







1. getInputStream()
对于web中简单的文件上传,思路是很清晰的,即:
->客户端使用form中的file选择文件
->提交表单
->服务端通过获取表单数据
->保存文件。
对应到jsp的话,客户端不用管,服务端使用servlet中的request获取表单数据,再将数据通过io流进行输出保存。上代码举例说明:
<form action="Upload" method="post" enctype="multipart/form-data">
<input type="file" name="upload" value="选择文件" multiple="multiple">
<input type="submit" value="提交">
</form>首先是注意的是表单的enctype属性,该属性用于设置表单提交数据的编码方式。它有以下3个值。
- application/x-www-form-urlencoded:这是默认值。主要用于处理少量文本数据的传递。在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。
- multipart/form-data:上传二进制数据,只用使用了multipart/form-data,才能完整的传递文件数据,进行上传的操作。
- text/plain:主要用于向服务器传递大量的文本数据。比较适用于电子邮件的应用。
关于这几种属性,扩展一下。针对multipart/form-data,更多详情参考这里。
还有一个地方,input file里面的multiple=”multiple”,这是html5才支持的新功能,部分浏览器可能不兼容,作用是选择文件时支持多选,这样可以直接实现多文件上传。
接下来处理服务端,按照思路,我们只需在servlet里获取数据,request的getInputStream()可以直接读取数据流,然后进行Output,来试一下。
protected void doPost(HttpServletRequest request,HttpServletResponse response)throws ServletException, IOException {
// TODO Auto-generated method stub
PrintWriter writer=response.getWriter();
InputStream in=request.getInputStream();
File file=new File("D://aaa.txt");
FileOutputStream fout = new FileOutputStream(file);
byte[] b=new byte[1024];
int n=0;
while((n=in.read(b))!=-1){
fout.write(b, 0, n);
}
fout.close();
in.close();
writer.println("成功");
writer.close();
}我们测试一下,没毛病,但是数据似乎有点问题
原文件:
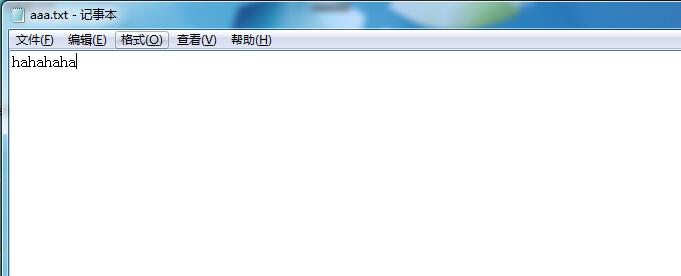
上传后的文件:
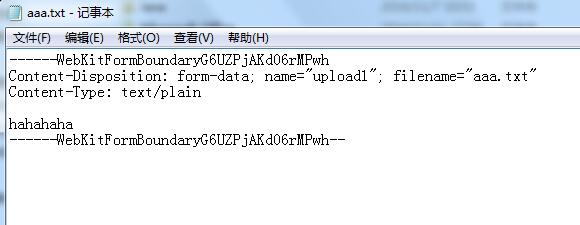
由于上传的实现方式是页面表单 + RFC1867规范 + http协议上传,传输过来的字节信息是boundary值+文件相关信息+body+boundary值,由于我上传的文件格式是文本,这些信息能够显示出来,但是要是上传的图片,多出来的这些字节信息可是会导致图片直接挂掉。

因为我们只需要body,解决方案是自己写一个处理方法,将这些多余的字节删除, 自己手写了一下,小文件没什么问题,但是使用的内存做文件缓存,不知道文件过大会怎么样。
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
int dataLength = request.getContentLength(); // 获取文件大小,单位字节
byte[] b = new byte[dataLength];
InputStream in = request.getInputStream();
int off = 0;
int n = 0;
byte[] tmp = new byte[8000];
while ((n = in.read(tmp)) != -1) { // 这里严重注意,我一开始直接就in.read(b)了,但是debug发现后面的数据都为0,经导师指正才明白read()每次不一定读取了所以数据,传过来的大小要根据n来确定,所以在IO里读取字节要while循环读取
for (int i = 0; i < n; i++) {
b[off + i] = tmp[i];
}
off += n;
}
if (off != dataLength) { // 这里的功能是判断读取的实际字节数和文件真实字节数是否一致,若不一致则意味着文件传输过程中数据丢失
PrintWriter writer = response.getWriter();
writer.print("<script language=javascript>window.alert('文件传输失败!');window.history.back();</script>");
writer.close();
return;
}
int begin = bytesIndexOf(b, "\r\n\r\n") + 4;// 根据协议,头信息和正文之间有一个\r\n\r\n,通过这个匹配位置
String header = getHeader(b, begin, request);
String fileName = getFileName(header); // 获取文件名
String contentType = request.getContentType(); // 获取头信息,主要是为了获取boundary值
String boundaryText = contentType.substring(contentType.lastIndexOf("=") + 1); // 格式:boundary=-------------xxxxxxxx
int end = bytesLastIndexOf(b, boundaryText) - 4; // 这里我看到的是两个字符,但多次尝试后发现还是得-4,不明白为什么
FileOutputStream fout = new FileOutputStream(new File("e://" + fileName)); // 文件保存路径
fout.write(b, begin, end - begin); // 结束位置-开始位置即为body
fout.close();
in.close();
}
String getHeader(byte[] b, int index, HttpServletRequest request) throws UnsupportedEncodingException {
String charEncoding = request.getCharacterEncoding();// 获取浏览器编码
byte[] header = new byte[index + 1];
System.arraycopy(b, 0, header, 0, index + 1);// 截取头信息的字节数组
return new String(header, charEncoding);
}
String getFileName(String dataString) throws UnsupportedEncodingException {
int stringBegin = dataString.indexOf("filename=\"") + 10; // 'filename=\'这一段即10个字符,所以+10
int stringEnd = dataString.indexOf("\"", stringBegin);
String fileName = dataString.substring(stringBegin, stringEnd);
int index = fileName.lastIndexOf('\\');// 针对IE浏览器,filename的值为路径+文件名
if (index != -1)
fileName = fileName.substring(index + 1);
return fileName;
}
/*
* byte数组的indexOf,同String的indexOf
*/
int bytesIndexOf(byte[] b, String s) {
byte[] mate = s.getBytes();
for (int i = 0; i < b.length - mate.length; i++) {
for (int j = 0; j < mate.length && b[i + j] == mate[j]; j++) {
if (j == mate.length - 1) {
return i;
}
}
}
return -1;
}
/*
* byte数组的lastIndexOf,同String的lastIndexOf
*/
int bytesLastIndexOf(byte[] b, String s) {
byte[] mate = s.getBytes();
for (int i = b.length - mate.length; i >= 0; i--) {
for (int j = 0; j < mate.length && b[i + j] == mate[j]; j++) {
if (j == mate.length - 1) {
return i;
}
}
}
return -1;
}**编写这段代码可是历经艰辛,迈进了好多坑,一一总结下:
- 原来学IO流的时候一直不明白,为什么要while((n=in.read(bytes))!=-1)循环读入,原来read并不是根据bytes大小直接读满的,而n是判断读入了多少的关键,所以下一句才是write(bytes,o,n)而不是直接write(bytes)
- 注意不同浏览器的情况不同,在chrome中filename就是文件名,而IE中filename是文件路径+文件名,在获取文件名的时候要处理
- 还是不同浏览器的问题,在判断body结束的位置的时候,我一开始只用了chrome,多次测试后发现最后的需要删除的就是46个字节,但是换了IE就不一样了,boundary值每个浏览器都不一样,所以还得先获取contentType取出boundary值来判断位置,不能想当然- -!
- 一开始我的解决思路的是把这些字节转换成字符串再进行查找位置的操作,但是文件内容很多的话本来byte数组就占了很多内存了再整个String是件很蠢的事情,参考了Commons-FileUpload的源码发现直接在byte数组里面匹配就好了,虽然没用String的indexOf方法但自己写一个也没什么问题。
- 在获取begin的值的时候,我一开始是仔细debug几次发现那些头信息就四行,于是用了四次indexOf(“\n”)+1,后来老师指正要根据协议来,查找”\r\n\r\n”就可以了,唉~
2. Commons-FileUpload
我采用的是Apache开发的文件上传处理库,Commons-FileUpload。在删除了多余信息的同时,将那些信息中的fieldName,filename和Content-Type三个参数的值可供调用,方便了文件的保存处理。同时通过一个list集合保存多个文件域,支持多文件上传。
需要用到两个jar包,commons-fileupload和commons-io,自行搜索下载。
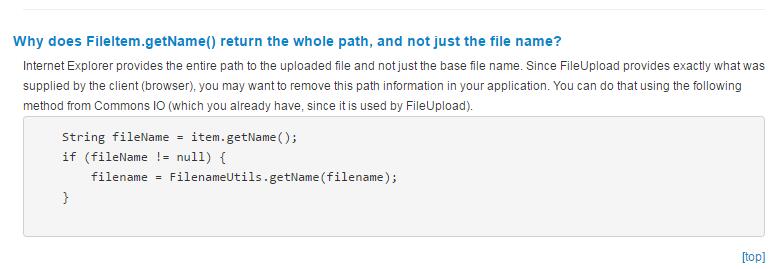
注意:这里面的getName()方法若使用chrome没毛病,但是要是用IE的话也会出现上文中提到的获取的是路径+文件名,Apache官网提供了解决方案。链接
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
DiskFileItemFactory factory = new DiskFileItemFactory(); //这里首先开一个用于文件缓存的对象
factory.setRepository(new File("D://apache-tomcat-7.0.72//Test//tmp")); //缓存文件路径
factory.setSizeThreshold(1024 * 1024 * 20); //设置内存大小,文件数据存放到内存中超出这个大小才会生成缓存文件
ServletFileUpload upload = new ServletFileUpload(factory); //创建上传文件对象
List items = null; //存放多个上传文件的集合
try {
items = upload.parseRequest(request); //获取集合,返回类型为List<FileItem>
} catch (FileUploadException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for (int i = 0; i < items.size(); i++) { //遍历集合
FileItem item = (FileItem) items.get(i);
if (item.isFormField()) { //判断表单域类型,若不是文件域,则返回true
/*处理方式略*/
} else {
String fieldName = item.getFieldName(); // 获取文件域的表单name
String fileName = item.getName(); // 获取文件名(后缀也有)
String contentType = item.getContentType(); // 获取文件类型
FileOutputStream fos = new FileOutputStream(new File("D://apache-tomcat-7.0.72//Test//" + fileName)); //存放路径
InputStream in = item.getInputStream();
byte[] b = new byte[1024];
int n = 0;
while ((n = in.read(b)) != -1) {
fos.write(b, 0, n);
}
fos.close();
in.close();
}
}
}
3. Part
在servlet3.0中,加入了对上传表单的支持,Part,它继承于javax.servlet.http,用于接收表单文件(type=”file”),并且要求enctype为multipart/form-data以及method为POST。
其中有个很重要的设置,@MultipartConfig标注,它的属性有:
| 属性名 | 类型 | 允许为null | 描述 |
|---|---|---|---|
| fileSizeThershold | int | 是 | 当前数据量大于该值时,内容将被写入tmp临时文件。默认空则全部生成临时文件 |
| location | String | 是 | 存放生成文件的地址 |
| maxFileSize | long | 是 | 允许上传的文件最大值,默认为-1,表示没有限制 |
| maxRequestSize | long | 是 | 针对 multipart/form-data 请求的最大数量,默认为-1,表示没有限制 |
最常用的莫过与location和fileSizeThershold,尤其是location,忒省事了。
Part提供的方法不多,有以下方法:
| 方法名 | 返回值 | 描述 |
|---|---|---|
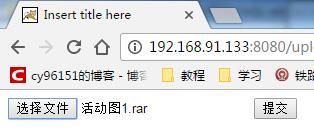
| getContentType() | String | 获取上传文件的文件类型,也就是下图中的text/plain |
| getHeader(String headerName) | String | 下图中的headerName只有Content-Disposition和Content-Type,根据headerName获取值,其中有很重要的文件名 |
| getHeaderNames() | Collection<String> | 获取所有headerName的字符串集合 |
| getHeaders(String headerName) | Collection<String> | 获取headerName值的集合,这里只有一个,所以这个方法一般用不上 |
| getInputStream() | InputStream | 获取字节流,可以采用传统方式使用IO输出文件,但是这里有更好的方法 |
| getName() | String | 就是下图的name=”upload1”,这是input file的name值 |
| getSize() | long | 获取文件大小,单位为字节 |
| write(String fileName) | void | 将文件保存到标注里location的路径里,以fileName命名文件 |
参考值:
下面上代码:
import java.io.IOException;
import java.util.Collection;
import javax.servlet.ServletException;
import javax.servlet.annotation.MultipartConfig;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.Part;
/**
* Servlet implementation class PartUpload
*/
@MultipartConfig(location = "e:/", fileSizeThreshold = 1024 * 1024 * 10) // 保存到e盘,设置文件大小超过10M就生成缓存文件
@WebServlet("/PartUpload")
public class PartUpload extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
Collection<Part> parts = request.getParts(); // Parts()的功能就是获取一个Part的集合,用于多文件上传
for (Part part : parts) {
/**
* 具体说明见上表
* String name=part.getName();
* String contentType=part.getContentType();
* Collection <String> headerNames=part.getHeaderNames();
* Collection <String> headers=part.getHeaders("Content-Disposition");
* long size=part.getSize();
* InputStream in = part.getInputStream();
*/
String header = part.getHeader("Content-Disposition");
String fileName = getFileName(header);
part.write(fileName);
}
}
String getFileName(String header) {
String fileName = header.substring(header.indexOf("filename=\"") + 10, header.lastIndexOf("\"")); // 截取字符串,获得文件名
int index = fileName.lastIndexOf('\\');// 针对IE浏览器,filename的值为路径+文件名
if (index != -1)
fileName = fileName.substring(index + 1);
return fileName;
}
}














 5474
5474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









