







作者 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)
“是谁把我的马斯克换成了科比?”
“这个人转过身怎么变了一张脸?”
“刚才还挺帅的,怎么一眨眼就面目全非了……”

在 AIGC —— 尤其是 AI 视频生成领域,这样的吐槽已经成为一种日常。自从今年二月 OpenAI 的 Sora 横空出世,引发了一场 AI 视频生成的热潮。但无论是紧随其后的 Runway,还是 Pika Labs 和 Google 的 Lumiere,每一个视频生成模型都在苦苦挣扎于一个让创作者头疼的“换脸魔咒”。
这个被学术界称为「一致性」的难题,堪称 AI 视频生成的最大痛点。简单来说,就是如何让生成的主体在整个视频中保持外观、特征的一致性。听起来很基础,做起来却异常困难。即便是 Sora,在处理人物连续动作时依然会出现细微的特征漂移。
直到 11 月,国产清华系初创公司生数科技自主研发的 Vidu 大模型发布了 1.5 版本,展示了一个令全球 AI 从业者震惊的能力:只需要提供 1-3 张参考图片,就能实现对任意主体的精确控制。这意味着什么?意味着原本需要几十段视频、数小时训练才能达到的效果,现在只需要三张照片、30 秒就能实现。
黑人老马的问题彻底解决了,现在上台的是更辣眼睛的新娘马斯克……
言归正传,Vidu 不只是解决了某个具体场景下的一致性问题。它开创了一种全新的视频生成范式:多主体一致性生成。在这种范式下,我们第一次看到:视觉模型也能像大语言模型一样,具备理解上下文、进行记忆管理的能力。
为什么说这是一场革命?因为它颠覆了此前视频生成的基本假设。
在传统范式下,要让模型理解一个主体的特征,我们需要用大量数据去“教会”它。这就像教一个孩子认识新事物,需要反复展示多个例子。而 Vidu 1.5 展现的是一种全新的认知方式:通过少量但关键的参照物,直接理解并迁移特征。这更接近人类的学习方式 —— 我们看到一个人的正面照和侧面照,就能在脑海中构建出这个人的立体形象。
而在 Vidu,就不只是结合正面与侧面这么简单,它还能通过一个人的背影,联想到更大胆的事情:
其实,为了解决这个问题,业界曾尝试过多种方案。最早的尝试是“分步生成”策略,后来找到了一个“曲线救国”的方案:LoRA(Low-Rank Adaptation)。这种方法通过大量特定主体的素材让模型进行“微调”,本质上是用海量数据和计算力来弥补技术上的不足。
然而,这个被玩家戏称为“炼丹”的 LoRA 过程虽然繁琐,但确实是目前最可靠的解决方案。通过足够多的素材和训练,模型能逐渐“认识”这个角色的样貌特征。但这种方案存在着明显的缺陷:
1. 成本畸高:不仅需要大量优质素材,训练成本更是单次视频生成的数百倍;
2. 效率低下:从准备素材到完成训练,往往需要耗费数小时甚至数天;
3. 过拟合风险:为了记住新特征,模型常常会“忘记”原有的知识,导致生成能力受限;
4. 创作受限:每次只能处理事先训练过的特定主体,无法灵活应对新需求;
5. 表现局限:在涉及复杂动作或大幅度变换时,容易出现不自然的画面崩坏。
就在整个行业都在试图优化这条原以为的“必经之路”时,一个意想不到的声音从东方传来:如果模型足够聪明,或许根本不需要这么复杂?
欢迎回顾 Vidu 的上一次更新:全球首发!国产自研 Vidu 王炸新功能,让任意主体在视频生成中保持一致可控

三大能力,重构视频生成的可能性
单主体的多角度精确控制:一个“完整的人”
当我们说“生成一个人”时,其实在要求模型完成一个极其复杂的任务:它需要理解这个人在不同角度下的样貌、在不同表情下的细节变化、在不同动作中的姿态转换。传统模型往往只能记住某个特定视角下的特征,一旦需要转换视角或改变表情,就容易出现“换脸”现象。
现在来试试,上传科比的正面照片和背面照片:
 +
+  =
=
上面这个单主体控制的案例展现了 Vidu 1.5 对人物动作的精确把控。
在生成的视频里,从背对镜头到转身微笑,每一个细节都令人惊叹:面部轮廓和五官特征始终如一,表情的变化自然流畅,转身动作行云流水,就连发型和服装的细节都毫无违和感。在复杂角色的处理上,这种能力同样出色。比如在动画角色的案例中,即便面对复杂的 3D 建模风格,角色的形象依然保持完美统一。这种高度一致性在传统方案中往往需要大量特定角度的训练素材才能实现。
多元素的无缝融合:突破物理限制的想象力
如果说单主体控制是在解决“一个人”的问题,那么多元素融合则是在解决“一个世界”的问题。
 +
+  =
=
在这段合成案例中,Vidu 1.5 展现出对场景融合的精准控制。人物与建筑的比例恰到好处,光影和色调浑然一体,小李子莱昂纳多的姿态自然地融入场景,仿佛这张照片本就是在意大利实地拍摄的一样。
而上面这个案例感觉是最直观的:一个神秘的精灵男孩手捧生日蛋糕,站在流光溢彩的水晶空间里。镜头缓缓环绕,画面中的每个元素都完美融合:男孩的手自然地托着蛋糕,周围的水晶空间随着镜头推进闪烁着梦幻的光芒。这种复杂场景的无缝衔接,在传统 AI 创作中往往需要多次分层渲染和后期合成才能实现,而在 Vidu 1.5 里,其实只上传了三张图:小男孩、小蛋糕、水晶地。
多主体的深度融合:超越现实的创意空间
Vidu 1.5 最惊艳的能力或许在于它对创意的理解和执行。模型不是机械地进行特征拼接,而是理解了这个极具创意的需求。而在处理多个角色同框的场景时,这种能力同样出色。Vidu 不仅要维持每个角色的特征一致性,还要处理好他们之间的互动关系,包括视线交汇、身体朝向等细节。这种能力为创作者打开了一个全新的想象空间:

视觉模型的“上下文时代”来临
在理解 Vidu 1.5 的技术突破之前,我们需要先认识到一个重要现象:视觉模型正在经历与大语言模型类似的进化过程。
回想 ChatGPT 横空出世时带来的震撼。在此之前,人们普遍认为 AI 只能通过大量特定场景的训练才能完成特定任务。但 ChatGPT 证明,只要模型足够“聪明”,它就能通过理解上下文来完成从未训练过的任务。这种能力被称为“上下文学习”(In-context Learning)。
如今,Vidu 1.5 在视觉领域实现了类似的突破。它展示了视觉模型同样可以具备对上下文的深刻理解和记忆管理能力。这不再是简单的“看图说话”,而是能够理解多个输入图像间的关联,并基于这种理解生成连贯、合理的视频内容。
传统视频模型面临一个根本性的矛盾:要么牺牲通用性,为每个场景训练特定模型;要么接受效果的不确定性。这就像是在“准确”和“灵活”之间做取舍。
Vidu 从 1.5 开始正式走出了一条全新的路。它采用了与大语言模型一致的设计哲学,构建了一个“大一统”的架构:
首先,它将所有视频生成问题统一为视觉输入到视觉输出的映射。不管是人物动作、场景转换,还是多主体互动,本质上都是在处理视觉特征的转换。
其次,它用单个网络统一处理变长的输入和输出。这意味着它能同时处理不同数量、不同类型的参考图片,并生成连贯的视频序列。
就像大语言模型从文本压缩中学习一样。这使得它能够理解视觉元素间的深层关联,而不是简单的特征匹配。
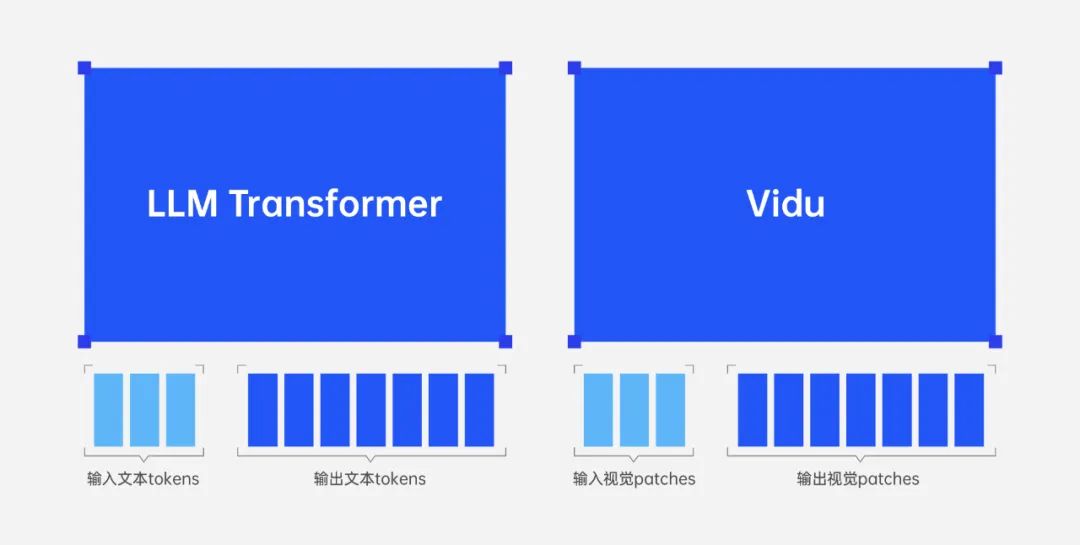
Vidu 1.5 的突破,标志着视觉模型正式进入“上下文时代”。这种转变的意义在于:模型不再需要针对每个特定场景进行专门训练,而是能够像人类一样,通过少量示例理解创作意图并完成任务。
所谓多主体一致性,不仅能保持单个主体在不同场景中的特征一致,还能准确处理多个主体之间的关系,甚至能将不同主体的特征进行创造性的融合。这种能力显示出视觉模型也开始具备了类似大语言模型的上下文理解能力。
更重要的是,这种技术路线为视频生成领域带来了新的可能:
1. 创作门槛的降低:从需要大量素材和训练时间,到仅需几张参考图片;
2. 创作自由度的提升:能够处理更复杂的多主体场景;
3. 生成效率的提升:从数小时的训练等待到 30 秒即可出片。
在更宏观的层面,这种突破预示着 AI 视觉理解正在向着更高层次迈进。就像大语言模型通过理解上下文实现了对自然语言的深度理解一样,视觉模型也正在获得对视觉世界的深层理解能力。这不仅是技术的进步,更是创作方式的革新。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









