









HDFS
Hadoop Distributed File System(Hadoop分布式文件系统)
HDFS
分布式存储,解决海量数据的存储
HDFS特点及原理
HDFS具有扩展性(横向扩展,任意添加数据节点datanode)、容错性(副本冗余机制默认3份 默认切片大小 1.0版本-64M 2.0~3.0版本 128M)、海量数量存储的特点
原理为将大文件切分成指定大小的数据块,并在分布式的多台机器上保.存多个副本
HDFS角色和概念
1.Client
切分文件、访问HDFS与NameNode交互获取文件位置信息、与DataNode交互读取和写入数据
2.Namenode
Master节点(主-管理者),管理HDFS的名称空间和数据块映射信息,配置副本策略,处理所有客户端请求
3.Secondarynode
定期同步NameNode,紧急情况下,可转正,NameNode的备胎
4.Datanode
数据存储节点,存储 实际 的数据
汇报存储信息给Namenode
5.Block
每块默认128MB大小
每块可以多个副本(默认3个)
HDFS示意图
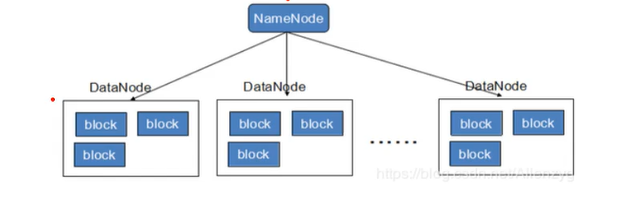
HDFS原理图
1、每个数据块3个副本,分布在两个机架内的节点,2个副本在同一个机架上,另外一个副本在另外的机架上!

2、心跳检测, datanode定期向namenode发送心跳消息。查看是否有datanode挂掉了

3、secondary namenode;定期同步元数据映像文件和修改日志,namenode发生故障, secondaryname会成为主namenode

HDFS写文件流程
【1】客户端将文件拆分成固定大小128M的块,并通知namenode
【2】namenode找到可用的datanode返回给客户端
【3】客户端根据返回的datanode,对块进行写入
【4】通过流水线管道流水线复制
【5】更新元数据,告诉namenode已经完成了创建新的数据块,保证namenode中的元数据都是最新的状态

HDFS读文件流程
【1】客户端向namenode发起读请求,把文件名,路径告诉namenode
【2】namenode查询元数据,并把数据返回客户端
【3】此时客户端就明白文件包含哪些块,这些块在哪些datanode中可以找到

HDFS特点
HDFS优点
高可靠性
高扩展性
高效性
高容错性
低成本
与一体机、商用数据仓库等相比, hadoop是开源的,项目的软件成本因此会大大降低
HDFS缺点
不能做到低延迟,由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟数据访问,不适合hadoop
不适合大量小文件存储,由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量,根据经验,每个文件、目录和数据块的存储信息大约占150字节
对于上传到HDFS上的文件,不支持修改文件, HDFS适合一次写入,多次读取的场景
HDFS相关
名词
NameNode
DataNode
写入文件流程
1.客户端将文件拆分成固定大小128M的块,并通知namenode
2.namenode找到可用的dataode返回给客户端
3.客户端根据返回的datanode ,对块进行写入
4.通过流水线管道流水线复制
5.更新元数据,告诉namenode已经完成了创建新的数据块,保证namenode中的元数据都是最新的状态
读取文件流程
1.客户端向namenode发起独立请求,把文件名,路径告诉namenode
2.namenode查询元数据,并把数据返回客户端
3.此时客户端就明白文件包含哪些块,这些块在哪些datanode中可以找到














 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









