







2021SC@SDUSC
提交差异
为了方便用户检视,以及为合并做准备,需要设计一种算法,来统计两个提交间(分支)的差异。在思考算法的具体流程前,需要先总结差异的类型。
差异类型
若有两个提交Commit, Parent,假设我们考虑Commit相对于Parent的差异。即,Commit是我的提交,Parent是别人的提交,现在需要考虑我的提交相对于别人的提交的不同。
文件差异
| 差异 | 说明 | 符号 |
|---|---|---|
| 添加 | Commit相对于Parent添加了该文件。 | A |
| 删除 | Commit相对于Parent删除了该文件。 | D |
| 修改 | Commit相对于Parent添加了该文件。 | M |
| 重命名 | Commit相对于Parent重命名了该文件,且内容尚未被修改。 | R |
目录差异
| 差异 | 说明 | 符号 |
|---|---|---|
| 添加 | Commit相对于Parent添加了该目录。 | B |
| 删除 | Commit相对于Parent删除了该目录。 | C |
| 重命名 | Commit相对于Parent重命名了该目录,且链接尚未被修改。 | E |
未合并差异
三路差异中的特殊情况。
| 差异 | 说明 |
|---|---|
| STATUS_UNMERGED_NONE | 未合并 |
| STATUS_UNMERGED_BOTH_CHANGED | 两者都被修改:相同文件被修改为不同结果 |
| STATUS_UNMERGED_BOTH_ADDED | 两者都被添加:两个合并都添加了相同的文件 |
| STATUS_UNMERGED_I_REMOVED | 一个移除了文件,一个修改了文件 |
| STATUS_UNMERGED_OTHERS_REMOVED | 一个修改了文件,一个移除了文件 |
| STATUS_UNMERGED_DFC_I_ADDED_FILE | 一个将目录替换为了文件,另一个修改了目录中的文件 |
| STATUS_UNMERGED_DFC_OTHERS_ADDED_FILE | 一个修改了目录中的文件,另一个将目录替换为了文件 |
(实际使用中的目的未知,因为尚未找到相关实现代码)
算法
流程
-
同构递归
目的是递归遍历各路文件树位置同构的部分。伪代码如下:
文件树同构递归(Tree[s][n]:n路文件树上位置同构的目录): Dirents[n]:n路文件树上位置同构的目录项 While (1): 获取同构目录项至Dirents 如果n路的Dirents完全相同: Return 文件差异处理(Dirents) 目录差异处理(Dirents) 文件差异处理(Dirents[n]:n路文件树上位置同构的文件): 获取对应的Files,然后调用差异回调函数 目录差异处理(Dirents[n]:n路文件树上位置同构的文件): 获取对应的Dir,然后调用差异回调函数 文件树同构递归(Dirs) -
同构目录项
同构递归之所以能做到多路位置同构,很重要的一点是需要获取同构目录项,而这一点需要某些基准。回到位置同构的本质,它实际上就是需要节点到根的路径完全相同。考虑搜索二/多叉树,因为存在权值,所以我们很容易找到多棵树中节点到根权值完全相同的路径。那么文件树中可以用什么作为权值呢?文件名/目录名。
我们认为相同名称的目录项,在多路位置同构目录中也位置同构。基于这个假设,我们很快能设计出高效复杂度的遍历同构项的方法。考虑将目录项按名称排序(这也是获取Seafdir时的默认操作),然后我们就可以用类似归并排序中的方法,基于多指针来得到多路相同的目录项。
当然,仅仅是知道同构仍然是不够的,因为我们的目的是需要知道同构的差异,所以我们需要进一步使用差异算法来获得差异。
二路差异与三路差异
对于两种产生提交的方式,有两种差异算法:
-
二路差异:应用于普通提交。判断Commit相对于Parent的差异。能直接确定非差异内容,而对于修改内容,则需要判断内容。
-
三路差异:应用于合并后提交。判断Commit相对于ParentA和ParentB的差异。可以区分出Commit相对于两者的增加、删除。但是修改仍然要结合内容来判断。

无论是二路差异还是三路差异,都无法判断用户是否是重命名了文件或目录,因为在基于名称的位置同构中,重命名等价于删除后增加。后处理中将处理这种情况。
后处理
-
重命名的近似判断
已知,基于名称的同构中,如果一个文件被重命名了,那么它可能会被判定为既被删除又被增加。那么如何还原真实的状态?
答案是只需要找到相同内容,如果相同内容下存在“删除-增加”对,则认为该目录或文件被重命名了。
注意这只是一种近似判断,有可能用户真的是删除后又增加,但由于我们不监控用户的行为,所以统一认为是重命名。
-
冗余空目录
另一个会出现bug的点在空目录。空目录是个特殊存在,所有空目录都指向同一个空目录对象,因为它们的内容相同,所以SHA1即对象名都相同。因此存在两种情况会对一个空目录作出误判:
- 向空目录添加文件后,会判定该空目录被删除;
- 将某目录清空后,会判定空目录被增加。
那么如何处理这两种情况?其实很简单,遍历所有状态为增加或删除的目录,然后特判一下,再将差异类型修正即可。
实现
-
差异对象
typedef struct DiffEntry { // 差异对象 char type; // 差异类型 char status; // 差异状态 int unmerge_state; // 未合并状态 unsigned char sha1[20]; // 用于解决重命名问题 char *name; // 名称 char *new_name; // 新名称,仅被用于重命名情形 gint64 size; // 大小 gint64 origin_size; // 原始大小,仅被用于修改情形 } DiffEntry; -
差异对比选项
typedef struct DiffOptions { // 比对选项 char store_id[37]; // 存储id int version; // seafile版本 // 两个回调 DiffFileCB file_cb; // 文件差异处理回调 DiffDirCB dir_cb; // 目录差异处理回调 void *data; // 用户参数 } DiffOptions;在使用中向差异对比操作传入该结构体,需要设置目录和文件回调函数。回调即差异算法。
-
差异对比算法
- 同构位置递归
static int // 文件树同构递归 diff_trees_recursive (int n, SeafDir *trees[], const char *basedir, DiffOptions *opt); int // 文件树差异处理,封装 diff_trees (int n, const char *roots[], DiffOptions *opt) static int // 目录差异处理 diff_directories (int n, SeafDirent *dents[], const char *basedir, DiffOptions *opt) static int // 文件差异处理 diff_files (int n, SeafDirent *dents[], const char *basedir, DiffOptions *opt)- 差异算法
static int // 二路文件差异处理 twoway_diff_files (int n, const char *basedir, SeafDirent *files[], void *vdata) static int // 二路目录差异处理 twoway_diff_dirs (int n, const char *basedir, SeafDirent *dirs[], void *vdata, gboolean *recurse) static int // 三路文件差异处理 threeway_diff_files (int n, const char *basedir, SeafDirent *files[], void *vdata) static int // 三路目录差异处理(默认无操作) threeway_diff_dirs (int n, const char *basedir, SeafDirent *dirs[], void *vdata, gboolean *recurse)其中有一个小环节值得一提,就是如何判断内容是否相同。这时再次体现了SHA1摘要命名的好处:我们只需要对比两个文件系统对象的id,就能直接判断它们的内容是否相同。
- 后处理
void // 解决重命名问题 diff_resolve_renames (GList **diff_entries) void // 解决冗余空目录问题 diff_resolve_empty_dirs (GList **diff_entries) -
封装
- 普通提交
int // 比对两个提交的差异 diff_commits (SeafCommit *commit1, SeafCommit *commit2, GList **results, // 结果记录在results列表 gboolean fold_dir_diff); int // 比对两个提交的差异;给定根目录 diff_commit_roots (const char *store_id, int version, const char *root1, const char *root2, GList **results, gboolean fold_dir_diff);- 合并后提交
int // 比对合并前后的差异(与两个父提交对比) diff_merge (SeafCommit *merge, GList **results, gboolean fold_dir_diff); int // 比对合并前后的差异;给定根目录 diff_merge_roots (const char *store_id, int version, const char *merged_root, const char *p1_root, const char *p2_root, GList **results, gboolean fold_dir_diff);
分支合并
合并、冲突与解决
合并是一种重要的手段,能将多个提交(分支)合为一体。合并的对象时两个提交,但一般被认为是分支的合并,因为需要用分支作为提交的指针。分支合并在图中的性质就是入度等于二,即一个提交的生成由两个父提交产生,并且可以携带增量内容。
合并两个提交(分支),最重要的问题就是解决冲突。冲突的判断实际上与差异的判断类似,都是借助位置同构进行的,在此不做赘述。这里的关键问题在于如何判定冲突和解决冲突。冲突对于用户来讲敏感,用户需要通过比较选择哪一个的内容将其放到新版本中。同时冲突又有可能是用户定义的,所有非相同内容都有可能是冲突。
在此有两种解决思路:第一种是二路合并,第二种是三路合并。
二路合并很简单,仅相同内容被保留,删除增加修改全部留给用户选择。因为对二路的非相同内容完全无法判断是否应该保留还是舍弃。这样做实现很容易,但对用户来说很麻烦,不过非常保险,因为冲突选择权全部交给用户,完全可以由用户定义冲突。
三路合并则是具有一定自主性,引入了Base即两个分支的公共祖先,然后借助Base来判断保留内容还是交给用户选择。这样做提高了效率,但并不一定保险,因为算法定义的冲突有可能不符合用户定义。
三路合并
合并的参与者包括三个分支,Base、Head、Remote。我们的目的是将Head和Remote合并,并且Base是它们的共同祖先。
引入了Base后,所有差异内容的判断都有了判断准则。算法认为两分支相对于祖先不交叉的更改(包括增删改)都是被保留的,而交叉的更改则是冲突内容。这样的冲突定义实际上已经符合大多数情况,而且将冲突的可能范畴进一步缩小,可以说是在效率与用户需求之间找到了平衡。
我们用表格来表示合并中三个分支可能出现的情况。假设各个分支中位置同构部分的内容以大写字母表示,则可以得到如下合并结果:
| Base | Head | Remote | 结果 | 说明 |
|---|---|---|---|---|
| A | A | A | A | 相同内容 |
| A | A | B | B | 如果只有一方修改了,那么选择修改的 |
| A | B | A | B | 同上 |
| A | B | B | B | 如果双方拥有相同的变更,则选择修改过的 |
| A | B | C | conflict | 如果双方都修改了且不一样,则报告冲突,需要用户解决 |
转自:https://blog.csdn.net/longintchar/article/details/83049840
由上述表格,我们能够直接给出各个同构位置合并是如何处理的。所以三路合并算法也自然显现:套用之前的同构递归,然后实现该表格中的判断即可。
实现
函数递归和调用流程如图:
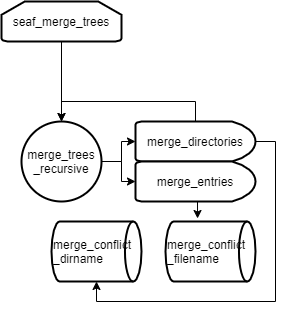
内容就是实现了三路合并算法(二路合并并未实装,将只调用回调函数)。
最后需要阐明的是合并结果的存储。对于合并后的结果,有两种选项:如果do_merge=true,则直接写入硬盘,然后返回一个根目录id到merged_tree_root;反之,只调用回调函数。
在此不再粘贴详细源码,详见:merge-new.c。















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









