







版本pk
hadoop 1.0 vs 2.0
1.0 很多单节点引起的问题,资源调度问题,资源隔离问题
2.0
- Hadoop HA :nameNode热备份 多nameNode
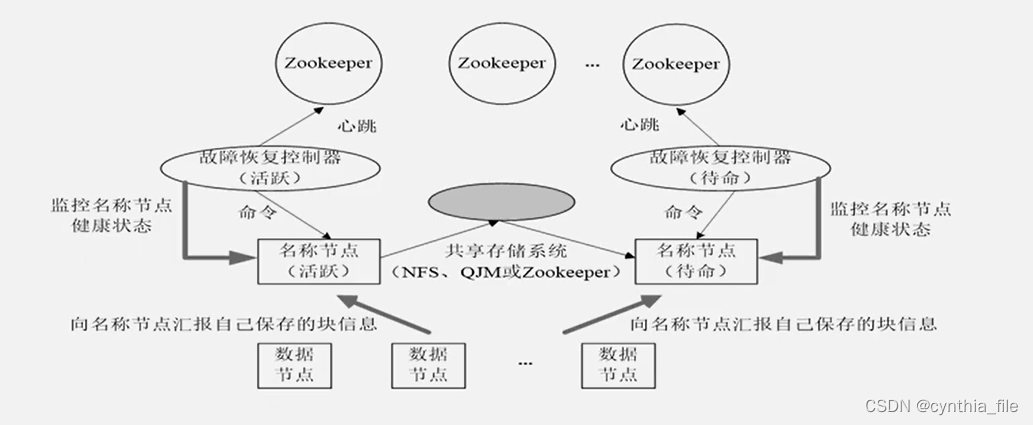
- Yarn&离线MapReduce
hadoop各组件
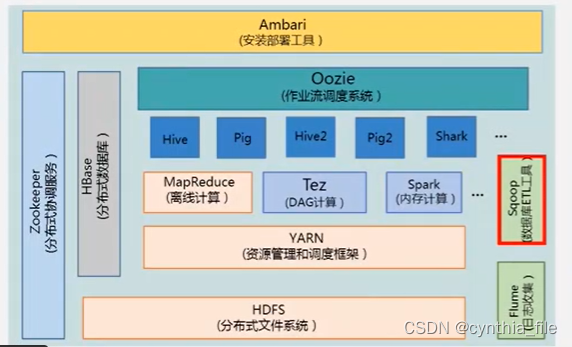
-
tez 构建有向无环图 保证处理效率,,任务先做后做少重复
-
mapreduce 批处理计算
-
Oozie 作业流调度 一个工作分成不同工作流, 管理不同应用程序协同完成一个工作,先做什么再做什么
-
ZooKeeper
分布式协调一致性:分布锁,HBase集群管理等
多 server 启动时选举leader -
HDFS
分布式文件系统结构:
文件名
元数据(meteData)【数据存储信息】
数据块 (block)【内容】默认128M一个文件分为多个数据块,分存在不同dataNode中(可冗余,默认3份,可设置) 1. NameNode ***唯一*** 存储元数据,内存中,block与datanode的映射关系 2. DataNode 多节点 存储文件内容,磁盘中 -
HBase
数据库 实时读写(分布式数据库) -
Flume 流日志收集
-
sqoop 数据导入导出
-
Pig 流处理 轻量级脚本语言 类似SQL的语言
-
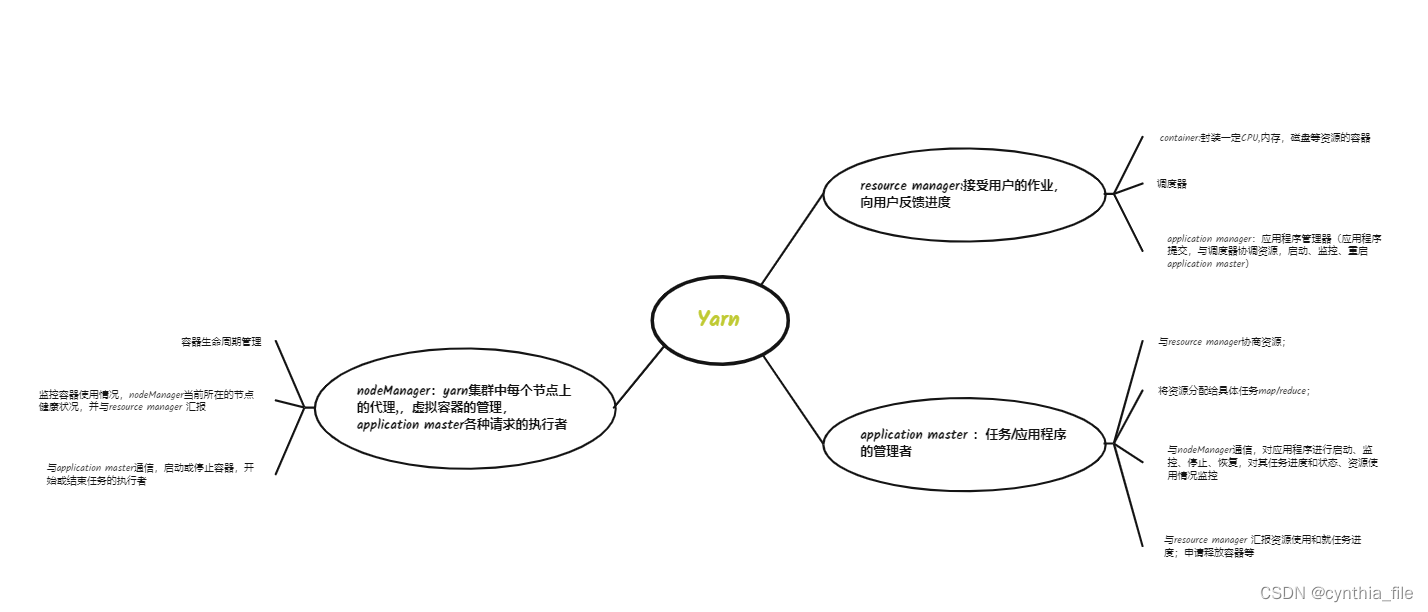
yarn 资源管理调度
-
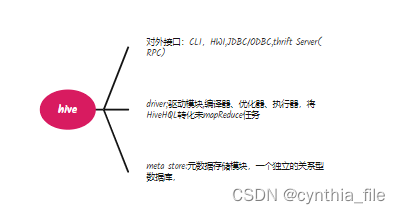
Hive 数据仓库
查询语言HQL (可做整个系统的ETL)
hive:相当于编译器,将HQL语言编译程 MapReduce任务进行执行-
hive架构
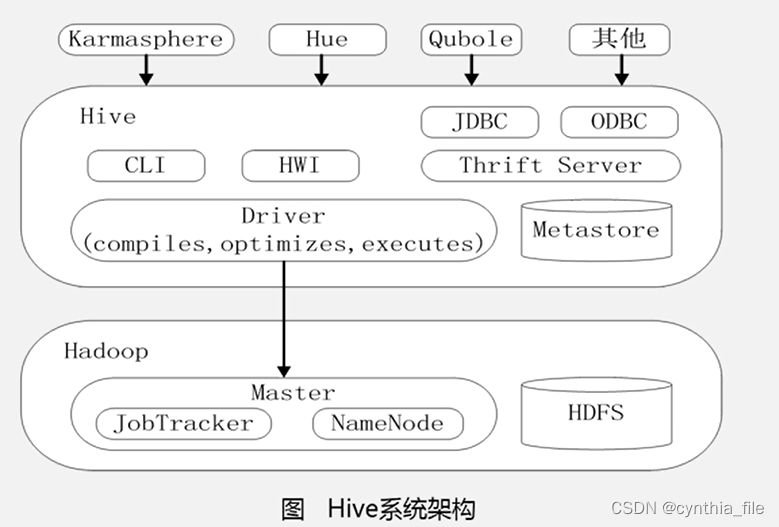
-
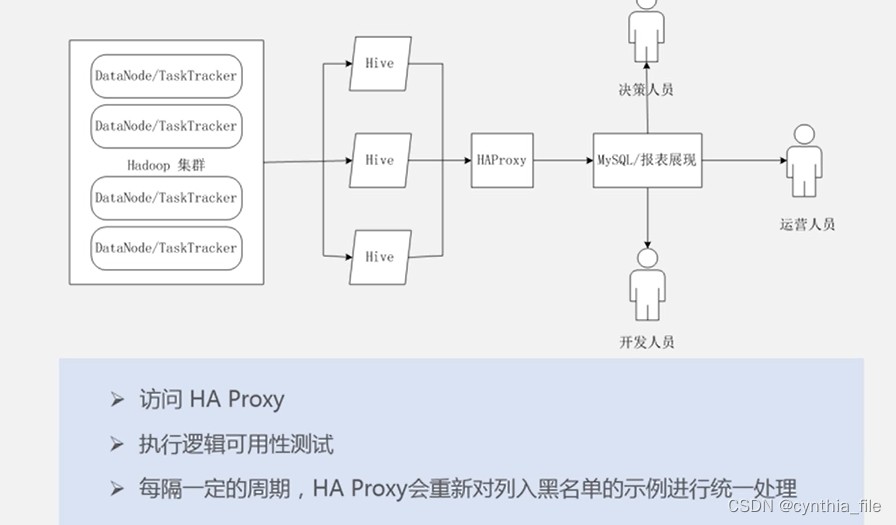
Hive HA:hive proxy 对hive实例进行管理
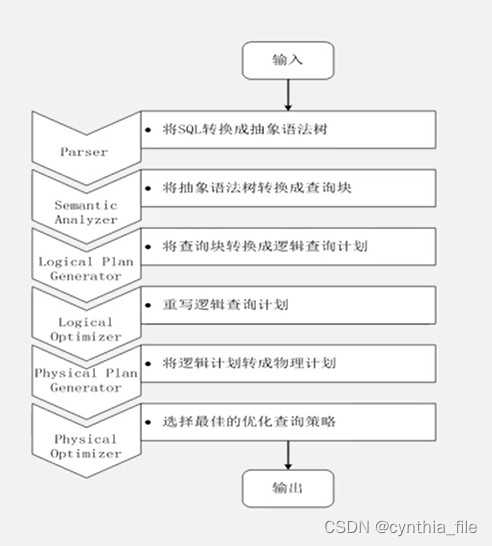
- HQL转mapReduce
- 分区:子目录(减小查询范围) 装载数据,记得分区
- 分桶:字段数据hash,存储,加快查询速度
–开启分桶功能
set hive.enforce.bucketing=true
– 忽略掉安全检查
hive.strict.checks.bucketing=false; - 内部表&外部表
为什么分内部表和外部表? - 严格模式&非严格模式
- 分区插入数据,,每次必须全部插入吗?不能指定字段?
分区与分桶的一些注意点
-















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









