







1. RabbitMQ 基本概念
- Exchange: 消息交换机,它指定消息按什么规则,路由到哪个队列
- Queue: 消息队列载体,每个消息都会被投入到一个或多个队列
- Binding: 绑定,它的作用就是把 exchange 和 queue 按照路由规则绑定起来
- Routing Key: 路由关键字,exchange 根据这个关键字进行消息投递
tips:交换器其实是我们想象出来的,它本质是一张查询表,里面包括了交换器名称和一个队列的绑定列表,当你将消息发布到交换器中,实际上是你所在的信道将消息上的路由键与交换器的绑定列表进行匹配,然后将消息路由出去。有了这个机制,RabbitMQ 所做的事情就是把交换器拷贝到所有节点上,因此每个节点上的每条信道都可以访问完整的交换器了。

2. RabbitMQ 的工作模式
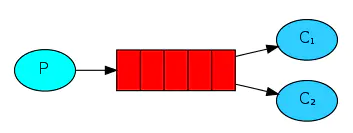
一.simple模式(即最简单的收发模式)
-
消息产生消息,将消息放入队列
-
消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉。消息被拿走后,自动从队列中删除(隐患:消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失,这里可以设置成手动的ack,但如果设置成手动ack,处理完后要及时发送ack消息给队列,否则会造成内存溢出)。
二.work工作模式(资源的竞争)
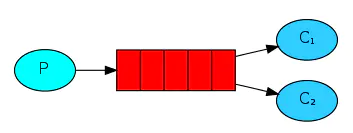
消息产生者将消息放入队列,消费者可以有多个,消费者1、消费者2同时监听同一个队列。
C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患:高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用)。
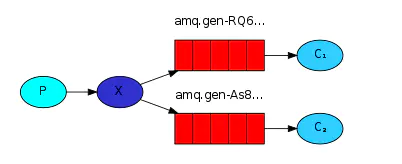
三.publish/subscribe发布订阅(共享资源)
-
每个消费者监听自己的队列;
-
生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息。
四.routing路由模式
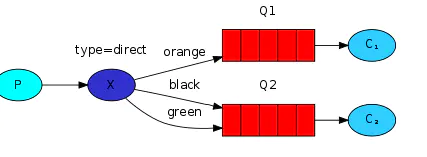
消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
五.topic 主题模式(路由模式的一种)
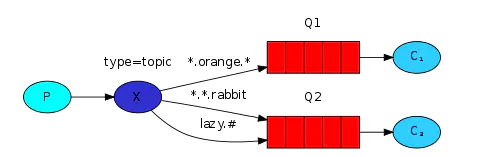
-
路由功能添加模糊匹配
-
消息产生者产生消息,把消息交给交换机
-
交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
3. 如何保证消息不被重复消费?或者说,如何保证消息消费时的幂等性?
先说为什么会重复消费:
正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除;但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
解决思路:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响。
比如:
给消息添加唯一标识,消费消息时,根据唯一标识判断是否消费过。假设有个系统,消费一条消息就往数据库里插入一条数据。那么,要是消息重复消费了,可以在后续消费时,判断一下是否消费过了,如果是则直接扔了,确保只保留一条数据。
4. 如何保证高可用?
RabbitMQ 的集群模式分为:普通集群模式 和 镜像集群模式
-
普通集群模式:
- 多台机器上启动多个 RabbitMQ,每台机器启动一个
- 创建的 queue 只会放在其中一台机器上,但是所有机器都同步该 queue 的元数据。
- 消费的时候,如果连接到其他机器,则会从 queue 所在的那台机器上拉取数据过来
- 这种方案是提高吞吐量的,就是说让多个节点来服务某个 queue 的读写操作
-
镜像集群模式:
- 这种模式,才是所谓的 RabbitMQ 的高可用模式。和普通集群模式不一样的是,创建的 queue,无论是元数据还是 queue 里的消息,全都会存在多台机器上。就是说,每台机器都会有这个 queue 的完整镜像。
- 每次写消息时,都会自动把消息同步到多台机器的 queue 上。
- 这样的好处在于,任何一个机器宕机了也没事,其他节点包含了这个 queue 的完整数据。但缺点是同步造成的网络开销大。















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









