







作者 | 王启隆
出品 | AI 科技大本营(ID:rgznai100)
千元机也能在本地跑的大模型又来了!
北京时间 4 月 11 日,清华系 AI 公司面壁智能联合清华 NLP 实验室宣布日前完成新一轮数亿元融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投,光源资本担任独家财务顾问。发布会上还公布了四款“各显神通”的模型,它们分别是:
主打「多模态」、在「中文 OCR 能力」显著领先的 MiniCPM-V 2.0
号称「最小的 128K 长文本」,MiniCPM-2B-128K
引入 MoE 架构 “越级打怪” 的 MiniCPM-MoE-8x2B MoE
参数减半、性能却保持 87% 的 MiniCPM-1.2B

在很多人苦苦等待 GPT-5 的这段时间里,小模型、多模态和 Agent(智能体)逐渐受到研究者甚至广大开发者的关注。此前,面壁智能在 2 月发布的“小钢炮” MiniCPM 以 1T 的数据超越了法国初创公司训练 8T 数据的 Mistral-7B 模型,贯彻了“以小博大”四个字。面壁得到了来自开发者社区的热情反馈,发布后多次登顶 GitHub Trending,跻身 HuggingFace 50 万模型 TOP 3(持续一周),GitHub 星标 3.4K,全网下载量 37 万。
面壁出身开源,信仰开源,MiniCPM 的发布也回馈了开源社区。来自 MIT、普林斯顿等研究机构的研究者基于 MiniCPM 的训练思路开源了一款名为 JetMoE 的模型,通过仅花费 10 万美元的训练成本,却实现了与耗费数十亿美元训练的 LLaMA-2 模型相当甚至更优的效果。
此外,智源研究院团队推出了新一代检索排序模型——BGE Re-Ranker v2.0,其中基于 MiniCPM 优化的版本 BGE Re-Ranker v2-MiniCPM-2B 在中文检索评测基准中取得了最先进的 SOTA(state-of-the-art)性能表现,进一步验证了 MiniCPM 架构的有效性和优越性。

全世界的大模型都要学中国话
这一次全新升级的小钢炮,将炮口瞄准了「多模态」。
在图像到文本和文本到图像生成领域,大规模多模态学习这几年取得了显著进展,然而,这些所谓的成功主要局限于英语环境,其他语言则远远落后。由于非英语多模态数据资源稀缺(即缺乏大规模高质量的图文对数据),在其他语言中构建具有竞争力的对应模型是一项重大挑战。
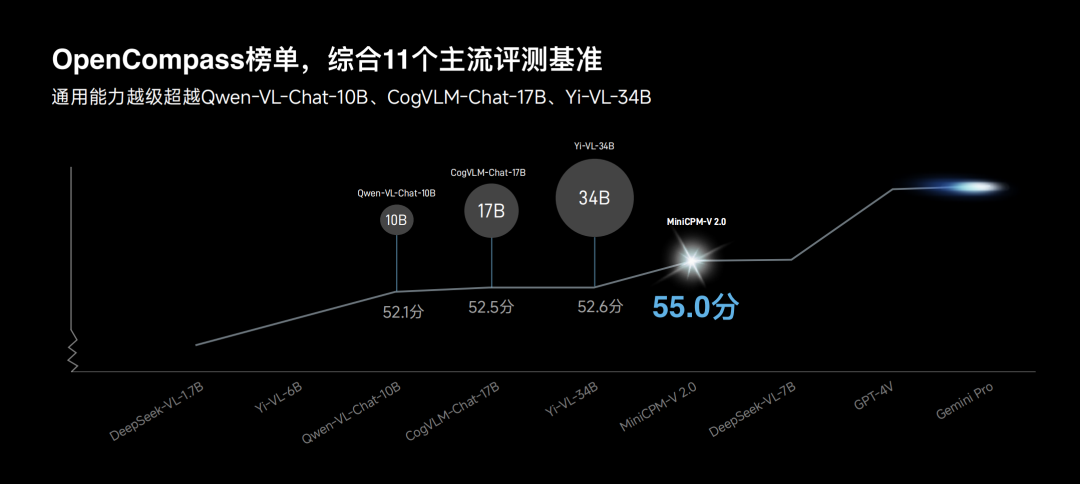
面壁端出的第一门炮便是 MiniCPM-V2.0 多模态大模型,尽管模型规模仅为 2.8B 左右,但在实际性能上表现出色,无论是在主流的评测基准上还是针对特定任务的表现,均超过了众多之前的大规模模型,如 Qwen-VL-Chat-10B、CogVLM-Chat-17B 和 Yi-VL-34B。
在避免模型产生幻觉的能力方面,其在 Object HalBench 榜单上评估的幻觉率仅为 14.5%,与 GPT-4V 的 13.6% 相差无几,这意味着 MiniCPM-V2.0 在降低幻觉性输出方面的表现已与 GPT-4V 持平,且在实例测试中,MiniCPM-V2.0 的幻觉错误数量少于 GPT-4V。
在多模态识别与推理能力的核心指标——OCR 光学字符识别方面,MiniCPM-V2.0 模型不仅能准确识别现代图像中的物体和文字,还特别适用于古文字识别,例如识别清华简中的古战国文字。通过针对性训练和强化,MiniCPM-V2.0 成功解决了诸如识别清华简中复杂古文字的挑战,并在相关领域中优于同类中文标杆多模态大模型。
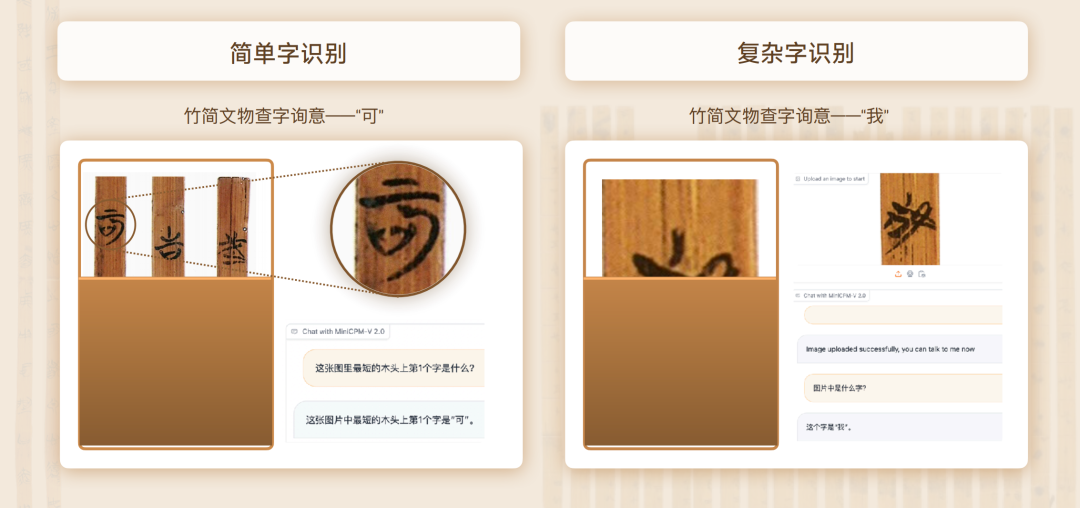
以后,考古学家就能靠大模型考古了。
量化评测方面,MiniCPM-V2.0 在 OCR 综合性榜单 CRBench 上刷新了开源模型的最佳表现,其在场景图片文字识别任务 TextVQA 上的表现甚至超越了全系 13B 量级模型,媲美业界顶级模型 Gemini Pro。
针对 OCR 识别的传统难题,MiniCPM-V2.0 通过采用独家技术 LLaVA-UHD,实现了对高清大图、任意尺寸和宽高比图像的无损识别。即使是对高度复杂、包含大量局部细节的场景图片,如街景图,也能精准捕获并识别出微小的文字信息,克服了传统模型在处理非标准化图片时的信息损失问题。

此外,MiniCPM-V2.0 在处理长图和不规则图像时,具备卓越的摘要能力和对图像全局及局部信息的理解力,使得长图中的文本信息得以高效提炼和理解。

CSDN 就 MiniCPM 独家的跨语言多模态泛化技术进行了询问,这项技术基于 面壁此前开源的中英双语多模态大模型——VisCPM。

开源地址:https://github.com/OpenBMB/VisCPM
论文地址:https://arxiv.org/abs/2308.12038
这篇论文提出了一种名为 MPM 的有效训练范式,用于训练非英语语言的大规模多模态模型。MPM 的全称是一句很长的话,即:多语言模型可以作为桥梁实现跨语言的零样本多模态学习(Multilingual language models can Pivot zero-shot Multimodal learning across languages)。
具体来说,基于一个强大的多语言大模型,仅使用英文图文数据预训练的多模态模型能够在近似零样本的方式下很好地推广到其他语言,并且性能甚至超越那些在母语图文数据上训练的模型。
作为 MBM 方法的实践,面壁基于中英双语大模型 CPM-Bee 研发了面向中文的大规模多模态模型 VisCPM。值得注意的是,尽管 VisCPM 仅在英文图文对上进行预训练,其在中文环境下的零样本性能仍然超越了那些在本土中文图文对上训练的现有中文多模态模型。遵循相同的训练流程,他们还进一步扩展了 MPM 技术,基于 LLaMA 开发了一款支持六种语言的多语种多模态对话模型,这六种语言包括英语、德语、法语、西班牙语、意大利语和葡萄牙语。
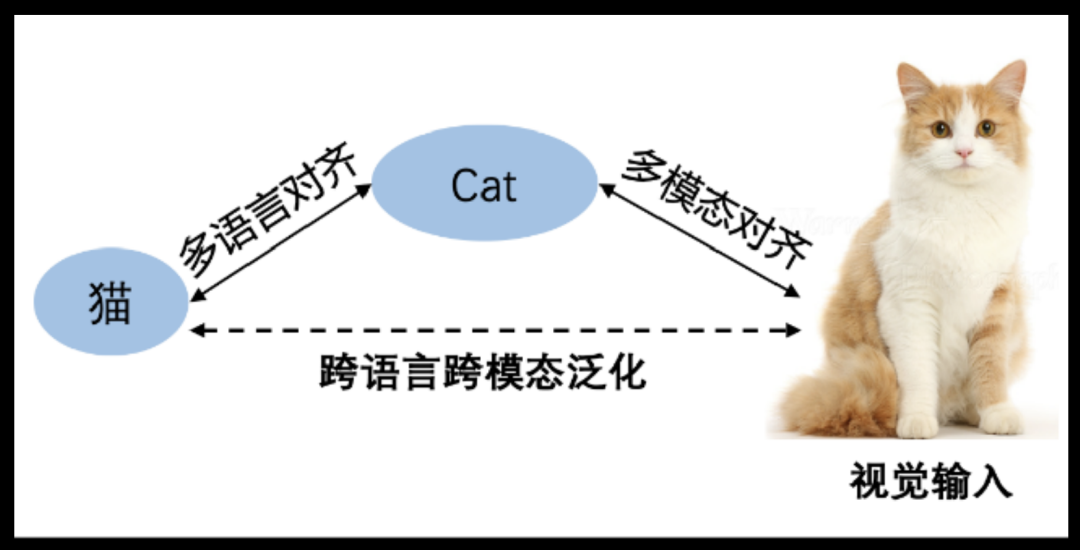
VisCPM:仅通过英文多模态数据预训练,泛化实现优秀中文多模态能力

参数越来越小,应用场景越来越多?
除了多模态小钢炮,面壁还展示了三个各具特色的模型:
MiniCPM-2B-128K
面壁给它的标签是「最小的 128K 长文本」。
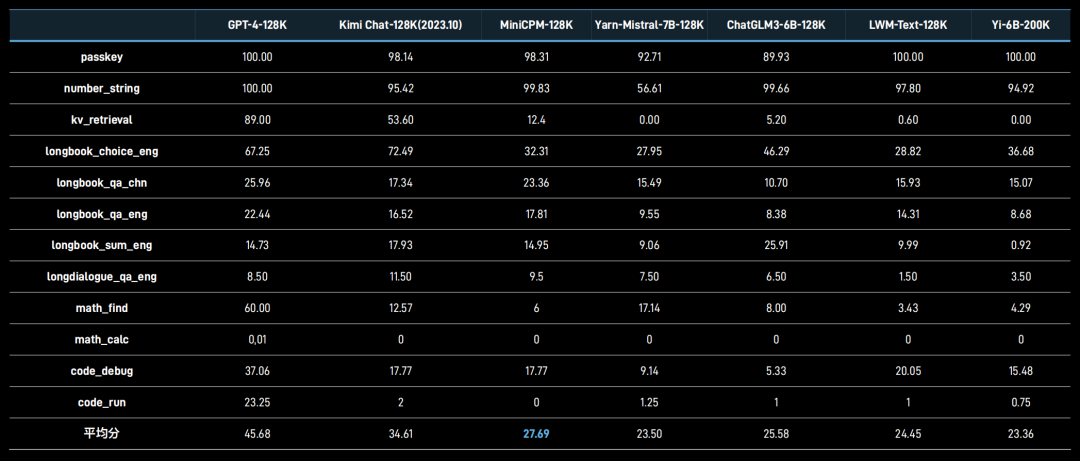
这是一款专注于处理长文本的轻量级模型,仅拥有 2B 参数量,在 7B 参数以下的模型中表现出色,尤其在 InfiniteBench 榜单上的平均成绩超越了 Yarn-Mistral-7B-128K、Yi-6B-200K、ChatGLM 3-6B-128K、LWM-Text-128K 等模型。
MiniCPM-MoE-8x2B MoE
MoE(mixture of experts),中文可以叫混合专家模型,因为他很像由多个专家组成的智囊团。想象一下,在模型里有个繁忙的决策中心,每个专家都专精于不同领域的知识和技能,比如有的擅长数学难题,有的精通文学创作,还有的是科学探索的高手……如果说大模型是在机器里塞了个人和我们对话,那 MoE 就是塞了一堆人。
MiniCPM-MoE-8x2B MoE 就引入了这样的 MoE 架构,提升了模型性能,相较于 MiniCPM 的基础版本平均性能提高了 4.5%。在保持较低平均激活参数量(4B)的同时,其性能优于更大参数量的 LLaMA 2-34B 和 Gemma-7B 等模型,并且推理成本仅为 Gemma-7B 的 69.7%,大幅降低了资源消耗。
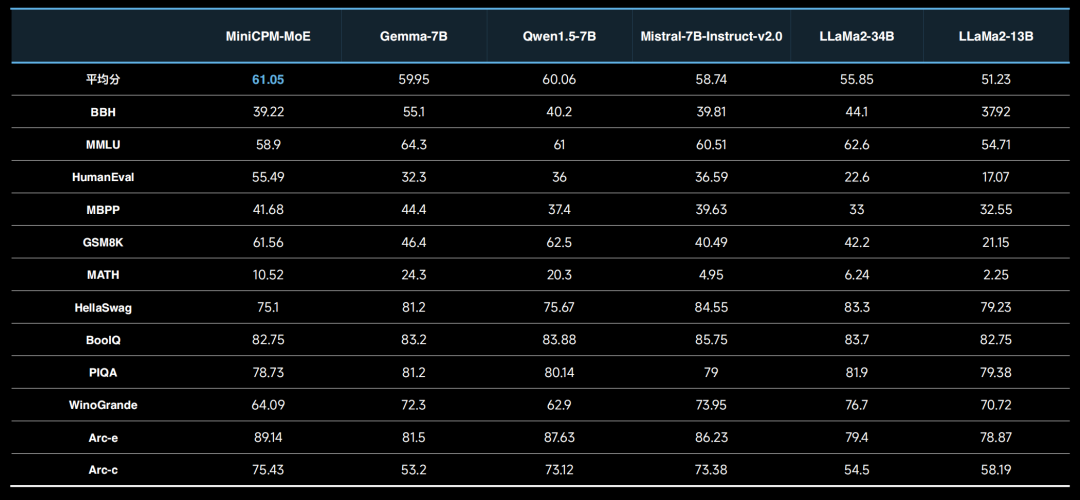
可惜的是,目前还没法把一堆人塞到手机里面。目前 MiniCPM 的 MoE 版本在端侧运行可能还需较大内存支持,但面壁的研发团队正在努力攻克这一技术难关,目标是使其能在移动设备上高效运行。
MiniCPM-1.2B
最后就是外号“小小钢炮”的 MiniCPM-1.2B。为了拓展更广泛的应用场景,面壁开发了这款更为精简的小型模型,其参数量减半,但依然保留了上一代 2.4B 模型 87% 的综合性能。
“小小钢炮”经过细致的优化措施,例如优化词表结构,剔除不常出现的词汇,有效减少了参数占用。在多个公开权威测试榜单上,它取得了超越 Qwen-1.8B、LLaMA 2-7B 甚至是 LLaMA 2-13B 的优秀成绩。
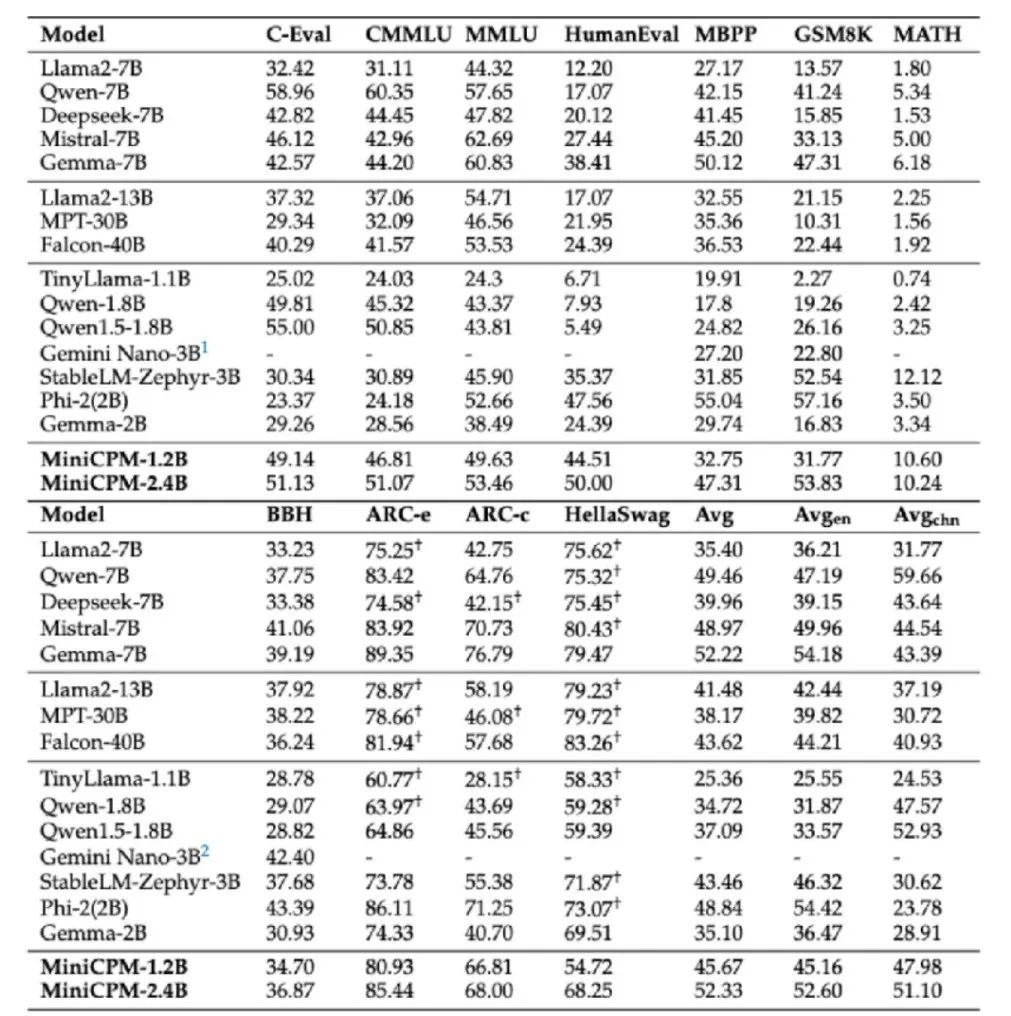
其高效的运行效率,特别是在移动端上能达到每秒处理 25 个 Tokens,远超人类正常说话速度的 15 ~ 25 倍,同时大幅度降低了内存占用和成本,例如在 iOS 平台上,MiniCPM-1.2B 量化模型大小为 1.01G,相比 MiniCPM-2.4B 减少了 51.9% 的内存需求,成本下降了 60%。
“高效”是面壁的信条。面壁智能 CEO 李大海强调了三种高效:高效训练、高效推理、高效落地 Agent 智能体。他们一直在不断探索并优化模型的 Scaling Law(大模型规模法则),力求在保证模型性能的同时,利用更少的数据量训练出更强大的模型,或实现同样性能的小型化模型,从而提高资源利用效率。
模型参数越来越小,“卷参数量”的阶段似乎已经结束了,我们来到了大模型之战的「下半场」。各大厂商纷纷开始寻找应用落地的场景,在理想和现实的平衡之间探索出一条通往 AGI 的道路。CSDN & 《新程序员》全新栏目「AGI 技术 50 人」为此而生,邀请到面壁智能 CTO 曾国洋进行对话,分享这位天才少年的成长历程、揭秘面壁的起源故事、解读 AGI 的终极使命。文章即将在下周发布,请继续关注 AI 科技大本营公众号。

4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「2024 全球机器学习技术大会」在上海再度启幕第一站,汇聚来自全球近 50 位在机器学习技术研发及行业应用领域的领军人物和知名专家,携手搭建一个专属于全球机器学习与人工智能精英的高层次交流与分享舞台。
届时,面壁智能 CTO 曾国洋将发表专题演讲——《面壁 AgentVerse 拥抱大模型群体智能涌现》,采访中没深入讨论的那些多模态技术研究内容,都将在大会上进行深度分享和探讨。欢迎点击「阅读原文」或扫描下方二维码,进一步了解详情。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









