







python环境2.7
今天是学习python第二天,做了一个抓取网页图片的爬虫。代码很简练。
#coding=utf-8
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)" size='
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
return imglist
html = getHtml("https://tieba.baidu.com/p/5052815069")
print getImg(html)
其中getHtml()是由地址获取类文件对象,然后通过正则表达式提取我们需要的图片下载链接。下边是循环保存图片,权威解释看知识库吧O(∩_∩)O~
下边是运行截图
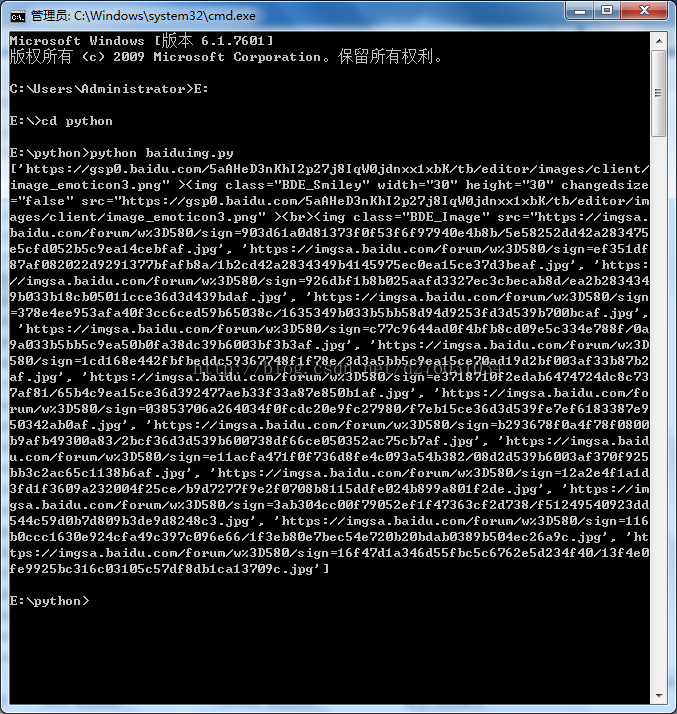
下边是成功截图:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











