







1. HashMap特点
HashMap基于哈稀表(或者叫哈希表,不是指Hashtable)实现Map接口,它允许为null的key以及value,而且不保证映射的顺序,毕竟当容量到阈值时会进行扩容,原map中的所有元素会被重哈稀。HashMap经常拿来跟Hashtable进行对比,前者除了不同步以及允许null值外,其它大致上都跟后者差不多
HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls
既然扯到了Hashtable,肯定少不了ConcurrentHashMap。Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替Hashtable,但是Hashtable提供更强的线程安全性
2. 主要属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认初始容量:16,用位运算提高效率
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量,2^30=1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //大小总是为2^n
transient int size; //hashmap中当前元素数量
int threshold; //一般为capacity*loadFactor
final float loadFactor; //加载因子
transient int modCount; //hashmap在结构上被修改的次数,在迭代时,如果expectedModCount!=modCount则会快速失败3. 数据结构
在HashMap中,每一个元素(k-v对)都是一个Entry实体,利用数组以及链表两种结构构成底层的存储结构,如下图:
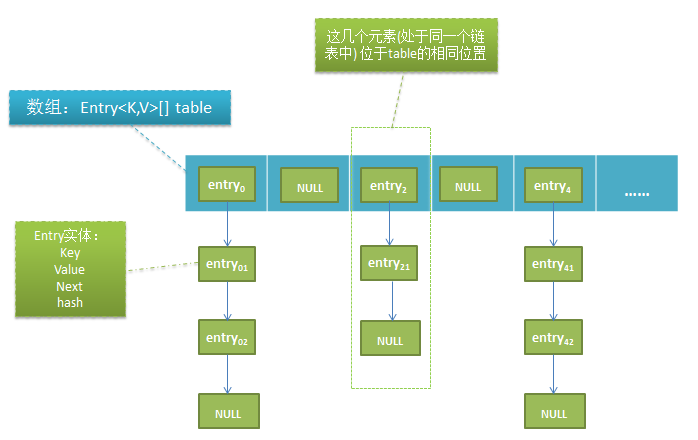
把数组table中每个元素比喻作一个桶(bucket),table保存着每个链表的头部,所以实际上只需要维护着table属性其实已经相当于管理着所有元素。在源码中把元素处于table的位置叫做bucketIndex,在下面会叫桶索引,而元素的bucketIndex则是由它自身的hashcode决定的,在上图中可以看得出,不同的元素可以有相同的bucketIndex(例如entry2->entry21,这些在同一个链表的中元素),而table[bucketIndex]只能容纳一个元素,所以以链表的方式把这些元素串起来。
无论我们要访问哪个元素时,只需要计算出元素的hashcode,定位到bucketIndex处的链表头,再遍历该链表,即可找到目标元素,这样的话性能的开销基本都在链表的访问。最极端的情况是所有的元素都处于相同链表中,所以元素越是均衡分布,性能越好。
4. 方法hash、indexFor
在HashMap中很多操作都会依赖hash,indexFor两个方法,hash是根据key来计算出高效的hashCode(原理解释),而indexFor是根据hashCode来计算出桶索引bucketIndex。
static int indexFor(int h, int length) {
//h为hashCode,length必须为2的n次方
return h & (length-1); //返回按位与的结果
}5. 添加元素
通过put(K key, V value)方法往HashMap中添加元素
public V put(K key, V value) {
if (table == EMPTY_TABLE) { //table还没初始化
inflateTable(threshold); //给table分配空间
}
if (key == null) //对于key==null的元素统一调用puForNullKey
return putForNullKey(value);
int hash = hash(key); //根据key计算元素的hashCode
int i = indexFor(hash, table.length); //根据hashCode计算bucketIndex
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//hashCode相等是key相同的前提
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} //从链表头table[i]开始遍历链表,并对比第一个元素,如果存在相同key的元素,则更新元素,返回旧元素,退出put方法
modCount++; //将会往hashmap中添加一个新的元素,属于结构上的修改
addEntry(hash, key, value, i); //添加一个新的元素到hashmap中
return null;
}整体理解put方法的话就是:对于HashMap中已经存在相同的key元素,则更新value,否则 插入一个新的元素,具体的步骤:
1.先判断table == EMPTY_TABLE,如果相等的话,则先初始化table,分配空间
private void inflateTable(int toSize) {
// roundUpToPowerOf2方法返回一个:
//1.比toSize大
//2.是2的次方
//3.最接近toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity); //重新计算hashSeed的值
}2.我们知道,HashMap是允许key和value为null的,对于key==null的元素调用putForNullKey
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} //从table[0]处的链表遍历,如果找到key==null的元素,则更新值
modCount++;
addEntry(0, null, value, 0); //在bucketInde==0处添加key==null的新元素
return null;
}在这个地方,为什么默认key==null的元素在table[0]处?key==null时是计算不出hashCode的,而table又是动态扩展的,那么0这个特殊位置应该是最适合的,不知道是不是这样理解。
3.通过hash方法计算出hashCode后,利用indexFor方法找到对应的table中的位置i
4.从链表头table[i]开始遍历,判断是否存在相同的key元素,如果重新,则更新value,返回旧值并终止操作,否则,进入步骤5。从源码中可以看出,判断key是否相同不仅要比较两key的值,而且还要对hashCode进行对比。
5.调用addEntry方法来添加指定key,value的元素,它负责判断并进行重新调整数组table的大小
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果hashmap的元素数量(size)已经到到阀值
//或者将要添加的元素的桶位置不为空,表示需要额外的空间
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //调整table大小为原本的2倍
hash = (null != key) ? hash(key) : 0; //计算hashCode
bucketIndex = indexFor(hash, table.length); //计算桶索引
}
createEntry(hash, key, value, bucketIndex); //创建一个新的元素实体并保存到相应位置
}6.调用createEntry方法构造元素(Entry实体),并保存
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //先记录新元素即将要保存的位置的元素
table[bucketIndex] = new Entry<>(hash, key, value, e); //构造出新元素,保存到table[bucketIndex],新元素的next为e
size++;
}从上面的代码可以看出,每次添加元素都会在链表头部插入,即新的元素都位于table数据中。
6. 扩容、重哈稀
就像ArrayList一样,HashMap也会在内部进行自动扩容,在上面的addEntry方法中,每次添加新元素时,如果数目达到了阀值,那么会调用resize进行扩容
void resize(int newCapacity) { //newCapacity必需是2^n,除非已经到达了MAXIMUM_CAPACITY
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}//如果容量已经到达了最大,那么不能再扩容
Entry[] newTable = new Entry[newCapacity]; //根据新容量创建新的数组
transfer(newTable, initHashSeedAsNeeded(newCapacity)); //把旧数组的元素转换到新的数组
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}在javadoc中强调了resize方法的参数必须为2的n次方,而且要比当前的容量大,除非容量已经达到了最大值MAXIMUM_CAPACITY
newCapacity the new capacity, MUST be a power of two; must be greater than current capacity unless current capacity is MAXIMUM_CAPACITY
为什么要强容量一定要是2的n次方,其实是为了使元素均衡分布在各个桶中,前面已经说过了,这对性能的影响是很大的,通过例子说明一下为什么是2的n次方就可以均衡分布:
我们取两个容量16和15,其中16=2^4符合要求,而15=2^4-1不符合要求。根据indexFor方法可以知道bucketIndex=h&(length-1)
其中h为hashCode,length为table长度,两者按位与操作后得出的是桶索引,如果我们有1~15个hashCode
- 当length=16时
| hashCode | 操作 | length-1 | = | 结果(bucketIndex) |
|---|---|---|---|---|
| 1 | & | 15 | = | 1 |
| 3 | & | 15 | = | 2 |
| 3 | & | 15 | = | 3 |
| 4 | & | 15 | = | 4 |
| 5 | & | 15 | = | 5 |
| 6 | & | 15 | = | 6 |
| 7 | & | 15 | = | 7 |
| 8 | & | 15 | = | 8 |
| 9 | & | 15 | = | 9 |
| 10 | & | 15 | = | 10 |
| 11 | & | 15 | = | 11 |
| 12 | & | 15 | = | 12 |
| 13 | & | 15 | = | 13 |
| 14 | & | 15 | = | 14 |
| 15 | & | 15 | = | 15 |
* 当length=15时
| hashCode | 操作 | length-1 | = | 结果(bucketIndex) |
|---|---|---|---|---|
| 1 | & | 15 | = | 0 |
| 3 | & | 15 | = | 2 |
| 3 | & | 15 | = | 2 |
| 4 | & | 15 | = | 4 |
| 5 | & | 15 | = | 4 |
| 6 | & | 15 | = | 6 |
| 7 | & | 15 | = | 6 |
| 8 | & | 15 | = | 8 |
| 9 | & | 15 | = | 8 |
| 10 | & | 15 | = | 10 |
| 11 | & | 15 | = | 10 |
| 12 | & | 15 | = | 12 |
| 13 | & | 15 | = | 12 |
| 14 | & | 15 | = | 14 |
| 15 | & | 15 | = | 14 |
根据两表格,明显是说明了当length=16时,最后得出的结果是分散的,没有重复,而length=15有很多重复结果,这种现象叫做碰撞。既然这样,如果我们通过指定一个非2的n次方容量来构造HashMap时,那会怎么样,其实在源码内部会在我们进行优化的,例如指定15为初始化容量,默认会计算得到最接近15、比15大、且是2的n次方的值,即16。看方法roundUpToPowerOf2 :
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); //如果toSize=15,则会得到capacity=16,具体的实现有兴趣可以看源码扩展的一个要点是,如何将原来的元素重新分配到新的数组中,看看transfer方法的具体实现
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //遍历数组元素
while(null != e) { //每个数组元素都是一个链表的表头,从表头开始遍历该链表
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key); //重新计算hashCode
}
int i = indexFor(e.hash, newCapacity); //重新计算桶索引bucketIndex
e.next = newTable[i];
newTable[i] = e; //将元素e插入newtable[i]
e = next;
}
}
}代码很简单,遍历所有桶的链表元素,重新计算元素的桶索引,然后将元素添加到新的哈稀表中
7. 迭代器
HashMap内部有3种迭代器:EntryIterator,KeyIterator,ValueIterator,它们的继承关系如下图:
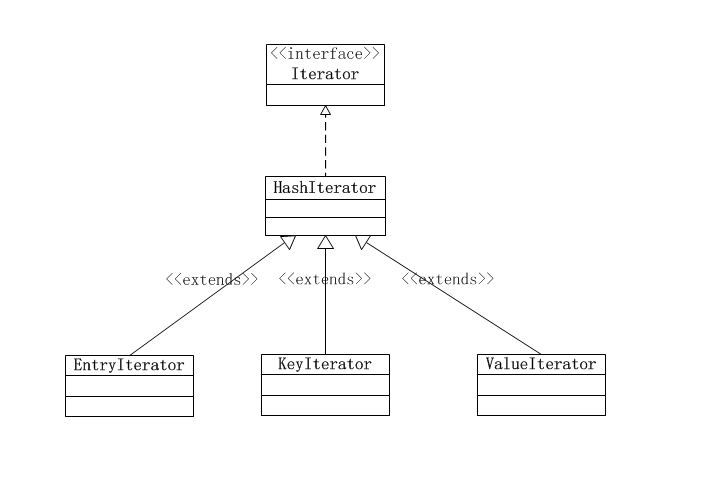
这3个迭代器的功能就正如它们各自的命名:
1. EntryIterator:可以迭代map中所有元素实体
2. KeyIterator:可以迭代map中所有元素实体的key值
3. ValueIterator:可以迭代map中所有元素实体的value值
不能像使用ArrayList那样直接通过iterator()来获得迭代器,在HashMap内部是有3个视图分别与这3个迭代器对应着:
EntryIterator –>EntrySet extends AbstractSet<Map.Entry<K,V>>
KeyIterator–>KeySet extends AbstractSet<Map.Entry<K,V>>
ValueIterator–>Values extends AbstractCollection
很容易理解,在HashMap中,key可为null,但不重复,而value可为任意值,所以用Set映射key合集和entry集合,而用Collection映射value集合,在javadoc中有如下的描述:
EntrySet : a Set view of the mappings contained in this map KetSet : a Set view of the keys contained in this map Values : a Collection view of the values contained in this map
未阅读源码之前,对ketSet()这些操作很不了解,总有一种误解,觉得调用这个方法后就把所有的key值添加到Set然后返回。其实视图这个概念在这里最为贴切不过,就像数据库视图一样:
视图是一个虚表,即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,在对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表
调用ketSet()后,返回的是KetSet对象,而这个对象就是HashMap中key集合的视图,真实的数据还是存储在HashMap中的table数组,简单用图来表示:
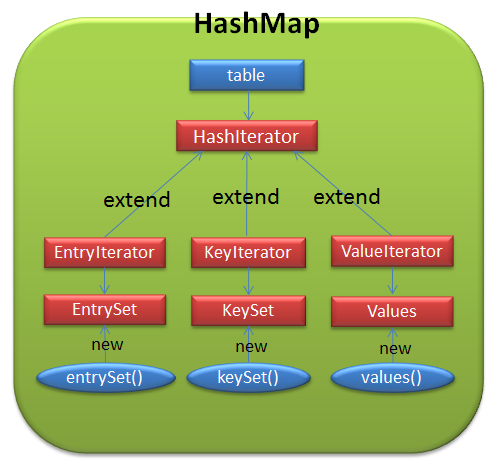
从图中可以看得出,table数组不仅是HashMap的数据源,还是迭代器(HashIterator,EntryIterator,KeyIterator,ValueIterator)以及视图(集合EntrySet,KeySet,Values)的数据源,对外提供了entrySet(),keySet(),values()方法
至于用什么方法来对HashMap进行迭代,其实根据它们各自的功能来选择即可,在网上也有看过一些文章对比entrySet()和keySet()两种方式的性能,感觉有点牵强,如果都用这两种方法来遍历元素实体(包括key和value),那当然是前者的性能更优,这无可置疑,毕竟后者获得key后还要重新计算hashCode来定位到桶索引,甚至还要遍历链表通过equals()找到目标key的元素。
8. 总结
断断续续写了一两周时间,没有对API作过多具体的分析,只量大概阐述了实现原理,虽然没什么技术含量,但一开始自己就定位在强迫自己形成好习惯(坚持写、总结,学习看源码),最后还是有收获在的,至少更清楚理解了HashMap原理,并稍微掀起jdk源码的一角面纱。
9. 参考
http://www.admin10000.com/document/3322.html
http://blog.csdn.net/ghsau/article/details/16890151
http://www.tuicool.com/articles/rQbAby















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









