







15.1-MySQL入门-ydl-笔记
文章目录
第一章 MySQL数据库
一、数据库的概念
-
数据库是【按照数据结构来组织、存储和管理数据的仓库】。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
-
数据对于公司来说是最宝贵的财富之一,而程序员的工作就是对数据的管理,包括运算、流转、存储、展示等,数据库的最重要的功能就是【存储数据】,绝大部分的数据需要进行持久化,长期保存,而数据库就可以很好的帮助我们完成这个工作。
二、MySQL介绍
-
MySQL是一个【关系型数据库管理系统】,由瑞典【MySQL AB】公司开发,属于 【Oracle】旗下产品。MySQL 是最流行的【关系型数据库管理系统】之一,在 【WEB】应用方面,MySQL是最好的 【RDBMS】 (Relational Database Management System,关系数据库管理系统) 应用软件之一。
-
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
-
MySQL所使用的 【SQL 语言是】用于访问【数据库】的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是【开放源码】这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
三、MySQL安装
1. 下载
进入网址:https://dev.mysql.com/downloads/mysql/



2.开始安装




















3.配置环境变量







4. 更改默认编码格式 以免出现中文乱码
第一步:找到my.ini文件

第二步:大概66行添加以下内容
default-character-set=utf8

第三步:大概77行添加以下内容
character-set-server=utf8
collation-server=utf8_general_ci
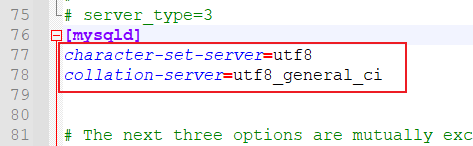
第四步:重启mysql服务

第五步:查看是否修改成功 从结果可以看出修改成功!


四、安装navicat
注意:激活前务必断开网络
第一步:先安装软件 激活前务必断开网络

第二步:安装过程直接下一步可以更换路径

第三步:完成安装 注意:安装完成后先不要运行该软件

第四步:运行补丁

第五步:直接点击path 选择navicat安装路径即可

第六步:随便输入一个用户名,直接打开navicat程序,不要关闭补丁

第七步:选择注册 (注意断开电脑连网)

第八步:创建第一个许可证

第九步:点击激活,因为网络断开,我们选择手动激活

第十步:创建第二个许可证,步骤看图

第十一步:激活成功

第十二步:


五、基本概念
1.数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。在mysql中可以创建多个数据库,一个数据库可以管理很多张表。
有个很形象的对比,例如execl中的一个execl文件就是一个数据库,一个sheet页就是一张表,表里边可以有所需要的数据:

我们可以在登陆 MySQL 服务后,
使用 create 命令创建数据库,语法如下,两条sql等效:
CREATE DATABASE 数据库名;
CREATE SCHEMA 数据库名
查看所有数据库:
SHOW DATABASES;
使用数据库:
USE 数据库名;
2.
表(TABLE)是数据库中用来存储数据的对象,是有结构的数据的集合,是整个数据库系统的基础。
第二章 SQL
SQL是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统
一、SQL语句分类
-
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
-
DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。功能:创建、删除、修改库和表结构。
-
DML(Data Manipulation Language):数据操作语言,用来定义数据库记录:增、删、改表记录。
-
DQL(Data Query Language):数据查询语言,用来查询记录。也是本章学习的重点
二、DCL(数据控制语言)语法
该语言用来定义【访问权限和安全级别】,理解即可,直接使用命令控制权限的场景不多,更多情况是使用图形化界面进行操作。
mysql中的权限无非是针对不同的用户而言,不同的用户的权限提现在以下几点:可否链接mysql服务 、可否访问数据库 、可否访问某张数据库表 、可否对表进行一些操作等
1、创建用户
创建一个用户,该用户只能在指定ip地址上登录mysql:
create user 用户名@IP地址 identified by ‘密码’;
创建一个用户,该用户可以在任意ip地址上登录mysql:
create user 'ydl'@'%' identified by 'root';
修改密码:
-- 5.7版本需要使用password对密码进行加密
set password for zn@'%' = password('newpwd');
-- 8.0直接赋值新的密码即可
set password for zn@'%' = 'newpwd';
如果直接修改表,也是可以创建用户修改密码的,【mysql数据库下的user表】但是通过修改数据库创建用户,修改密码,都需要刷新权限:
flush privileges;
2、给用户授权
给【指定用户】在【指定数据库】上赋予【指定权限】,权限有很多,列举几个常用的:
- create:可以常见数据库
- select:可以查询数据
- delete:可以删除数据
- update:可以更新数据
- insert:可以插入数据
-- 语法:`grant 权限1,…,权限n on 数据库.* to 用户名@IP地址;
grant all on `ydlclass`.`user` to 'ydl'@'%';
grant select,insert,update,delete,create on `ydlclass`.`user` to 'ydl'@'%';
3、撤销授权
撤销【指定用户】在【指定数据库】上的【指定权限】:
-- 语法:revoke 权限1,…,权限n on 数据库.* from 用户名@ ip地址;
revoke all on `ydlclass`.`user` from 'ydl'@'%';
revoke select,insert,update,delete,create on `ydlclass`.`user` from 'ydl'@'%';
4、查看权限
查看指定用户的权限:
-- 语法:show grants for 用户名@ip地址;
show grants for 'ydl'@'%';
5、删除用户
-- 语法:drop user 用户名@ip地址;
drop user 'ydl'@'%';
三、DCL(数据定义语言)语法
DDL主要是用在定义或改变表(TABLE)的结构,主要的命令有CREATE、ALTER、DROP等:
1、创建表的基本语法
create table 表名 (
字段名1(列名) 类型(宽度) 约束条件,
字段名2 类型(宽度) 约束条件,
字段名3 类型(宽度) 约束条件,
.......
);
在关系型数据库中,我们需要设定表名和列名,同时需要指定
2、常用的数据类型
整型
| MySQL数据类型 | 含义(有符号) |
|---|---|
| tinyint | 1字节,范围(-128~127) |
| smallint | 2字节,范围(-32768~32767) |
| mediumint | 3字节,范围(-8388608~8388607) |
| int | 4字节,范围(-2147483648~2147483647) |
| bigint | 8字节,范围(±9.22*10的18次方) |
在整形中我们默认使用的都是【有符号】的,当然了,我们也可以加上unsigned关键字,定义成无符号的类型,那么对应的取值范围就会发生改变:
比如:tinyint unsigned的取值范围为0~255,
宽度n的作用需要配合zerofill进行使用: 如:int(4) UNSIGNED zerofill 查询结果: 0001 0002 1000
浮点型
| MySQL数据类型 | 含义 |
|---|---|
| float(m, d) | 4字节,单精度浮点型,m总长度,d小数位 |
| double(m, d) | 8字节,双精度浮点型,m总长度,d小数位 |
| decimal(m, d) | decimal是存储为字符串的浮点数,对应我们java的Bigdecimal |
字符串数据类型
| MySQL数据类型 | 含义 |
|---|---|
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 可变长度,最大容量65535个字节 |
| tinytext | 可变长度,最大容量255个字节 |
| text | 可变长度,最大容量65535个字节 |
| mediumtext | 可变长度,最大容量2的24次方-1个字节 16MB |
| longtext | 可变长度,最大容量2的32次方-1个字节 4GB |
(1)char和varchar的区别:
-
char类型是【定长】的类型,即当定义的是char(10),输入的是"abc"这三个字符时,它们占的空间一样是10个字符,包括7个空字节。当输入的字符长度超过指定的数时,char会截取超出的字符。而且,当存储char值时,MySQL是自动删除输入字符串末尾的空格。
-
char是适合存储很短的、一般固定长度的字符串。例如,char非常适合存储密码的MD5值,因为这是一个定长的值。对于非常短的列,char比varchar在存储空间上也更有效率。
-
varchar(n)类型用于存储【可变长】的,长度最大为n个字符的可变长度字符数据。比如varchar(10), 然后输入abc三个字符,那么实际存储大小为3个字节。除此之外,varchar还需要使用1或2个额外字节记录字符串的长度,如果列的最大长度小于等于255字节(是定义的最长长度,不是实际长度),则使用1个字节表示长度,否则使用2个字节来表示。n表示的是最大的
-
char类型每次修改的数据长度相同,效率更高,varchar类型每次修改的数据长度不同,效率更低。
(2)varchar和text
-
text不能设置默认值,varchar可以,这个我们在后边再看。
-
text类型,包括(MEDIUMTEXT,LONGTEXT)也受单表 65535 最大行宽度限制,所以他支持溢出存储,只会存放前 768 字节在数据页中,而剩余的数据则会存储在溢出段中。虽然 text 字段会把超过 768 字节的大部分数据溢出存放到硬盘其他空间,看上去是会更加增加磁盘压力。但从处理形态上来讲 varchar 大于 768 字节后,实质上存储和 text 差别不是太大了。因为超长的 varchar 也是会用到溢出存储,读取该行也是要去读硬盘然后加载到内存,基本认为是一样的。
-
根据存储的实现:可以考虑用 varchar 替代 text,因为 varchar 存储更弹性,存储数据少的话性能更高。
-
如果存储的数据大于64K,就必须使用到 mediumtext,longtext,因为 varchar 已经存不下了。
v如果 varchar(255+) 之后,和 text 在存储机制是一样的,性能也相差无几。
日期和时间数据类型
| MySQL数据类型 | 含义 |
|---|---|
| date | 3字节,日期,格式:2014-09-18 |
| time | 3字节,时间,格式:08:42:30 |
| datetime | 8字节,日期时间,格式:2014-09-18 08:42:30 |
| timestamp | 4字节,自动存储记录修改的时间 |
| year | 1字节,年份 |
3、建表约束
(Create Table Constraints)
目前我们已经学会了如何创建表,但是,一张表不止有一列,数据库中的表不止有一个,建表约束说的就是,我们应该如何规范表中的数据以及表和表的关系。
(1)MySQL约束类型
| 约束名称 | 描述 |
|---|---|
| NOT NULL | 非空约束 |
| UNIQUE | 唯一约束,取值不允许重复, |
| PRIMARY KEY 主 | 键约束(主关键字),自带非空、唯一、索引 |
| DEFAULT | 默认值(缺省值) |
| FOREIGN KEY | 外键约束(外关键字) |
(2)[NOT] NULL约束
非空约束指的是,如果我们要在这张表中添加数据,设定了非空约束的列必须赋值,不能为空:
create table `ydlclass`.`author`(
`aut_id` int ,
`aut_name` varchar(50) not null, # 这就是非空约束
`gander` char(1) default '男',
`country` varchar(50),
`brithday` datetime
primary key(aut_id,aut_name)
);
(3)UNIQUE约束
唯一约束指的是,如果我们要在这张表中添加数据,设定了唯一约束的列中的值不能重复,不能为空:
实现方法1(表的定义最后施加)
-- 创建图书表
create table `ydlclass`.`book`(
`id` int primary key auto_increment,
`name` varchar(50) not null,
`bar_code` varchar(30) not null,
`aut_id` int not null,
unique(bar_code) -- 这就是唯一约束的定义
)
实现方法2(字段定义的最后施加)
-- 创建图书表
create table `ydlclass`.`book`(
`id` int primary key auto_increment,
`name` varchar(50) not null,
`bar_code` varchar(30) not null unique, -- 这就是唯一约束的定义
`aut_id` int not null,
)
(4)DEFAULT约束
默认约束指的是,如果我们要在这张表中添加数据,如果为给设定了默认约束的列赋值,该列会自动填充默认值:
-- 创建作者表
create table `ydlclass`.`author`(
`aut_id` int ,
`aut_name` varchar(50) not null,
`gander` char(1) default '男', -- 这就是默认约束
`country` varchar(50),
`brithday` datetime
primary key(aut_id,aut_name)
);
(5)PRIMARY KEY约束
主键(PRIMARY KEY)的完整称呼是“主键约束”,是 MySQL中使用最为频繁的约束。一般情况下,为了便于 DBMS 更快的查找到表中的记录,都会在表中设置一个主键。
主键分为单字段主键和多字段联合主键,本节将分别讲解这两种主键约束的创建、修改和删除。
使用主键应注意以下几点:
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在有相同主键值的两行数据。这是唯一性原则。
- 一个字段名只能在联合主键字段表中出现一次。
- 【联合主键】不能包含不必要的多余字段。当把联合主键的某一字段删除后,如果剩下的字段构成的主键仍然满足唯一性原则,那么这个联合主键是不正确的。这是最小化原则。
单个字段作为主键(方法1)
-- 创建作者表
create table `ydlclass`.`author`(
`aut_id` int primary key, -- 这就是主键约束
`aut_name` varchar(50) not null,
`gander` char(1) default '男',
`country` varchar(50),
`brithday` datetime
);
单个字段作为主键(方法2)
-- 创建作者表
create table `ydlclass`.`author`(
`aut_id` int ,
`aut_name` varchar(50) not null,
`gander` char(1) default '男',
`country` varchar(50),
`brithday` datetime,
primary key(aut_id) -- 这就是主键约束
);
联合主键:多个字段同时作为主键
-- 创建作者表
create table `ydlclass`.`author`(
`aut_id` int ,
`aut_name` varchar(50) not null,
`gander` char(1) default '男',
`country` varchar(50),
`brithday` datetime,
primary key(aut_id,aut_name) -- 这就是联合主键
);
(6)AUTO_INCREMENT约束
需要配合主键使用,有个这个约束,我们在向表中插入数据时,不需要额外关心主键的数据,他会自动帮我们维护一个递增的主键:
-- 创建图书表
create table `ydlclass`.`book`(
`id` int primary key auto_increment, -- 这就是自动递增
`name` varchar(50) not null,
`bar_code` varchar(30) not null unique,
`aut_id` int not null,
foreign key (aut_id) references author(aut_id)
)
(7)FOREIGN KEY约束
外键维护的表与表之间的关系,他规定了当前列的数据必须来源于一张其他表的某一列中的主键:
外键会产生的效果
1、删除表时,如果不删除引用外键的表,被引用的表不能直接删除
2、外键的值必须来源于引用的表的主键字段
语法:
FOREIGN KEY [column list] REFERENCES [primary key table] ([column list]);
-- 创建作者表
create table `ydlclass`.`author`(
`aut_id` int ,
`aut_name` varchar(50) not null,
`gander` char(1) default '男',
`country` varchar(50),
`brithday` datetime
primary key(aut_id,aut_name)
);
-- 创建图书表
create table `ydlclass`.`book`(
`id` int primary key auto_increment,
`name` varchar(50) not null,
`bar_code` varchar(30) not null unique,
`aut_id` int not null,
foreign key (aut_id) references author(aut_id) -- 这就是外键约束
)
4、对表的修改操作
查看当前数据库中所有表:SHOW TABLES;
查看表结构:DESC 表名;
desc authors;
修改表有5个操作,但前缀都是一样的:ALTER TABLE 表名…(不重要)
- 修改表之添加列:ALTER TABLE 表名 add (列名 列类型,…,列名 列类型);
alter table author add (hobby varchar(20),address varchar(50));
修改表之修改列类型:ALTER TABLE 表名 MODIFY 列名 列的新类型;
alter table author modify address varchar(100);
修改表之列名称列类型一起修改:ALTER TABLE 表名 CHANGE 原列名 新列名 列名类型;
alter table author change address addr varchar(60);
修改表之删除列:ALTER TABLE 表名 DROP 列名;
alter table author drop addr;
修改表之修改表名:ALTER TABLE 表名 RENAME TO 新表名
alter table author rename authors;
删除表:
drop table if exists 表名;
四、DML(数据操作语言)语法
该语言用来对表记录进行操作(增、删、改),不包含查询。
1、插入数据
insert into `authors` (aut_name,gander,country,brithday,hobby) values ('罗曼罗兰','女','漂亮国','1969-1-14','旅游');
insert into `authors` values (2,'罗曼罗兰2','女','漂亮国','1969-1-14','旅游');
说明:
- 在数据库中所有的字符串类型,必须使用单引号。
- (列名1,列名2,列名3)可省略,表示按照表中的顺序插入。但不建议采取这种写法,因为降低了程序的可读性。
当然我们还可以批量插入:
insert into `authors` (aut_name,gander,country,brithday,hobby) values ('罗曼罗兰','女','漂亮国','1969-1-14','旅游'),('海明威','男','老人与海','1969-1-3','看书');
2、修改记录
修改某列的全部值:update 表名 set 列名1=列值1(,列名2=列值2);
UPDATupdate `authors` set aut_name = '吴军';
update `authors` set aut_name = '吴军',country='中国';
上边的语句会讲改表中所有的数据全修改,因此我们可以使用where语句进行限制,如下:
UPDATE author set aut_name='lucy' where aut_id = 1;
where是一个很关键的关键字,我们可以使用where关键字实现丰富的筛选,他很像我们的if语句,可以使用各种条件运算:
可使用的逻辑运算符如下:=、!=、<>、<、>、>=、<=、between…and、in(…)、is null、not、or、and,其中in(…)的用法表示集合。
- where aut_id >1
- where aut_id in (1,3,5)
- where aut_id between 1 and 4
- where aut_id >1 and aut_name='xxx'
- where aut_name is null
- where aut_name is not null
-- 字符串也使用=比较,不是 ==也不是equals
update `authors` set aut_name = '王五',
-- 使用in关键字
update `authors` set aut_name = '张三',country='中国' where aut_id in (7,9);
-- 逻辑运算都可以
update `authors` set aut_name = '王五',country='中国' where gander = '男' and country = '中国';
-- 使用between关键字
update `authors` set aut_name = '玉帝',country='中国' where aut_id between 7 and 9
-- 空值使用is null \ is not null
update `authors` set aut_name = '王五',country='中国' where birthday is not
3、删除数据
delete from 表名 (where 条件);
不加where条件时会删除表中所有的记录,所以为了防止这种失误操作,很多数据库往往都会有备份。
delete from author where auth_id = 1;
还有一个关键字:truncate,truncate是DDL语言,操作立即生效,原数据不会放到rollback segment中,不能回滚。
- 当表被truncate后,表和索引的所占空间会恢复到初始大小,delete操作不会减少表和索引的所占空间。
- truncate和delete只删除数据,drop则删除整个表(结构和数据)。
- truncate速度快,效率高,可以理解为先把表删除了,再重新建立。
- truncate和delete均不会使表结构及其列、约束、索引等发生改变。
第三章 DQL数据查询语言
重点,DQL是我们每天接触编写最多也是最难的sql,该语言用来查询记录,不会修改数据库和表结构:
一、构建数据库
学习之前我们需要创建数据库并填充部分数据:
drop TABLE if EXISTS student;
CREATE TABLE student (
id INT(10) PRIMARY key,
name VARCHAR (10),
age INT (10) NOT NULL,
gander varchar(2)
);
drop TABLE if EXISTS course;
CREATE TABLE course (
id INT (10) PRIMARY key,
name VARCHAR (10) ,
t_id INT (10)
) ;
drop TABLE if EXISTS teacher;
CREATE TABLE teacher(
id INT (10) PRIMARY key,
name VARCHAR (10)
);
drop TABLE if EXISTS scores;
CREATE TABLE scores(
s_id INT ,
score INT (10),
c_id INT (10) ,
PRIMARY key(s_id,c_id)
) ;
表单填充数据:
insert into student (id,name,age,gander)VALUES(1,'白杰',19,'男'),(2,'连宇栋',19,'男'),(3,'邸志伟',24,'男'),(4,'李兴',11,'男'),(5,'张琪',18,'男'),(6,'武三水',18,'女'),(7,'张志伟',16,'男'),(8,'康永亮',23,'男'),(9,'杨涛瑞',22,'女'),(10,'王杰',21,'男');
insert into course (id,name,t_id)VALUES(1,'数学',1),(2,'语文',2),(3,'c++',3),(4,'java',4),(5,'php',null);
insert into teacher (id,name)VALUES(1,'张楠'),(2,'李子豪'),(3,'薇薇姐'),(4,'猴哥'),(5,'八戒');
insert into scores (s_id,score,c_id)VALUES(1,80,1);
insert into scores (s_id,score,c_id)VALUES(1,56,2);
insert into scores (s_id,score,c_id)VALUES(1,95,3);
insert into scores (s_id,score,c_id)VALUES(1,30,4);
insert into scores (s_id,score,c_id)VALUES(1,76,5);
insert into scores (s_id,score,c_id)VALUES(2,35,1);
insert into scores (s_id,score,c_id)VALUES(2,86,2);
insert into scores (s_id,score,c_id)VALUES(2,45,3);
insert into scores (s_id,score,c_id)VALUES(2,94,4);
insert into scores (s_id,score,c_id)VALUES(2,79,5);
insert into scores (s_id,score,c_id)VALUES(3,65,2);
insert into scores (s_id,score,c_id)VALUES(3,85,3);
insert into scores (s_id,score,c_id)VALUES(3,37,4);
insert into scores (s_id,score,c_id)VALUES(3,79,5);
insert into scores (s_id,score,c_id)VALUES(4,66,1);
insert into scores (s_id,score,c_id)VALUES(4,39,2);
insert into scores (s_id,score,c_id)VALUES(4,85,3);
insert into scores (s_id,score,c_id)VALUES(5,66,2);
insert into scores (s_id,score,c_id)VALUES(5,89,3);
insert into scores (s_id,score,c_id)VALUES(5,74,4);
insert into scores (s_id,score,c_id)VALUES(6,80,1);
insert into scores (s_id,score,c_id)VALUES(6,56,2);
insert into scores (s_id,score,c_id)VALUES(6,95,3);
insert into scores (s_id,score,c_id)VALUES(6,30,4);
insert into scores (s_id,score,c_id)VALUES(6,76,5);
insert into scores (s_id,score,c_id)VALUES(7,35,1);
insert into scores (s_id,score,c_id)VALUES(7,86,2);
insert into scores (s_id,score,c_id)VALUES(7,45,3);
insert into scores (s_id,score,c_id)VALUES(7,94,4);
insert into scores (s_id,score,c_id)VALUES(7,79,5);
insert into scores (s_id,score,c_id)VALUES(8,65,2);
insert into scores (s_id,score,c_id)VALUES(8,85,3);
insert into scores (s_id,score,c_id)VALUES(8,37,4);
insert into scores (s_id,score,c_id)VALUES(8,79,5);
insert into scores (s_id,score,c_id)VALUES(9,66,1);
insert into scores (s_id,score,c_id)VALUES(9,39,2);
insert into scores (s_id,score,c_id)VALUES(9,85,3);
insert into scores (s_id,score,c_id)VALUES(9,79,5);
insert into scores (s_id,score,c_id)VALUES(10,66,2);
insert into scores (s_id,score,c_id)VALUES(10,89,3);
insert into scores (s_id,score,c_id)VALUES(10,74,4);
insert into scores (s_id,score,c_id)VALUES(10,79,5);
二、单表查询
1、基本查询
(1)基本语法
查询所有列,其中*表示查询所有列,而不是所有行的意思:
select * from 表名;
查询指定列:
select 列1,列2,列n from 表名;
select `id`,`name`,`age`,`gander` from `student`;
select `id`,`name`,`age` from `student`;
完全重复的记录只显示一次,在查询的列之前添加distinct
(2)列运算
数量类型的列可以做加、减、乘、除等运算:
-- 查询给所有员工工资加1000的结果
select id,name,sal+1000 from employee;
select `id`,`name`,`age`*10 from student;
说明:
1、null加任何值都等于null,,需要用到ifnull()函数。SELECT IFNULL(sal,0) from 表名; 如果薪资列为空,则输出0;
2、将字符串做加减乘除运算,会把字符串当作0。
(3)别名
我们可以给列名起【别名】,因为在查询的结果中列名可能重复,可能名字不够简洁,或者列的名字不满足我们的要求:
select 列名1 (as) 别名1,列名2 (as) 别名2 from 表名;
select `id` `编号`,`name` `名字`,ifnull(`age`,0) as `age` from `student` as s;
只需要在列名后加 as 新列名 ,或是直接加上 新列名即可。
(4)条件控制
条件查询:在后面添加where指定条件,我们在学习update语句时,接触过这里大致是一样的:
-- 条件控制 select * from 表名 where 列名=指定值;
select * from student where id = 3;
select * from student where id in (1,3,7);
select * from student where id >5 ;
select * from student where id between 3 and 7 ;
select * from student where id between 6 and 7 or age > 20;
模糊查询:当你想查询所有姓张的记录。用到关键字like。
select * from student where name like '张_';
select * from student where name like '张%';
(_代表匹配任意一个字符,%代表匹配0~n个任意字符)
2、排序(所谓升序和降序都是从上往下排列)
- 升序: ascend
select * form 表名 order by 列名 asc; asc为默认值可以不写
- 降序:descend
select * from 表名 order by 列名 desc;
- 使用多列作为排序条件: 当第一列排序条件相同时,根据第二列排序条件排序(当第二列依旧相同时可视情况根据第三例条件排序):
select * from 表名 order by 列名1 asc, 列名2 desc;
意思是当列名1的值相同时按照列名2的值降序排。
3、聚合函数
- 1.count:查询满足条件的记录行数,后边可以跟where条件:
如果使用的列值为空,不会进行统计,
我们如果统计真实的表记录条数,最好不要用可以为空的列:
count(*) count(id) count(1)
select count(列名) from 表名;
select max(age) from student where id > 5;
- 2.max:查询满足条件的记录中的最大值,后边可以跟where条件:
select max(列名) from 表名;
- 3.min:查询满足条件的记录中的最大值,后边可以跟where条件:
select min(列名) from 表名;
- 4.sum:查询满足条件的记录中的值的和,后边可以跟where条件:
select sum(列名) from 表名;
- 5.avg:查询满足条件的记录中的值的平均数,后边可以跟where条件:
select avg(列名) from 表名;
4、分组查询
顾名思义:分组查询就是将原有数据进行分组统计:
我们举一个例子:将班级的同学按照性别分组,统计男生和女生的平均年龄和成绩。这就是一个典型的分组查询。
基本语法:
select 分组列名,聚合函数1,聚合函数2 from 表名 group by 该分组列名;
分组要使用关键词group by,后边可以是一列,也可以是多个列,分组后查询的列只能是分组的列,或是使用了聚合函数的其他列,其他列不能单独使用。
我们可以这样理解:一旦发生了分组,我们查询的结果只能是所有男生的成绩总和、平均值,而不能查询某一个男生的成绩。
有时我们需要对数据进行帅选,作为分组条件的列和聚合函数:
分组查询前,还可以通过关键字【where】先把满足条件的人分出来,再分组,语法为:
select 分组列,聚合函数 from 表名 where 条件 group by 分组列;
分组查询后,也可以通过关键字【having】把组信息中满足条件的组再细分出来,语法为:
select 分组列,聚合函数 from 表名 where 条件 group by 分组列 having 聚合函数或列名(条件);
例子:
select gander,avg(age) avg_age,sum(age) sum_age from student GROUP
5、LIMIT子句
LIMIT用来限定查询结果的起始行,以及总行数,通常用来做分页查询,他是mysql中独有的语法。
例如:
select * from 表名 limit 4,3;
如果一个参数:说明从开始查找三条记录
SELECT id,name,age,gander FROM student limit 3;
如果两个参数:说明从第三行起(不算),向后查三条记录
SELECT id,name,age,gander FROM student limit 3,3;
第四章 多表查询
一、笛卡尔积
如果我们的查询条件相对比较复杂,需要涉及多张表进行查询,如果是两张无关的表联合查询,列出所有的可能的结果,如下图:

查询的过程大致如下:
1、选取一张表,我们称之为【驱动表】,从驱动表中开始查询,找到满足条件的数据(如果没有条件就依次全部取出)。
2、根据从驱动表查询的这条数据,以及其他条件,去第二张【被驱动表】中查询,并将结果进行拼接。
3、依次类推,从驱动表获取第二条数据,使用该数据和条件,再次查询【被驱动表】进行查询。
4、整个过程,会查询【驱动表】一次,查询【被驱动表】多次。

对于没有【条件约束】的两张表进行关联查询,如select * from t1,t2,就是从t1中一条条的选取数据,然后全量匹配t2的所有数据,形成一个大的集合,集合的数据量是两表数据量的乘积,我们称之为【笛卡尔积】,如下:

没有连接条件时,我们必须列举所有的可能性,就会产生上边的一张大表,如果两个表的数据量变大,比如每张表1000条数据,那笛卡尔积,就会扩张到1百万,如果是三张表关联,就必须再乘以1000。
但是很明显,如果两个表没有任何的关系,我们也不会连接两张表进行查询的,在上边的案例中,很明显有一个关联条件就是部门id,两张表的部门id一致,才是我们想要的结果,如下:

于是,我们的sql就可以写成这个样子:
select e.id,e.name,e.dept_id,d.dept_name from employee e,dept e where e.dept_id = d,id
多表连接的方式有四种,内连接、外链接(左外连接,右外连接),全连接,我们将依次讲解
二、内连接
在我们刚才的sql当中,使用逗号分割两张表进行查询(employee e,dept e),mysql经过优化默认就等效与内链接,内连接使用关键字 【inner join】 或 【join】 来连接两张表。内连接中,【驱动表】是系统优化后自动选取的,会将执行计划中【扫描次数少】的表选做【驱动表】。
注意: 使用【join】关键字后要使用【on】来确定连接条件,而不是【where】。但是,在内连接中的where和on效果是等价的,但是一定要明确【on】用来声明连接条件,【where】是整理的帅选条件。
以下三条sql等效:
SELECT * from teacher t ,course c where c.t_id = t.id
SELECT * from teacher t join course c on c.t_id = t.id
SELECT * from teacher t inner join course c on c.t_id = t.id
原始数据:

通俗讲就是根据条件,找到表 A 和 表 B 的数据的交集。

三、外连接
内连接和外连接的区别:
- 对于【内连接】中的两个表,若【驱动表】中的记录在【被驱动表】中找不到与之匹配的记录,则该记录不会被加入到最后的结果集中。
- 对于【外连接】中的两个表,即使【驱动表】中的记录在【被驱动表】中找不到与之匹配的记录,也要将该记录加入到最后的结果集中,针对不同的【驱动表的选择】,又可以将外连接分为【左外连接】和【右外连接】。
所以我们可以得出以下结论:
- 对于左外连接查询的结果会包含左表的所有数据
- 对于右外连接查询的结果会包含右表的所有数据
外连接的关键字是【outter join】 也可以省略outter,连接条件一样需要使用【on】关键字:
(1)左连接(左外连接)
以下是左外连接的一条sql(等效):
SELECT * from course c left outer join on teacher t c.t_id = t.id
SELECT * from course c left join on teacher t c.t_id = t.id
我们可以看到,在左表course中第五条数据中的php课程并没有与之匹配的老师,但是结果php课程也显示出来了,同时将不能匹配其他表的字段都置空 【Null】:

我们可以使用一个图形来形容左外连接的效果:

(2)右连接(右外连接)
以下是左外连接的一条sql(等效):
SELECT * from course c left outer join teacher t on c.t_id = t.id
SELECT * from course c left join teacher t on c.t_id = t.id
我们可以看到,在右表teacher中第五条数据并没有与之匹配的左表数据,但是结果也显示出来了,同时将不能匹配其他表的字段都置空 【Null】:

我们可以使用一个图形来形容左外连接的效果:

四、全连接
mysql中并不支持全连接,但是有些数据库是支持的,比如oracle,使用【full outer join】关键字,sql如下:
SELECT * from teacher t full outer join course c on c.t_id = t.id
SELECT * from teacher t full join course c on c.t_id = t.id
虽然我的 MySQL 不支持此种方式,可以用其他方式替代解决,如下。
SELECT * from teacher t right outer join course c on c.t_id = t.id
union
SELECT * from teacher t left outer join course c on c.t_id = t.id
在这个结果中,不管是左表还是右表,所有的数据都被包含在了结果集当中:

我们可以使用一个图形来形容左外连接的效果:

小知识:阿里规约有这么一条【强制】超过三个表禁止join。需要join的字段,数据类型必须绝对一致; 多表关联查询时,保证被关联的字段需要有索引。说明:即使双表join也要注意表索引、SQL性能。
五、子查询
按照结果集的行列数不同,子查询可分为以下几类:
- 标量子查询:结果集只有一行一列 (又称为单行子查询)
- 列子查询: 结果集只有一列多行
- 行子查询: 结果集只有一行多列
- 表子查询: 结果集一般为多行多列
1、where/having 型子查询
在where性的子查询中,我们可以使用(标量子查询,列子查询,行子查询)
(1)查询比连宇栋年龄大的所有的学生 (标量子查询)
select * from student where age > (
select age from student where name = '连宇栋'
);
(2)查询有一门学科分数大于九十分的学生信息 (列子查询)
select * from student where id in(
select distinct s_id from scores where score > 90
)
(3)在多条件中,如果行子查询的结果正好满足条件,可以简化书写,如下:
以下的语句是为了写而写,不是最优的选择:
-- 查询男生且是年龄大学的学生信息
select * from student
where gander = '男' and age = (
select max(age) from student
GROUP BY gander having gander = '男'
)
select * from student
where (gander,age) = (
select gander,max(age) from student
GROUP BY gander having gander = '男'
)
总结:
- where 型子查询,如果是 where 列 =(内层 sql) 则内层 sql 返回的必须是单行单列,单个值。
- where 型子查询,如果是 where 列 in(内层 sql) 则内层 sql 返回的必须是单列,可以多行。
2、from 型子查询
在学习 from 子查询之前,需要理解一个概念:查询结果集在结构上可以当成表看,那就可以当成临时表对他进行再次查询,所以他支持的就是表子查询:
取排名数学成绩前五名的学生,正序排列。
select * from (
select s.id,s.name sname,r.score,c.name cname from student s
left join scores r on s.id = r.s_id
left join course c on r.c_id = c.id
where c.name = '数学'
order by r.score desc
limit 5) t order by t.score
3、SELECT型子查询
*在select关键字后的子查询仅仅支持标量子查询。
select ,1 as a,2,3,4,5,6 from student;
例子:查询每个部门的员工个数
select t.id,t.name,count(*) `代课的数量` from teacher t left join course c
on t.id = c.t_id group by t.id,t.name;
select t.id,t.name,(
select count(*) from course c where c.t_id = t.id
) as `代课的数量`
from teacher t;
4、exists型子查询:
表示判断子查询是否有返回值(true/false),有则返回true,没有返回false,这类子查询使用的不是很多。
例子:查询有员工的部门
select * from teacher t where exists (
select * from course c where c.t_id = t.id
);
六、sql大练兵
注:答案在文档下方的:附录一,一定要先自己做。
- 查询‘01’号学生的姓名和各科成绩。 难度:两颗星
- 查询各个学科的平均成绩,最高成绩。 难度:两颗星
- 查询每个同学的最高成绩及科目名称。 难度:四颗星
- 查询所有姓张的同学的各科成绩。 难度:两颗星
- 查询每个课程最高分的同学信息。 难度:五颗星
- 查询名字中含有“张”和‘李’字的学生信息和各科成绩 。 难度:两颗星
- 查询平均成绩及格的同学的信息。 难度:三颗星
- 将学生按照总分数进行排名。 难度:三颗星
- 查询数学成绩的最高分、最低分、平均分。 难度:两颗星
- 将各科目按照平均分排序。 难度:两颗星
- 查询老师的信息和他所带科目的平均分。 难度:三颗星
- 查询被“张楠”和‘‘李子豪’教的课程的最高分和平均分。 难度:三颗星
- 查询每个同学的最好成绩的科目名称。 难度:五颗星
- 查询所有学生的课程及分数。 难度:一颗星
- 查询课程编号为1且课程成绩在60分以上的学生的学号和姓名。 难度:两颗星
- 查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩。 难度:三颗星
- 查询有不及格课程的同学信息。 难度:四颗星
- 求每门课程的学生人数。 难度:两颗星
- 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列。 难度:两颗星
- 查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩。 难度:三颗星
- 查询有且仅有一门课程成绩在90分以上的学生信息; 难度:三颗星
- 查询出只有三门课程的全部学生的学号和姓名。难度:三颗星
- 查询有不及格课程的课程信息 。 难度:三颗星
- 检索至少选修5门课程的学生学号。难度:三颗星
- 查询没有学全所有课程的同学的信息 。难度:四颗星
- 查询学全所有课程的同学的信息。难度:四颗星
- 查询各学生都选了多少门课。难度:两颗星
- 查询课程名称为”java”,且分数低于60的学生姓名和分数。 难度:三颗星
- 查询学过”张楠”老师授课的同学的信息 。 难度:四颗星
- 查询没学过“张楠”老师授课的同学的信息 。 难度:五颗星
第五章 MySQL常用函数介绍
MySQL数据库中提供了很丰富的函数,比如我们常用的聚合函数,日期及字符串处理函数等。SELECT语句及其条件表达式都可以使用这些函数,函数可以帮助用户更加方便的处理表中的数据,使MySQL数据库的功能更加强大。本篇文章主要为大家介绍几类常用函数的用法:
一、聚合函数
聚合函数是平时比较常用的一类函数,这里列举如下:
- COUNT(col) : 统计查询结果的行数
- MIN(col): 查询指定列的最小值
- MAX(col): 查询指定列的最大值
- SUM(col): 求和,返回指定列的总和
- AVG(col): 求平均值,返回指定列数据的平均值
本类函数之前已经基本全部接触过,这里不在多做赘述。
二、数值型函数
数值型函数主要是对数值型数据进行处理,得到我们想要的结果,常用的几个列举如下:
- CEILING(x): 返回大于x的最小整数值,向上取整
- FLOOR(x): 返回小于x的最大整数值,向下取整
- ROUND(x,y): 返回参数x的四舍五入的有y位小数的值 四舍五入
- TRUNCATE(x,y): 返回数字x截短为y位小数的结果
- PI(): 返回pi的值(圆周率)
- RAND(): 返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值
一些示例:
# ABS()函数求绝对值
SELECT ABS(5),ABS(-2.4),ABS(-24),ABS(0);
# 取整函数 CEIL(x) 和 CEILING(x) 的意义相同,返回不小于 x 的最小整数值
SELECT CEIL(-2.5),CEILING(2.5);
# 求余函数 MOD(x,y) 返回 x 被 y 除后的余数
SELECT MOD(63,8),MOD(120,10),MOD(15.5,3);
# RAND() 函数被调用时,可以产生一个在 0 和 1 之间的随机数
SELECT RAND(), RAND(), RAND();
三、字符串函数
字符串函数可以对字符串类型数据进行处理,在程序应用中用处还是比较大的,同样这里列举几个常用的如下:
- LENGTH(s): 计算字符串长度函数,返回字符串的字节长度
- CONCAT(s1,s2…,sn): 合并字符串函数,返回结果为连接参数产生的字符串,参数可以是一个或多个
- LOWER(str): 将字符串中的字母转换为小写
- UPPER(str): 将字符串中的字母转换为大写
- LEFT(str,x): 返回字符串str中最左边的x个字符
- RIGHT(str,x): 返回字符串str中最右边的x个字符
- TRIM(str): 删除字符串左右两侧的空格
- REPLACE: 字符串替换函数,返回替换后的新字符串 REPLACE(name,‘白’,‘黑’)
- SUBSTRING: 截取字符串,返回从指定位置开始的指定长度的字符换
- REVERSE(str): 返回颠倒字符串str的结果
一些示例:
# LENGTH(str) 函数的返回值为字符串的字节长度
SELECT LENGTH('name'),LENGTH('数据库');
# CONCAT(sl,s2,...) 函数返回结果为连接参数产生的字符串 若有任何一个参数为 NULL,则返回值为 NULL
SELECT CONCAT('MySQL','5.7'),CONCAT('MySQL',NULL);
# INSERT(s1,x,len,s2) 返回字符串 s1,子字符串起始于 x 位置,并且用 len 个字符长的字符串代替 s2
SELECT INSERT('Football',2,4,'Play') AS col1,INSERT('Football',-1,4,'Play') AS col2;
# UPPER,LOWER是大小写转换函数
SELECT LOWER('BLUE'),LOWER('Blue'),UPPER('green'),UPPER('Green');
# LEFT,RIGHT是截取左边或右边字符串函数
SELECT LEFT('MySQL',2),RIGHT('MySQL',3);
# REPLACE(s,s1,s2) 使用字符串 s2 替换字符串 s 中所有的字符串 s1
SELECT REPLACE('aaa.mysql.com','a','w');
# 函数 SUBSTRING(s,n,len) 带有 len 参数的格式,从字符串 s 返回一个长度同 len 字符相同的子字符串,起始于位置 n
SELECT SUBSTRING('computer',3) AS col1,SUBSTRING('computer',3,4) AS col2,
SUBSTRING('computer',-3) AS col3,SUBSTRING('computer',-5,3) AS col4;
+--------+------+------+------+
| col1 | col2 | col3 | col4 |
+--------+------+------+------+
| mputer | mput | ter | put |
+--------+------+------+------+
四、日期和时间函数
获取时间和日期
- 【CURDATE】 和 CURRENT_DATE】 两个函数作用相同,返回当前系统的【日期值】
- 【CURTIME 和 CURRENT_TIME】 两个函数作用相同,返回当前系统的【时间值】
- 【NOW】 和 【SYSDATE】 两个函数作用相同,返回当前系统的【日期和时间值】
时间戳或日期转换函数:
- 【UNIX_TIMESTAMP】 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数
- 【FROM_UNIXTIME】 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数
根据日期获取年月日的数值
- 【MONTH】 获取指定日期中的月份
- 【MONTHNAME】 获取指定日期中的月份英文名称
- 【DAYNAME】 获取指定曰期对应的星期几的英文名称
- 【DAYOFWEEK】 获取指定日期对应的一周的索引位置值
- 【WEEK】 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53
- 【DAYOFYEAR】 获取指定曰期是一年中的第几天,返回值范围是1~366
- 【DAYOFMONTH】 获取指定日期是一个月中是第几天,返回值范围是1~31
- 【YEAR】 获取年份,返回值范围是 1970〜2069
时间日期的计算
- 【DATE_ADD】 和 【ADDDATE】 两个函数功能相同,都是向日期添加指定的时间间隔
- 【DATE_SUB】 和【 SUBDATE】 两个函数功能相同,都是向日期减去指定的时间间隔
- 【ADDTIME】 时间加法运算,在原始时间上添加指定的时间
- 【SUBTIME】 时间减法运算,在原始时间上减去指定的时间
- 【DATEDIFF】 获取两个日期之间间隔,返回参数 1 减去参数 2 的值
- 【DATE_FORMAT】 格式化指定的日期,根据参数返回指定格式的值
当使用了表达式计算后,不能直接使用别名进行判断了。
一些示例:
# CURDATE() 和 CURRENT_DATE() 函数的作用相同,将当前日期按照“YYYY-MM-DD”或“YYYYMMDD”格式的值返回
mysql> SELECT CURDATE(),CURRENT_DATE(),CURRENT_DATE()+0;
# MONTH(date) 函数返回指定 date 对应的月份
SELECT MONTH('2017-12-15');
# DATE_ADD(date,INTERVAL expr type) 和 ADDDATE(date,INTERVAL expr type) 两个函数的作用相同,都是用于执行日期的加运算。
SELECT DATE_ADD('2018-10-31 23:59:59',INTERVAL 1 SECOND) AS C1,DATE_ADD('2018-10-31 23:59:59',INTERVAL '1:1' HOUR) AS C2, ADDDATE('2018-10-31 23:59:59',INTERVAL 1 SECOND) AS C3;
# DATEDIFF(date1,date2) 返回起始时间 date1 和结束时间 date2 之间的天数
SELECT DATEDIFF('2017-11-30','2017-11-29') AS COL1,DATEDIFF('2017-11-30','2017-12-15') AS col2;
# DATE_FORMAT(date,format) 函数是根据 format 指定的格式显示 date 值
SELECT DATE_FORMAT('2017-11-15 21:45:00','%W %M %D %Y') AS col1,DATE_FORMAT('2017-11-15 21:45:00','%h:i% %p %M %D %Y') AS col2;
五、加密函数
- MD5() 计算字符串str的MD5校验和
SELECT MD5('abc');
结果:900150983cd24fb0d6963f7d28e17f72
六、流程控制函数
流程控制类函数可以进行条件操作,用来实现SQL的条件逻辑,允许开发者将一些应用程序业务逻辑转换到数据库后台,列举如下:
- IF(test,t,f): 如果test是真,返回t;否则返回f
- IFNULL(arg1,arg2): 如果arg1不是空,返回arg1,否则返回arg2
- NULLIF(arg1,arg2): 如果【arg1=arg2】返回NULL,否则返回arg1
SELECT NULLIF('abc','abc'); #返回null
SELECT NULLIF('abc','abcd'); #返回abc
通过对某一列的值进行判断,
- CASE [test] WHEN[val1] THEN [result]…ELSE [default] END:
如果test和valN相等,则返回resultN,否则返回default
创建表和数据如下:
CREATE TABLE `mystudent` (
`ID` int(10) NOT NULL AUTO_INCREMENT,
`USER_NAME` varchar(20) DEFAULT NULL,
`COURSE` varchar(20) DEFAULT NULL,
`SCORE` float DEFAULT '0',
PRIMARY KEY (`ID`)
)
insert into mystudent(USER_NAME, COURSE, SCORE) values
("张三", "数学", 34),
("张三", "语文", 58),
("张三", "英语", 58),
("李四", "数学", 45),
("李四", "语文", 87),
("李四", "英语", 45),
("王五", "数学", 76),
("王五", "语文", 34),
("王五", "英语", 89);
例子一:输出学生各科的成绩,以及评级,60以下是D,60-70是C,71-80:是B ,80以上是A
SELECT
*,
CASE
WHEN score < 60 THEN 'D'
WHEN score >= 60 and score < 70 THEN 'C'
WHEN score >= 70 and score < 80 THEN 'B'
WHEN score >= 80 and score <= 100 THEN 'A'
END AS "评级"
FROM
mystudent
例子二:行转列案例,要求根据上边的表结构,查询出如下结果::
sql语句如下:
select user_name,
max(case course when '数学' then score else 0 end) as '数学',
max(case course when '语文' then score else 0 end) as '语文',
max(case course when '英语' then score else 0 end) as '英语'
from mystudent group by user_name
第六章 数据库设计
一、三范式
注:设计只是一种思想一种理念,我们按照规范的设计方式设计数据库对我们来说有好处,但绝对不是说一定要严格遵守,三范式能极大的减少数据冗余,但是相对编写sql而言是增加了难度的,所以所有好的设计都是要权衡利弊的,要对编码难度,存储大小,执行效率等多方面进行综合考量,但是在学习初期最好紧紧的遵循三范式,在后续的编码中体会和总结自己的经验。
设计数据库表的时候所依据的规范,共三个规范:
- 第一范式:要求有主键,并且要求每一个字段原子性不可再分
- 第二范式:要求所有非主键字段完全依赖主键,不能产生部分依赖
- 第三范式:所有非主键字段和主键字段之间不能产生传递依赖
1、第一范式
数据库表中不能出现重复记录,每个字段是原子性的不能再分
不符合第一范式的实例:
| 学生编号 | 学生姓名 | 联系方式 |
|---|---|---|
| 1001 | 白杰 bj@qq.com,18565987896 | |
| 1002 | 杨春旺 ycw@qq.com,13659874598 | |
| 1003 | 张志伟 zzw@qq.com,12598745698 |
解决方案
| 学生编号 | 学生姓名 | 邮箱地址 | 联系电话 |
|---|---|---|---|
| 1001 | 白杰 bj@qq.com | 18565987896 | |
| 1002 | 杨春旺 ycw@qq.com | 13659874598 | |
| 1003 | 张志伟 zzw@qq.com | 12598745698 |
不符合第一范式的实例,不是说他错哈:
| 学生编号 | 学生姓名 | 联系地址 |
|---|---|---|
| 1001 | 白杰 | 太原市尖草坪区恒山路108号 |
| 1002 | 杨春旺 | 太原市迎泽区迎泽大家100号 |
| 1003 | 张志伟 | 太原市杏花岭区北大街152号 |
解决方案:
| 学生编号 | 学生姓名 | 市 | 区 | 详细地址 |
|---|---|---|---|---|
| 1001 | 白杰 | 太原市 | 尖草坪区 | 恒山路108号 |
| 1002 | 杨春旺 | 太原市 | 迎泽区 | 迎泽大街100号 |
| 1003 | 张志伟 | 太原市 | 杏花岭区 | 北大街152号 |
必须有主键,这是数据库设计的最基本要求,主要采用数值型或定长字符串表示,关于列不可再分,应该根据具体的情况来决定。如联系方式,为了开发上的便利可能就采用一个字段。
关于第一范式,每一行必须唯一,也就是每个表必须有主键,这是数据库设计的最基本要求,主要采用数值型或定长字符串表示,关于列不可再分,应该根据具体的情况来决定。如联系方式,为了开发上的便利可能就采用一个字段。
2、第二范式
第二范式是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
不符合第二范式的案例:
其中学生编号和课程编号为联合主键
| 学生编号 | 性别 | 学生姓名 | 课程编号 | 课程名称 | 教室 | 成绩 |
|---|---|---|---|---|---|---|
| 1001 | 男 | 白杰 | 2001 | java | 3004 | 89 |
| 1002 | 男 | 杨春旺 | 2002 | mysql | 3003 | 88 |
| 1003 | 女 | 刘慧慧 | 2003 | html | 3005 | 90 |
| 1001 | 男 | 白杰 | 2002 | mysql | 3003 | 77 |
| 1001 | 男 | 白杰 | 2003 | html | 3005 | 89 |
| 1003 | 女 | 刘慧慧 | 2001 | java | 3004 | 90 |
以上虽然确定了主键,但此表会出现大量的数据冗余,出现冗余的原因在于,学生信息部分依赖了主键的一个字段学生编号,和课程id没有毛线关系。同时课程的信息只是依赖课程id,和学生id没有毛线关系。只有成绩一个字段完全依赖主键的两个部分,这就是第二范式部分依赖。
解决方案:
学生表:学生编号为主键
| 学生编号 | 性别 | 学生姓名 |
|---|---|---|
| 1001 | 男 | 白杰 |
| 1002 | 男 | 杨春旺 |
| 1003 | 女 | 刘慧慧 |
课程表:课程编号为主键
| 课程编号 | 课程名称 | 教室 |
|---|---|---|
| 2001 | java | 3003 |
| 2002 | mysql | 3003 |
| 2003 | html | 3005 |
成绩表:学生编号和课程编号为联合主键
| 学生编号 | 课程编号 | 成绩 |
|---|---|---|
| 1001 | 2001 | 89 |
| 1002 | 2002 | 88 |
| 1003 | 2003 | 90 |
| 1001 | 2002 | 77 |
| 1001 | 2003 | 89 |
| 1003 | 2001 | 90 |
如果一个表是单一主键,那么它就是复合第二范式,部分依赖和主键有关系
以上是典型的“多对多”设计
3、第三范式
建立在第二范式基础上的,非主键字段不能传递依赖于主键字段(不要产生传递依赖)
不满足第三范式的例子:
其中学生编号是主键
| 学生编号 | 学生姓名 | 专业编号 | 专业名称 |
|---|---|---|---|
| 1001 | 白杰 | 2001 | 计算机 |
| 1002 | 杨春旺 | 2002 | 自动化 |
| 1003 | 张志伟 | 2001 | 计算机 |
何为传递依赖?
专业编号依赖学生编号,因为该学生学的就是这个专业啊。但是专业名称和学生其实没多大关系,专业名称依赖于专业编号。这就叫传递依赖,就是某一个字段不直接依赖主键,而是依赖 依赖主键的另一个字段。
解决方法:
学生表,学生编号为主键:
学生编号为主键:
| 学生编号 | 学生姓名 | 专业编号 |
|---|---|---|
| 1001 | 白杰 | 2001 |
| 1002 | 杨春旺 | 2002 |
| 1003 | 张志伟 | 2001 |
专业表,专业编号为主键:
| 专业编号 | 专业名称 |
|---|---|
| 2001 | 计算机 |
| 2002 | 自动化 |
| 以上设计是典型的一对多的设计,一存储在一张表中,多存储在一张表中,在多的那张表中添加外键指向一的一方 |
二、常见表关系
1、一对一 用的不多
一个表和另一张表存在的关系是一对一,此种设计不常用,因为此种关系经常会将多张表合并为一张表。
举例:
学生信息表可以分为基本信息表和详细信息表。
可能有这种需求,需要给个某个账户对学生表的操作,但是有些私密信息又不能暴露,就可以拆分。
第一种方案:分两张表存储,共享主键
第二种方案:分两张表存储,外键唯一
2、一对多
第三范式的例子
两张表 外键建在多的一方
分两张表存储,在多的一方添加外键,
这个外键字段引用一的一方中的主键字段
3、多对多
第二范式的例子
分三张表存储,在学生表中存储学生信息,在课程表中存储课程信息,
在成绩表中存储学生和课程的关系信息
附录一 练习题答案
1、查询‘01’号学生的姓名和各科成绩。 难度:两颗星
select s.id,s.name sname,c.name cname,r.score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
where s.id = 1;
2、查询各个学科的平均成绩,最高成绩。 难度:两颗星
select c.id,c.name,avg(r.score),max(r.score) from course c
left join scores r on c.id = r.c_id
group by c.id,c.name;
3、查询每个同学的最高成绩及科目名称。 难度:四颗星
select t.id,t.name,c.id,c.name,r.score from
(select s.id,s.name,(
select max(score) from scores r where r.s_id = s.id
) score from student s) t
left join scores r on r.s_id = t.id and r.score = t.score
left join course c on r.c_id = c.id;
4、查询所有姓张的同学的各科成绩。 难度:两颗星
select s.id,s.name sname,c.name cname,r.score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
where s.name like '张%';
5、查询每个课程最高分的同学信息。 难度:五颗星
select * from student s where id in
(
select distinct r.s_id from
(
select c.id,c.name,max(score) score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
group by c.id,c.name
) t
left join scores r on t.id = r.c_id and t.score = r.score
);
6、查询名字中含有“张”和‘李’字的学生信息和各科成绩 。 难度:两颗星
select s.id,s.name sname,c.name cname,r.score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
where s.name like '%张%' or s.name like '%李%';
7、查询平均成绩及格的同学的信息。 难度:三颗星
select * from student s where id in (
select r.s_id from scores r
group by r.s_id
having avg(r.score)>60
);
8、将学生按照总分数进行排名。 难度:三颗星
select s.id,s.name sname,sum(r.score) score from student s
left join scores r on r.s_id = s.id
group by s.id,s.name order by score desc;
9、查询数学成绩的最高分、最低分、平均分。 难度:两颗星
select c.name,max(score),min(score),avg(score) from course c
left join scores r on c.id = r.c_id
where c.name = '数学';
10、将各科目按照平均分排序。 难度:两颗星
select c.id,c.name,avg(score) score from course c
left join scores r on c.id = r.c_id
group by c.id,c.name order by score desc;
11、查询老师的信息和他所带科目的平均分。 难度:三颗星
select t.id,t.name,c.id,c.name,avg(r.score)
from teacher t
left join course c on t.id = c.t_id
left join scores r on r.c_id = c.id
group by t.id,t.name,c.id,c.name;
12、查询被“张楠”和‘‘李子豪’教的课程的最高分和平均分。 难度:三颗星
select t.id,t.name,c.id,c.name,avg(r.score)
from teacher t
left join course c on t.id = c.t_id
left join scores r on r.c_id = c.id
group by t.id,t.name,c.id,c.name
having t.name in ('张楠','李子豪');
13、查询每个同学的最好成绩的科目名称。 难度:五颗星
select t.id,t.sname,r.c_id,c.id,c.name,t.score from
(select s.id,s.name sname,max(r.score) score
from student s
left join scores r on r.s_id = s.id
group by s.id,s.name) t
left join scores r on r.s_id = t.id and r.score = t.score
left join course c on r.c_id = c.id ;
14、查询所有学生的课程及分数。 难度:一颗星
select s.id,s.name sname,c.id,c.name cname,r.score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id;
15、查询课程编号为1且课程成绩在60分以上的学生的学号和姓名。 难度:两颗星
select * from student s where id in
(
select r.s_id from scores r where r.c_id = 1 and r.score > 60
);
16、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩。 难度:三颗星
select s.id,s.name,t.score from student s
left join (
select r.s_id ,avg(r.score) score from scores r group by r.s_id
) t on s.id = t.s_id;
17、查询有不及格课程的同学信息。 难度:四颗星
-- 什么叫有不及格 ---》最低分数的科目如果不及格
select * from student s where id in (
select r.s_id from scores r group by r.s_id
HAVING min(r.score) < 60
);
18、求每门课程的学生人数。 难度:两颗星
select c.id,c.name, t.number from course c
left join
(select r.c_id,count(*) number from scores r group by r.c_id) t
on c.id = t.c_id;
select c.id,c.name,count(*) from course c
left join scores r on c.id = r.c_id
group by c.id,c.name;
19、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列。 难度:两颗星
select c.id,c.name,avg(score) score from course c
left join scores r on c.id = r.c_id
group by c.id,c.name
order by score desc,c.id asc;
20、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩。 难度:三颗星
select s.id,s.name,t.score from student s
right join (
select r.s_id,avg(score) score from scores r
group by r.s_id having score >= 70
) t on s.id = t.s_id;
select s.id,s.name sname, avg(r.score) score from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
group by s.id,s.name having avg(r.score) > 70;
21、查询有且仅有一门课程成绩在90分以上的学生信息; 难度:三颗星
select * from student s where id in (
select r.s_id from scores r where r.score > 90
group by r.s_id having count(*) = 1
);
select s.id,s.name,s.gander from student s
left join scores r on s.id = r.s_id
where r.score > 90
group by s.id,s.name,s.gander having count(*) = 1;
22、查询出只有三门课程的全部学生的学号和姓名。难度:三颗星
select * from student s where id in (
select r.s_id from scores r group by r.s_id having count(*) = 3
);
select s.id,s.name,s.gander from student s
left join scores r on s.id = r.s_id
group by s.id,s.name,s.gander having count(*) = 3;
23、查询有不及格课程的课程信息 。 难度:三颗星
select * from course c where id in (
select r.c_id from scores r group by r.c_id
HAVING min(r.score) < 60
);
select r.c_id,c.name from course c
left join scores r on c.id = r.c_id
group by r.c_id,c.name HAVING min(r.score) < 60;
24、检索至少选修5门课程的学生学号。难度:三颗星
select * from student s where s.id in (
select r.s_id from scores r group by r.s_id having count(*) >= 5
);
select s.id,s.name from student s
left join scores r on s.id = r.s_id
group by s.id,s.name having count(*) >= 5;
25、查询没有学全所有课程的同学的信息 。难度:四颗星
select s.id,s.name,count(*) number from student s
left join scores r on s.id = r.s_id
group by s.id,s.name having number < (
select count(*) from course
);
26、查询学全所有课程的同学的信息。难度:四颗星
select s.id,s.name,count(*) number from student s
left join scores r on s.id = r.s_id
group by s.id,s.name having number = (
select count(*) from course
);
27、 查询各学生都选了多少门课。难度:两颗星
select s.id,s.name,count(*) number from student s
left join scores r on s.id = r.s_id
group by s.id,s.name;
28、查询课程名称为”java”,且分数低于60的学生姓名和分数。 难度:三颗星
select s.id,s.name,r.score from student s
left join scores r on s.id = r.s_id
left join course c on r.c_id = c.id
where c.name = 'java' and r.score < 60;
29、查询学过”张楠”老师授课的同学的信息 。 难度:四颗星
select s.id,s.name from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
left join teacher t on c.t_id = t.id
where t.name = '张楠';
30、查询没学过“张楠”老师授课的同学的信息 。 难度:五颗星
select * from student where id not in
(select distinct s.id from student s
left join scores r on r.s_id = s.id
left join course c on c.id = r.c_id
left join teacher t on c.t_id = t.id
where t.name = '张楠');
附录二 日期格式
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| % | Y |
| % | y 年,2 位 |
















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











