










上篇文章介绍了leveldb block格式,block的构建及读取,这一篇文章继续介绍SST文件的写入和读取,会对SST文件整体的结构以及文件的读写做细致的介绍。
SST File Layout
通过前一篇文章可知block中除了用户数据外,还存储了每一个还原点的offset和还原点的总个数,其实在将block真正写入到文件的时候会将其按照配置的压缩类型做压缩,然后会会block末尾记录压缩类型以及crc. 整个SST文件的layout如下图所示:
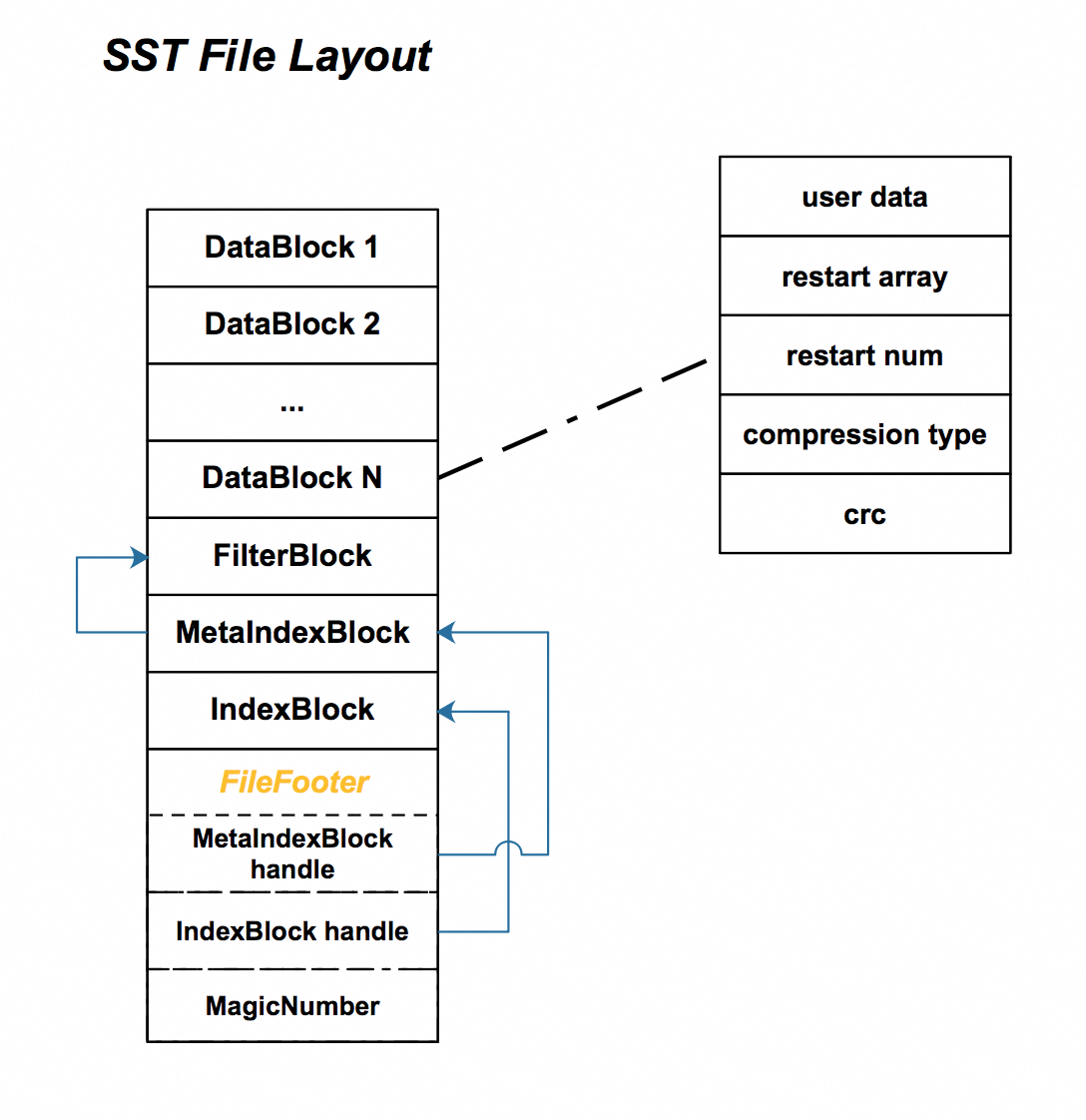
可以看到在block内部有5部分组成,其中compression type和crc作为block的trailer存储在每个block最后,DataBlock, IndexBlock, FilterIndexBlock和MetaIndexBlock的trailer都是同样的结构。
每个文件只有1个FilterBlock,其中存放的是BloomFilter的数据,用来快速判断一个指定的key是否在某个block中,具体的逻辑之后会介绍。
MetaIndexBlock的结构如同普通的dataBlock或者indexBlock,其中存储的只有一个kv-pair. key是filter.policy_name,如filter.bloomfilter_policy,目前leveldb中的filter policy有bloomfilter和stats filter. 根据filter policy不同,FilterBlock中存储的内容不同,常用的一般是bloomfilter policy. MetaIndexBlock中的value是指向FilterBlock的block handle.
在文件的结尾会存储FileFooter,由3部分构成——分别是MetaIndexBlockHandle,IndexBlockHandle和MagicNumber. FileFooter大小固定是48bytes,其中MetaIndexBlockHandle和IndexBlockHandle分别指向MetaIndexBlock和IndexBlock.
FilterBlock
FilterBlock是用来构建一个SST文件中所有filter的,一个SST文件只有一个FilterBlock,根据filter policy不同,FilterBlock存储的内容不同。此外FilterBlock的结构并不是典型意义上的leveldb的block结构,其内部只是存了一个字符串,相当于将所有数据的filter都放在同一个字符串里了,在SST文件构建的时候再将这个字符串写入到文件中的某个位置,并记录下这个位置保存在MetaIndexBlock中。目前leveldb只有stats filter policy和bloomfilter policy,下面以最常见的bloomfilter为例,阐述FilterBlock存储的内容。
FilterBlock很简单,代码如下:
// A FilterBlockBuilder is used to construct all of the filters for a
// particular Table. It generates a single string which is stored as
// a special block in the Table.
// The sequence of calls to FilterBlockBuilder must match the regexp:
// (StartBlock AddKey*)* Finish
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
FilterBlockBuilder(const FilterBlockBuilder&) = delete;
FilterBlockBuilder& operator=(const FilterBlockBuilder&) = delete;
void StartBlock(uint64_t block_offset);
void AddKey(const Slice& key);
Slice Finish();
private:
void GenerateFilter();
const FilterPolicy* policy_;
std::string keys_; // Flattened key contents
std::vector<size_t> start_; // Starting index in keys_ of each key
std::string result_; // Filter data computed so far
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
std::vector<uint32_t> filter_offsets_;
};在构造的时候只需传入一个FilterPolicy即可,根据policy的不同会生成不同内容的数据。FilterBlock所有内容都存储在result_成员中。result_中存储的内容有分为3个部分:
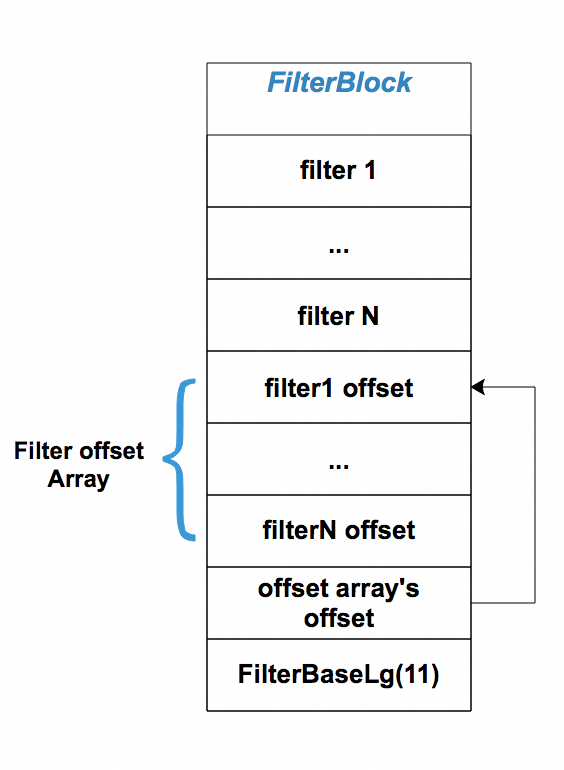
每个具体的filter entry数据,filter offset Array以及最后的FilterBaseLg.
每个filter entry是针对一个或多个dataBlock,构建FilterBlock的过程也分3步:
FilterBlockBuilder::StartBlock(0)FilterBlockBuilder::AddKey...FilterBlockBuilder::StartBlock(dataBlock1 offset)FilterBlockBuilder::AddKey...- ...
FilterBlockBuilder::StartBlock(dataBlockN offset)FilterBlockBuilder::Finish
每当dataBlock Flush的之后,都会调用一次FilterBlockBuilder::StartBlock(dataBlock's offset)来判断是否要在FilterBlock中生成一个新的FilterEntry,注:FilterEntry跟dataBlock不是一一对应的,可能多个dataBlock共用一个FilterEntry,对于bloomfilter来说,多个dataBlock的keys数据计算的bloomfilter bits可能在一个FilterEntry里面:
// Generate new filter every 2KB of data
static const size_t kFilterBaseLg = 11;
static const size_t kFilterBase = 1 << kFilterBaseLg;
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
} 如上所示,每2KB数据会切换一个新的FilterEntry,Flush下去一个dataBlock之后,若当前数据量截止上一次生成FilterEntry还没超过2KB,那么继续用当前的FilterEntry,即该dataBlock的keys生成的bloomfilter bits继续塞在当前的FilterEntry中。如果超过了2KB,那么则将现有数据生成FilterEntry,然后继续buffer新的数据。
随着SST文件dataBlock的构建,每次Add kv-pair的时候也会往FilterBlockBuilder中加入这个key:
void FilterBlockBuilder::AddKey(const Slice& key) {
Slice k = key;
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}可以看到AddKey的逻辑非常简单,只是往keys_这段buffer加入要添加的key,然后在start_中记录这个key在keys_buffer中的offset.
随着keys_buffer不断加入key,终归是要将keys_buffer中的数据根据具体的filter policy来生成FilterEntry的。下面来看下生成FilterEntry的逻辑:
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size();
if (num_keys == 0) {
// Fast path if there are no keys for this filter
filter_offsets_.push_back(result_.size());
return;
}
// Make list of keys from flattened key structure
start_.push_back(keys_.size()); // Simplify length computation
tmp_keys_.resize(num_keys);
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
tmp_keys_.clear();
keys_.clear();
start_.clear();
}生成的FilterEntry是存储在result_buffer中的。生成FilterEntry的逻辑就是将到目前为止keys_buffer中的数据计算filter然后写到result_buffer中。
由于start_中记录了当前key_buffer中每个key的offset,因此根据start_数组就可以解出之前每次添加进来的每个key是什么,因此12行这里首先解出了当前key_buffer中的每个key放在了tmp_keys_数组中,然后19行记录了当前result_buffer的size作为此时FilterEntry在result_buffer中的offset. 最后20行根据具体的policy将生成tmp_keys_数组中的所有key计算生成一个FilterEntry存放在result_buffer中。之后tmp_keys_,keys_和start_就可以清空了,他们会继续保存下一个FilterEntry的内容。
SST文件在查找某个kv-pair的时候会先在indexBlock中查找这个key位于哪个dataBlock,在定位到具体dataBlock后,会先将dataBlock的offset传入FilterBlock中先通过FilterEntry来判断一下该dataBlock是否存在这个key,若存在的话,那么再将dataBlock读出来坐进一步的查找,若不存在这个key则直接返回,因此这里就涉及到了FilterBlock的查找,其实查找的逻辑也是比较简单的:
bool FilterBlockReader::KeyMayMatch(uint64_t data_block_offset, const Slice& key) {
uint64_t index = data_block_offset >> base_lg_;
if (index < num_) {
uint32_t start = DecodeFixed32(offset_ + index * 4);
uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
Slice filter = Slice(data_ + start, limit - start);
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}- 首先第2行算出
data_block_offset对应于哪个FilterEntry - 第4-5行从filter offset Array中解析出这个
FilterEntry的offset - 第7行读出这个
FilterEntry,第8行判断指定的key是否在这个FilterEntry中
综上所述就是整个FilterBlock的构建和查找逻辑了,每个SST文件在点查的时候定位出具体的dataBlock后,会先从FilterBlock中判断查询的key是否存在,若不存在的话就直接返回了,不会读取具体的dataBlock,这算是leveldb的一种优化吧。目前支持的FilterBlock类型有stats统计信息(即根据min/max Key来判断查询的key是否存在),和bloomfilter(比较常用).
SST File构建
在介绍完了dataBlock,indexBlock,FilterBlock以及metaIndexBlock后,下面来看下SST文件构建的过程。
SST文件的构建依赖于TableBuilder这个类,如下:
class LEVELDB_EXPORT TableBuilder {
public:
// Add key,value to the table being constructed.
// REQUIRES: key is after any previously added key according to comparator.
// REQUIRES: Finish(), Abandon() have not been called
void Add(const Slice& key, const Slice& value);
// Advanced operation: flush any buffered key/value pairs to file.
// Can be used to ensure that two adjacent entries never live in
// the same data block. Most clients should not need to use this method.
// REQUIRES: Finish(), Abandon() have not been called
void Flush();
// Finish building the table. Stops using the file passed to the
// constructor after this function returns.
// REQUIRES: Finish(), Abandon() have not been called
Status Finish();
uint64_t NumEntries() const;
// Size of the file generated so far. If invoked after a successful
// Finish() call, returns the size of the final generated file.
uint64_t FileSize() const;
private:
bool ok() const { return status().ok(); }
void WriteBlock(BlockBuilder* block, BlockHandle* handle);
void WriteRawBlock(const Slice& data, CompressionType, BlockHandle* handle);
struct Rep {
Options options;
Options index_block_options;
WritableFile* file;
uint64_t offset; // offset in current file
Status status;
BlockBuilder data_block;
BlockBuilder index_block;
std::string last_key;
int64_t num_entries;
bool closed; // Either Finish() or Abandon() has been called.
FilterBlockBuilder* filter_block;
// Invariant: r->pending_index_entry is true only if data_block is empty.
bool pending_index_entry;
BlockHandle pending_handle; // Handle to add to index block
std::string compressed_output;
};
Rep* rep_;
};该类将主要成员打包在struct Rep中了,主要是构建dataBlock,indexBlock,FilterBlock的3个builder,以及文件句柄WritableFile* file.
其核心只有3个函数——Add, Flush以及Finish. 构建SST文件的过程是由Add函数驱动的,上层在Flush MemTable的时候会不断调用Add来往data_block中添加kv-pair,更新FilterBlock的内容,若当前data_block满了的话,则会触发Flush,即在文件中写入当前dataBlock的内容,然后生成一个blockHandle存入indexBlock中。
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
if (r->filter_block != nullptr) {
r->filter_block->AddKey(key);
}
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}Add的过程主要分为以下步骤:
- 第18-20行,更新filter_block
- 第22-24行向当前
data_block中添加这个kv-pair - 第27行判断当前
data_block大小是否超过配置的blockSize,若超过了,则调用Flush往文件中写入当前data_block的内容
需要注意的是在FlushdataBlock的时候并不是将dataBlock持久化之后的block offset马上插入到indexBlock中,leveldb这里做了一个优化:
为了使indexBlock中存储的内容尽可能地小,将indexBlock中的key做最简化的处理,当然可以存储每个dataBlock的最后一个key,但是若最后一个key很长的话,那么indexBlock就会很大,并且在查找的时候indexBlockcompareKey函数开销也会很大(compareKey的开销取决于所比较的字符串长度).
因此在indexBlock中只要存储最短的并且能区分出在哪个dataBlock中的key就可以了,下面是个具体的例子:
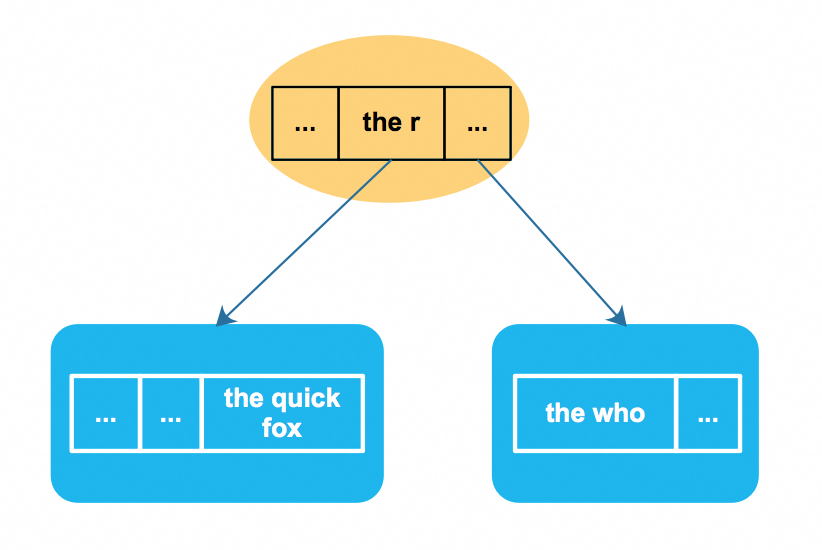
其中dataBlock1的lastKey是the quick fox,dataBlock1的firstKey是the who. indexBlock中可以存储the quick fox这个key,但是这个key有点长,有点浪费,我们只要能够区分出dataBlock1和dataBlock2就可以了,因此可以算出一个最短的且具有区分度的key——the r,indexBlock的定位dataBlock的时候将the r与待查询的key作比较就可以定位出待查询的key位于哪个dataBlock.
因此,第9-16行的逻辑就是等到下一个当前dataBlock的第一个kv-pair来到的时候,才会算出上一个dataBlock的indexKey,并将其插入到indexBlock中。
dataBlock Flush的逻辑比较简单:
void TableBuilder::Flush() {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->data_block.empty()) return;
assert(!r->pending_index_entry);
WriteBlock(&r->data_block, &r->pending_handle);
if (ok()) {
r->pending_index_entry = true;
r->status = r->file->Flush();
}
if (r->filter_block != nullptr) {
r->filter_block->StartBlock(r->offset);
}
}首先第7行是将data_block对应的block内容做压缩然后写入到文件中,将block的offset,size信息保存到r->pending_handle中 (等下一个dataBlock的kv-pair到来之后再算出上一个dataBlock的indexKey之后插入到indexBlock中),然后将pending_index_entry标记为true,意味着这个pending_index_handle延迟写入。最后调用filter_block->StartBlock来判断是否要切换一个新的FilterEntry.
TableBuilder::Finish函数逻辑也比较直白,具体就是依次持久化写入FilterBlock, MetaIndexBlock, IndexBlock和FileFooter,这里不再赘述。
SST文件读取
SST文件读取是由Table这个类实现的:
class LEVELDB_EXPORT Table {
public:
static Status Open(const Options& options, RandomAccessFile* file,
uint64_t file_size, Table** table);
// Returns a new iterator over the table contents.
// The result of NewIterator() is initially invalid (caller must
// call one of the Seek methods on the iterator before using it).
Iterator* NewIterator(const ReadOptions&) const;
private:
struct Table::Rep {
~Rep() {
delete filter;
delete[] filter_data;
delete index_block;
}
Options options;
Status status;
RandomAccessFile* file;
uint64_t cache_id;
FilterBlockReader* filter;
const char* filter_data;
BlockHandle metaindex_handle; // Handle to metaindex_block: saved from footer
Block* index_block;
};
static Iterator* BlockReader(void*, const ReadOptions&, const Slice&);
explicit Table(Rep* rep) : rep_(rep) {}
// Calls (*handle_result)(arg, ...) with the entry found after a call
// to Seek(key). May not make such a call if filter policy says
// that key is not present.
Status InternalGet(const ReadOptions&, const Slice& key, void* arg,
void (*handle_result)(void* arg, const Slice& k,
const Slice& v));
// 读取metaIndexBlock
void ReadMeta(const Footer& footer);
// 读取FilterBlock
void ReadFilter(const Slice& filter_handle_value);
Rep* const rep_;
};Table也是将读取SST所需要的成员打包在Table::Rep中,其核心成员有FilterBlockReader, metaindex_handle和index_block. SST文件的读取和遍历也是通过创建Iterator来实现的,Table类主要有4个重要的方法:
Table::Open:读取文件指定大小的内容,读取FileFooter,IndexBlock,metaIndexBlock和FilterBlock,构建Table对象出来Table::BlockReader:根据给定的dataBlockHandle,创建出这个dataBlock的Block::Iter并返回
// Convert an index iterator value (i.e., an encoded BlockHandle)
// into an iterator over the contents of the corresponding block.
/**
* @param arg pointer to Table
* @param index_value index block's entry(i.e. encoded BlockHandle of data block)
* @return data block's iterator
*/
Iterator* Table::BlockReader(void* arg, const ReadOptions& options,
const Slice& index_value) {
Table* table = reinterpret_cast<Table*>(arg);
Cache* block_cache = table->rep_->options.block_cache;
Block* block = nullptr;
Cache::Handle* cache_handle = nullptr;
BlockHandle handle;
Slice input = index_value;
Status s = handle.DecodeFrom(&input);
// We intentionally allow extra stuff in index_value so that we
// can add more features in the future.
if (s.ok()) {
BlockContents contents;
if (block_cache != nullptr) {
// Read block from cache
char cache_key_buffer[16];
EncodeFixed64(cache_key_buffer, table->rep_->cache_id);
EncodeFixed64(cache_key_buffer + 8, handle.offset());
Slice key(cache_key_buffer, sizeof(cache_key_buffer));
cache_handle = block_cache->Lookup(key);
if (cache_handle != nullptr) {
block = reinterpret_cast<Block*>(block_cache->Value(cache_handle));
} else {
s = ReadBlock(table->rep_->file, options, handle, &contents);
if (s.ok()) {
block = new Block(contents);
if (contents.cachable && options.fill_cache) {
cache_handle = block_cache->Insert(key, block, block->size(),
&DeleteCachedBlock);
}
}
}
} else {
// Read block from file
s = ReadBlock(table->rep_->file, options, handle, &contents);
if (s.ok()) {
block = new Block(contents);
}
}
}
// Create block's iterator
Iterator* iter;
if (block != nullptr) {
iter = block->NewIterator(table->rep_->options.comparator);
if (cache_handle == nullptr) {
iter->RegisterCleanup(&DeleteBlock, block, nullptr);
} else {
iter->RegisterCleanup(&ReleaseBlock, block_cache, cache_handle);
}
} else {
iter = NewErrorIterator(s);
}
return iter;
}BlockReader函数参数之一就是dataBlockHandle,该函数作用就是将dataBlockHandle指向的dataBlock从文件中读出来,然后构造Block::Iterator并返回。通过代码可以看到其实现主要就是先尝试着从block_cache里读取指定的block,如果block_cache没有数据那么就从文件中读取这个block的数据,然后再构造这个block的Iterator.
Table::InternalGet:查找到SST文件中指定key对应的kv-pair,然后使用传入的handle_result函数对这个kv-pair做处理。
Status Table::InternalGet(const ReadOptions& options, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&,
const Slice&)) {
Status s;
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
iiter->Seek(k);
if (iiter->Valid()) {
Slice handle_value = iiter->value();
FilterBlockReader* filter = rep_->filter;
BlockHandle handle;
if (filter != nullptr && handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// Not found
} else {
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k);
if (block_iter->Valid()) {
(*handle_result)(arg, block_iter->key(), block_iter->value());
}
s = block_iter->status();
delete block_iter;
}
}
if (s.ok()) {
s = iiter->status();
}
delete iiter;
return s;
}- 首先第5-6行用IndexBlock::Iter定位传入的
k,找到dataBlock的BlockHandle - 第11-12行通过FilterBlock来查询这个dataBlock中是否包含这个
k,不包含则直接返回 - 第15行构造这个dataBlock::Iter,第16行查找指定的
k - 第17-18行对查找到的kv-pair做处理
Table::NewIteraor:创建SST文件的Iterator
Iterator* Table::NewIterator(const ReadOptions& options) const {
return NewTwoLevelIterator(
rep_->index_block->NewIterator(rep_->options.comparator),
&Table::BlockReader, const_cast<Table*>(this), options);
}Table的Iterator是个TwoLevelIterator. TwoLevelIterator本质是持有1个IndexBlock::Iter,然后根据IndexBlock::Iter当前的值,读出解析出对应dataBlock::Iter,然后返回数据的。最后来看一下TwoLevelIterator的实现
class TwoLevelIterator : public Iterator {
public:
TwoLevelIterator(Iterator* index_iter, BlockFunction block_function,
void* arg, const ReadOptions& options);
void Seek(const Slice& target) override;
void SeekToFirst() override;
void SeekToLast() override;
void Next() override;
void Prev() override;
bool Valid() const override { return data_iter_.Valid(); }
Slice key() const override {
assert(Valid());
return data_iter_.key();
}
Slice value() const override {
assert(Valid());
return data_iter_.value();
}
private:
void SkipEmptyDataBlocksForward();
void SkipEmptyDataBlocksBackward();
void SetDataIterator(Iterator* data_iter);
void InitDataBlock();
BlockFunction block_function_;
void* arg_;
const ReadOptions options_;
Status status_;
IteratorWrapper index_iter_;
IteratorWrapper data_iter_; // May be nullptr
// If data_iter_ is non-null, then "data_block_handle_" holds the
// "index_value" passed to block_function_ to create the data_iter_.
std::string data_block_handle_;
}; TwoLevelIterator的two level是指上下2层,上层是indexBlock,下层对应indexBlock索引的每一个dataBlock,因此访问数据的逻辑是先找到IndexBlock::Iter指向的dataBlock,然后通过dataBlock::Iter去访问具体的数据,Block::Iter上一篇文章已有介绍,TwoLevelIterator是对Block::Iter的封装和调用。
TwoLevelIterator继承了Iterator,实现了通用迭代器的所有方法,其主要成员只有2个,即index_iter_和data_iter_. index_iter_只会构造一次,data_iter_会随着index_iter_指向不同的dataBlock而即时创建。其构造函数会传入index_iter和block_function,其中block_function就是上一节提到的Table::BlockReader方法——用来创建dataBlock::Iter的。
下面来看看TwoLevelIterator一些主要的成员函数
InitDataBlock:读取index_iter_当前指向的dataBlock,并构造其iter赋值给data_iter_
void TwoLevelIterator::SetDataIterator(Iterator* data_iter) {
if (data_iter_.iter() != nullptr) SaveError(data_iter_.status());
data_iter_.Set(data_iter);
}
// Create new data block iter corresponding to the block entry of current index block iter points to
void TwoLevelIterator::InitDataBlock() {
if (!index_iter_.Valid()) {
SetDataIterator(nullptr);
} else {
Slice handle = index_iter_.value();
if (data_iter_.iter() != nullptr &&
handle.compare(data_block_handle_) == 0) {
// data_iter_ is already constructed with this iterator, so
// no need to change anything
} else {
Iterator* iter = (*block_function_)(arg_, options_, handle);
data_block_handle_.assign(handle.data(), handle.size());
SetDataIterator(iter);
}
}
}实现非常简单,使用了block_function_,并用data_block_handle_hold住当前dataBlock的blockHandle的值。
SeekToFirst:将index_iter_指向第一个dataBlock,创建dataBlock::Iter,并将指向第一个记录
void TwoLevelIterator::SeekToFirst() {
index_iter_.SeekToFirst();
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.SeekToFirst();
SkipEmptyDataBlocksForward();
}第2-4行分别是创建第一个dataBlock的Iter,并将其也指向第一条记录。SkipEmptyDataBlocksForward的实现如下:
SkipEmptyDataBlocksForward:向后移动到下一个合法的dataBlock为止。
// Move to the next valid data block
void TwoLevelIterator::SkipEmptyDataBlocksForward() {
while (data_iter_.iter() == nullptr || !data_iter_.Valid()) {
// Move to next block
if (!index_iter_.Valid()) {
SetDataIterator(nullptr);
return;
}
index_iter_.Next();
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.SeekToFirst();
}
}其实就是不断向后迭代下一个dataBlock,直到其valid为止
Next:data_iter后移一位,若当前dataBlock数据遍历完了,则遍历下一个dataBlock
void TwoLevelIterator::Next() {
assert(Valid());
data_iter_.Next();
SkipEmptyDataBlocksForward();
}实现简单,不再赘述
Seek(const Slice& target):查询出>=target的第一条记录
void TwoLevelIterator::Seek(const Slice& target) {
index_iter_.Seek(target);
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.Seek(target);
SkipEmptyDataBlocksForward();
}首先第2行先是将index_iter_Seek到相应位置找到对应的dataBlock,然后第4行将data_iter_也Seek到相应位置。最后第5行如果当前data_iter_是Invalid的,那么就后移一个dataBlock.
SeekToLast, Prev和SkipEmptyDataBlocksBackward的逻辑也类似,不再赘述。
总结
本文先介绍了SST文件的物理Layout,其中包括组成SST的每一种类型的Block以及FileFooter,之后重点介绍了FilterBlock的构建与查询,目前leveldb有stats类型和bloomfilter类型的2种FilterBlock.接下来着重分析了SST文件的构建(TableBuilder)与读取(Table),最后介绍了一种新的Iterator——TwoLevelIterator,及其基本成员函数的实现。
到这篇文章为止,SST文件的结构及源码就全部分析完了。SST格式(一)和SST格式(二)两篇文章介绍了leveldb SST文件的所有内容,可以看到涉及到SST文件的读写还是有相当一部分内容的,但是其源码实现也比较简单易懂。SST文件格式及其读写是leveldb的核心,也是LSM kv存储引擎的基础。
p.s. 开通微信个人公众号啦,会不定期更新一些大数据/数据库技术文章和个人思考等,欢迎关注微信公众号 搜索:一些次要时刻
















 2255
2255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









