







 本文介绍了如何使用Python获取数据,包括从TXT、CSV、JSON文件中读取,从服务接口获取以及从数据库中获取。重点讲解了pandas库在CSV处理中的作用,HTTP协议在接口请求中的应用,以及Python连接MySQL数据库的基本方法。
本文介绍了如何使用Python获取数据,包括从TXT、CSV、JSON文件中读取,从服务接口获取以及从数据库中获取。重点讲解了pandas库在CSV处理中的作用,HTTP协议在接口请求中的应用,以及Python连接MySQL数据库的基本方法。
本文代码与使用到的公开数据集可在 本人Github 中进行阅读与使用
如何理解数据
数据是指通过观察、测量或收集得到的信息集合。他的存在方式可以是数字、图像、文字、声音。
数据是数据分析的基础,整个数据分析过程通常包括以下几个步骤:
- 获取数据: 从数据库,接口服务,txt文件,scv文件等数据源拿到数据
- 数据清洗和预处理:对原始数据进行清洗、筛选、去除异常值或缺失值,并进行格式转换和标准化
- 探索性分析数据 (EDA) : 对数据进行可视化与统计分析。了解数据的分布特征,相关性。对数据有一个整体的认知。例如网络质量分析:我们单纯从数据层面上来看,可以发现当我们的访问时延越高,我们的下载速度会越差。在没有网络知识基础的情况下也能够知道,下载速度和时延是高度相关的。
- 数据建模与分析: 通过适当的统计方法、机器学习算法等,对数据进行建模。发现因此在数据下的潜在规律。
- 最终的解释性报告:画出老板想要的图表,得到有价值的结论。
整个数据分析生命周期里贯穿着对数据的操作
如何获取数据
从不同的文件格式获取数据
TXT
TXT: 纯文本文件,往往是没有任何格式或者样式的文本信息。当前很火的gtp的语料库多为这个格式。
接下来用一个简单的例子来说明如何读取TXT文件。
这里以小说 《诡异之主》为例子说明如何使用python读文件。再后续章节会介绍对文本进行词频统计,提取关键字,自动生成摘要的相关算法。
with open("《诡秘之主》.txt","r") as f:
for i in f.readlines():
print(i)
这里使用到的函数有:
- open() : 打开一个文件:若我们使用 ./文件名或者直接的文件名则可以读去到当前jupyter的同级文件下其运行效果为将文本中的内容打印在交互式单元格内。
- with 是 Python 中的一种上下文管理器,它可以用来管理资源的获取和释放。with 语句提供了一种更简洁、更安全的方式来处理文件、网络连接、数据库连接等资源的打开和关闭。在打开文件时通常会适用该功能,防止没有正确的关闭资源
- f.readlines() : readlines() 是 Python 文件对象的一个方法,用于一次性读取整个文件的内容,并将每行内容存储为一个字符串元素的列表。该方法可以将我们的文件内容读去到内存中存放在变量里,以便后续对他进行操作。
CSV
CSV(Comma-Separated Values)是一种常见的文本文件格式,用于存储表格数据。它是一种纯文本格式,可以通过逗号或其他字符(如分号、制表符等)作为字段之间的分隔符。
以下是 CSV 文件的一些特点和常见规则:
- 分隔符:CSV 文件使用特定字符作为字段之间的分隔符。逗号是最常见的分隔符,但也可以使用其他字符,如分号、制表符等。分隔符的选择通常取决于文件的要求和数据内容。
- 行:每一行表示一个数据记录。每行中的字段由分隔符进行分隔,字段的顺序对应于表格中的列。
- 引号:如果字段中包含分隔符或换行符等特殊字符,可以使用引号将该字段括起来。通常,双引号是用于引用字段的字符。
- 头部行:CSV 文件通常包含一个头部行,其中包含列名或字段名称。这样可以提供对每列数据的标识,方便后续处理和操作。
- 缺失值:如果某些单元格没有值,可以用空字符串或特定符号表示缺失值。
下面是一个示例,我们的乳腺癌分类数据集CSV文件:
"id","diagnosis","radius_mean","texture_mean","perimeter_mean","area_mean","smoothness_mean","compactness_mean","concavity_mean","concave points_mean","symmetry_mean","fractal_dimension_mean","radius_se","texture_se","perimeter_se","area_se","smoothness_se","compactness_se","concavity_se","concave points_se","symmetry_se","fractal_dimension_se","radius_worst","texture_worst","perimeter_worst","area_worst","smoothness_worst","compactness_worst","concavity_worst","concave points_worst","symmetry_worst","fractal_dimension_worst",
842302,M,17.99,10.38,122.8,1001,0.1184,0.2776,0.3001,0.1471,0.2419,0.07871,1.095,0.9053,8.589,153.4,0.006399,0.04904,0.05373,0.01587,0.03003,0.006193,25.38,17.33,184.6,2019,0.1622,0.6656,0.7119,0.2654,0.4601,0.1189
842517,M,20.57,17.77,132.9,1326,0.08474,0.07864,0.0869,0.07017,0.1812,0.05667,0.5435,0.7339,3.398,74.08,0.005225,0.01308,0.0186,0.0134,0.01389,0.003532,24.99,23.41,158.8,1956,0.1238,0.1866,0.2416,0.186,0.275,0.08902
84300903,M,19.69,21.25,130,1203,0.1096,0.1599,0.1974,0.1279,0.2069,0.05999,0.7456,0.7869,4.585,94.03,0.00615,0.04006,0.03832,0.02058,0.0225,0.004571,23.57,25.53,152.5,1709,0.1444,0.4245,0.4504,0.243,0.3613,0.08758
接下来我们使用python将文件进行读取
首先我们需要安装pandas库
pip install pandas -i https://pypi.douban.com/simple/
然后执行以下代码
import pandas as pd
df = pd.read_csv("./data/breast_cancer.csv")
df
完成将csv文件读入内存形成表格方便后续操作
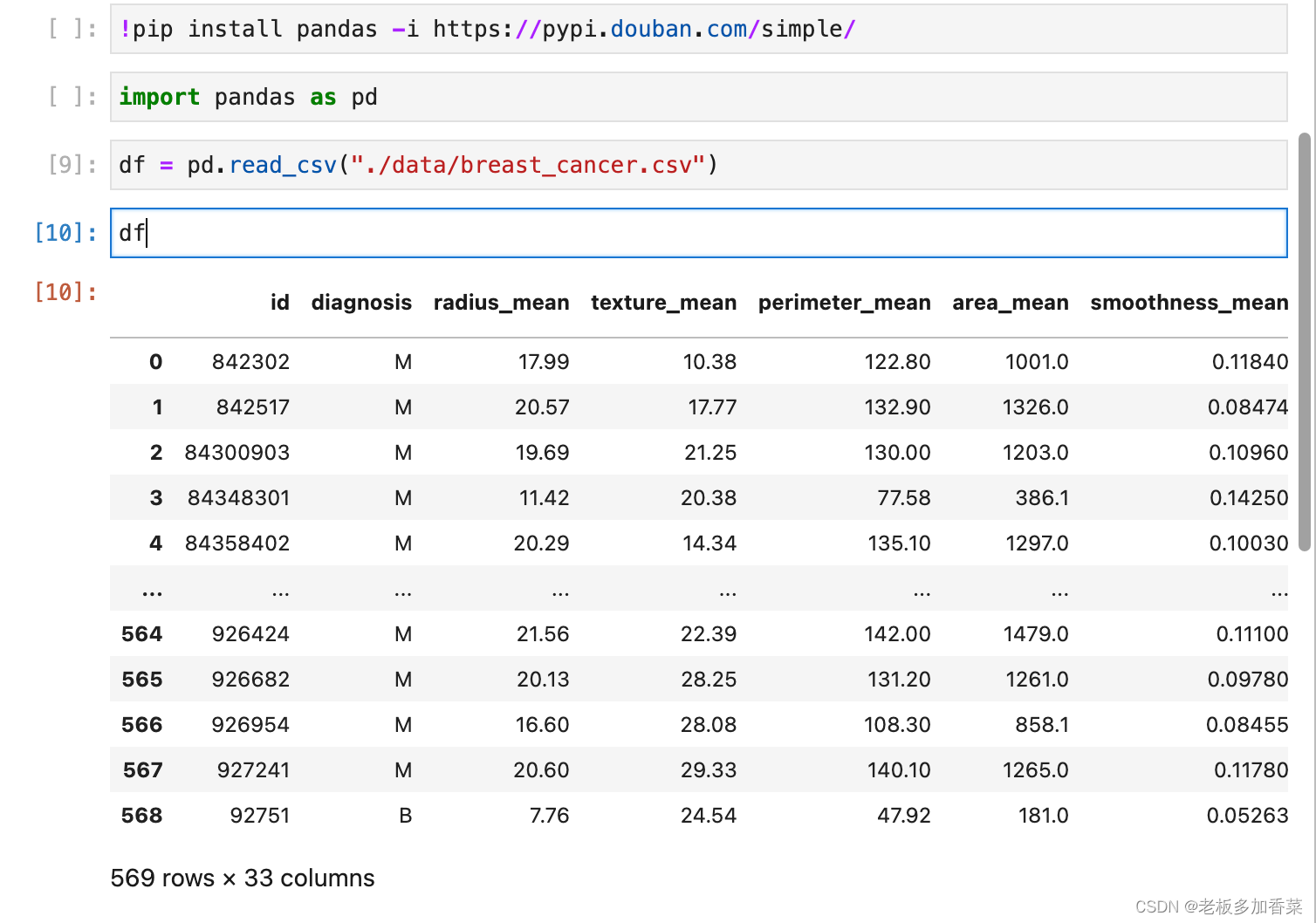
这里使用了一个强大的数据分析第三方库pandas 后续的百分之90数据分析操作基本都在使用这个库,因此需要好好掌握他的基础用法。
- 使用pip安装pandas: 其中 -i 表示使用指定的国内的镜像源进行下载。一般没有制定会访问到国外的源,若你的网络环境无法科学上网,那么可能需要下载两到三个小时
- import as : 给pandas包 取一个别名,后续应用不需要打六个字母只需要打 pd.function()
- pd.read_csv() : 可以根据需要进行配置。例如,可以指定分隔符、跳过行、指定列名等。具体的参数和用法可以参考 Pandas 文档中的相关说明。
JSON
JSON(JavaScript Object Notation)是一种常用的数据交换格式,用于存储和传输结构化数据。它基于JavaScript的语法,但已成为许多编程语言的通用格式。
JSON使用简洁的文本表示法来描述数据对象,具有易读性和易解析性。它由键值对(key-value pairs)组成,其中键是字符串,值可以是字符串、数字、布尔值、数组、对象或null。
以下是一个JSON示例:
{
"name": "John Smith",
"age" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









