







HashMap 是 Java 中最常用的键值对存储结构之一,它基于哈希表实现,具有高效的查找、插入和删除操作。以下是关于Java8中的 HashMap 的详细介绍:
基本概念
键值对存储:HashMap 存储的是键值对(Key-Value Pair),其中键(Key)是唯一的,值(Value)可以重复。
无序性:HashMap 不保证元素的顺序,插入的顺序和遍历的顺序可能不一致。
允许空键和空值:HashMap 允许键和值为 null。
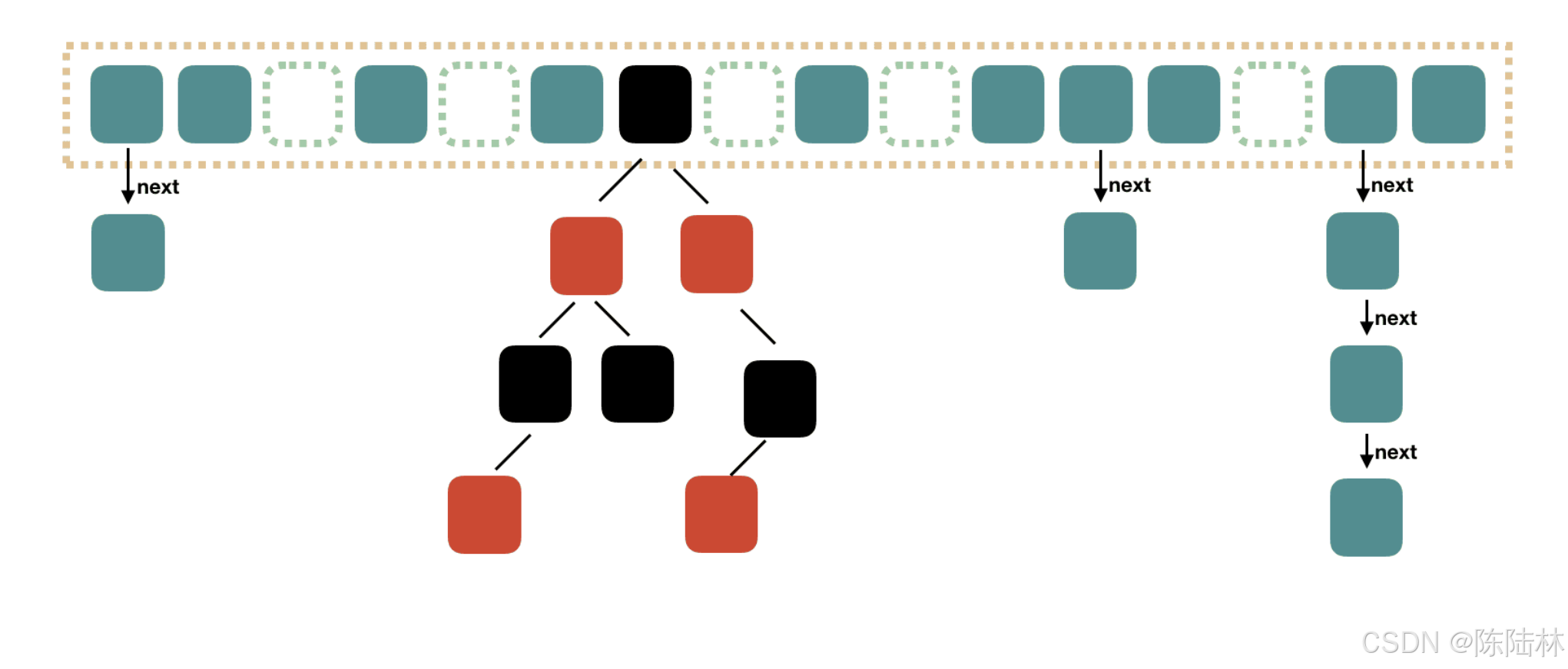
底层数据结构
HashMap的底层结构结合了数组、链表、红黑树三种数据结构:
数组
用于存储桶(Bucket),每个桶是一个链表或红黑树的头节点
具体作用:
- 存储桶(Bucket):数组的每个元素称为一个“桶”,用于存储键值对。
- 快速定位:通过哈希函数计算键的哈希值,然后对数组长度取模,确定键值对应该存储在数组的哪个索引位置。这个操作的时间复杂度是O(1)
- 示例:
假设有一个长度为 16 的数组,键 K1 的哈希值为 25,那么 K1 会被存储在索引 25 % 16 = 9 的位置。
链表
用于解决哈希冲突,存储冲突的键值对。
具体作用
- 处理哈希冲突:当多个键被映射到同一个数组索引时,这些键值对会以链表的形式存储在该索引位置。
- 存储冲突的键值对:链表中的每个节点包含键值对以及指向下一个节点的指针。
- 示例:
假设键 K1 和 K2 都被映射到数组的索引 9,那么索引 9 处的链表会存储 K1 和 K2 的键值对。
红黑树
在链表过长时(默认长度超过8),链表转化为红黑树,以提升性能。
具体作用
- 优化性能:当链表的长度超过一定阈值(默认是 8),链表会转换为红黑树,将查找、插入和删除操作的时间复杂度从 O(n) 降低到 O(logn)。
动态调整:当红黑树的节点数减少到一定阈值(默认是 6),红黑树会重新转换为链表。 - 示例:
假设索引 9 处的链表长度超过了 8,那么链表会转换为红黑树,以提升后续操作的性能。
核心属性
table:一个Node<K,V>[]类型的数组,用于存储键值对
size:当前HashMap中键值对的数量
loadFactor:负载因子,默认是0.75 ,用于决定何时扩容
threshold:扩容阈值,等于capacity * loadFacttor
工作原理
插入操作:
- 计算键值的哈希值,确定数组索引
- 如果该索引位置为空,直接插入键值对
- 如果该索引位置不为空(即发生哈希冲突)
- 如果当前是链表
i. 遍历链表,如果找到相同的键,更新其值。
ii. 如果为找到相同的键,将新键值对插入链表尾部
ii. 如果链表长度达到了阈值(默认8),将链表转换为红黑树。 - 如果当前是红黑树:
i. 按照红黑树的规则插入键值对。
- 如果当前是链表
查询操作
- 计算键的哈希值,确定数组索引
- 如果该索引位置为空,返回null
- 如果该索引位置不为空
- 如果当前是链表,遍历链表查找键值
- 如果当前是红黑树,按照红黑树的规则查找键
删除操作
- 计算键的哈希值,确定数组索引
- 如果该索引位置空,返回null
- 如果该索引位置不为空
- 如果当前是链表,遍历链表删除键值对
- 如果当前是红黑树,按照红黑树的规则删除键值对
- 如果红黑树的节点数减少到阈值(默认是6),将红黑树转换为链表
哈希冲突
HashMap使用链地址法(Separate Chaining)解决哈希冲突:
- 当多个键被映射到同一个数据索引时,这些键值对会以链表或红黑树的形式存储该索引位置。
扩容机制
当HashMap中的键值对数量超过阈值(threshold)时,会触发扩容
- 创建一个新的数组,容量是原来数组的两倍
- 将原来数组中的键值对重新哈希到新的数组中
- 扩容操作时间复杂度较高,因此尽量避免频繁扩容。
性能分析
查找:平均时间复杂度为O(1),最坏情况下(所有键都冲突)为O(logn)(红黑树)
插入:平均时间复杂度为O(1),最坏情况下为O(logn)
删除:平均时间复杂度为O(1),最坏情况下为O(logn)
注意事项
线程不安全:HashMap不是线程安全的,多线程环境下应使用ConcurrentHashMap。
初始容量和负载因子:可以通过构造函数指定初始容量和负载因子,以减少扩容次数。
键的哈希值:键的hashCode() 方法应尽量分布均匀,以减少哈希冲突。
基础操作代码
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// 创建 HashMap
HashMap<String, Integer> map = new HashMap<>();
// 插入键值对
map.put("Alice", 25);
map.put("Bob", 30);
map.put("Charlie", 35);
// 查找值
System.out.println("Alice's age: " + map.get("Alice"));
// 删除键值对
map.remove("Bob");
// 遍历 HashMap
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
}
}
总结
HashMap是一种高效的键值对存储结构,通过数组、链表和红黑树的结合,能够在多数情况下实现O(1)的查找、插入和删除操作。理解器底层实现和扩容机制,有助于在实际开发中更好地使用和优化HashMap



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









