







一、差值排序
1、排序原理
在学习插值排序之前,首先让我们回忆一下我们曾经玩过的扑克牌游戏的抓牌的过程:假设现在我的手里有4张牌,分别是♥A,♦3,♥8和❀9,并且我从牌堆中又抽取了一张牌,这张牌是♠7,那么,我们应该如何确定这张♠7应该放在我手牌中的什么位置,才能够保证手牌是有序(仅比较大小,忽略牌的花色)的呢?实际上很简单,首先我们发现:我的手牌现在本身就是有序的,然后我们可以将这张♠7首先和❀9进行比较,我们发现,♠7小于❀9,那么我们将这张♠7放在❀9的前面,与它前面的一张牌继续比较❀9的前面是♥8,♠7又小于♥8,所以我们将♠7放在♥8的前面,继续和前一张牌进行比较♥8的前面是♦3,♠7不小于♦3,那么此时♠7就找到了自己在手牌中的位置,不需要继续向前移动并进行比较了上面这一系列抓牌的流程,实际上就是一个完整的插值排序的流程,所以我们可以将插值排序的流程总结成为:将待排序序列(牌堆)中的第一个元素(抓到的牌)与前面有序序列(手牌)中的元素逐一比较,反序则互换并继续向前比较,否则停止比较,元素归位。实际上,插值排序的思想得益于“前面的n个元素都是有序”的这一思想,也就是说:新元素之所以下不小于某一个元素,之后就可以停止比较和互换,是因为如果他不小于第m个元素,那么在有序序列中他也一定不小于前m-1个元素。
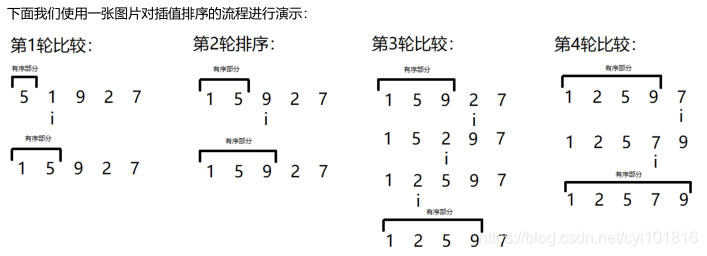
从上图中我们依然能够总结出一些规律:
1.在开始首轮排序比较的时候,我们一般都是选择数组中下标为1的元素作为抽到的牌而保留小标为0的元素作为已有的一张手牌,也就是说:在第n轮排序过程中(n从1开始取值),我们使用下标为n的数组元素作为待比较的元素;
2.并不是每一轮排序,我们都要将抽取到的新牌与手中有序的m张牌都比较一遍,这也是插值排序相比起前两种排序稍微快一些的原因;
3.因为我们首先认定数组中下标为0的元素就是初始的一张手牌,所以如果数组中有n元素,我们依然只要进行n1轮排序就能够保证数组中所有的元素有序;
2、算法实现
import java.util.Arrays;
public class InsertionSort {
/**
* 插值排序
* @param array
*/
public void insertionSort(int[] array) {
//[1]使用外层排序控制从“牌堆”中抽取的“手牌”
for(int i = 1; i < array.length; i++) { //手牌从数组中的第2个元素开始抽,也就是下标为1的元素开始,下标为0的元素当做已有手牌
//[2]使用内层循环控制抽到的牌和手牌之间的比较和排序,只要手牌更小,就一直向前交换,直到找到合适位置,或者数组到头为止
for(int j = i; j-1 >= 0 && array[j] < array[j-1]; j--) {
//[3]直接进行交换,因为比较的步骤已经定义在循环条件中了
int tmp = array[j];
array[j] = array[j-1];
array[j-1] = tmp;
}
}
}
public static void main(String[] args) {
int[] array = new int[] {7,0,1,9,2,6,3,8,5,4};
InsertionSort is = new InsertionSort();
is.insertionSort(array);
System.out.println(Arrays.toString(array));
}
}3、时间复杂度、空间复杂度、稳定性分析
1.插值排序的时间复杂度
在上面的内容中我们也已经说过:插值排序并不是每一轮排序都要进行n1次比较,但是如果在最坏情况下——也就是将数组元素逆序的情况下,我们依然需要将待比较元素和前面有序的元素全部进行比较,那么在一个长度为n的数组中:
第1轮排序:比较1次
第2轮排序:比较2次
第3轮排序:比较3次
...
第n2轮排序:比较n2次
第n1轮排序:比较n1次
将上述比较次数相加:1 + 2 + 3 + ... + (n2) + (n1),所得到的的是和冒泡排序和选择排序一样的n*(n-1)/2,也就是说,插值排 序的时间复杂度同样是O(n ^2 ),但是,如果一个序列本身就是近似有序的,那么插值排序的效率就会更高,这一点我们会在后 面的希尔排序中进行说明。
2.插值排序的空间复杂度
从上述原理我们可以看出,插值排序也只是在元素进行交换的时候使用了一个可以重复使用的临时变量空间。那么,插值排序的空间复杂度同样是O(1)
3.插值排序的稳定性
如果我们在牌堆中抽到了一张我们手中已有取值的牌,因为我们是从手牌的末尾开始逐一向前比较这张牌的,所以在遇到取值相同的牌的时候,我们并不会将两张牌进行交换,而是直接同值比较,结束这一轮排序。所以插值排序是一种稳定的排序算法。
二、.第一个突破O(n ^2 )的排序算法:希尔排序
1、排序原理
希尔排序算法(Shell's Sort)是排序算法中第一个时间复杂度突破O(n ^2 )的排序算法,也就是说:前面我们学过的冒泡排序、选择排序和插值排序的理论实践复杂度都是O(n ^2 ),而希尔排序是第一个从理论计算到实际操作中,时间复杂度都小于O(n ^2 )的一种排序算法,所以希尔排序在排序算法界具有很重要的意义。
希尔排序的实际上是一种变形的插值排序。它将整个序列按照规定的步长(step)进行分部分取值,并将这些值进行插值排序;在一轮排序之后,再将步长折半,以此类推,当步长取值为1的时候,整个希尔排序也就退化成为了一个单纯的插值排序。但是,正如前面我们说过的,如果一个序列本身就是近似有序的,那么插值排序的效率将会大大提升,所以,实际上希尔排序前面进行的分步和按照步长排序,都是在为这一点打下基础,最终提升插值排序的效率希尔排序的这种“步步紧逼”的做法,我们称之为“缩小增量法”。
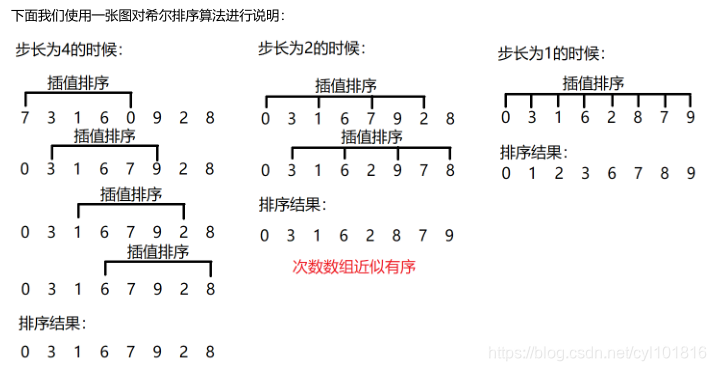
希尔排序的规律总结如下:
1.希尔排序总共进行几轮,取决于步长的取值,当步长取值为1的时候,就是最后一轮排序
2.希尔排序的步长,在每一轮中都是上一轮步长的一半,如果不能整除,则向下取整
3.希尔排序的每一轮比较,实际上都是将数组中间隔为step的诸多元素进行插值排序。所以在每一轮比较之后,数组整体都更接近有序状态
4.关于希尔排序的初始步长选择,我们一般定义为待排序序列长度的一半,然后每进行一轮希尔排序,步长折半。
2、算法实现
import java.util.Arrays;
public class ShellSort {
/**
* 希尔排序
* @param array
*/
public void shellSort(int[] array) {
int step = array.length / 2; //定义初始步长是数组长度的一半
while(step > 0) {
//使用一个循环,控制步长内的元素全部进行一次插值排序
for(int start = 0; start < step; start++) {
insertionSort(array, start, step); //内部使用间隔为步长的插值排序算法
}
step /= 2; //步长变成原来的一半
}
}
/**
* 希尔排序是一种基于插值排序的算法
* 这个方法是希尔排序内部使用的一种带有步长,并指定比较起点的插值排序算法
* @param array 待排序数组
* @param start 比较起点
* @param step 步长
*/
private void insertionSort(int[] array, int start, int step) {
for(int i = start + step; i < array.length; i += step) {
for(int j = i; j-step >= 0 && array[j] < array[j-step]; j -= step) {
int tmp = array[j];
array[j] = array[j-step];
array[j-step] = tmp;
}
}
}
public static void main(String[] args) {
int[] array = new int[] {7,0,1,9,2,6,3,8,5,4};
ShellSort ss = new ShellSort();
ss.shellSort(array);
System.out.println(Arrays.toString(array));
}
}
3、时间复杂度、空间复杂度、稳定性分析
1.希尔排序的时间复杂度
希尔排序的时间复杂度我们计算起来比较复杂,所以在这里我们直接记住这个结论即可:
在数组整体有序的情况下,希尔排序的时间复杂度是接近O(n^1.3 )的
在数组整体逆序的情况下,希尔排序的时间复杂度和插值排序接近,是O(n^2 )。
所以,希尔排序的时间复杂度我们进行如下表示:
希尔排序的时间复杂度:O(n ^k ) (1.3 <= k <= 2)
注意:希尔排序在代码实现的时候,相当于嵌套了4层循环结构,那它的时间复杂程度应该是O(n^4 ),实际上这种认知是错误 的.通过算法的循环嵌套层数推断算法的事件复杂程度的确是一种技巧,但是并不是百试百灵的.一个算法的时间复杂程度, 依然要通过分析算法的致病流程本身才能够得到
2.希尔排序的空间复杂度
希尔排序本身是基于插值排序的,所以在进行排序的过程中我们需要一个临时变量去进行元素交换,同时我们还需要一个额 外的变量保存当前的步长,所以这样一来我们就需要两个额外空间进行希尔排序的运算。但是,之前我们说过,只要所需的 辅助空间数量是常量级别的,那么空间复杂度都是O(1),所以,希尔排序的空间复杂度依然是O(1)
3.希尔排序的稳定性
希尔排序虽然是基于插值排序的,并且插值排序也是一种稳定的排序算法,但是我们在分布对数组进行排序的时候,有可 能将两个具有相同取值的元素的相对位置进行改变所以,希尔排序是一种不稳定的排序算法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











