Spring Boot 2025
Spring Boot
概述
什么是
Spring Boot
?
Spring Boot
是
Spring
开源组织下的子项目,是
Spring
组件一站式解决方案,主要是简化了使用
Spring
的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
Spring Boot
有哪些优点?
Spring Boot
主要有如下优点:
1.
容易上手,提升开发效率,为
Spring
开发提供一个更快、更广泛的入门体验。
2.
开箱即用,远离繁琐的配置。
3.
提供了一系列大型项目通用的非业务性功能,例如:内嵌服务器、安全管理、运行数据监控、运行
状况检查和外部化配置等。
4.
没有代码生成,也不需要
XML
配置。
5.
避免大量的
Maven
导入和各种版本冲突。
Spring Boot
的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是
@SpringBootApplication
,它也是
Spring Boot
的核心注解,主要组合包含了以下
3
个注解:
@SpringBootConfiguration
:组合了
@Configuration
注解,实现配置文件的功能。
</mvc:interceptor>
</mvc:interceptors>
@EnableAutoConfiguration
:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源
自动配置功能:
@SpringBootApplication(exclude
= { DataSourceAutoConfiguration.class })
。
@ComponentScan
:
Spring
组件扫描。
配置
什么是
JavaConfig
?
Spring JavaConfig
是
Spring
社区的产品,它提供了配置
Spring IoC
容器的纯
Java
方法。因此它有助于
避免使用
XML
配置。使用
JavaConfig
的优点在于:
(
1
)
面向对象的配置。由于配置被定义为
JavaConfig
中的类,因此用户可以
充分利用
Java
中的面向对象功能。一个配置类可以继承另一个,重写它的
@Bean
方法等。
(
2
)
减少或消除
XML
配置。基于依赖注入原则的外化配置的好处已被证明。
但是,许多开发人员不希望在
XML
和
Java
之间来回切换。
JavaConfig
为开发人员提供了一种纯
Java
方
法来配置与
XML
配置概念相似的
Spring
容器。从
技术角度来讲,只使用
JavaConfig
配置类来配置容器是可行的,但实际上很多人认为将
JavaConfig
与
XML
混合匹配是理想的。(
3
)类型安全和重构友好。
JavaConfig
提供了一种类型安全的方法来配置
Spring
容器。由于
Java 5.0
对泛型的支持,现在可以按类型而不是按名称检索
bean
,不需要任何强制
转换或基于字符串的查找。
Spring Boot
自动配置原理是什么?
注解
@EnableAutoConfiguration, @Configuration, @ConditionalOnClass
就是自动配置的核心,
@EnableAutoConfiguration
给容器导入
META-INF/spring.factories
里定义的自动配置类。
筛选有效的自动配置类。
每一个自动配置类结合对应的
xxxProperties.java
读取配置文件进行自动配置功能
你如何理解
Spring Boot
配置加载顺序?
在
Spring Boot
里面,可以使用以下几种方式来加载配置。
1
)
properties
文件;
2
)
YAML
文件;
3
)
系统环境变量;
等等
……
4
)命令行参数; 什么是
YAML
?
YAML
是一种人类可读的数据序列化语言。它通常用于配置文件。与属性文件相比,如果我们想要在配
置文件中添加复杂的属性,
YAML
文件就更加结构化,而且更少混淆。可以看出
YAML
具有分层配置数
据。
YAML
配置的优势在哪里
?
YAML
现在可以算是非常流行的一种配置文件格式了,无论是前端还是后端,都可以见到
YAML
配置。
那么
YAML
配置和传统的
properties
配置相比到底有哪些优势呢?
1.
配置有序,在一些特殊的场景下,配置有序很关键
2.
支持数组,数组中的元素可以是基本数据类型也可以是对象
3.
简洁
相比
properties
配置文件,
YAML
还有一个缺点,就是不支持
@PropertySource
注解导入自定义的
YAML
配置。
Spring Boot
是否可以使用
XML
配置
?
Spring Boot
推荐使用
Java
配置而非
XML
配置,但是
Spring Boot
中也可以使用
XML
配置,通过
@ImportResource
注解可以引入一个
XML
配置。
spring boot
核心配置文件是什么?
bootstrap.properties
和
application.properties
有何区别
?
单纯做
Spring Boot
开发,可能不太容易遇到
bootstrap.properties
配置文
件,但是在结合
Spring Cloud
时,这个配置就会经常遇到了,特别是在需要加载一些远程配置文件的时
侯。
spring boot
核心的两个配置文件:
bootstrap (. yml
或者
. properties)
:
boostrap
由父
ApplicationContext
加载的,比
applicaton
优先
加载,配置在应用程序上下文的引导阶段生效。一般来说我们在
Spring Cloud Config
或者
Nacos
中会
用到它。且
boostrap
里面的属性不
能被覆盖;
application (. yml
或者
. properties)
: 由
ApplicatonContext
加载,用于
spring boot
项目的自动化配
置。
什么是
Spring Profiles
?
Spring Profiles
允许用户根据配置文件(
dev
,
test
,
prod
等)来注册
bean
。因此,当应用程序在开发
中运行时,只有某些
bean
可以加载,而在
PRODUCTION
中,某些其他
bean
可以加载。假设我们的要求是
Swagger
文档仅适用于
QA
环境,并
且禁用所有其他文档。这可以使用配置文件来完成。
Spring Boot
使得使用配置文件非常简单。
如何在自定义端口上运行
Spring Boot
应用程序?
为了在自定义端口上运行
Spring Boot
应用程序,您可以在
application.properties
中指定端口。
server.port = 8090
安全
如何实现
Spring Boot
应用程序的安全性?
为了实现
Spring Boot
的安全性,我们使用
spring-boot-starter-security
依赖项,并且必须添加安全配
置。它只需要很少的代码。配置类将必须扩展
WebSecurityConfigurerAdapter
并覆盖其方法。
比较一下
Spring Security
和
Shiro
各自的优缺点
?
由于
Spring Boot
官方提供了大量的非常方便的开箱即用的
Starter
,包括
Spring Security
的
Starter
,使得在
Spring Boot
中使用
Spring Security
变得更加容易,甚至只需要添
加一个依赖就可以保护所有的接口,所以,如果是
Spring Boot
项目,一般选择
Spring Security
。当然这只是一个建议的组合,单纯从技术上来说,无论
怎么组合,都是没有问题的。
Shiro
和
Spring
Security
相比,主要有如下一些特点:
1. Spring Security
是一个重量级的安全管理框架;
Shiro
则是一个轻量级
的安全管理框架
2. Spring Security
概念复杂,配置繁琐;
Shiro
概念简单、配置简单
3. Spring Security
功能强大;
Shiro
功能简单
Spring Cloud 2025
Spring Cloud
熔断机制介绍;
在
Spring Cloud
框架里,熔断机制通过
Hystrix
实现。
Hystrix
会监控微服务间调用的状况,当失 败的调
用到一定阈值,缺省是
5
秒内
20
次调用失败,就会启动熔断机制。熔断机制的注解是
@HystrixCommand
,
Hystrix
会找有这个注解的方法,并将这类方法关联到和熔断器连在一起 的代理
上。当前,
@HystrixCommand
仅当类的注解为
@Service
或
@Component
时才会发挥 作用。
Spring Cloud
对比下
Dubbo
,什么场景下该使用
Spring
Cloud
?
两者所解决的问题域不一样:
Dubbo
的定位始终是一款
RPC
框架,
而
Spring Cloud
的目的是微 服务架构
下的一站式解决方案
。
Spring Cloud
抛弃了
Dubbo
的
RPC
通信,采用的是基于
HTTP
的
REST
方式。
严格来说,这两种方式各有优劣。虽然在一定程度上来说,后者牺牲了服务调用的性能,但也避 免了上
面提到的原生
RPC
带来的问题。而且
REST
相比
RPC
更为灵活,服务提供方和调用方的依赖 只依靠一纸契
约,不存在代码级别的强依赖,这在强调快速演化的微服务环境下,显得更为合 适。
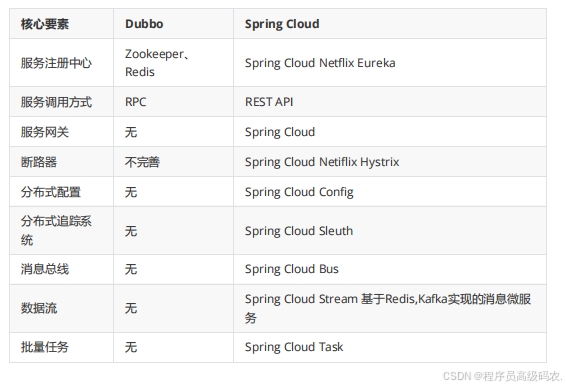
Dubbo 2025
基础知识
为什么要用
Dubbo
?
Dubbo
随着服务化的进一步发展,服务越来越多,服务之间的调用和依赖关系也越来越 复杂,诞生了面向服务的架构体系
(SOA)
,也因此衍生出了
一系列相应的技术,如对服务提供、服务调用、连接处理、通信协议、序列化方式、服务发现、服务 路由、日志输出等行为进行封装的服务
框架。就这样为分布式系统的服务治理框 架就出现了,
Dubbo
也就这样产生了。
是什么?
Dubbo
是一款高性能、轻量级的开源
RPC
框架,提供服务自动注册、自动发 现等高效服务治理方案, 可以和
Spring
框架无缝集成。
Dubbo
的使用场景有哪些?
透明化的远程方法调用:就像调用本地方法一样调用远程方法,只需简单配置, 没有任何
API
侵入。
软负载均衡及容错机制:可在内网替代
F5
等硬件负载均衡器,降低成本,减少 单点。
服务自动注册与发现:不再需要写死服务提供方地址,注册中心基于接口名查询 服务提供者的
IP
地址,并且能够平滑添加或删除服务提
供者。
Dubbo
核心功能有哪些?
Remoting
:网络通信框架,提供对多种
NIO
框架抽象封装,包括
“
同步转异 步
”
和
“
请求
-
响应
”
模式的信息交换方式。
Cluster
:服务框架,提供基于接口方法的透明远程过程调用,包括多协议支 持,以及软负载均衡,失败容错,地址路由,动态配置等
集群支持。
Registry
:服务注册,基于注册中心目录服务,使服务消费方能动态的查找服务 提供方,使地址透明,使服务提供方可以平滑增加或减
少机器。
架构设计
Dubbo
核心组件有哪些?
Mybatis 2025
JPA
原理
事务
事务是计算机应用中不可或缺的组件模型,它保证了用户操作的原子性
( Atomicity )
、一致性
( Consistency )
、隔离性
( Isolation )
和持久性
( Durabilily )
。
本地事务
紧密依赖于底层资源管理器(例如数据库连接
)
,事务处理局限在当前事务资源内。此种事务处理方式不存在对应用服务器的依赖,因而部
署灵活却无法支持多数据源的分布式事务。在数据库连接中使用本地事务示例如下:
分布式事务
public void transferAccount() {
Connection conn = null; Statement stmt = null;
try{
conn = getDataSource().getConnection();
// 将自动提交设置为 false,若设置为 true 则数据库将会把每一次数据更新认定为一个事务并自动提交
conn.setAutoCommit(false); stmt = conn.createStatement();
// 将 A 账户中的金额减少 500
stmt.execute("update t_account set amount = amount - 500 where account_id = 'A'");
// 将 B 账户中的金额增加 500
stmt.execute("update t_account set amount = amount + 500 where account_id = 'B'");
// 提交事务
conn.commit();
// 事务提交:转账的两步操作同时成功
} catch(SQLException sqle){
// 发生异常,回滚在本事务中的操做
conn.rollback();
// 事务回滚:转账的两步操作完全撤销
stmt.close(); conn.close();
}
}
Java
事务编程接口(
JTA
:
Java Transaction API
)和
Java
事务服务
(JTS
;
Java Transaction Service)
为
J2EE
平台提供了分布式事务服务。分
布式事务(
Distributed Transaction
)包括事务管理器(
Transaction Manager
)和一个或多个支持
XA
协议的资源管理器
( Resource
Manager )
。我们可以将资源管理器看做任意类型的持久化数据存储;事务管理器承担着所有事务参与单元的协调与控制。
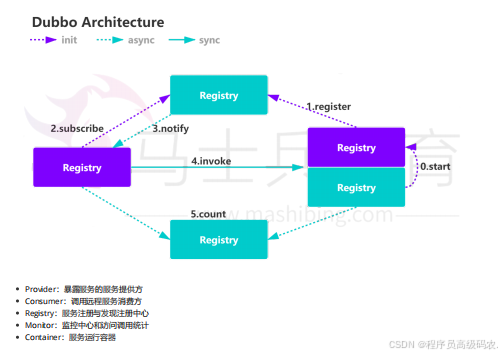
两阶段提交
两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做,所谓的两个阶段是指:第一阶段:准备阶段;第二阶段:提
交阶段。
Redis 2025
该策略可以 大化地节省
CPU
资源,却对内存非常不友好。极端情况可能出现大量的过期
key
没有再次被访问,从而不会被清除,占用大量内存。定期过期:每隔一定的时间,会
扫描一定数量的数据库的
expires
字典中一定数量的
key
,并清除其中已过期的
key
。该策略是前两者的一个折中方案。通过调整定
时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得
CPU
和内存资源达到 优的平衡效果。
(expires
字典会保存所有设置了过期时间的
key
的过期时间数据,其中,
key
是指向键空间中的某个键的指针,
value
是该键的毫秒精度的
UNIX
时间戳表示的过期时间。键空间是指
该

网络 2025
计算机网络体系结构
在计算机网络的基本概念中,分层次的体系结构是基本的。计算机网络体系结构的抽象概念较多,在学习时要多思考。这些概念对后面的学习很有帮助。网络协议是什么?
在十算机网络要做到有条不紊地交换数据,就必须遵守一些事先约定好的规则,比如交换数据的格式、是否需要发送一个应答信息。这些规则被称为网络协议。为什么要对网络协议分层?
·简化问题难度和复杂度。由于各层之间独立,我们可以分割大问题为小问题。
·灵活性好。当其中一层的技术变化时,只要层间接口关系保持不变,其他层不受影响。·易于实现和维护。
·倔进标准化工作。分开后,每层功能可以相对简单地被描述。
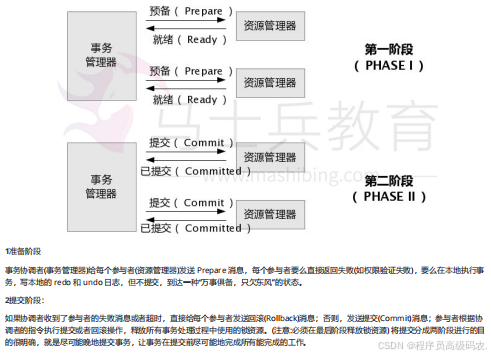
网络协议分层的缺点∶功能可能出现在多个层里,产生了额外开销。为了使不同体系结构的计算机网络都能互联,国际标准化组织ISO于1977年提出了一个试图使各种计算机在世界范围内互联成网的标准框架,即著名的开放系统互联基本参考模型OSI/RM,简称为OSl.
OSl的七层协议体系结构的概念清楚,理论也较完整,但它既复杂又不实用,TCPIP体系结构则不同,但它现在却得到了非常广泛的应用。TCPIP是一个四层体系结构,它包含应用层,运输层,网际层和网路接口层(用阿际层这个名字是强调这一层是为了解决不同网络的互连问题),不过从实质上讲,TCPIP只有上面的三层,因为下面的网络接口层并没有什么具体内容,因此在学习计算机网络的原理时性往采用折中的力法,即综合OSI和TCPIP的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚,有时为了方便,也可把底下两层称为网络接口层。
·四层协议,五层协议和七层协议的关系如下:
· TCP/IP是一个四层的体系结构,主要包括:应用层、运输层、网际层和网络接口层。·五层协议的体系结构主要包括:应用层、运输层、网络层,数据链路层和物理层。
·OSI七层协议摸型主要包括是:应用层(Application)、表示层(Presentation)、会话层(Session)、运输层(Transport)、网络层(Network)、数据链路层
(Data Link)、物理层(Physical) .
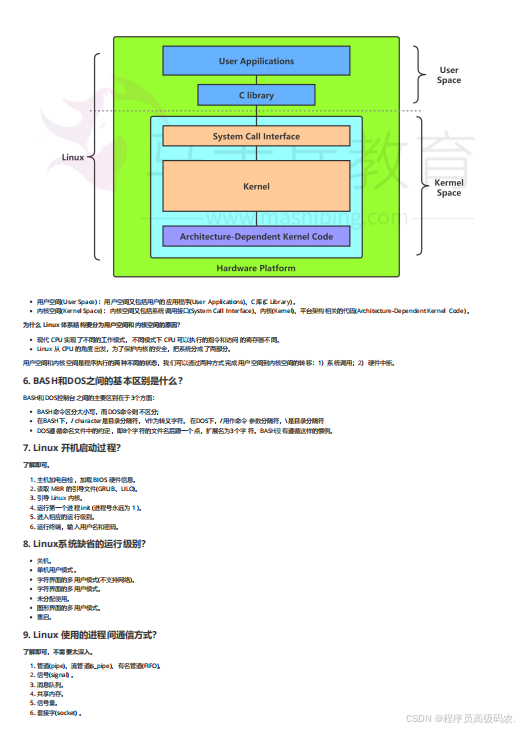
Linux 2025

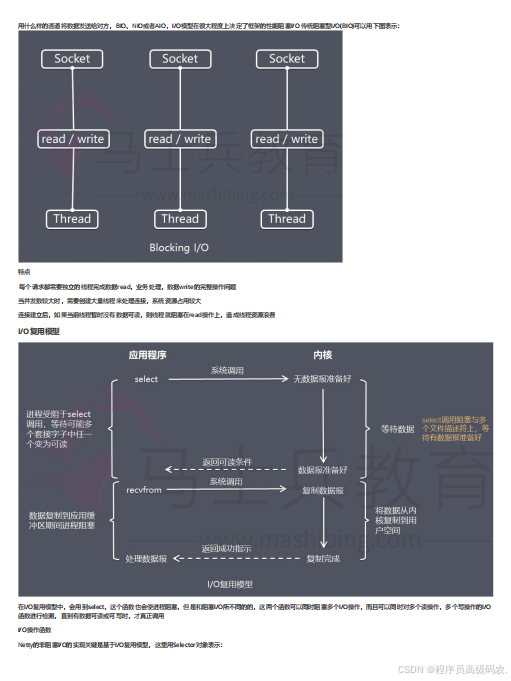
MQ 2025
为什么使用
MQ
?
MQ
的优点
简答
异步处理
-
相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦
-
系统间通过消息通信,不用关心其他系统的处理。
流量削锋
-
可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请 求。
日志处理
-
解决大量日志传输。
消息通讯
-
消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通 讯。比如实现点对点消息队列,或者聊天室等。
详答
主要是:解耦、异步、削峰。
解耦:A系统发送数据到 BCD三个系统,通过接口调用发送,如果E系统也要这个数据呢?那如果C系统现在不需要了呢?A系统负责人几乎崩s.…..系统跟其它各种乱七八糟的系统严重耦合,A系统产生一条比较关键的数据,很多系统都需要A系统将这个数据发送过来。如果使用MQ,A系统产生一条数据,发送到MQ里面去,哪个系统需要数据自己去MQ里面消费。如果新系统需要数据,直接从MQ里消费即可;如果某个系统不需要这条数据了,就取消对MQ消息的消费即可。这样下来,A系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用MQ给它异步化解耦。
异步:A系统接收一个请求,需要在自己本地写库,还需要在BCD三个系统写库,自己本地写库要3ms,BCD三个系统分别写库要30ms、 45Oms、20ms。最终请求总延时是3+300+450+200=953ms,接近1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求。如果使用MQ,那么A系统连续发送3条消息到MQ队列中,假如耗时5ms,A系统从接受一个请求到返回响应给用户,总时长是3+5= 8ms。
削峰:减少高峰时期对服务器压力。
消息队列有什么优缺点? RabbitMQ有什么优缺点?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
系统可用性降低
本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;系统复杂度提高
加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大.一致性问题

Zookeeper 2025


Netty 2025

大数据 2025
Hadoop概念
就是一个大数据解决方案。它提供了一套分布式系统基础架构。核心内容包含hdfs和mapreduce。hadoop2.0以后引入yarn.hdfs是提供数据存储的,mapreduce是方便数据计算的。
1. hdfs又对应 namenode和datanode.namenode负责保存元数据的基本信息,datanode直接存放数据本身;2. mapreduce对应jobtracker和tasktracker. jobtracker负责分发任务,tasktracker负责执行具体任务;
3.对应到masterlslave架构,namenode和jobtracker就应该对应到master, datanode和tasktracker就应该对应到slave.
HDFS
Client
Client(代表用户)通过与NameNode和DataNode交互访问HDFS中的文件。Client提供了一个类似POS风的文件系统接口供用户调用。NameNode
整个Hadoop集群中只有一个NameNode,它是整个系统的”·总管',负责管理HDS 的目录树和相关的文件元数据信息。这些信息是以"fsimage"(HDFS元数据镜像文件)和" edtog"(HDFS文件改动日志)两个文件形式存放在本地磁盘,当HDS重启时重新构造出来的,此外,NameNode还负责监控各个DataNode 的健康状态,一旦发现某个DataNode宕掉,则将该DataNode移出 HDFS并重新备份其上面的数据。
Secondary NameNode
Secondry NameNocde最重要的任务并不是为NameNocde元数据进行热备份,而是定期合并fsimage和edis日志,并传输给NameNode,这里需要注意的是,为了减小NameNode压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由
Secondary NameNode完成。
DataNode
一股而言,每个Slave 节点上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode,DataNode以固定大小的block为基本单位组织文件内容,默认情况下block 大小y为64MB,当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的 DataNode上。这种文件切割后存储的过程是对用户透明的。
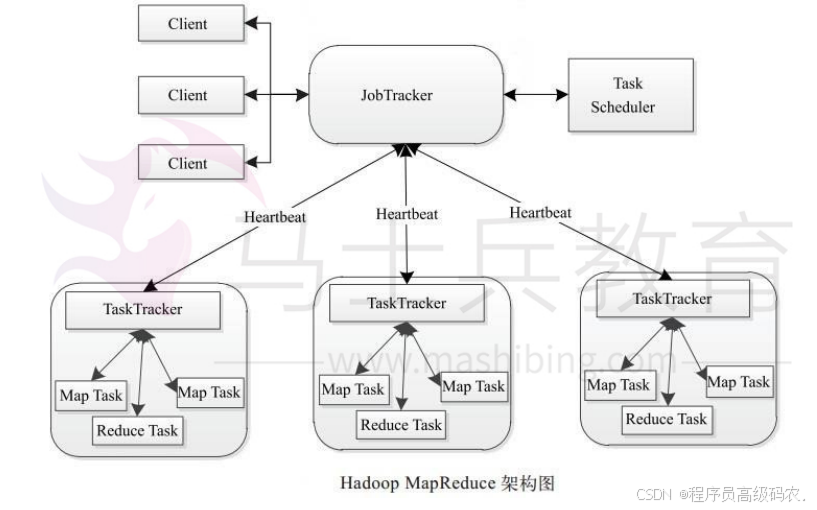
MapReduce
同HDFS一样,Hadop MapReduce 也采用了MasterSlave(MIS)架构,具体如图所示、它主要由以下几个组件组成:Client,JobTracker、TaskTracker和Task,下面分别对这几个组件进行介绍。
算法 2025

设计模式 2025


篇幅过大,1658页 Java面试突击核心讲
因包含的内容过多,这里就不多给大家介绍了,下面就只能给大家展示小册包含的内容了。

这份面试笔记包括了:Java基础、JVM、多线程&并发、spring、mybatis、springboot、MySQL、springcloud、Dubbo、Nginx、MQ、数据结构与算法、Linux、Zookeeper、Redis篇、分布式、网络篇、设计模式等;
需要全套1658页Java面试笔记的小伙伴,查看下方名片免费获取!




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









