







LinkedHashMap是HashMap的子类。使用了hashMap的构造方法。内部结构是hashMap + 双向环形链表。
Entry结构:记录了前后结点,并且也继承hashMap的entry。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}初始化:初始化都调用了hashMap的构造方法,默认初始化accessOrder成员变量为false。accessOrder可形成两种模式,查询模式,插入模式。
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* true模式时,查询操作会把此entry放在尾结点处,形成查询时间排序
* false(默认)时,是按照entry的插入顺序查出
*/
private final boolean accessOrder;
public LinkedHashMap(int initialCapacity, float loadFactor){
super(initialCapacity, loadFactor);
// 把accessOder模式赋值为false
accessOrder = false;
}
LinkedHashMap(int initialCapacity)
LinkedHashMap()
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)利用模板模式,重写了hashMap的init方法。
// hashMap类
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
// LinkedHashMap 类
private transient Entry<K,V> header;
void init() {
// 初始化头结点hash值为-1。
header = new Entry<>(-1, null, null, null);
// 形成双链表结构
header.before = header.after = header;
}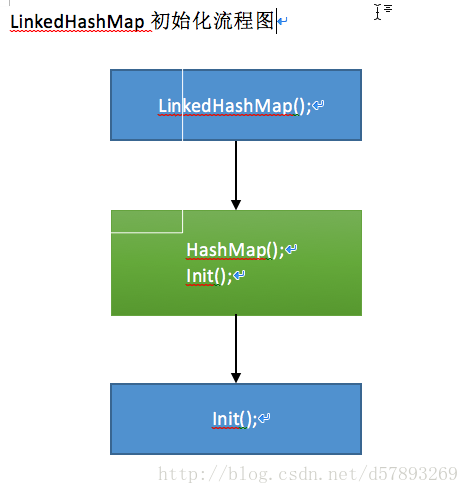
LInkedHashMap提供了4种初始化重载方式。内部调用了hashMap构造方法,赋值accessOrder模式,默认为false,可通过构造方法更改为true。重写了init方法,初始化一个双链表header头结点(hash值为-1,其他成员变量为null)。
get操作:
public V get(Object key) {
// 调用hashMap.get方法查找出节点位置
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 查询后对列表进行调整
e.recordAccess(this);
return e.value;
}
// 是否把节点移到尾处
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
// accessOrder默认为false
if (lm.accessOrder) {
lm.modCount++;
// 移除这个节点
remove();
// 添加此节点在尾节点
addBefore(lm.header);
}
}
/**
* 假设列表:1->2->3 1<-2<-3 删除2节点
* | |
* 1 3
* before = 1, after = 3
* 1.after = 3 // 1->3
* 3.before = 1 // 1<-3
* 把[2节点之后3节点]赋值给[2节点之前1节点]的后节点
* 把[2节点之前1节点]赋值给[2节点之后3节点]的前节点(发现数据结构的学习还是有用的!)
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* 假设列表:header->1->3 header<-1<-3 添加2节点(this=2)
*
* 2.after = header // 2->header
* 2.before = header.before // 2<-3 3->2->header
*
* header.bef = 2
*
*/
// existingEntry = lm.header;
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}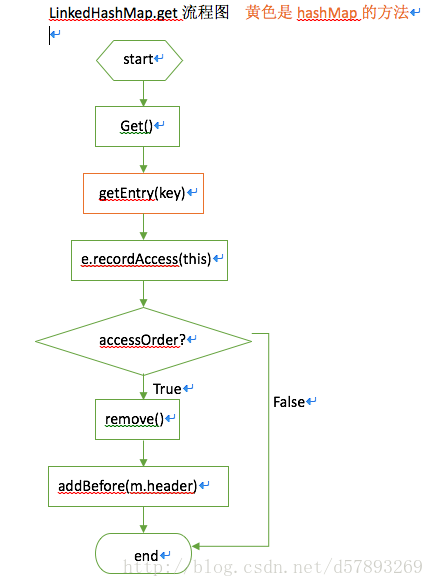
get操作是调用hashMap的get方法,查找后根据accessOrder值判断是否对双向链表进行调整。把查找节点移动到链表尾处。其中remove方法是移除这个节点在双向链表中,addBefore方法是把当前节点放到链表尾
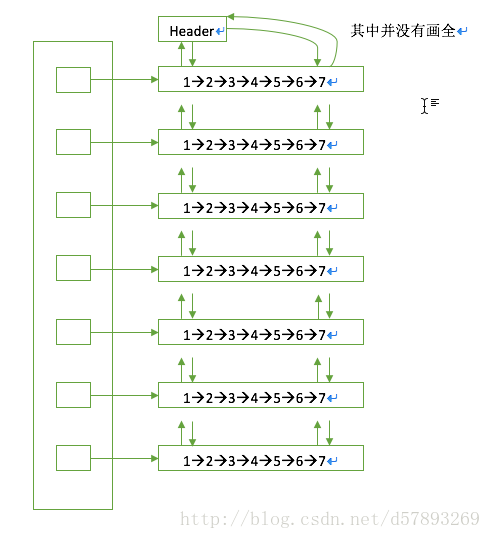
(其实双向链表是一个环形的,以header节点为头结点,则新加入元素就在链表尾了)
put方法:
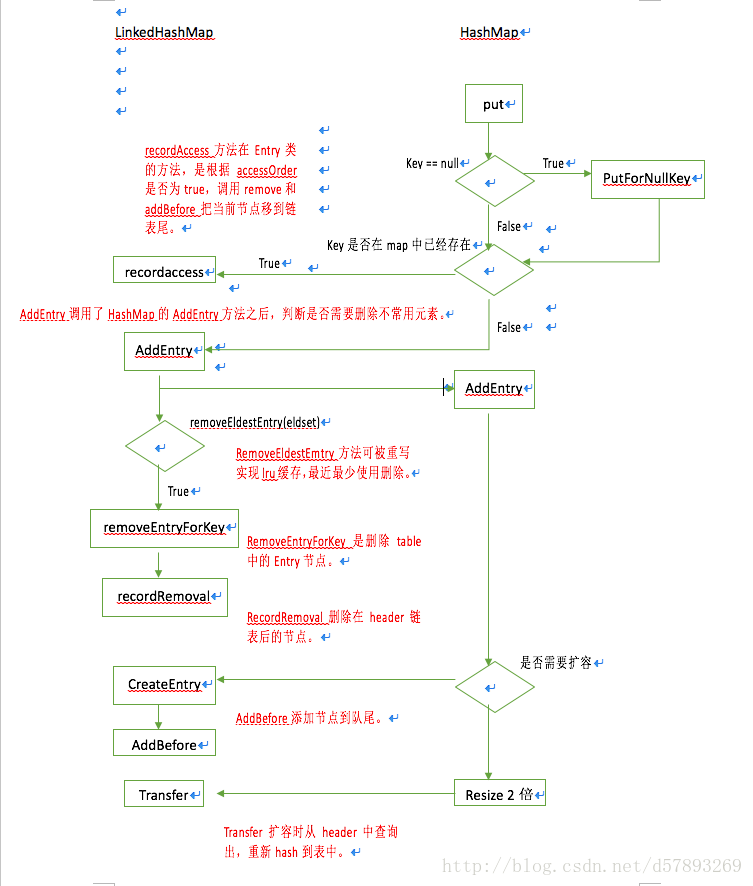
LinkedHashMap并没有重写hashMap的put方法。其内部还是调用还是调用了hashMap的put方法。
当put的key已经存在时,当前Entry会调用LinkedHashMap中Entry的recordaccess方法。这里会如果accessOrder的值为true时,会把当前查找entry放在双链表尾处。
当put的key不存在时,需要新创建Entry,调用LinkedHashMap的addEntry方法,首先会调用hashMap的addEntry方法,保证hashMap的正常逻辑。然后会调用removeEldestEntry方法判断是否删除老元素,这也就是LinkedHashMap可以实现LRU缓存的原理。(Least recent used的缩写,最近最少使用)我们可以通过重写这个removeEldestEntry返回true和初始化设置recordAccess为true来实现。
之前调用HashMap的addEntry方法还没有走完,里面会判断是否需要扩容,如果需要扩容,会调用LinekHashmap的transfer进行数据的转移,transfer里使用header双向列表重新hash插入table中,比hashMap的方法效率高,减少查询次数。
如果不需要扩容,直接调用LinkedHashMap的createEntry方法去添加节点。
ps:这里并没有写入过多的代码,需要读者自己去查看本机源码,jdk1.7.
总结:
LinkedhashMap大多方法使用的是hashMap,底层是Entry增加了before和after两个节点,把所有节点以环形双链表结构再连接起来。
可用来实现LRU最近最少使用缓存原则,是accessOrder成员变量和removeEldestEntry方法。accessOrder可通过构造方法改变为true,在put和get时把当前Entry放在队尾(严格来讲没有队尾,因为是环形,以header为参照物),removeEldestEntry可通过重写返回true,删除header节点之后一个元素。以此来删除最不长使用元素。awayls put /get last out 。
get方法是使用hashMap方法的get查找方式,先找到table中的位置,再循环链表。LinkedList增加accessOrder操作。
put中重写了record access,AddEntry,CreateEntry,Transfer方法。
put方法重写recordaccess方法增加accessOrder操作。AddEntry时是否删除过期节点。CreateEntry在table中和双链表结构中增加相同节点。Transfer利用循环双链表扩容,减少操作,提高效率。
Ps:LinkedHashMap的源码研究到这里就先截止了,生命还有很多事要做,技术上还有很多要学,其中大部分的知识理论也是从网上众多博客参考而来,但完全不是照抄,是有个人理解的。双向环状链表是真的手写bug才看出来的,博客里有说头插有说尾插的。文章中有很多知识点重复出现,是为了让大家能够记住,采用总分总的作文模式来写的。写这个技术文章,花了很长时间,也画了图解释说明,主要是想自己加深理解,希望能够帮到迷茫的同学们,个人还有很多不足,希望大家提出。















 5336
5336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









