







众所周知,互联网 "三高" 架构: 高并发,高可用,高可扩展,导致了必然需要线程池来处理高并发请求。而管理线程最好的工具,就是线程池。今天,我就和大家分享一下JDK中的线程池: ThreadPoolExecutor 。
本文会从以下几个方面来介绍线程池
- 1. 构造函数 中 变量介绍
- 2. 线程池状态
- 3. ctl变量介绍
- 4. 工作流程和对应源码,包括 executor 方法解析 和 核心工作类 Worker
一、 构造方法中的参数
new ThreadPoolExecutor(
int corePoolSize, //核心工作线程数
int maximumPoolSize, // 最大工作线程数
longkeepAliveTime, // 超过核心线程数的线程存活时间
TimeUnit timeUnit,
BlockingQueue<Runnable> workQueue, // 工作队列,只有当工作队列满了之后,并且还有任务要加入时,才会创建多于核心工作线程的线程
ThreadFactory threadFactory, // 创建线程的工厂
RejectedExecutionHandler handler // 拒绝策略,当工作队列满了,并且最大线程也满了后,再来任务时候的拒绝策略
)注1:只有当工作队列满了以后,并且还有任务要加入时,才会创建多余核心线程数的线程。因此,当 工作队列为无界队列时,不会触发创建超过核心线程数的事件。
注2:可以自定义 RejectedExecutionHandler, 只需要 实现 RejectedExecutionHandler 接口就可以,该接口只有一个方法:
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
例如:
// 当工作队列满后,并且工作线程也是满的时,会使用调用者自身来调用这个方法
public static class CallerRunsPolicy implements RejectedExecutionHandler {
// 构造函数
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
二、线程池状态
线程池总共有5个不同的状态,分别为:
- RUNNING: 可以接受新的任务并且在处理队列中的任务
- SHUTDOWN: 不再接受新任务,但是依然在处理队列中已有的任务
- STOP: 不再接受新任务,不再处理队列中已有任务,立即打断正在执行的任务
- TIDYING: 当所有任务都终止,工作线程计数器为0时候的状态,这时会调用 terminated() 钩子方法
- TERMINATED: 当 terminated() 方法执行结束
整体的状态转换图如 图2.1 所示。
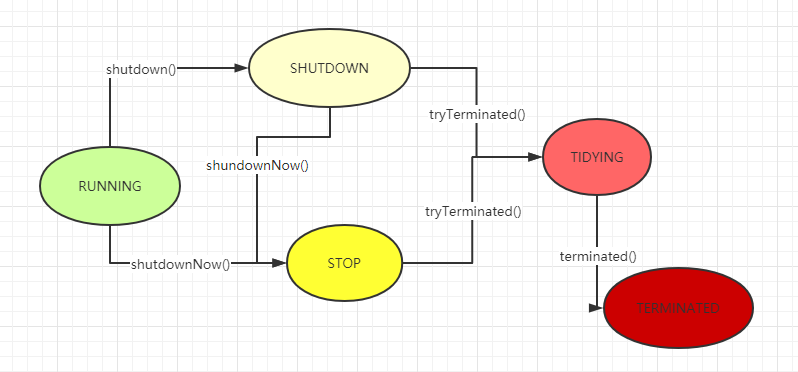
图2.1 线程池状态转换
三、ctl 变量
ThreadPoolExecutor 中有一个非常非常重要的变量: ctl 。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));ctl,是线程池的状态控制变量,保存着两个重要指标:
- workerCount: 工作线程的个数,由 ctl 的低29位保存
- runState: 线程池状态,由 ctl 的高3位保存
四、工作流程和对应源码
- 线程池的核心工作流程
使用线程池提交线程时,一般使用
executor.execute(r);因此,我们从 入口方法 execute 来分析线程池的工作流程。如图3.1所示,为一个简要的线程池的工作流程。可以看到,核心的任务调度方法为 addWorker 方法。
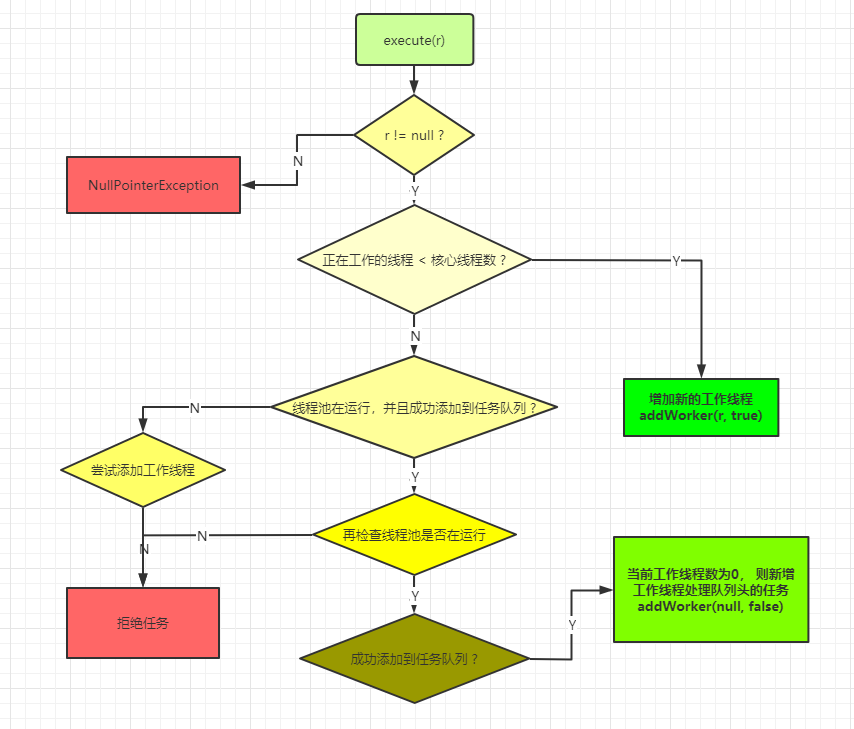
图3.1 线程池 execute 工作流程图
- execute源码解析
public void execute(Runnable command) {
// 分为3步
// 1. 如果 当前工作线程个数 < 核心线程数 则
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2. 线程池在运行,并且成功将任务添加到队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再检查时 线程池不在运行,则拒绝
if (! isRunning(recheck) && remove(command))
reject(command);
// 3. 否则添加任务到任务队列
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}可以看到,execute的核心方法是 调用 addWorker 方法。接下来分析下 addWorker 的源码。
private boolean addWorker(Runnable firstTask, boolean core) {
// 两步工作
// 1. 循环 cas,将线程池中的线程数 + 1;失败则重试
// 之前会先判断
// 1) 线程池的运行状态以及队列是否为空
// ...... 省略前面的循环
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 2)判断 线程数是否超过,超过则不能再添加
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 使用 CAS,将线程池中线程数 + 1
compareAndIncrementWorkerCount(c);
// 2. 新建线程,并加入到 线程池的 workers 中
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread; // 得到worker中的工作线程: getThreadFactory().newThread(this)
// ...... 省略中间判断
t.start(); // 启动工作线程
workerStarted = true;
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
- 核心工作类 Worker
Worker 是 ThreadPoolExecutor 的内部类,ThreadPoolExecutor通过创建 Worker来执行任务。接下来来简单分析下 Worker 类。
Worker 继承 AQS,实现 Runnable接口。图3.2 为 Worker的类图。 AQS,抽象队列同步器,是实现锁的基础组件,我们以后再讲解。现在先集中在 Worker上。
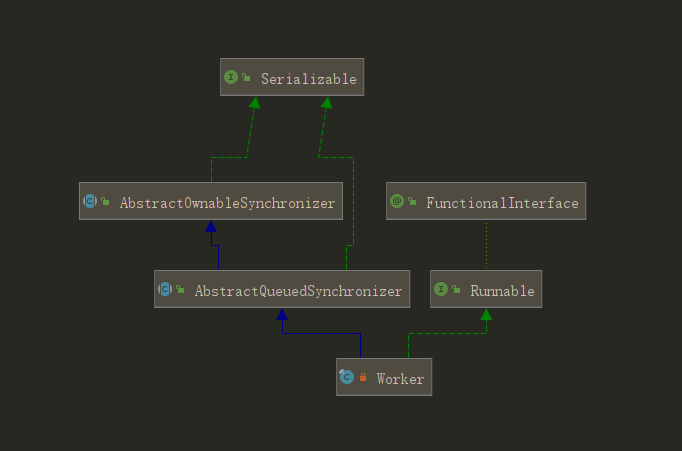
图3.2 Worker类图
Worker 的成员变量和主要方法有:
final Thread thread; // 这个worker自己的线程,通过线程工厂创建
Runnable firstTask; // 任务
volatile long completedTasks; // 已经完成的任务数量
// 构造函数
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
// 调度工作线程的核心逻辑
public void run() {
runWorker(this); // 不停的从队列中获取任务,然后执行
}
五、总结
以上就是 ThreadPoolExecutor 的流程和源码,希望大家和我多多讨论,也指出我的错误。
参考资料:
[1] jdk1.8 源码
[2] Java异步编程实战
[3] 美团博客: Java线程池实现原理及其在美团业务中的实践
( https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html )














 3935
3935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









