










目录
2.1、为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢(面试蘑菇街问过)?
问题1:为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
问题2:为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
问题3:为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
2.4、为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
2.5、为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
2.6、如果想要在HashMap 中将key存储为Object类型,需要为这个Object类实现哪些方法?
3.1 HashMap、Hashtable、ConccurentHashMap 三者的区别
3.3 为啥Hashtable和ConcurrentHashMap 是不允许键或值为 null 的,HashMap 的键值则都可以为 null?
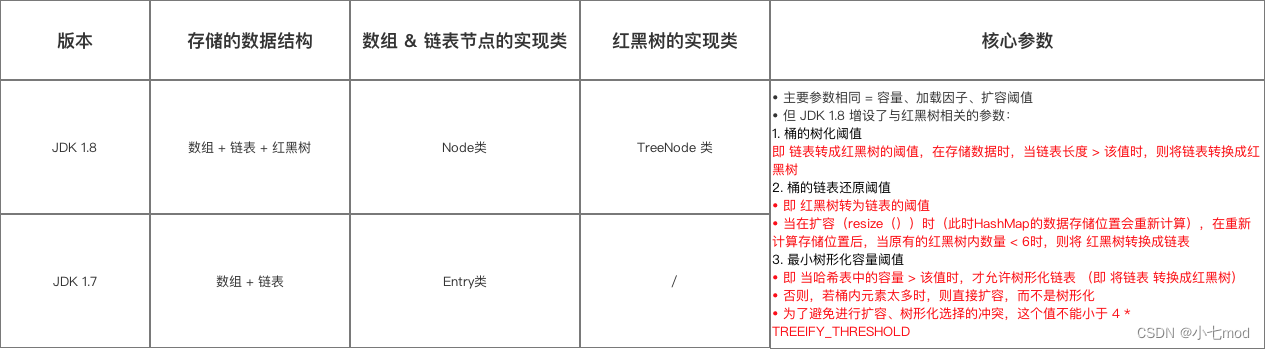
一、JDK1.7和JDK1.8HashMap的区别
1.1 数据结构上的区别
JDK1.7的时候使用的是数组+单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)
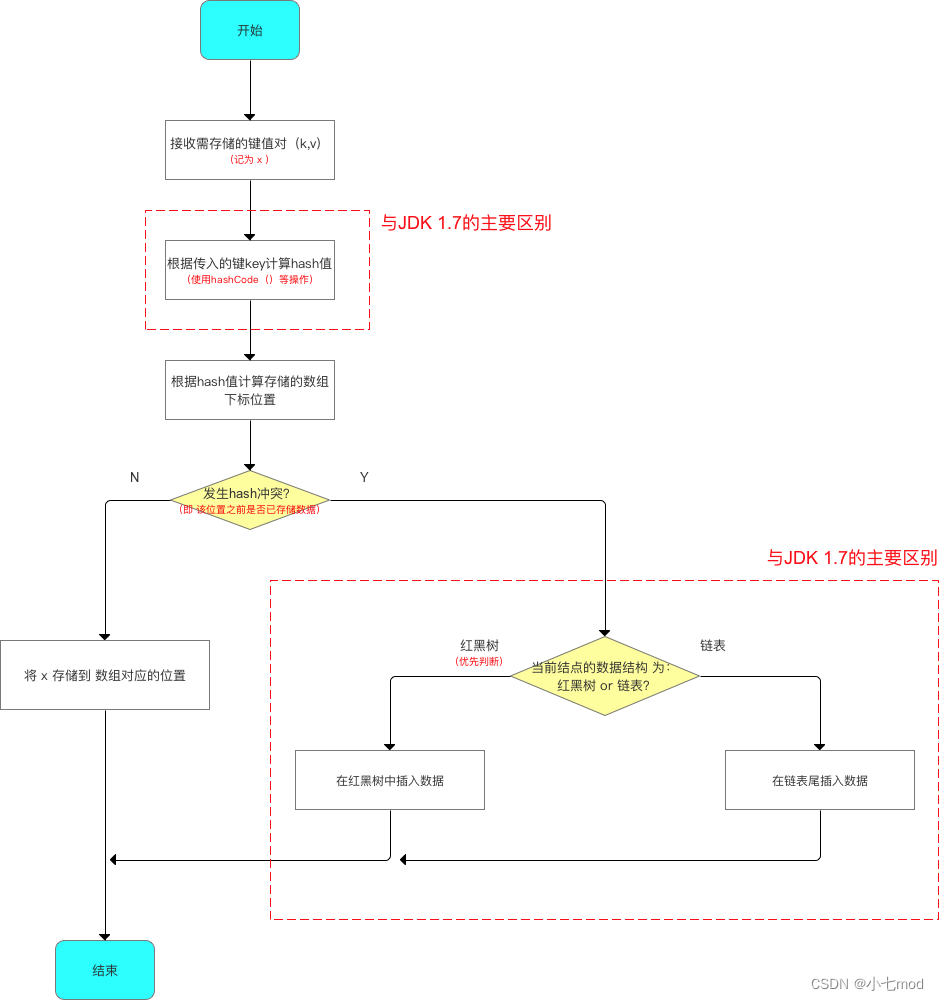
1.2 插入数据时的区别
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现链表逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现链表逆序且链表死循环的问题。

流程区别图:
1.3 计算哈希值方法的区别
JDK1.7

JDK1.8
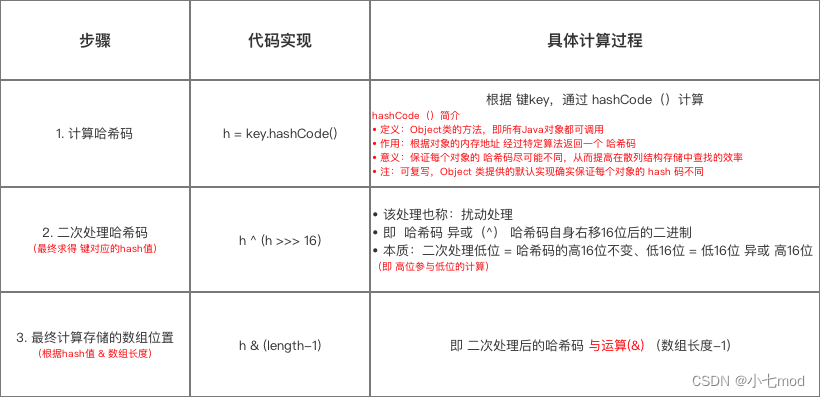
在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
1.4 扩容操作的区别
扩容后数据存储位置的计算方式也不一样:
- 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)。
- 而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值(原数组大小)= JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
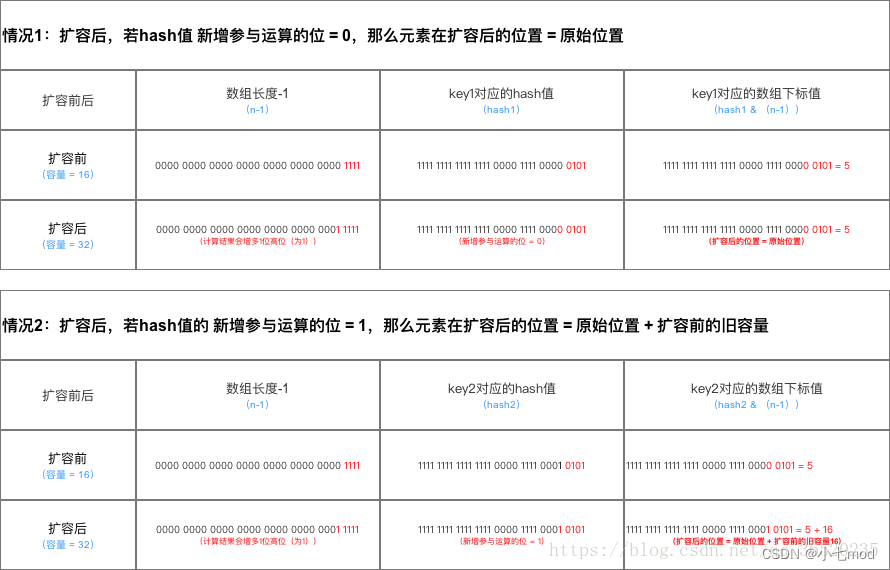

流程区别图:
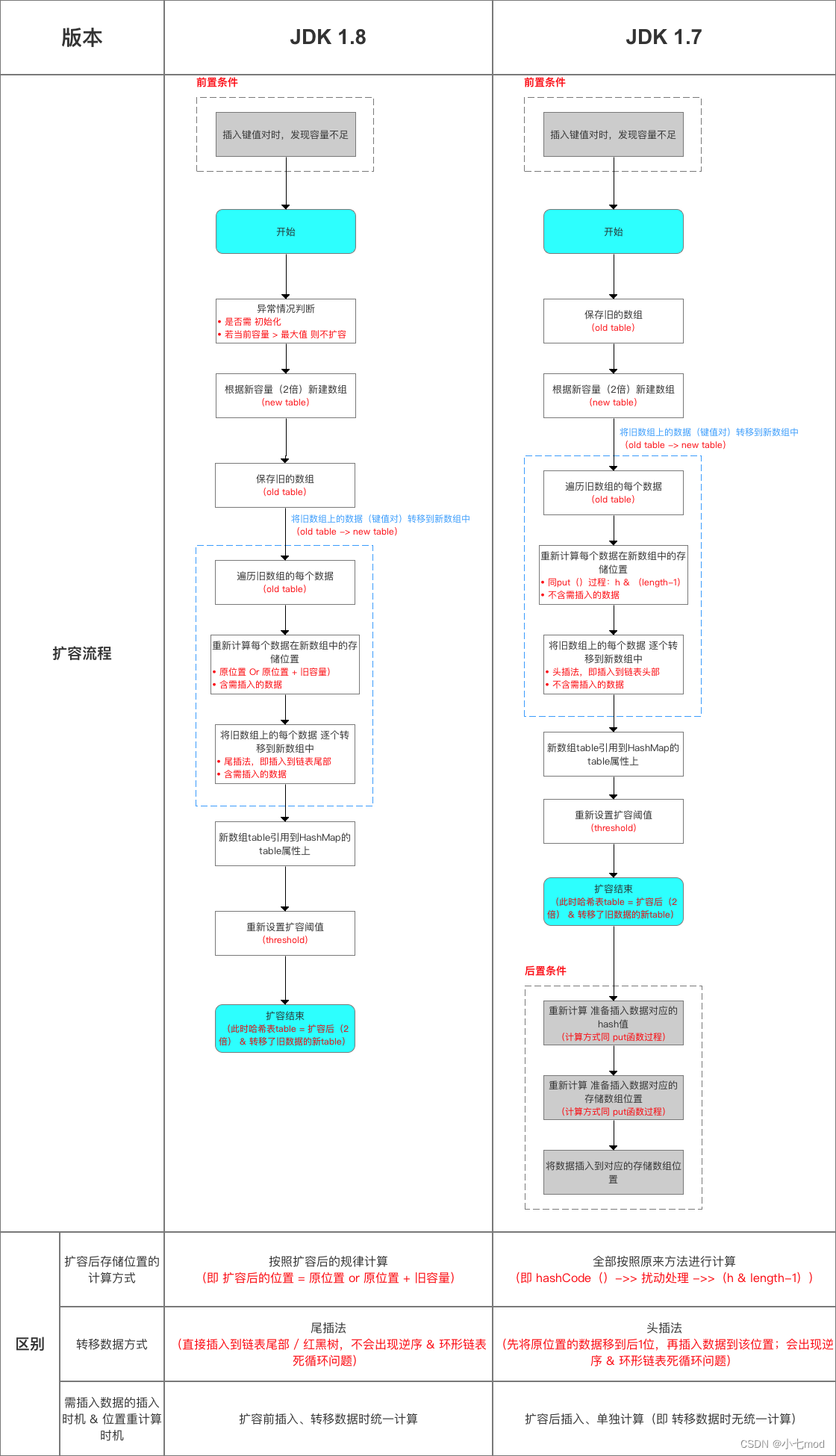
1.4 插入和扩容之间顺序的区别
在JDK1.7的时候是先扩容后插入的,不过在扩容前会先判断插入节点是否存在Hash冲突,如果有Hash冲突才会扩容,如果没有Hash冲突,其要插入的数组桶是空的,就会直接插入,不会触发扩容,并不会导致无效扩容的情况。扩容完之后再去计算要插入的元素应该放在新数组的什么位置,新插入节点在新数组中的新位置是单独计算的,但是扩容时存在旧数组中的原有节点在新数组中的位置都是统一计算的。但是在1.8的时候是先插入再扩容的,插入完了之后,再去判断是否达到了扩容阈值,来决定是否扩容。是统一将旧数组中的所有节点转移到新数组的对应位置中,每个节点在新数组中的位置是统一计算的。
JDK1.7源码:
public V put(K key, V value) {
// 1. 若 哈希表未初始化(即 table为空)
// 则使用构造函数进行初始化 数组table
if (table == EMPTY_TABLE) {
// 分配数组空间
// 入参为threshold,此时threshold为initialCapacity initialCapacity可以是构造方法中传入的大小,如果构造方法没有指定HashMap容量大小,则使用默认值1<<4(=16)
inflateTable(threshold);
}
// 2. 判断key是否为空值null
// 2.1 若key == null,则将该键-值 存放到数组table 中的第1个位置,即table [0]
// (本质:key = Null时,hash值 = 0,故存放到table[0]中)
// 该位置永远只有1个value,新传进来的value会覆盖旧的value
if (key == null)
return putForNullKey(value);
// 2.2 若 key ≠ null,则计算存放数组 table 中的位置(下标、索引)
// a. 根据键值key计算hash值
int hash = hash(key);
// b. 根据hash值 最终获得 key对应存放的数组Table中位置
int i = indexFor(hash, table.length);
// 3. 判断该key对应的值是否已存在(通过遍历 以该数组元素为头结点的链表 逐个判断)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
// 3.1 若该key已存在(即 key-value已存在 ),则用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
// 调用value的回调函数,该函数为空实现
e.recordAccess(this);
return oldValue;
}
}
// 结构性修改,记录HashMap被修改的次数。保证并发访问时,若HashMap内部结构发生变化,快速响应失败
modCount++;
//========================如果此时容器中不存在key的节点,那么就将这个键值对插入到Map容器中,下面的操作时扩容 + 插入 ================================
// 3.2 若 该key不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
return null;
}
/**
* 先扩容,再插入
*
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 1. 插入前,先判断容量是否足够
// 1.1 若不足够,并且存在hash冲突,则进行扩容(2倍)、重新计算Hash值、重新计算存储数组下标
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // a. 扩容2倍
hash = (null != key) ? hash(key) : 0; // b. 重新计算该Key对应的hash值
bucketIndex = indexFor(hash, table.length); // c. 重新计算该Key对应的hash值的存储数组下标位置
}
// 1.2 若容量足够,则创建1个新的数组元素(Entry) 并放入到数组中
createEntry(hash, key, value, bucketIndex);
}
通过源码,我们可以看出来JDK1.7是先去扩容,再去插入数据的。
JDK1.8源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//=====================插入操作==================================
// tab用来临时存放数组table引用 p用来临时存放数组table桶中的bin
// n存放HashMap容量大小 i存放当前put进HashMap的元素在数组中的位置下标
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
// e记录当前节点 k记录key值
Node<K,V> e; K k;
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录。直接将插入的新元素覆盖旧元素
e = p;
// hash值不相等,即key不相等并且该节点为红黑树结点,将元素插入红黑树
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 为链表结点
else {
// 在链表最末插入结点(尾插法)
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个treeifyBin()方法会根据 HashMap 数组情况来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少执行效率。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 树化操作
treeifyBin(tab, hash);
// 跳出循环 此时e=null,表示没有在链表中找到与插入元素key和hash值相同的节点
break;
}
// 判断链表中结点的key值和Hash值与插入的元素的key值和Hash值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 若相等,则不用将其插入了,直接跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 当e!=null时,表示在数组桶或链表或红黑树中存在key值、hash值与插入元素相等的结点。此时就直接用原有的节点就可以了,不用插入新的元素了。此时e就代表原本就存在于HashMap中的元素
if (e != null) {
// 记录e的value,也就是旧value值
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null,则需要用新的value值对旧value值进行覆盖
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 替换旧值时会调用的方法(默认实现为空)
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改,记录HashMap被修改的次数,主要用于多线程并发时候
++modCount;
//================扩容操作==================================
// 实际大小大于阈值则扩容 ++size只有在插入新元素才会执行,如果发现HashMap中已经存在了相同key和hash的元素,就不会插入新的元素,在上面就已经执行return了,也就不会改变size大小
if (++size > threshold)
resize();
// 插入成功时会调用的方法(默认实现为空)
afterNodeInsertion(evict);
// 没有找到原有相同key和hash的元素,则直接返回Null
return null;
}通过源码我们可以知道JDK1.8是先插入,后扩容
二、常见面试问题
2.1、为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢(面试蘑菇街问过)?
JDK1.8的HashMap当挂在数组桶链表长度大于等于8的时候,就会将链表进行树化;如果挂在数组桶上的红黑树节点个数变回小于等于6时,就会再把红黑树变回链表,但是链表变成红黑树的一个前提条件就是HashMap的数组长度不能小于64,否则就只会扩容数组,而不会将链表转化为红黑树。
当挂在数组桶上的链表大于等于如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果因为某些业务原因对一个HashMap节点不停的插入、删除,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。这样中间有一个缓冲值,就能很大程度上避免这种情况。
还有一点重要的就是由于TreeNode的大小大约是常规节点的两倍,因此我们仅在容器包含足够多的节点以保证使用时才使用红黑树结构,当节点数量变得太小(由于移除或调整大小)时,它们会被转换回普通的Node节点,容器中节点分布在hash桶中的频率遵循泊松分布,根据数据统计,挂在数组桶上的链表的长度超过8的概率非常非常小(也就是因hash冲突放置在同一个数组桶上的节点数量超过8个的概率比较小)。所以作者应该是根据概率统计而选择了8作为树化阀值。
//HashMap源码的注解中解释的原因
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
*因为树节点的大小大约是常规节点的两倍,所以我们
*仅当容器包含足够的节点以保证使用时才使用它们
*(参见TREEIFY_THRESHOLD)。当它们变得太小时(由于
*移除或调整大小)它们被转换回普通箱。在里面
*使用分布良好的用户哈希代码、树状容器
*很少使用。理想情况下,在随机哈希码下
*箱中的节点遵循泊松分布
* (http://en.wikipedia.org/wiki/Poisson_distribution)带着
*默认调整大小的参数平均约为0.5
*阈值为0.75,但由于
*调整粒度。忽略方差,则为预期值
*列表大小k的出现次数为(exp(-0.5)*pow(0.5,k)/
*阶乘(k))。第一个值是:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*更多:不到一千万分之一
通俗点讲就是put进去的key进行计算hashCode时 只要选择计算hash值的算法足够好(hash碰撞率极低),从而遵循泊松分布,使得桶中挂载的bin的数量等于8的概率非常小,从而转换为红黑树的概率也小,反之则概率大。
所以,之所以选择8,不是拍脑袋决定的,而是根据概率统计决定的。由此可见,发展30年的Java每一项改动和优化都是非常严谨和科学的。
之所以变成6的时候会再变回链表,是为了做一个缓冲,如果7就变得话,那么会变得太频繁了,所以我们留一个7作为缓冲。
2.2、三个关于JDK1.8计算存放数组下标的问题
- 为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
- 为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
- 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
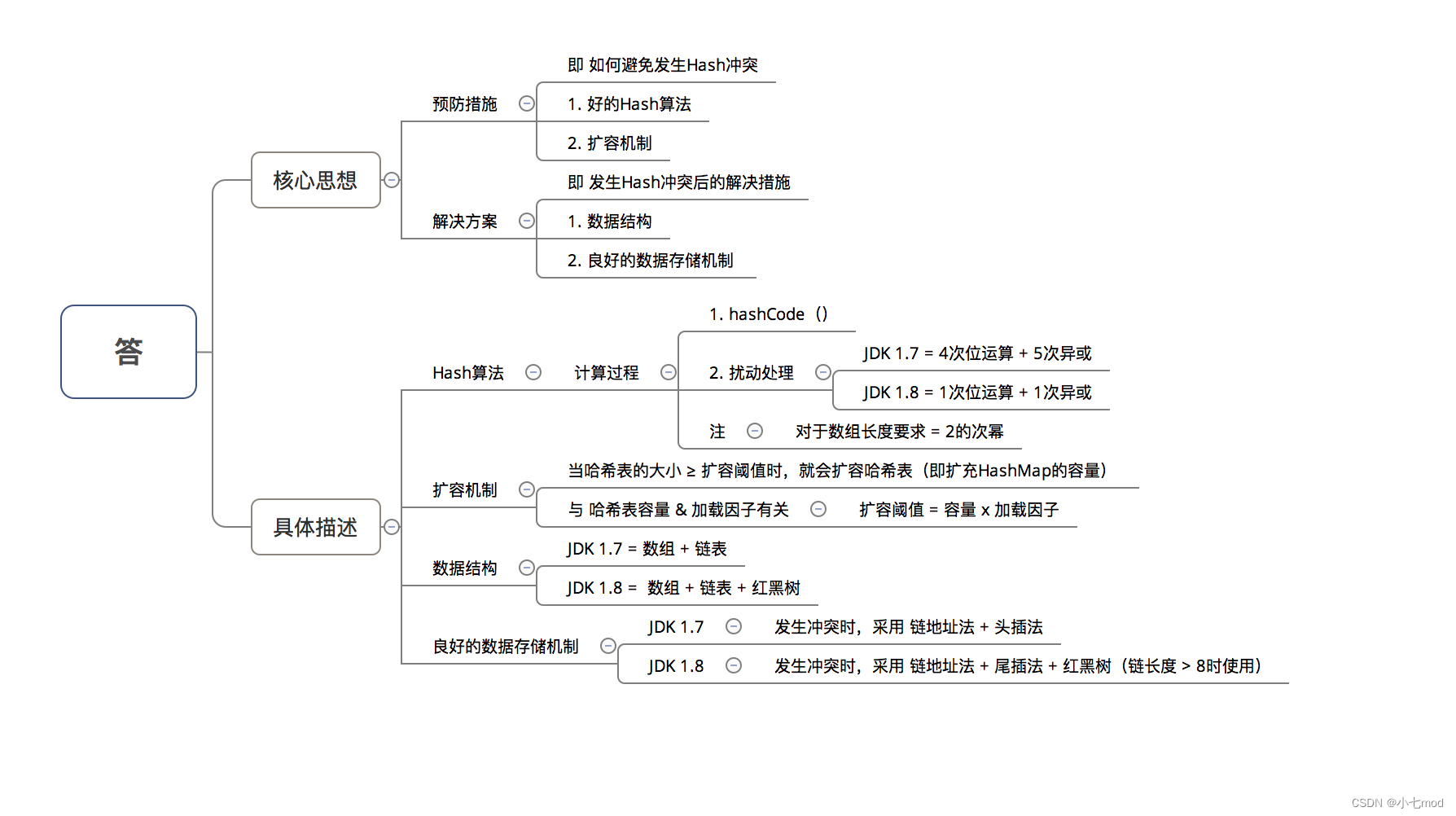
在回答这3个问题前,请大家记住一个核心思想:
所有处理的根本目的,都是为了提高 存储key-value的数组下标位置 的随机性 & 分布均匀性,尽量避免出现hash值冲突。即:对于不同key,存储的数组下标位置要尽可能不一样
问题1:为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
结论:容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置
原因描述:

为了解决 “哈希码与数组大小范围不匹配” 的问题,HashMap给出了解决方案:哈希码 与运算(&) (数组长度-1),即问题2
问题2:为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
结论:根据HashMap的容量大小(数组长度),按需取 哈希码一定数量的低位 作为存储的数组下标位置,从而 解决 “哈希码与数组大小范围不匹配” 的问题
具体解决方案描述:
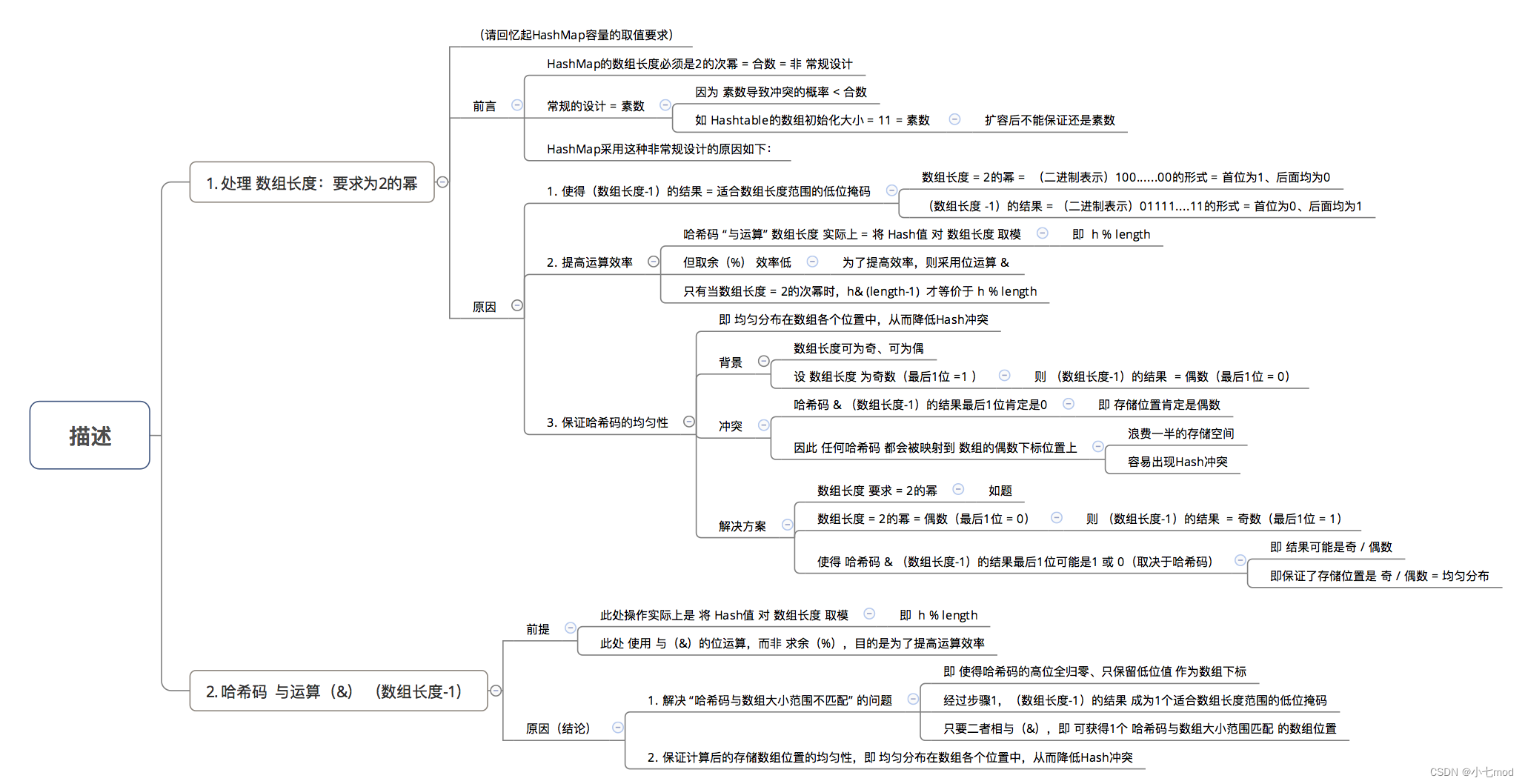
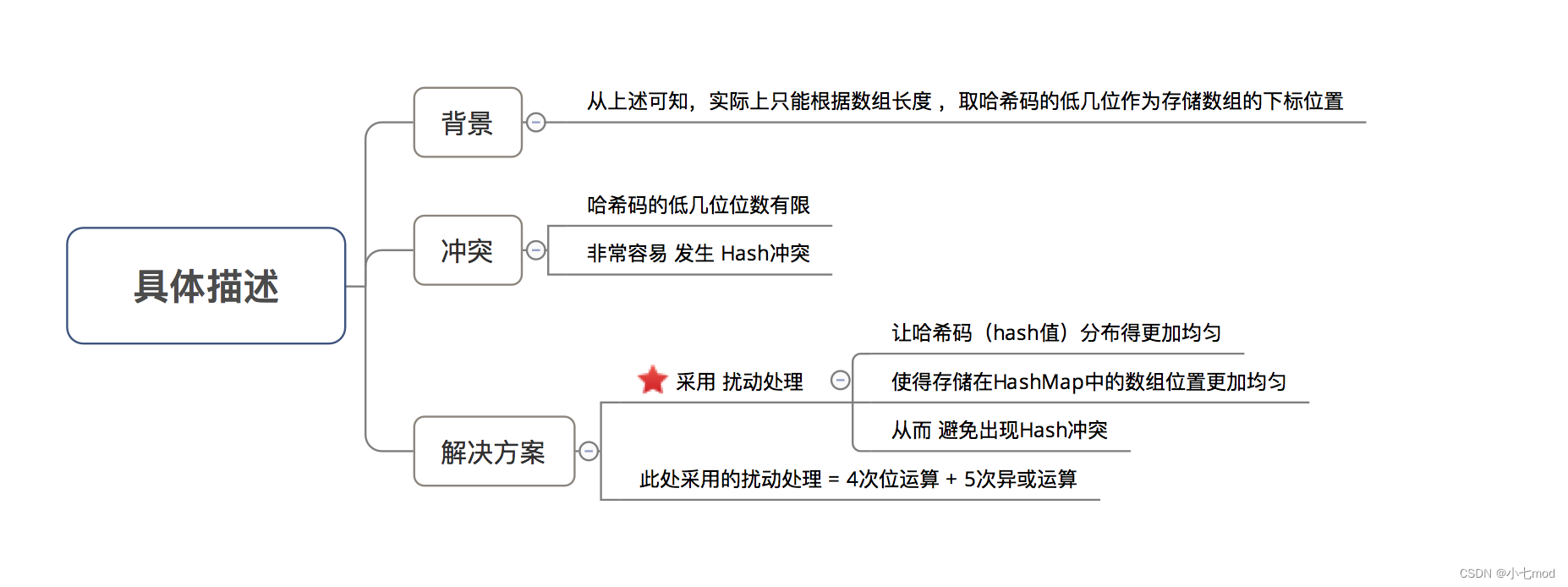
问题3:为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
结论:加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突
具体描述:
2.3、哈希表如何解决Hash冲突
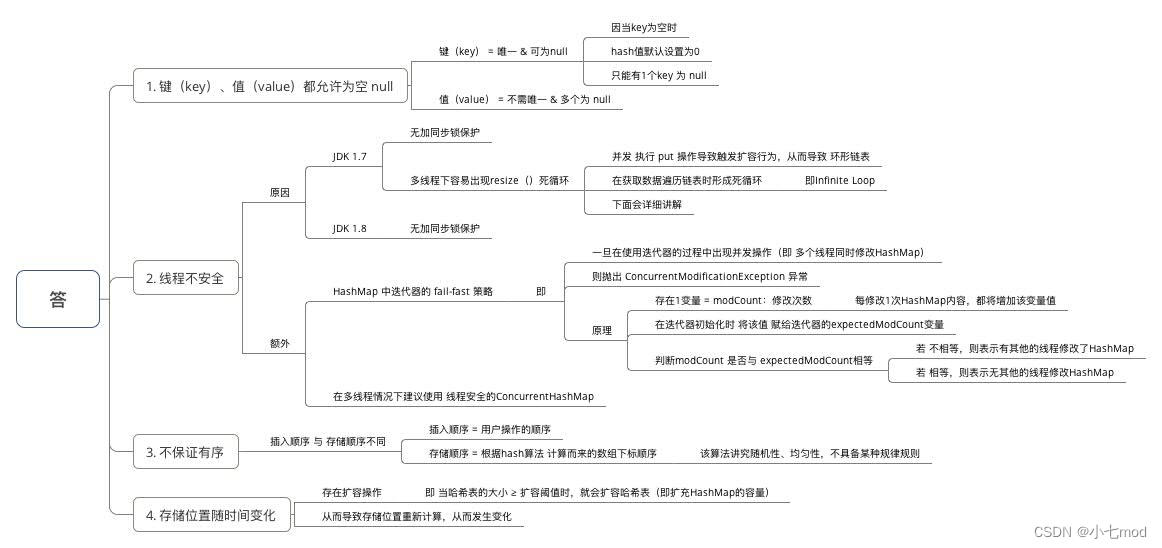
2.4、为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
2.5、为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键

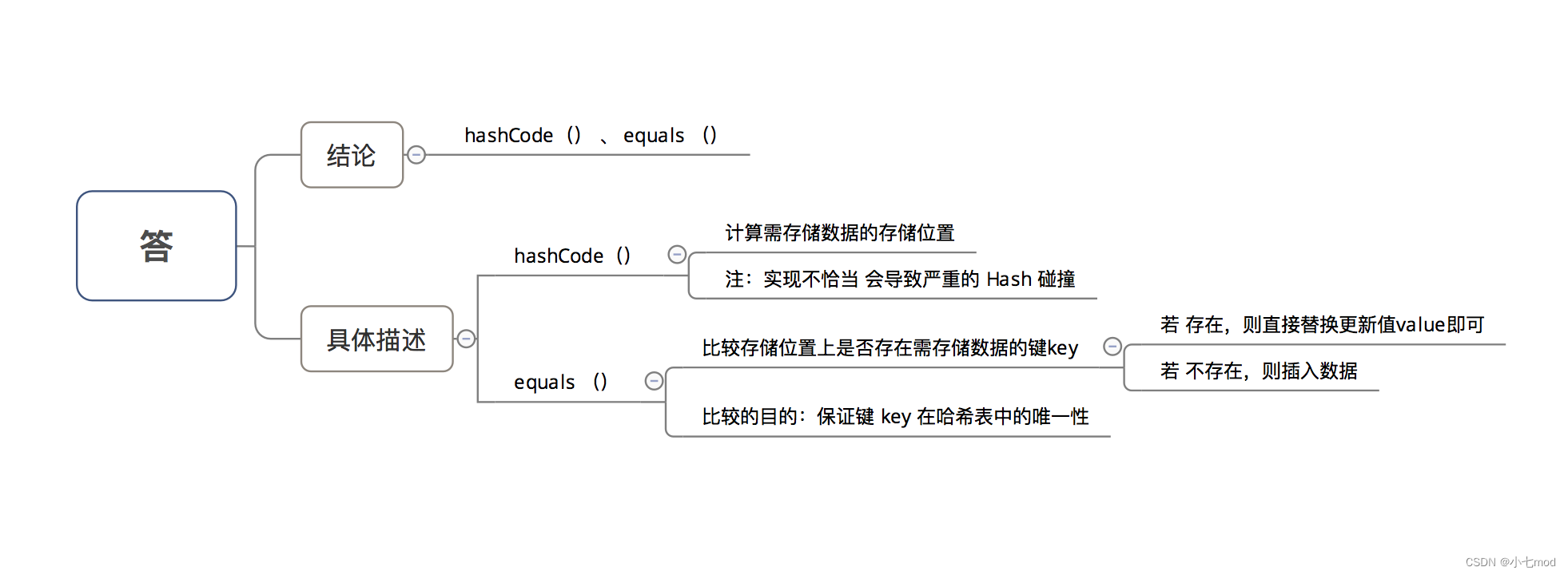
2.6、如果想要在HashMap 中将key存储为Object类型,需要为这个Object类实现哪些方法?
不实现这些也可以,但是如果直接用默认的哪些,可能会导致出现大量的Hash碰撞和无法精准地判断容器中的key是否相同。所以最好还是针对自己的业务场景来实现一下这两个方法。
2.7 HashMap中初始化大小为什么是16?
先看一下这个16是怎么来的,下面是源码中HashMap初始化容量大小的常量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16这里使用了位运算,为啥不直接16嘞?这里主要是位运算的性能好,能直接得到二进制的数字,不需要再进制转换了。为啥位运算性能就好,那是因为位运算人家直接操作内存,不需要进行进制转换,计算机是以二进制的形式做数据存储,所以这样效率更高。
首先我们看HashMap的源码可知当新put一个数据时会进行计算位于table数组(也称为桶)中的下标,通过将计算出来地Hash值与(数组长度 - 1)进行与运算得到下标,HashMap每次扩容都是以 2的整数次幂进行扩容
比如: 假设计算得到的Hash值的二进制为 11 0001 0010 0110 0010
假设初始化大小为16
16 - 1 = 15,15转化为二进制: 1111
index : 11 0001 0010 0110 0010 & 1111 =0010 为 3
假设初始化大小为10
10转化为二进制: 1010
index: 11 0001 0010 0110 0010 & 1010=0010 为 3
因为是将二进制进行按位与,(16-1) 是 1111,末位是1,这样就可以保证按位取与后的结果的最后一位数,既可以是0也可以是1,进而保证计算后的index既可以是奇数也可以是偶数,这样就能保证计算出更多不同的数,减少相同碰撞的概率。但是如果初始化大小是10,二进制末位是0,那么不管和任何数取与,最后一位二进制只能是0,这样就只能计算出偶数,数据相同碰撞的概率就更大了。而且只要传进来的key足够分散和均匀那么按位与的时候获得的index就会减少重复,这样也就减少了hash的碰撞以及HashMap的查询效率。
上面这一段也解释为什么要将容量大小减一,然后再去做按位取与的操作。总之就是首先用(n-1)是为了实现与取模运算相同的效果,除此之外就是为了降低碰撞概率。
分析到这里,我们也就知道了为什么初始容量为16,并且容量大小永远都是2的整数次幂了。
那么到了这里你也许会问? 那么既然16可以,是不是只要是2的整数次幂就可以呢?
答案是肯定的。但那为什么不是8、4呢? 因为是8或者4的话很容易导致map扩容影响性能,如果分配的太大的话又会浪费资源,所以就规定使用16作为初始大小
总结:
- 减少hash碰撞
- 提高map查询效率
- 分配过小防止频繁扩容
- 分配过大浪费资源
三、补充
3.1 HashMap、Hashtable、ConccurentHashMap 三者的区别
- HashMap线程不安全,数组+链表+红黑树
- Hashtable线程安全,锁住整个对象,数组+链表
- ConccurentHashMap 线程安全,CAS+同步锁、数组+链表+红黑树
- HashMap的key,value均可为null,其他两个不行。
3.2 HashMap和Hashtable的区别
1、线程安全
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全。
Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合。
Note:Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的HashMap实例,简单的说就是Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理。
2、针对null的不同
HashMap可以使用null作为key,而Hashtable则不允许null作为key
虽说HashMap支持null值作为key,不过建议还是尽量避免这样使用,因为一旦不小心使用了,若因此引发一些问题,排查起来很是费事。
Note:HashMap以null作为key时,总是存储在table数组的第一个节点上。
3、继承结构
HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类。
4、初始容量与扩容
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
HashMap扩容时是当前容量翻倍即:capacity * 2,Hashtable扩容时是容量翻倍+1即:capacity * 2+1。
5、两者计算hash的方法不同
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
3.3 为啥Hashtable和ConcurrentHashMap 是不允许键或值为 null 的,HashMap 的键值则都可以为 null?
HashMap是允许key和value为null,它允许一个 null键,多个 null值。而 Hashtable和ConcurrentHashMap是不允许键和值为null的。
3.3.1 从源码的角度分析原因
首先,我们从源码中,找到HashMap允许key和value为null,Hashtable和ConcurrentHashMap不允许key和value为null的直接原因。
1、Hashtable
public synchronized V put(K key, V value) {
// Make sure the value is not null
// 如果value为空,直接怕抛出异常
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
// Hashtable是直接用Object类提供的hashCode()方法计算出来的哈希值,与数组长度直接取模来得到对应下表值的
// 如果key为null,则会造成null.hashCode()这样的调用,直接导致空指针异常报错
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}通过源码我们能清楚的看到,Hashtable的put操作,如果传入的value是null,就会直接抛出异常;如果传入的key是null,因为Hashtable是直接用Object的hashCode()方法计算出来哈希值,然后用哈希值直接与数组长度取模求出对应的数组下标的,所以如果key是null,就会出现null.hashCode()的情况,直接导致出现空指针异常。
2、ConcurrentHashMap
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key和value都不能为null
if (key == null || value == null) throw new NullPointerException();
...
}ConcurrentHashMap的put操作源码,也是直接就不允许传入的key和value为null,如果有null就会直接抛出异常。
3、HashMap
/**
* 该方法的作用:将传入的子Map中的全部元素逐个添加到HashMap中
* @param evict 最初构造此Map时为false,否则为true(中继到afterNodeInsertion方法)。
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
...
putVal(hash(key), key, value, false, evict);
...
}
/**
* JDK 1.8实现:将 键key 转换成 哈希码(hash值)操作 = 使用hashCode() + 1次位运算 + 1次异或运算(2次扰动)
* 1. 取hashCode值: h = key.hashCode()
* 2. 高位参与低位的运算:h ^ (h >>> 16)
*/
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
// a. 当key = null时,hash值 = 0,所以HashMap的key 可为null
// 注:对比HashTable,HashTable对key直接hashCode(),若key为null时,会抛出异常,所以HashTable的key不可为null
// b. 当key ≠ null时,则通过先计算出 key的 hashCode()(记为h),然后 对哈希码进行扰动处理: 按位 异或(^) 哈希码自身右移16位后的二进制
}
HashMap的源码中,求哈希值不是直接通过Object的hashCode()方法计算的,而是还要做一些额外的扰动处理,为了避免哈希碰撞概率。并且也没有对put操作的入参key和value做判空抛异常操作。所以HashMap是允许key和value为空的。
之所以HashMap只允许一个null键,我们可以看hash()方法源码,如果key为null,它就会将key的哈希值直接赋值为0,这样在后续计算对应数组下标时一定是0,这样所有的key值为null的数据都会被北方数组0下标上,并且新插入的数据是会直接在数组桶上覆盖掉旧数据的,也就保证了数组中只会有一个key为null的键值对。
但是HashMap允许多个null值,因为key可以是任意值,所以键值对可以放在数组的任意位置,有多少个value为null的键值对都是不会有限制的。
3.3.2 从架构设计的角度分析原因
我们从源码的角度了解到了Hashtable和ConcurrentHashMap不允许key和value为null的直接原因,但是当初为什么要这样设计呢,为什么不能和HashMap一样,允许key和value为null呢?我们将问题拆分两个小问题来分别分析,即为何不支持 null 键,以及为何不支持 null 值。
1、为何不支持 null 值?
ConcurrentHashMap:
我们先以ConcurrentHashMap为例进行讲解,给ConcurrentHashMap中插入 null (空)值会存在歧义。我们可以假设ConcurrentHashMap允许插入 null(空) 值,那么,我们取值的时候会出现两种结果:
- 值没有在集合中,所以返回的结果就是 null (空);
- 值就是 null(空),所以返回的结果就是它原本的 null(空) 值。
这就产生了歧义,出现了二义性问题。
ConcurrentHashMap 的设计本意就是为了在对线程场景下使用的,而在多线程场景下,出现了这样歧义的情况,会导致一些错误的结果。
我们用下面的示例代码举个例子,假设此时ConcurrentHashMap是可以插入空值的
ConcurrentHashMap map;
if (map.containsKey(key)) {
return map.get(key);
} else {
throw new KeyNotFoundException;
}
我们先看一下containsKey()的源码:
// 查找ConcurrentHashMap中是否存在键为key的键值对
public boolean containsKey(Object key) {
// 这里直接使用的get()方法,如果通过这个key去查找相应的value,返回的是null的话,就认为不存在
return get(key) != null;
}判断当前ConcurrentHashMap中是否存在以key为键的键值对,其实就是调用的get()方法,如果返回的是null,就返回false,不是null就返回true。ConcurrentHashMap的get()方法没有加锁。
假设此时有线程T1调用ConcurrentHashMap 的 containsKey(key) 方法,想要判断一下容器中有没有以key为键的键值对,我们假设存在这个键值对,并且这个键值对的value不为null。那么containsKey()方法就会返回true,进入到If分支中。
但是进入之后在线程T1执行return map.get(key)代码之前,另一个线程T2将这个键为key的键值对删除了。然后T1执行get(key)方法的时候,它就无法在ConcurrentHashMap容器中找到对应的键值对了,进而返回null。
这样,就出现了一个很严重的问题,上面这段代码认为如果要查询的key存在,就会返回其对应的value,如果不存在,在调用containsKey()方法的时候就会返回fasle,进而进入到了另一个else分支,抛出key不存在的异常。但是上面我们将的这种情况,明明此时容器中已经不存在以key为键的键值对了,但是最后并没有抛出异常,而是返回了一个null。我们这里假设的是ConcurrentHashMap可以插入空值,那么用户就会认为此时容器中存在以key为键的键值对,并且其对应的value为null,这样就与真实情况不符了,出现了并发错误。归结其原因,是因为存在二义性问题,返回的是null即有可能是不存在该键值对,也有可能是存在该键值对,只是value为null。
通过上面的假设分析,我们就发现如果允许ConcurrentHashMap为空的话,会出现并发错误。回到现实,现实是它并不允许key和value为空,在这种前体现,我们去套用上面的这个案例,在T2线程将容器中key对应的键值对删除后,T1线程再去执行get(key)操作,因为容器中没有这个key,就会返回null。但是ConcurrentHashMap并不允许存在value为null的情况,所以说用户在得到了返回值null的时候,唯一的原因是键不存在而不是因为值可能为null,这样就会知道此时容器中并没有键为key的键值对,这也符合事实情况,就不会出现并发错误了。不允许存在key和value为null,就不会出现二义性问题,只要是返回的null,就认为是容器中不存在该键值对,不会出现其他含义。
Hashtable:
Hashtable不允许key和value为null的原因,和ConcurrentHashMap是一样的。在并发环境下使用时,会造成歧义问题。如果允许值为null,有可能出现线程以为存在该键值对,但实际这个键值对已经被删除的情况,造成并发错误。
继续使用之前的测试案例:
Hashtable map;
if (map.containsKey(key)) {
return map.get(key);
} else {
throw new KeyNotFoundException;
}
// 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
// % tab.length 的目的是防止数据越界
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
整个分析过程和ConcurrentHashMap的分析过程是一样的,出现的并发问题也是一样的。Hashtable的所有操作方法都直接上了synchronized锁,会直接将整个类都锁上,所以会保证并发安全。但是只有在方法代码块中会加锁,执行完方法之后就会将锁释放。所以当多个线程同时对Hashtable进行操作的时候,假设如果允许存在null值,线程T1先去执行map.containsKey(key),发现存在该键值对,执行完containsKey方法后,线程T1就将锁释放了,其他线程就又可以操作该Hashtable了,在T1下去执行map.get(key)之前,线程T2将该键值对成功删除,然后T1继续执行map.get(key)取出来的value为null,此时并没有抛出KeyNotFoundException异常,所以线程T1就会认为该键值对存在,但实际上是不存在的,这就出现了并发错误。
如果不允许value为null,那么线程只要是通过get(key)方法获取到null,就知道容器中根本就不存在key的键值对,因为此时Hashtable不存在二义性问题。
HashMap:
那么HashMap允许插入 null(空) 值,难道它就不担心出现歧义吗?这是因为HashMap的设计本意就是给单线程使用的,HashMap就完全是按照认为用户只会在单线程环境下使用它而设计的,它只需要保证在单线程环境下使用不会出现按问题就可以了。
分析之前也是先看一下HashMap的源码,
get()是根据传入的key,在容器找找到对应的键值对并返回value。如果不存在这个键值对或者存在这个键值对但是value为null,这个方法都会返回null。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}get()方法本质是调用的这个方法,这个方法是传入key和hash值,然后在容器中找到对应的键值对并返回其Node对象,注意这里不是返回的value,而是返回的键值对的Node对象,所以如果HashMap中并不存在key对应的键值对,这个方法就会返回null,如果存在key对应的键值对,这个方法就会返回其对应的Node对象,就算是value为null,也是能返回Node对象,只不过对象中的value属性为Null。
final Node<K,V> getNode(int hash, Object key) {
// tab:当前map的数组,first:当前hash对应的索引位置上的节点,e:遍历过程中临时存储的节点,
// n:tab数组的长度,k:first节点的key/遍历链表时遍历到的节点e的key值
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1.对table进行校验:table不为空 && table长度大于0 &&
// hash对应的索引位置上的节点不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是不是要找的元素,比较hash值和key是否和入参的一样,如果一样,直接返回第一个节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k)))){
return first;
}
// 第一个节点不是要找的元素,
// 取出来第二个节点,并且第二个节点不为null,说明还没走到该节点链的最后
if ((e = first.next) != null) {
// 如果第一个节点是红黑树类型
if (first instanceof TreeNode){
// 调用红黑树的查找目标节点方法getTreeNode
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
}
// 前提条件:第一个节点不为null,并且也不是红黑树,而且还有下一个节点,那么该索引位置的元素类型就是链表,从第二个节点开始遍历该链表,
do {
// hash值和key值与入参一致,说明找到要查询的节点,返回节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);// e指针后移,并且下一个节点不为null则继续遍历,不为null表示没到链表最后
}
}
// 没找到返回null
return null;
}
判断HashMap中是否存在以key为键的键值对,存在就返回true,不存在就返回false,这个方法本质时调用的getNode()方法,只要是能找到对应的键值对Node对象,就证明容器中存在这个键值对。就算一个键值对的value为null,因为这里是判断键值对的Node对象是否为空,所以仍然会认为存在该键值对的。
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}通过上面的源码分析,我们发现HashMap的get()方法也是存在二义性问题的。但是HashMap设置之初就是为了在单线程环境下使用,所以只要是在单线程环境下不会出现问题,就是可以的。
我们接着用之前的测试代码,只不过此时是单线程环境,只有线程T1去执行这段代码。
HashMap map;
if (map.containsKey(key)) {
return map.get(key);
} else {
throw new KeyNotFoundException;
}
因为是在单线程环境下,就不会存在线程T1执行完map.containsKey(key),发现存在该键值对,进入到If分支中后,别的线程再将这个键值对删掉的情况。所以说只要是map.containsKey(key)判断是存在该键值对的,那么后面执行return map.get(key)的时候也肯定还是存在的,即使是返回的null值,用户也认为是该键值对的value为null。如果HashMap中不存在该键值对,在一开始判断map.containsKey(key)时就会返回false,进而进入到else分支抛出异常。我们发现,在单线程环境下,虽然HashMap也存在二义性问题,但是结合使用containsKey方法可以避免二义性,也就不会出现问题。这也进一步表明了,HashMap是一个线程不安全的对象,只能用在单线程环境下,并且在单线程使用的时候,如果想要获取指定key的键值对,应该先去通过containsKey(key)判断存不存在该键值对,存在的话再去调用get(key),这样才能避免HashMap的二义性问题。
通过上述的分析,我们就可以从设计的角度明白为什么Hashtable和ConcurrentHashMap 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。其实对于这个问题,有人就问过 ConcurrentHashMap 的作者 Doug Lea,以下是他的回答的邮件内容:
The main reason that nulls aren't allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can't be accommodated. The main one is that if map.get(key) returns null, you can't detect whether the key explicitly maps to null vs the key isn't mapped.
In a non-concurrent map, you can check this via map.contains(key),but in a concurrent one, the map might have changed between calls.Further digressing: I personally think that allowing
nulls in Maps (also Sets) is an open invitation for programs
to contain errors that remain undetected until
they break at just the wrong time. (Whether to allow nulls even
in non-concurrent Maps/Sets is one of the few design issues surrounding
Collections that Josh Bloch and I have long disagreed about.)It is very difficult to check for null keys and values
in my entire application .Would it be easier to declare somewhere
static final Object NULL = new Object();
and replace all use of nulls in uses of maps with NULL?-Doug
以上信件的主要意思是,Doug Lea 认为这样设计最主要的原因是:不容忍在并发场景下出现歧义!
也就是我们上面分析出来的歧义的问题,在并发场景下,是无法判断是键不存在,还是键对应的值为null。
2、为何不支持 null 键?
从上面的 Doug Lea 的回复可以看出,他本人和 HashMap 的作者 Josh Bloch 在设计上是存在分歧的,他认为如果在 Maps(及 Sets)中允许出现 null,会导致一些未知的异常在特殊的情况下发生。
个人认为在实现上是可以支持允许key为null的,通过上述的思路去分析,并没有发现如果允许key为null会导致出现错误,因为get操作都是去获取value,所以一般都是因为value的值而导致二义性问题的。但是作者的设计风格是想尽量避免不必要的隐藏异常,进而也就不允许key为null了。
3.3.3 替代方案
如果你确实需要在 ConcurrentHashMap 中使用 null 怎么办呢?
可以使用一个特殊的静态空对象来代替 null。
public static final Object NULL = new Object();
3.3.4 总结
下面我们就来总结一下。
ConcurrentHashma是p线程安全用来做支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。
Hashtable同理,它也是线程安全用来做支持并发的,Hashtable 采用了安全失败机制(fail-safe),导致当前得到的数据不一定是集合最新的数据。如果使用null值,就不能判断到底是映射的value是null,还是因为没有找到对应的key而为空,因为在多线程环境下,无法通过调用contain(key)来对key是否存在做判断,在多线程情况下,即便此刻你能通过contains(key)知晓了是否包含null,下一步当你使用这个结果去做一些事情时可能其他并发线程已经改变了这种状态。
而HashMap是非并发的,它是在单线程环境下使用的,不会存在一个线程操作该HashMap时,其他的线程将该HashMap修改的情况,所以可以通过contains(key)来做判断是否存在这个键值对,从而做相应的处理。而支持并发的Map在调用m.contains(key)和m.get(key)时,这两个时间点的m很可能已经不同了。
相关文章:【Java集合】HashMap系列(一)——底层数据结构分析
【Java集合】HashMap系列(二)——底层源码分析
【Java集合】HashMap系列(三)——TreeNode内部类源码分析
【Java集合】HashMap系列(四)——JDK1.7和JDK1.8中的并发问题的分析
【Java集合】一文快速了解HashMap底层原理
【数据结构】史上最好理解的红黑树讲解,让你彻底搞懂红黑树
参考资料:https://blog.csdn.net/carson_ho/article/details/79373026















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









