







一个flink程序,其实就是对DataStream的各种转换。具体可以分成以下几个部分:
- 获取执行环境(Execution Environment)
- 读取数据源(Source)
- 定义基于数据的转换操作(Transformations)
- 定义计算结果的输出位置(Sink)
- 触发程序执行(Execute)

一、执行环境(Execution Environment)
flink 程序可以在各种上下文环境中运行:我们可以在本地JVM中执行程序,也可以提交到远程集群上运行。
不同的环境代码的提交运行过程会有所不同。这就要求我们再提交作业执行计算时,必须获取当前 flink 的运行环境,从而建立起与flink框架之间的联系。只有获取了环境上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
1.1 创建执行环境
执行环境是 StreamExecutionEnvironment 类的对象。创建执行环境的方式,就是调用这个类的静态方法。
1.1.1 getExecutionEnvironment
getExecutionEnvironment 方法会根据当前运行的方式,自行决定该返回什么样的运行环境。如果程序是独立运行的,就返回一个本地执行环境;如果创建了jar包然后从命令行调用后提交到集群执行,那么久返回集群的执行环境。
val env = StreamExecutionEnvironment.getExecutionEnvironment1.1.2 createLocalEnvironment
返回一个本体执行环境。可以在调用时传入一个参数,指定默认的并行度。如果传入,默认就是本地的CPU核心数。
val localEnvironment = StreamExecutionEnvironment.getExecutionEnvironment()1.1.3 createRemoteEnvironment
返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定在集群中运行的jar包。
获取执行环境后,还可以对执行环境进行灵活的设置。如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制等。
val localEnvironment = StreamExecutionEnvironment
.getExecutionEnvironment(
"host", // JobManager主机名
1234, // 进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
) 1.2 执行模式(Execution Mode)
// 批处理环境
// 1.12.0版本起,可以通过“执行模式: execution mode”实现切换
val batchEnv = ExecutionEnvironment.getExecutionEnvironment
// 流处理环境
val env = StreamEnvironment.getExecutionEnvironment
- 流执行模式(STREAMING)
DataStream API经典模式,一般用于需要持续实时处理的无界数据流。默认情况下使用的就是流执行模式。
- 批执行模式(BATCH)
专门用于批处理的执行模式,这种模式下,flink处理作业的方式类似于MapReduce。对于不会持续计算的有界数据,这种模式处理会更方便。
配置方式: 1. 命令行配置 bin/flink run -Dexecution.runtime-mode=BATCH 2. 代码配置(不推荐) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setRuntimeMode(RuntimeExecutionMode.BATCH)
- 自动模式(AUTOMATIC)
根据数据源是否有界,来自动选择执行模式
总结:用 BATCH 处理批数据,用 Streaming 处理流数据。
1.3 触发程序执行
写完输出(sink)操作之后不代表程序已经结束。这是因为main()方法被调用时,只定义了作业的每个执行操作,然后添加到数据流图中,这时候并没有真正的处理数据。
Flink是事件驱动的,只有等数据到来,才会触发真正的计算,是懒执行/延迟执行。所以我们需要显式的调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果。
env.execute()二、源算子(Source)
flink可以从各种源获取数据,然后构建DataStream进行转换处理。数据的输入来源就是数据源,读取数据的算子就是源算子(Source)
2.1 准备工作
我们可以定义一个样例类Event,字段如下:
| 字段名 | 数据类型 | 说明 |
| id | String | 用户id |
| timestamp | Long | 时间戳 |
| temperature | Double | 温度 |
//定义样例类 温度传感器
case class SensorReading(id:String,timestamp:Long,temperature:Double)2.2 从元素中读取数据
从元素中读取数据
val stream1: DataStream[SensorReading] = env.fromElements(
SensorReading("北京",1684201960L,23.5),
SensorReading("南京",1684201960L,32.8)
)2.3 从集合中读取数据
从集合中读取数据
val temp = List(
SensorReading("北京",1684201960L,23.5),
SensorReading("南京",1684201960L,32.8)
)
val stream2: DataStream[SensorReading] = env.fromCollection(temp)2.4 从文件中读取数据
从文件中读取数据
val path = "F:\\Server\\flink\\resources\\sensor.txt"
val value: DataStream[String] = env.readTextFile(path)2.5 从Socket读取数据
socket并行度默认为1,且不够稳定,一般仅测试使用。
val parameterTool = ParameterTool.fromArgs(args)
val hostname = parameterTool .get("host")
val port = parameterTool .get("port")
val lineDataStream = env.socketTtextStream(hostname, port)2.6 从Kafka读取数据
kafka进行数据的收集与传输,flink进行分析与计算,这种架构目前已经称为很多企业的首选。但是Kafka与flink的连接比较复杂,flink内部没有提供预实现的方法,所以我们需要通过调用addSource()来传入一个 SourceFunction 的实现类。而同时,Flink官方提供了连接工具flink-connector-kafka 帮我们实现了一个消费者 FlinkKafkaConsumer ,用来读取Kafka数据的 SourceFunction。
1> 导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>2> 传入FlinkKafkaConsumer实例对象
object SourceTest {
def main(args: Array[String]): Unit = {
// 1. 创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 用Properties保存Kafka连接的相关配置
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"sensorgroup1")
// 3. 调用 env.addSource()
val stream1 = env.addSource(new FlinkKafkaConsumer[String](
"sensor", // topic
new SimpleStringSchema(), // 当前值的反序列化器
properties // prop
))
// 4. 输出
stream1.print()
// 5. 启动
env.execute()
}
}2.7 读取自定义源算子
class MySensorSource() extends SourceFunction[SensorReading]{
// 标志位
var running = true
// run方法:不停循环,发送数据
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
// 1. 随机数生成器
val random = new Random()
// 2. 用标志位作为循环判断的条件,不断发送数据
while (running){
val i = random.nextInt()
// 3. 调用sourceContext的方法向下游发送数据
sourceContext.collect(SensorReading("生成:"+i,1,1))
}
Thread.sleep(500)
}
// cancel方法:定义标志位,用于run中断的控制
override def cancel(): Unit = {
running = false
}
}val env = StreamExecutionEnvironment.getExecutionEnvironment
读取自定义的数据源
val stream1 = env.addSource(new MySensorSource)
stream1.print()
env.execute()三、转换算子(Transformation)
数据源读入数据之后,可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。可以对一条数据流进行转换操作,也可以进行分流、合流等多流转换操作,从而组合成复杂的数据流拓扑。
3.1 基本转换算子
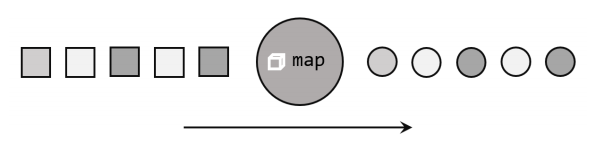
1. 映射 map
一一映射,消费一个元素就产出一个元素。
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformMapTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(Event("Mary","./home",1000L),Event("Bob","./cart",2000L))
// 提取每次点击事件的用户名
// 1. 使用匿名函数
stream.map( _.user ).print("1")
// 2. 实现 MapFUnction 接口
stream.map(new MyMapFunction).print("2")
env.execute()
}
class MyMapFunction extends MapFunction[Event, String]{
override def map(t: Event): String = {
t.user
}
}
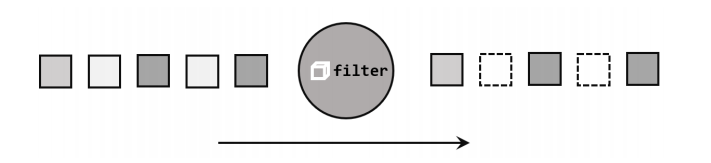
}2. 过滤 filter
对数据流执行一个过滤,通过一个布尔表达表达式设置过滤条件。
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformFilterTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(Event("Mary","./home",1000L),Event("Bob","./cart",2000L))
// 提取每次点击事件的用户名
// 1. 使用匿名函数
stream.filter( _.user=="Mary" ).print("1")
// 2. 实现 FilterFUnction 接口
stream.filter(new MyFilterFunction).print("2")
env.execute()
}
class MyFilterFunction extends FilterFunction[Event]{
override def filter(t: Event): Boolean = t.user=="Bob"
}
}
3. 扁平映射 flatMap
将数据流中的整体(一般为集合类型)拆分成一个个的个体使用。消费一个元素,可以产生0个到多个元素。 先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。

import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
import org.apache.flink.util.Collector
object TransformFlatmapTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice","./cart", 3000L)
)
// 提取每次点击事件的用户名
stream.flatMap( new MyFlatMap ).print()
env.execute()
}
// 自定义实现FlatMapFunction
class MyFlatMap extends FlatMapFunction[Event, String]{
override def flatMap(t: Event, collector: Collector[String]): Unit = {
// 如果当前数据是Mary的点击事件,那么就直接输出user
if (t.user == "Mary"){
collector.collect(t.user)
}
// 如果当前数据是Bob的,那么就输出user和url
else if (t.user == "Bob"){
collector.collect(t.user)
collector.collect(t.url)
}
}
}
}
3.2 聚合算子
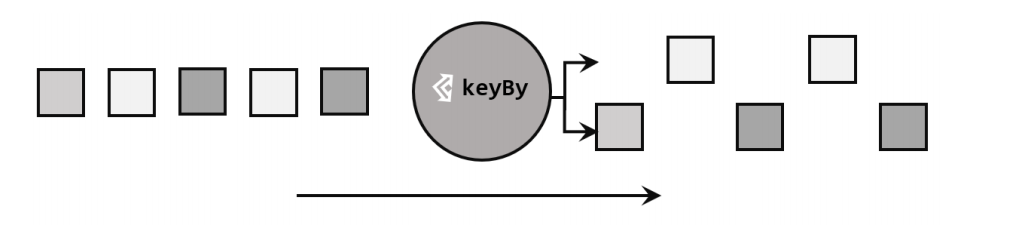
1. 按键分区 keyBy
DataStream是没有直接进行聚合的API的。所以如果需要聚合,需要先进行分区操作。
keyBy()通过指定键key,将一条流从逻辑上划分成不同的分区partitions,也就是并行处理的子任务,对应着任务槽task slots。基于不同的key,流中的数据将被分配到不同的分区中去,下一步算子将会在同一个slot中进行处理。
对于相同的key,一定会被分到同一个分区。不同的key值可能会被分到同一个分区,也可能被分到不同分区。
键选择器
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformAggTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice","./cart", 3000L),
Event("Mary", "./prod?id=1", 4000L),
)
// 1. 使用lambda表达式
stream.keyBy( data => data.id )
或
stream.keyBy( _.id )
// 2. 使用键选择器
stream.keyBy( new MyKeySelector()
env.execute()
}
class MyKeySelector() extends KeySelector[Event, String]{
override def getKey(in: Event): String = in.user
}
}
2. 简单聚合
如sum()、min()、max()、minBy()。聚合方法在调用时,也需要传入参数。但不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
minBy()和min()类似,都是用于简单聚合的函数,求指定字段的最小值。
min() 只计算指定字段的最小值,其他字段回保留最初的第一个数据的值。
minBy() 会返回包含字段最小值的整条数据。
对于聚合计算而言,先进行 keyBy( ),得到 keyedStream ,在进行聚合得到,得到 dataStream 类型。
stream.keyBy(_.user).max("timestamp").print()3. 归约聚合 reduce
与简单聚合类似,reduce()操作也会将KeyStream转换为DataStream。不会改变流的元素数据类型,所以输出类型和输入类型一致。
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformReduceTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice", "./cart", 3000L),
Event("Mary", "./prod?id=1", 4000L),
)
// reduce规约聚合
// 提前当前最活跃用户
stream.map( data => (data.user, 1L ))
.keyBy(_._1)
.reduce( new MySum() ) // 统计每个用户的活跃度
.keyBy( data => true ) // 将所有数据按照同样的 key 分到同一个组中
.reduce( (state,data)=> if(data._2>state._2) data else state ) // 选取当前最活跃的用户
.print()
env.execute()
}
class MySum extends ReduceFunction[(String, Long)]{
override def reduce(t: (String, Long), t1: (String, Long)): (String, Long) = ( t._1, t._2 + t1._2 )
}
}3.3 用户自定义函数UDF
Flink 的 DataStream API 编程风格其实是一致的:基本上都是基于 DataStream 调用一个方
1. 函数类
——实现一个自定义的函数类
// 通过传入自定义FilterFunction实现过滤
val stream = clicks.filter( new FlinkFilter )
// 自定义FilterFunction函数类
class FlinkFilter extends FilterFunction[Event]{
override def filter(value: Event): Boolean = value.url.contains("home")
}——使用匿名类
stream.filter( new FilterFunction[Event]{
override def filter(t: Event): Boolean = t.url.contains("prod")
} )——使用 lambda 表达式
stream.filter( _.url.contains("prod") )import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformUDFTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice", "./cart", 3000L),
Event("Mary", "./prod?id=1", 4000L),
)
// 测试UDF的用法,筛选url中包含某个关键字home的Event事件
// 1. 实现一个自定义的函数类
stream.filter( new MyFilterFunction("prod") ).print("1")
// 2. 使用匿名类
stream.filter( new FilterFunction[Event] {
override def filter(t: Event): Boolean = t.url.contains("prod")
}).print("2")
// 3. 使用lambda表达式
stream.filter(_.url.contains("prod")).print("3")
env.execute()
}
class MyFilterFunction(keyWord: String) extends FilterFunction[Event]{
override def filter(t: Event): Boolean = t.url.contains("keyWord")
}
}2. 富函数类
富函数类是 DataStream API 的一个函数类的接口,所有的 flink 函数类都有其 rich 版本。
与常规函数类不同主要在于:富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,可以实现更复杂的功能。几乎每一个算子都有对应的rich版本
典型的生命周期有:
open()方法:
Rich Function的 初始化方法,开启一个算子的生命周期。当一个算子的实际工作方法被调用之前,会先调用 open() 方法
close()方法:
生命周期的最后一个调用方法。
在下面的代码中,getRuntimeContext()的作用是获取运行时上下文信息。其提供了访问与运行时环境相关的属性和方法。
核心逻辑:
// 自定义一个RichMapFunction,测试富函数类的功能
stream.map( new MyRichMap() )
class MyRichMap() extends RichMapFunction[Evnet, Long]{
override def open(parameters: Configuration): Unit = {
println("索引号为:"+ getRuntimeContext.getIndefOfThisSubtask + "的任务开始")
}
override def map(in: Event): Long = {
in.timestamp
}
override def close(): Unit = {
println("索引号为:"+ getRuntimeContext.getIndefOfThisSubtask + "的任务结束")
}
}import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformRichFunctionTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice", "./cart", 3000L),
Event("Mary", "./prod?id=1", 4000L),
)
// 自定义一个 RichMapFunction,测试富函数类的功能
stream.map( new MyRichMap() ).print()
env.execute()
}
class MyRichMap() extends RichMapFunction[Event, Long]{
override def open(parameters: Configuration): Unit =
println("索引号为:" + getRuntimeContext.getIndexOfThisSubtask + "的任务开始")
override def map(in: Event): Long = in.timestamp
override def close(): Unit = {
println("索引号为:" + getRuntimeContext.getIndexOfThisSubtask + "的任务结束")
}
}
}
调整并行度:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
object TransformRichFunctionTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice", "./cart", 3000L),
Event("Mary", "./prod?id=1", 4000L),
)
// 自定义一个 RichMapFunction,测试富函数类的功能
stream.map( new MyRichMap() ).print()
env.execute()
}
class MyRichMap() extends RichMapFunction[Event, Long]{
override def open(parameters: Configuration): Unit =
println("索引号为:" + getRuntimeContext.getIndexOfThisSubtask + "的任务开始")
override def map(in: Event): Long = in.timestamp
override def close(): Unit = {
println("索引号为:" + getRuntimeContext.getIndexOfThisSubtask + "的任务结束")
}
}
}

3.4 物理分区
1. 随机分区shuffle
随即分区服从均匀分布,可以把流中的数据随机打乱,均匀地传递到下游任务分区。如下图所示。

val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource( new ClickSource )
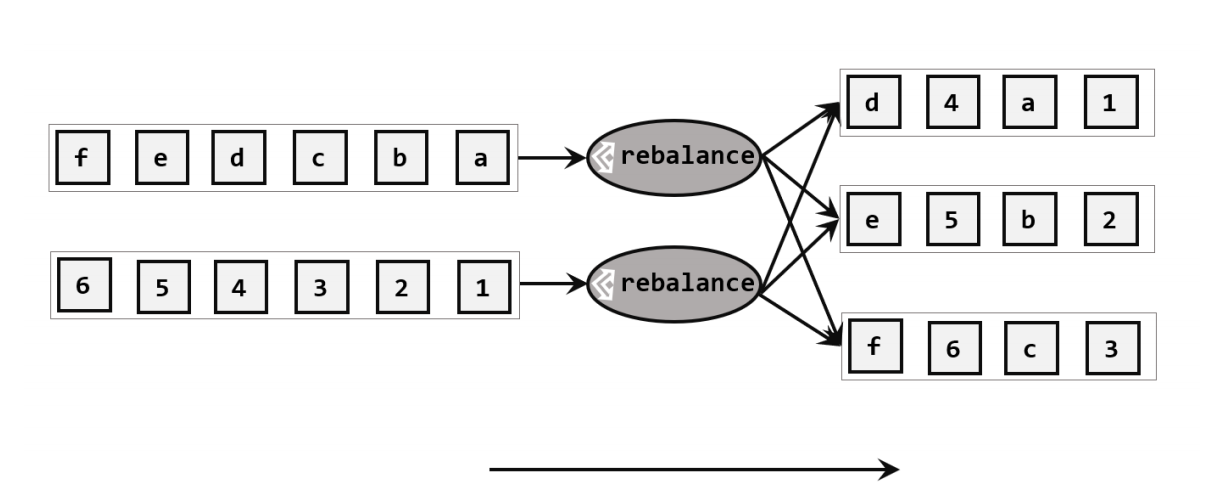
stream.shuffle.setParallelism(4)2. 轮询分区 Round-Robin
按照先后顺序将数据依次分发。通过调用DataStream的rebalance()方法,实现轮询重分区。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource( new ClickSource )
stream.rebalance.setParallelism(4)3. 重缩放分区 rescale
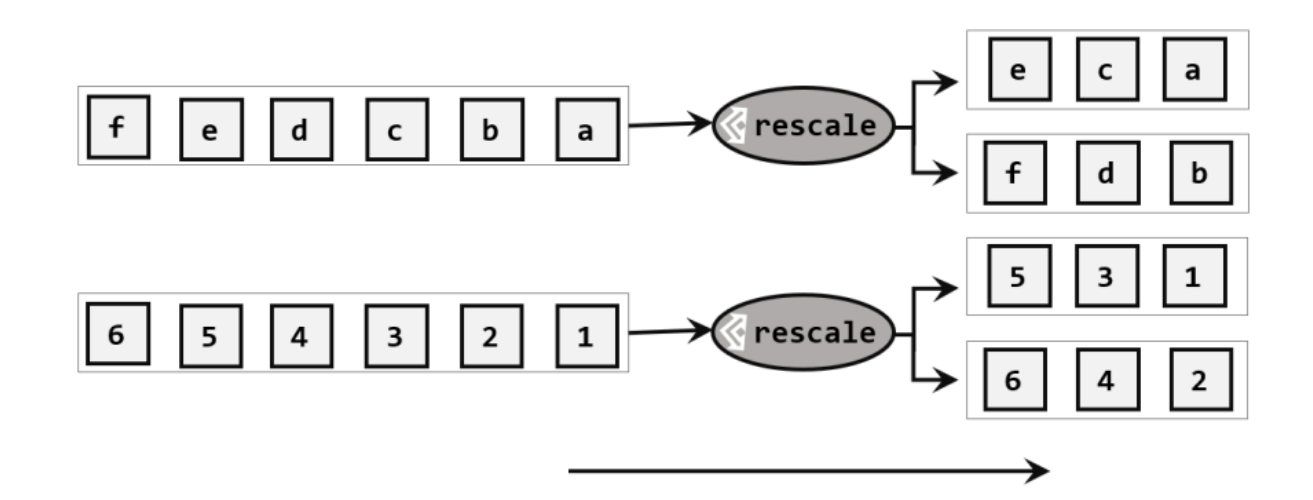
重缩放分区与轮询分区类似,当调用rescale()方法时,底层也是使用轮询,但是只会讲数据轮询发送到下游并行任务的一部分中。
如果理解成发牌,rebalance()是每个发牌人都面向所有人发牌;而rescale()是分成小团体,发牌人只给自己团体内的所有人轮流发牌。所以当下游任务数量是上有任务数量的整数倍时,rescale()的效率明显会更高。
object RescaleExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 使用匿名类的方式自定义数据源,这里使用了并行数据源函数的富函数版本
env
.addSource(new RichParallelSourceFunction[Int] {
override def run(sourceContext: SourceFunction.SourceContext[Int]): Unit = {
for (i <- 0 to 7) {
// 将偶数发送到下游索引为 0 的并行子任务中去
// 将奇数发送到下游索引为 1 的并行子任务中去
if ((i + 1) % 2 == getRuntimeContext.getIndexOfThisSubtask) {
sourceContext.collect(i + 1)
}
}
}
// 这里???是 Scala 中的占位符
override def cancel(): Unit = ???
})
.setParallelism(2)
.rescale
.print()
.setParallelism(4)
env.execute()
}
}4. 广播 broadcast
经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
object BroadcastTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 读取数据源,并行度为1
val stream = env.addSource(new ClientSource)
// 经过广播后打印输出,并行度为4
stream.broadcast.print("broadcast").setParallelism(4)
env.execute()
}
}5. 全局分区 global
通过.global()方法,将所有的输入流数据都发送到下游算子的第一个并行子任务中去。对程序压力很大,谨慎使用。
6. 自定义分区 Custom
当flink提供的所有分区策略都不能满足用户需求时,可以通过使用partitionCustom()方法来自定义分区策略。
partitionCustom()方法传参:
- 自定义分区器(Partitioner)对象
- 应用分区器的字段
object TransCustomPartitioner {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromElements(1,2,3,4,5,6,7,8)
.partitionCustom(
// 根据 key 的奇偶性计算出数据将被发送到哪个分区
new Partitioner[Int] {
override def partition(key: Int, numPartitions: Int) = key % 2
},
// 以自身作为key
data => data
).print()
env.execute()
}
}四、输出算子(Sink)
4.1 输出到外部系统
与 source 类似,一般情况下sink算子的创建是通过调用 DataStream 的 addSink() 方法来实现的。
4.2 输出到文件
flink有一些输出到文件的预实现方法,如writeAsText()、writeAsCsv()。但是对于大数据来说,这种方法过于简单,无法满足分布式的需求。StreamingFileSink支持行编码和批量编码,这两种不同的方式都有各自的构造器,可以直接调用StreamingFileSink的静态方法:
行编码:StreamingFileSink.forRowFormat( basePath, rowEncoder )
批量编码:StreamingFileSink.forBulkFormat( basePath, bulkWriterFactory )
stream.addSink( StreamFileSink.forRowFormat(
new Path("F:\Server\flink\resources\out1.txt"),
new SimpleStringEncoder[String]("UTF-8")
) )4.3 输出到Kafka
flink为Kafka提供了source和sink的连接器,我们可以用它方便地从Kafka读写数据。而且flink和Kafka的连接器提供了端到端的精确一次保证。
object SinkToKafka {
def main(agrs: Array[String]): Unit = {
// 1. 配置环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 2. 编辑Kafka环境
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"sensorgroup1")
// 3. 读取文件
val stream = env.readTextFile("input/clicks.csv")
// 4. 数据处理后写入到Kafka
stream.addSink( new FlinkKafkaProducer[String](
"clicks",
new SimpleStringSchema(),
properties
) )
// 5. 执行
env.execute()
}
}
4.4 输出到HBase
添加对应pom依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.3.5</version>
</dependency>main函数中调用addSink方法
dataStream.addSink(new MyHbaseSink)实现MyHbaseSink方法
class MyHbaseSink extends RichSinkFunction[SensorReading] {
var connection: Connection = _
var mutator: BufferedMutator = _
override def open(parameters: Configuration): Unit = {
val configuration: conf.Configuration = HBaseConfiguration.create()
configuration.set(HConstants.HBASE_DIR, "hdfs://192.168.78.20:9000/hbase")
configuration.set(HConstants.ZOOKEEPER_QUORUM, "192.168.136.20")
configuration.set(HConstants.CLIENT_PORT_STR, "2181")
connection = ConnectionFactory.createConnection(configuration)
val params: BufferedMutatorParams = new BufferedMutatorParams(TableName.valueOf("ha:test"))
params.writeBufferSize(10*1024*1024)
params.setWriteBufferPeriodicFlushTimeoutMs(5*1000L)
mutator = connection.getBufferedMutator(params)
}
override def close() = {
connection.close()
}
override def invoke(value: SensorReading, context: SinkFunction.Context) = {
val put = new Put(Bytes.toBytes(value.id + value.temperature + value.timestamp))
put.addColumn("sensor".getBytes(), "id".getBytes(), value.id.getBytes())
put.addColumn("sensor".getBytes(), "timestamp".getBytes(), value.timestamp.toString.getBytes())
put.addColumn("sensor".getBytes(), "temperature".getBytes(), value.temperature.toString.getBytes())
mutator.mutate(put)
mutator.flush()
}
}4.5 输出到MySQL
添加依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>main函数中调用addSink方法
dataStream.addSink(new MyJdbcSink)实现MyJdbcSink方法
class MyJdbcSink extends RichSinkFunction[SensorReading]{
var connection: Connection = _
var insertState: PreparedStatement = _
var updateState: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
connection = DriverManager.getConnection("jdbc:mysql://192.168.136.20:3306/kb21?useSSL=false","root","root")
insertState = connection.prepareStatement("insert into sensor_temp(id, temp) value(?,?)")
updateState = connection.prepareStatement("update sensor_temp set temp=? where id=?")
}
override def invoke(value: SensorReading, context: SinkFunction.Context): Unit = {
updateState.setDouble(1,value.temperature)
updateState.setString(2, value.id)
val i: Int = updateState.executeUpdate()
if (i==0){
insertState.setString(1,value.id)
insertState.setDouble(2,value.temperature)
insertState.execute()
}
}
override def close(): Unit = {
insertState.close()
updateState.close()
connection.close()
}
}4.6 自定义Sink
与Source类似,Flink为我们提供了通用的SinkFunction接口和对应的RichSinkFunction抽象类。可以通过简单的调用DataStream的addSink()方法来自定义写入任何外部存储。比如hbase的连接。
在实现SinkFunction的时候需要重写关键方法invoke(),在这个方法中我们可以实现将流里的数据发送出去的逻辑。创建连接以及关闭连接分别放在open()和close()方法中。这里不做赘述。















 811
811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









