







 本文介绍了推荐系统中的一些关键算法,包括非个性化模型(MovieAvg,TopPop)、邻域模型(CorNgbr,NNCosNgbr)以及隐语义模型(AsySVD,PureSVD)。通过对MovieLens(1M)数据集的实验,展示了各种算法的实现和评价标准,如召回率和准确率。
本文介绍了推荐系统中的一些关键算法,包括非个性化模型(MovieAvg,TopPop)、邻域模型(CorNgbr,NNCosNgbr)以及隐语义模型(AsySVD,PureSVD)。通过对MovieLens(1M)数据集的实验,展示了各种算法的实现和评价标准,如召回率和准确率。
写在前面:
本文作为关于推荐系统的算法实现的总结,作为一个大二学生,刚接触研究推荐系统,作出的总结一定有很多的错误,望见谅指正。在学习途中参考了很多技术博客、项亮博士的《推荐系统实践》,有引用到他人总结会的尽量标注。
转载请注明出处:http://blog.csdn.net/czzffff
在暑假期间,所在推荐系统小组针对MovieLens(1M)数据集,重现了一些论文的几个算法,包括:
非个性化模型(Non-personalized models):Movie Average(MovieAvg)和Top Popular(TopPop);
邻域模型(Neighborhood models):Correlation Neighborhood models(CorNgbr)和Non-normalized Cosine Neighborhood(NNCosNgbr);
隐语义模型(Latent Factor Model):Asymmetric-SVD(AsySVD)、SVD++和PureSVD
重现论文:【RecSys '10,2010,Cremonesi】 Performance of recommender algorithms on top-n recommendation task
相关论文:【KDD '08 ,2008,Koren】Factorization Meets the Neighborhood:a Multifaceted Collaborative Filtering Model
【CARS-2011,2011,Cremonesi】Top-N recommendations on unpopular items with contextual knowledge
一、数据集
(a) 名称:MovieLens(1M)
(b) 介绍:包括6,040个用户对于3,900部电影的1,000,209个评分。时间发表于2000年,包含ratings.dat、users.dat、movies.dat三个文件。
Ratings.dat:用户id、电影id、评分(1~5)、时间标; 格式:UserID::MovieID::Rating::Timestamp;
Users.dat: 性别、年龄、职位、邮编; 格式:UserID::Gender::Age::Occupation::Zip-codeAll;
Movies.dat:电影id、标题、流派; 格式:MovieID::Title::Genres。
(c) 来源:http://grouplens.org/datasets/movielens/
二、数据预处理
将三个文件整合成一行(一行为一条记录)为如下格式的文件:
userId,movieId,rating,timestamp,age,gender,occupation,zipcode,movietitle,year,genres
论文中提出,从这些记录中随机抽取1.4%的记录作为探测集(probe set),余下的作为训练集(training set),将探测集(probe set)中评分为5的全部记录提取作为测试集(test set)。
三、评价标准
(a)评判值:召回率、准确率
(b)算法:
1) 名称:召回率、准确率
2) 算法步骤:
a) 步骤一:从测试集中抽取一条记录(包括用户ID、电影ID);
b) 步骤二:在未评分集中随机选取1000个该用户u未评过分的电影id,加上测试集的一个电影ID,共1001个电影ID;
c) 步骤三:通过提出的评分规则对该1001部电影评分,并基于得到的评分降序排序得到一个top-N推荐列表;
d) 步骤四:推荐前N(N为0到20的整数)个列表中的电影,若前N个中包含测试集中第一步中的电影ID,算作命中一次;
e) 步骤五:继续按顺序抽取测试集中下一条记录,循环以上步骤,算出每一个N的命中次数;
f) 步骤六:命中次数除以测试集记录条数作为召回率;
g) 步骤七:召回率除以N值作为准确率。
(c)相关公式:
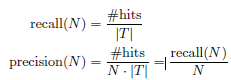
四、算法描述(部分算法有源码实现)
(一)非个性化模型(Non-personalized models)算法
(1) 算法名称:Movie Average(MovieAvg)
算法步骤:
a) 步骤一:算出所有被评价过的每一部电影的平均评分;
b) 步骤二:根据电影平均分作为评分规则,对推荐列表电影降序排序。
(2) 算法名称:Top Popularity(TopPop)
算法步骤:
a) 步骤一:算出每一部电影的被评分次数;
b) 步骤二:根据电影被评分次数作为评分规则,越高次数,排名越高,对推荐列表电影降序排序。
(二)邻域模型(Neighborhood models)算法:
(1) 算法名称:Correlation Neighborhood(CorNgbr)
算法步骤:
a) 步骤一: 通过baseline estimates公式,得到每个用户对每部电影的基础评分bui;
b) 步骤二:用皮尔逊相关系数法计算相关电影(有共同用户评价过的)相似度sij,并得出收缩相似度dij;
c) 步骤三:设定K值,取K个相似度最高的电影项目,用作基于用户的协同过滤公式的计算;
d) 步骤四:由以上步骤得到的相似度、基本分,通过CorNgbr公式计算得出评分
相关公式:


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









