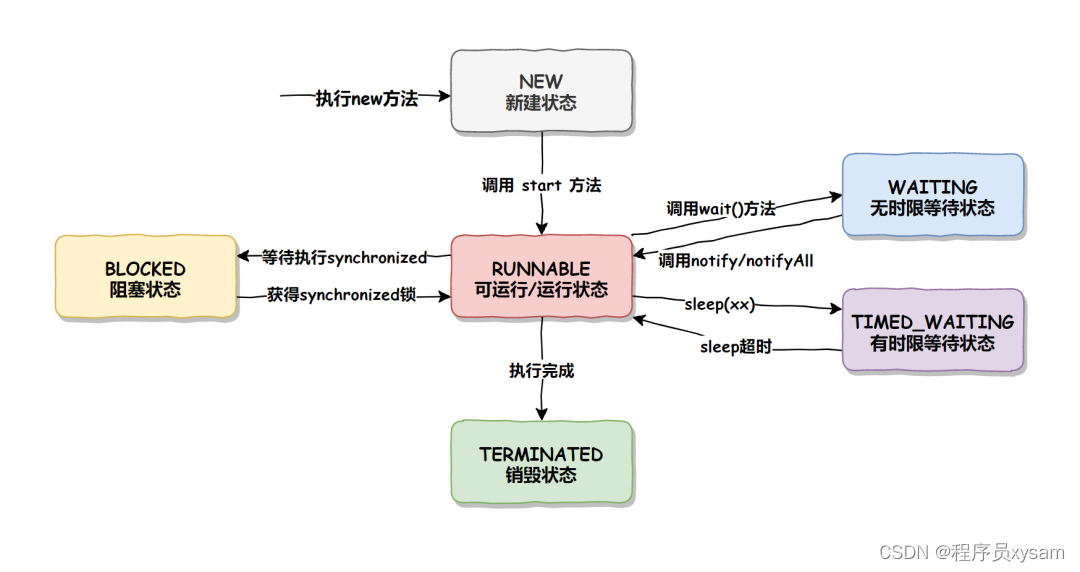
线程中包含哪些状态?
答:在 Java 中,线程状态总共有以下 6 种:
-
NEW(初始化状态):线程刚被创建时是初始状态,线程对象被创建,但还未调用 start() 方法启动线程。
-
RUNNABLE(可运行状态):线程正在 Java 虚拟机中执行,调用 start() 方法后,线程开始执行,变为此状态。
-
BLOCKED(阻塞状态):线程被阻塞,等待获取锁资源。当线程执行 synchronized 关键字标识的代码块时,如果无法获取到锁资源,则线程进入阻塞状态。当其他线程释放锁资源后,该阻塞线程进入就绪状态,等待竞争锁资源。
-
WAITING(无时限等待状态):线程通过调用 Object.wait() 方法进入等待状态,直到被其他线程通过 Object.notify() 或 Object.notifyAll() 来唤醒。
-
TIMED_WAITING(有时限等待状态):线程通过调用 Thread.sleep(long millis) 方法或 Object.wait(long timeout) 方法进入计时等待状态。在指定的时间段内,线程会一直保持计时等待状态,直到到达指定时间或被其他线程唤醒。
-
TERMINATED(终止状态):线程执行完成或者异常终止,即线程生命周期结束,线程进入终止状态后不可再次转换为其他状态。
线程状态的转换流程如下图所示:
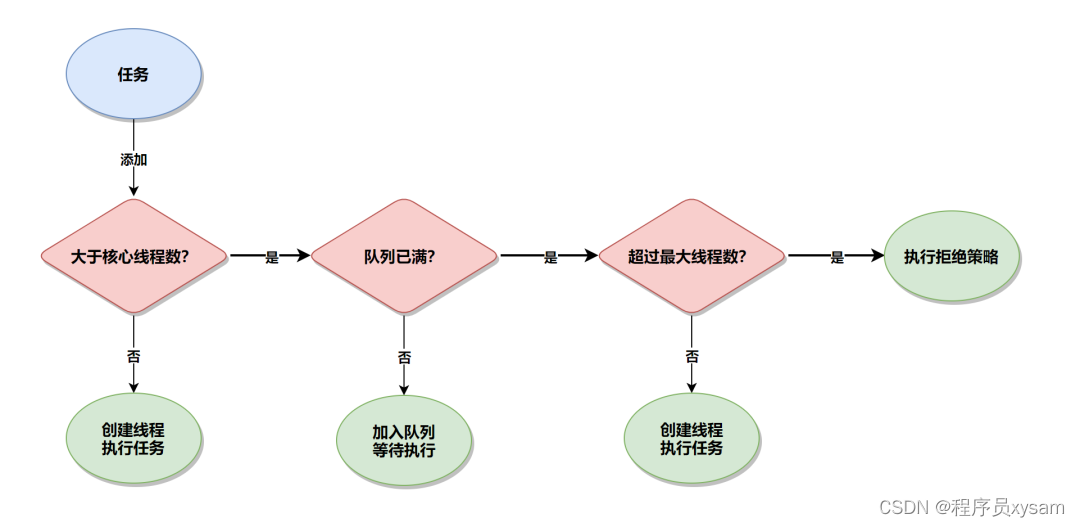
线程池执行任务的过程?
答:线程池的执行流程如下(当任务来了之后):
-
先判断当前线程数是否大于核心线程数?如果结果为 false,则新建线程并执行任务;
-
如果结果为 true,则判断任务队列是否已满?如果结果为 false,则把任务添加到任务队列中等待线程执行;
-
如果结果为 true,则判断当前线程数量是否超过最大线程数?如果结果为 false,则新建线程执行此任务;
-
如果结果为 true,则将执行线程池的拒绝策略。
执行流程如下图所示:
线程同步有哪些策略和类?有没有实测过关键字的性能?
答:线程同步是为了保证多线程环境下数据的一致性和协调线程之间的执行顺序。在 Java 中,有多种线程同步的策略和类有以下这些:
-
synchronized 关键字:通过在代码块或方法上加上 synchronized 关键字,可以实现对代码块或方法的同步访问。当一个线程获取到了对象的锁资源,其他线程就无法进入该代码块或方法,只能等待锁资源的释放。
-
ReentrantLock 类:它是显示锁的一种实现,提供了可重入的锁机制,与 synchronized 关键字相比,ReentrantLock 提供了更高的灵活性和额外的功能,例如设置等待时间、中断等待、公平性等。
-
Condition 类:与 ReentrantLock 类一起使用,通过创建多个 Condition 对象,可以实现更加精细化的线程等待和唤醒机制。
-
Semaphore 类:通过设置信号量的数量,可以控制同时访问某个资源的线程数量。
-
CountDownLatch 类:通过设置计数器的值,可以控制某个任务等待其他一组任务完成后再执行。
-
CyclicBarrier 类:通过设置参与线程数量,当所有线程都达到栅栏点后,所有线程会被释放,并继续执行。
然而,这些线程同步类的性能是和具体使用场景有关的,不同的业务场景其性能是不同的,synchronized 在早期的版本(JDK 1.6 之前)使用的是重量级锁,所以性能不是很好。但在 JDK 1.6 时经过了锁升级的优化(无锁、偏向锁、轻量级锁、重量级锁),因此绝大部分场景使用更易操作的 synchronized 就足够了,但如果需要创建公平锁或有多个任务需要协调一起执行时可以考虑其他的同步关键字。
SpringBoot 搭建的 Web 服务处理过程?
答:Spring Boot 内部使用 Servlet 容器(如 Tomcat、Jetty 等)来处理 Web(HTTP)请求和响应。它的执行流程可以分为以下几个关键步骤:
-
客户端发起请求:客户端通过 HTTP 协议向 Spring Boot 应用程序发送请求。请求可以包括 HTTP 方法(GET、POST等)、URL 路径、请求头、请求参数等信息。
-
路由匹配:Spring Boot 应用程序根据请求的 URL 路径,通过路由匹配将请求分发到对应的处理器。
-
处理器处理请求:匹配到的处理器(Controller)会执行相应的方法来处理请求。在 Spring Boot 中,Controller 会被注解标识,Spring Boot 会根据注解配置自动将请求分发给对应的 Controller。Controller 方法可以接收请求参数、处理业务逻辑,并返回响应结果。
-
调用服务层:Controller 可以调用业务逻辑处理层(Service)来进行具体的业务处理。Service 层通常负责处理复杂的业务逻辑,如数据库读写、事务管理等。
-
返回响应结果:处理器处理完请求后,将处理结果封装成 HTTP 响应返回给客户端。响应可以包括 HTTP 状态码、响应头、响应体等信息。
-
客户端接收响应:客户端收到响应后,根据响应的内容进行相应的处理,如解析 JSON 数据、渲染页面等。
-
结束请求生命周期:请求处理完成后,会结束请求的生命周期,释放相关资源。
有没有看过开源框架的源码,举一个例子讲讲?
答:这个问题没有固定的答案了,个人可根据自己的情况来说,这个给大家提供两个比较典型的案例。
Spring Boot 请求执行源码
你可以说你看过 Spring Boot 的源码,其中记忆比较深刻的就是请求进入 Spring Boot 中的执行流程,他的执行流程是这样的,所有请求先进入 DispatcherServlet(前端控制器),调用其父类 FrameworkServlet service 方法,核心源码如下:
/**
* Override the parent class implementation in order to intercept PATCH requests.
*/
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
HttpMethod httpMethod = HttpMethod.resolve(request.getMethod());
if (httpMethod == HttpMethod.PATCH || httpMethod == null) {
processRequest(request, response);
} else {
super.service(request, response);
}
}
继续往下看,processRequest 实现源码如下:
protected final void processRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 省略一堆初始化配置
try {
// 真正执行逻辑的方法
doService(request, response);
}
catch (ServletException | IOException ex) {
...
}
}
doService 实现源码如下:
protected abstract void doService(HttpServletRequest request, HttpServletResponse response) throws Exception;
doService 是抽象方法,由 DispatcherServlet 重写实现了,源码如下:
@Override
protected void doService(HttpServletRequest request, HttpServletResponse response) throws Exception {
// 省略初始化过程...
try {
doDispatch(request, response);
}
finally {
// 省略其他...
}
}此时就进入到了 DispatcherServlet 中的 doDispatch 源码了:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
// 获取原生请求
HttpServletRequest processedRequest = request;
// 获取Handler执行链
HandlerExecutionChain mappedHandler = null;
// 是否为文件上传请求, 默认为false
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
// 检查是否为文件上传请求
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request);
// Determine handler for the current request.
// 获取能处理此请求的Handler
mappedHandler = getHandler(processedRequest);
if (mappedHandler == null) {
noHandlerFound(processedRequest, response);
return;
}
// Determine handler adapter for the current request.
// 获取适配器
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Process last-modified header, if supported by the handler.
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
}
// 执行拦截器(链)的前置处理
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
// 真正的执行对应方法
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
}
// 忽略其他...
}通过上述的源码我们可以看到,请求的核心代码都在 doDispatch 中,他里面包含的主要执行流程有以下这些:
-
调用 HandlerExecutionChain 获取处理器:DispatcherServlet 首先调用 getHandler 方法,通过 HandlerMapping 获取请求对应的 HandlerExecutionChain 对象,包含了处理器方法和拦截器列表。
-
调用 HandlerAdapter 执行处理器方法:DispatcherServlet 使用 HandlerAdapter 来执行处理器方法。根据 HandlerExecutionChain 中的处理器方法类型不同,选择对应的 HandlerAdapter 进行处理。常用的适配器有 RequestMappingHandlerAdapter 和 HttpRequestHandlerAdapter。
-
解析请求参数:DispatcherServlet 调用 HandlerAdapter 的 handle 方法,解析请求参数,并将解析后的参数传递给处理器方法执行。
-
调用处理器方法:DispatcherServlet 通过反射机制调用处理器方法,执行业务逻辑。
-
处理拦截器:在调用处理器方法前后,DispatcherServlet 会调用拦截器的 preHandle 和 postHandle方法进行相应的处理。
-
渲染视图:处理器方法执行完成后,DispatcherServlet 会通过 ViewResolver 解析视图名称,找到对应的 View 对象,并将模型数据传递给 View 进行渲染。
-
生成响应:View 会将渲染后的视图内容生成响应数据。
Spring Cloud LoadBalancer 负载均衡源码
当然,除了 Spring Boot 外,你还可以讲一下 Spring cloud 微服务的源码,比如业务代码比较简单的 Spring Cloud LoadBalancer 的源码,这样既能展现自己会微服务,而且掌握的还不错。因为微服务在企业中应用广泛,所以熟练掌握微服务是一个很大的加分项。
Spring Cloud LoadBalancer 中内置了两种负载均衡策略:
-
轮询负载均衡策略
-
随机负载均衡策略
轮询负载均衡策略的核心实现源码如下:
// ++i 去负数,得到一个正数值
int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;
// 正数值和服务实例个数取余 -> 实现轮询
ServiceInstance instance = (ServiceInstance)instances.get(pos % instances.size());
// 将实例返回给调用者
return new DefaultResponse(instance);
随机负载均衡策略的核心实现源码如下:
// 通过 ThreadLocalRandom 获取一个随机数,最大值为服务实例的个数
int index = ThreadLocalRandom.current().nextInt(instances.size());
// 得到实例
ServiceInstance instance = (ServiceInstance)instances.get(index);
// 返回
return new DefaultResponse(instance);
小结
淘天集团一个标准的大厂,其薪资是比较高的,校招也能给到 30W 以上,社招薪资也不会太低,但其实看了他的面试题也可以发现,他的面试题其实不难,所以好好准备面试,也是有很大的几率进大厂的哦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









