






Kafka的Broker相关知识回归总结
1.ZooKeeper在Kafka中存储了那些信息?工作流程?
1.broker.ids(Kafka分区)
2.controller(辅助选举)
3.leader(节点信息)

2.新节点服役流程
1.准备一台干净的服务器
2.对哪个主题进行操作
3.形成计划
4.执行计划
5.验证计划
3.旧节点退役流程
1.要退役的节点不存储数据
2.退出节点
4.副本
1.副本的好处:提高可靠性
2.生产环境通常是两个,默认是一个
3.副本有leader,follower之分
4.AR=isr+osr,Leader跟Follower每30s进行一次通信
5.副本选举机制controller,保证在isr存活,按照AR的顺序依次选择
6.Leader挂了之后的选举,(LEO=每个副本最新的offset+1,HW=所有副本中最小的LEO)为了保证数据的一致性,将log文件中高于HW部分截取掉,从新的leader同步数据
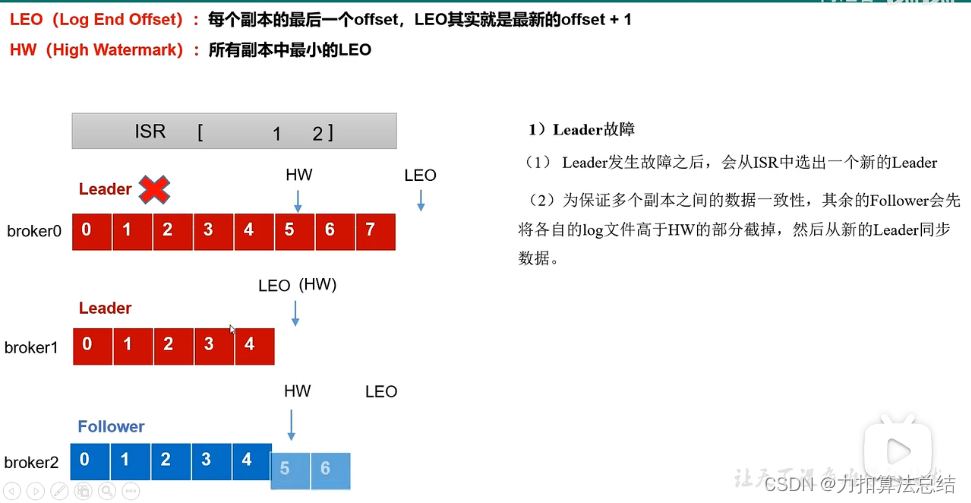
7.Folower挂了之后,自己恢复。将folower的log文件中高于HW部分截取掉,重新同步数据
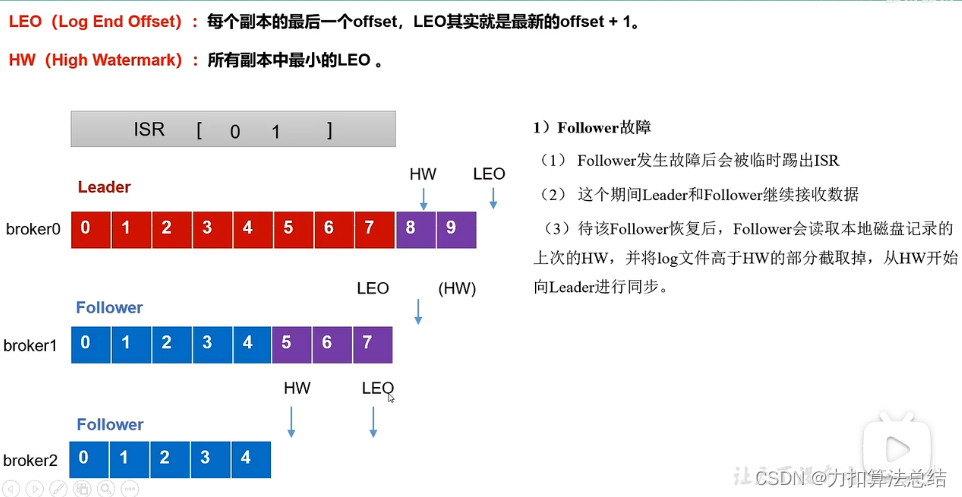
8.副本分配,默认保证负载均衡
9.手动副本分配。制定计划 ->执行计划-> 验证计划
10.leader partition的负载均衡 ->10%
11.手动增加副本因子
5.存储机制
broker -> topic -> partition -> log ->segment(1G,里面有 1. .log,2. .index(稀疏索引,每4kb记录一条索引),3. 时间戳)
6.删除数据
默认7天
1.直接删除(等segment所有数据过期,再进行删除)
2.压缩(按照每个key对应最新的value进行保存)
7.Kafka高效读写数据
1.Kafka本身是分布式集群,可以采用分区技术,并行度高
2.读数据采用稀疏索引,可以快速定位要要消费的数据
3.顺序写磁盘
4.页缓存和零拷贝(Kafka的Broker应用层不关心存储的数据,所以不用走应用层,传输效率更高)
尚硅谷讲的真的很棒,相关资料资源链接
链接:https://pan.baidu.com/s/15nsdIwLJ3vd_h9VAug3kbQ
提取码:wcdx















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









