







一提到“大模型”,很多人的第一反应往往是那个既能聊天,又会写代码、画画的“模型本身”。但其实,大模型远不止是一个“能输出结果的程序”这么简单,其背后有一整套复杂而庞大的技术体系作为支撑:从大规模、高质量、多样化的数据,到先进的模型架构与训练策略,再到推理部署、资源调度等支撑落地的系统能力,以及不可或缺的科学评测机制。大模型更像是一个由模型、数据、系统、评测平台等多要素构成的“技术共同体”,而非单一模块的堆叠。
如今在闭源技术壁垒与高昂商用门槛的对比下,开源大模型正迅速崛起,成为推动 AI 技术普惠化的重要力量。但面对层出不穷的开源 AI 模型技术,我们该如何选型?不同的模型技术体系又各有怎样的优势与短板?
在这一背景下,为系统呈现全球大模型生态的开源发展现状,CSDN 联合多家机构于 4 月 18 日在 2025 全球机器学习技术大会(ML-Summit 2025)现场重磅发布《AI 大模型技术体系综合开源影响力榜单》,全面评估全球范围内开源大模型技术体系的贡献与影响力,旨在为行业提供参考坐标,推动开源创新持续前行。
注:这里大模型是指主要包括 decoder-only 以来的模型结构,包括使用了大模型技术训练的小尺寸模型,不包括 Bert 类模型。

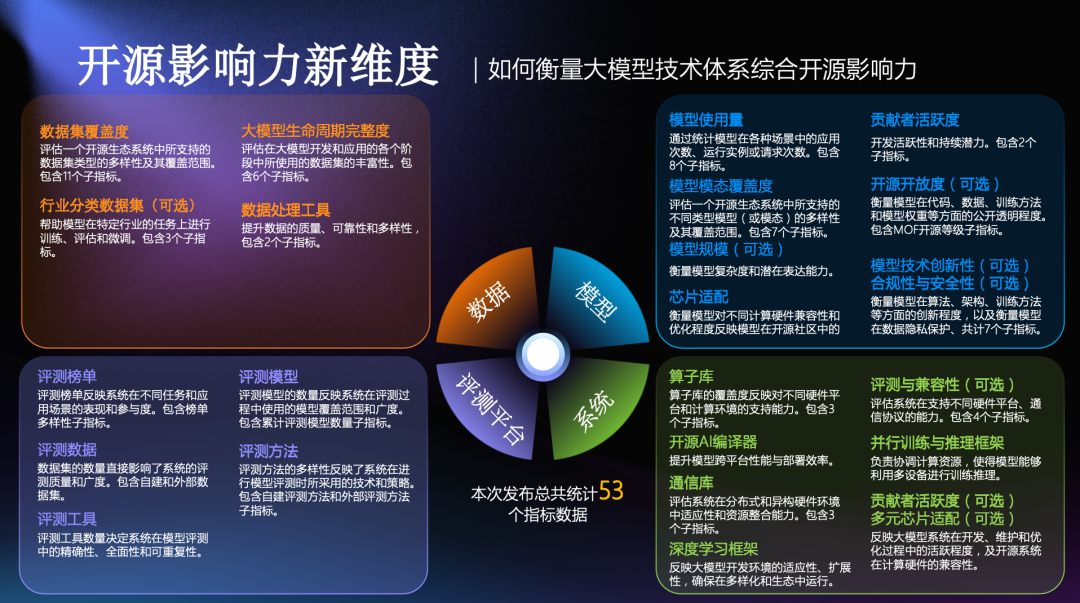
覆盖模型、数据、系统、评测四大维度的大模型技术体系
这份榜单的独特之处在于,它并不是只关注大模型本身,而是从“模型—数据—系统—评测平台”四个关键环节出发,对整个大模型技术体系的开源生态进行了全景式评估。之所以选择这四个维度作为核心,是因为它们共同构成了大模型发展的基本支撑:
第一,模型是整个体系的核心所在。开源大模型的种类越丰富,支持的模态越多,能覆盖的应用场景就越广,社区的技术创新也会随之加快。评估模型维度,可以衡量技术生态的创新能力和实际应用上的表现。
第二,数据是大模型的基础。模型表现好不好,很大程度上取决于数据的质量和多样性。而现在,高质量数据愈发稀缺,数据的开源不仅能降低模型训练门槛,也方便不同机构之间资源共享,让模型“吃得更好、长得更快”。所以,评估各家机构在开源数据及数据处理技术方面的覆盖广度、数量多少和实际应用情况,能够直观反映其在大模型生态中构建基础设施能力的成熟度。
第三,系统是整个体系的底层支撑。一个好的开源系统,不仅能适配不同的芯片平台,尤其是国产芯片,还能帮助模型更高效地训练与部署,提升整个生态的灵活性与可用性。
第四,评测平台则是检验模型效果的“试金石”。开源评测工具和排行榜越完善,就越能帮助研究者和开发者科学比较、快速迭代,提升模型的可靠性与实际应用价值。
这四个环节环环相扣,缺一不可。正因为如此,这次发布的榜单正是以“模型、数据、系统、评测平台”为骨架,设置了共 53 项核心评估指标,包括模型使用量、模型模态覆盖度、模型适配的芯片数量、贡献者活跃度、数据集的覆盖情况、数据处理工具、开源 AI 编译器、通信库、评测工具等,力求全面、客观地呈现出各大机构在大模型开源生态中的综合技术实力。
在数据采集方面,榜单共分析了来自 Hugging Face、ModelScope、GitHub、GitCode 等全球 17 个主流开源平台,分析了 11673 个链接中的多种指标数据,覆盖了全球范围内有代表性的模型机构、研究团队和平台所发布的公开资料,数据采集周期为 2025 年 1 月-4 月。为确保评估结果的科学性与可比性,榜单在模型、数据、系统、评测平台四个维度分别制定了明确的统计方法和筛选标准:
数据指标:同一项目的多个仓库 ,根据仓库README文件及关联论文划分每个数据仓库所属的模态、生命周期。
模型指标:统计各个机构下属所有子机构/组织的仓库,仅统计月下载量大于 50 的模型,仅统计 Transformer 之后的架构的大模型,排除 CNN/RNN 等传统深度学习模型,排除参数量小于 500M 的语言模型。
系统指标:支持异构训练、接入训练芯片厂商数量、大模型生命周期支持程度均通过从 GitHub、GitCode、PaddlePaddle、Mindspore 等网站获取。
评测平台指标:评测模型、评测数据数量从 2023 年后开始统计。仅统计公开可查的模型,为数据集发布而评测的模型不计其中。 仅统计保持更新的评测平台,随数据集发布而评测的榜单不计其中。评测模型以评测平台上的数据为准。(下载量相关数据均为统计当月下载量,其他数据为统计当月的截止值。)
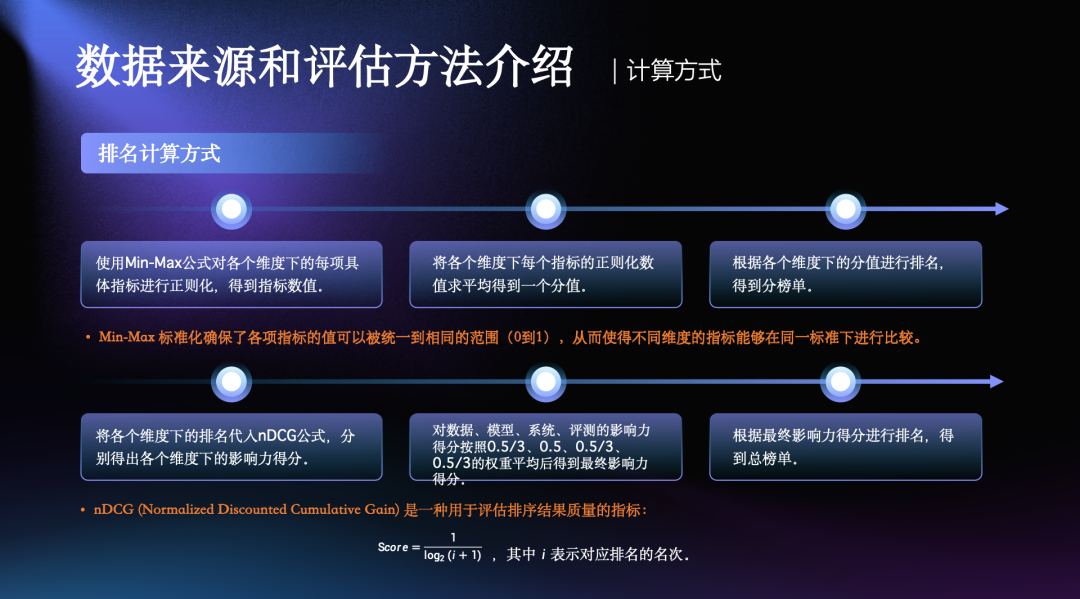

DeepSeek 荣登百亿级语言模型榜首,五大技术分榜单齐发!
基于上述四个核心维度的评估方法,我们对全球开源数据进行了系统化收集与标准化处理,最终形成百亿参数大语言模型、模型、数据、系统和评测平台五个分榜单。
百亿大模型下载榜出炉:DeepSeek 独占四席,强势跻身第一梯队
当前,业界对“百亿参数级”大模型(即参数规模在 32B 以上的模型)的关注日益升温。这类模型在性能与通用能力之间找到了相对理想的平衡点,既能支撑复杂任务,又具备可控的部署和训练成本,逐渐成为产业界和研究界争相投入的焦点。尤其是在开源社区,百亿模型正成为衡量机构技术力与实战落地能力的重要标尺。
在这一细分赛道上,国内机构正在加速追赶。在“百亿参数大语言模型下载量榜单”中,DeepSeek 表现格外亮眼,前十名中独占四席,显示出强劲的用户吸引力和产品号召力。其中,R1 模型以 954 万次下载量位居榜首,V3 模型紧随其后。这不仅体现了模型本身的实用性和稳定性,也从侧面反映了 DeepSeek 生态影响力正在迅速攀升。
模型分榜单:Meta、阿里巴巴稳居前列,DeepSeek 强势突围
在“模型分榜单”中,评估参考了多个维度,包括模型的下载量、开源数量、是否覆盖多种模态(如语言、视觉、语音、多模态、3D、蛋白质、向量),以及社区活跃度(点赞数、讨论数量、Issue 数),综合衡量各机构在模型层面的开源影响力。
从多项指标得出的模型维度榜单来看,2025 年 1 月至 4 月期间,大模型的竞争格局呈现“强者稳固,后秀崛起”态势:Meta 连续四个月蝉联榜首,阿里巴巴则稳居第二,整体格局相对稳固,展现其强大生态力。而 DeepSeek 则是今年的最大黑马,凭借 V3、R1 等新模型的持续发布迅速上升,在模型维度榜单中排到第 4,成为最具成长性的国内机构之一。

数据分榜单:Ai2 靠 C4 出圈登顶、Google 凭语音数据集加持不甘示弱
毋庸置疑,在大模型世界里,数据就是“食粮”。这份数据分榜单评估主要考察数据集的模态覆盖度(语言、视觉、语音、具身等)、大模型生命周期支持情况以及配套数据工具的完整性。
从榜单来看,或许不少人对排名第一的 Ai2(Allen Institute for AI)这个名字还不太熟悉,但如果提到 C4 数据集,很多从事大模型训练的从业者一定不会陌生。C4 是多个主流语言模型的训练基础,而发布它的正是 Ai2。这家由微软联合创始人保罗·艾伦在 2014 年创办的研究机构,长期专注于“普惠”和“透明”的人工智能基础研究。
在这次数据维度的开源影响力榜单中,Ai2 凭借 C4 数据集的广泛使用和影响力,成功登顶。它的上榜虽然让一些人感到意外,但从它在数据资源方面的积累来看,也可以说是实至名归。

除了 Ai2,Google 在语音数据集方面表现出色,贡献了不少关键性资源;而 Hugging Face 也凭借 FineWeb 等高质量数据集保持了持续的开源活跃度。
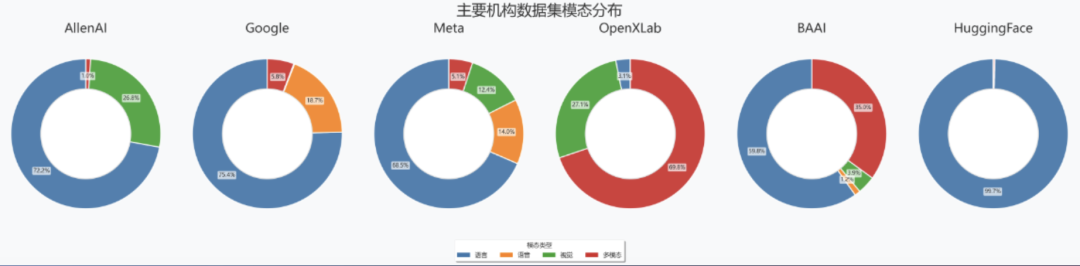
在国内机构中,BAAI 在语言和多模态数据集方向均有系统布局,如 CCI 系列语言数据集和 Infinity 多模态数据集表现抢眼。Shanghai AI Lab 则在视觉与多模态领域构建了优势地位。
整体而言,当前,语言类数据依然是主流,但多模态数据正在加速追赶,尤其是带有“具身感知”特性的交互式数据集开始受到关注。这种变化也从下载量上得到了验证。它说明大家对 AI 的期待正在从“读懂文本”转向“理解世界”,从语言走向实体交互应用。
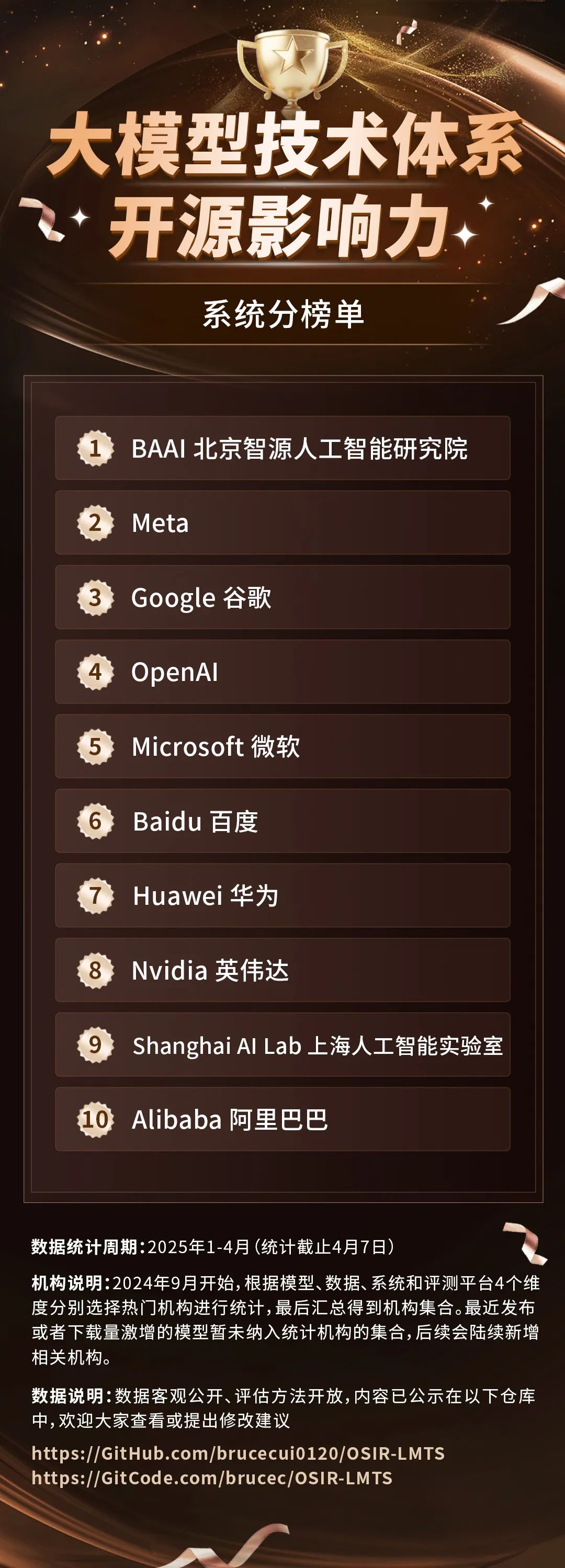
系统分榜单:智源研究院突出,百度、华为跻身十强,打造最强大模型底座
系统维度聚焦的是 AI 模型背后的“底层支撑能力”,主要看哪些机构在开源核心技术工具方面下了功夫。这一维度的评估主要从并行训练和推理框架、算子库、通信库、AI 编译器以及深度学习框架五个方面展开。可以理解为这是构建和运行大模型的“工具箱”。
根据榜单结果显示,目前还没有哪家机构能在这五个指标上做到全覆盖,但已有六家机构表现突出,覆盖了其中的四项,它们分别是:智源研究院、百度、华为、Google、OpenAI 和微软。
其中,智源研究院在通信库和 AI 编译器这两个更偏向底层优化的模块上表现出色,逐渐走出一条差异化的技术路线。而 Meta 和 Google 在“多芯片支持”的算子库和并行训练框架方面领先优势明显,擅长处理大规模算力调度。
这类“系统底座”能力虽然不容易直接被用户感知,但却是大模型性能、效率和可扩展性的关键。谁能在这些方面做好,谁就能为更强大的模型打下更稳的地基。
评测平台分榜单:上海人工智能实验室、Hugging Face、智源研究院领跑大模型技术体系评测
在大模型评测领域,关键的评测维度包括评测工具、数据集的数量、支持的模态等因素。总体来看,虽然评测工具和方法在短期内已逐渐稳定,但对于评测覆盖的模态和数据规模的扩展却持续加速。
在这个维度中,Shanghai AI Lab 凭借其丰富的数据集和评测工具,位居前列。HuggingFace 则通过其平台生态的强大优势,在参与评测的模型数量上遥遥领先,目前已提交了 4576 个模型进行评测。与此同时,BAAI 也不甘落后,依托其 FlagEval 平台,在评测榜单上的模型数量紧随 Hugging Face,显示出较强的评测覆盖能力。
随着评测平台不断增加数据集和支持的模态,未来的评测将更全面,能够覆盖更多类型的模型和应用场景。这不仅帮助行业标准化,也让模型开发者和研究者能更清楚地评估自己模型的性能,推动整个领域的持续发展。


综合开源影响力榜单:四家中国机构跻身 Top 10,加速全球开源创新
最终,我们基于模型、数据、系统、评测平台四大技术维度进行加权评分,其中模型维度占比 50%,其余三项均分剩余权重。根据此评估结果,我们正式发布——《大模型技术体系综合开源影响力榜单》。

亮点解析
榜单显示,Meta 凭借其在模型和系统两大核心维度的深厚积累,位居总榜首位。要知道,Meta 在模型方面的领先地位几乎无可撼动,其主导发布的 LLaMA 系列模型,从 LLaMA 1 到最新的 LLaMA 4,已成为全球开源语言模型的核心基座,并衍生出诸如 Alpaca、Vicuna 等多个流行模型,极大丰富了开源生态。此外,Meta 还是 PyTorch 框架的主要推动者,深度参与了分布式训练工具 FairScale、FSDP 以及模型部署工具 TorchServe 的建设,构建了全球最为成熟的 AI 系统工具链。在数据方面,Meta 也在多模态与视频数据领域有所突破,开源了 HOT3D、Ego-Exo4D、OMat24 等具有代表性的数据集,推动 AI 向更高维度感知发展。
紧随其后的 Google 凭借轻量化大模型理念与完善的工具链生态,在本次评估中表现亮眼,排在第二位。其最新发布的开源语言模型 Gemma 3 展现出良好的性能与开放性,受到开发者社区广泛关注。同时,TensorFlow 与 JAX 等核心系统工具,长期在业界保持领先地位,也为其在系统层面的综合影响力加分不少。
在国内机构中,北京智源人工智能研究院(BAAI)在数据、模型、评测平台等多个维度均有不俗表现,在系统层面的突出优势尤其引人注目。这主要得益于其在底层 AI 框架、训练平台、推理加速等关键技术上的持续投入与开源落地。其打造的 FlagOpen(飞智)开源体系,不仅覆盖了大模型训练和部署所需的核心组件,还致力于构建一个支撑大模型技术演进的完整软件栈,目标是成为大模型时代的一站式“开源底座”,类似于大模型领域的“Linux”。
阿里巴巴在综合开源影响力总榜中排名第四。其主力模型通义千问(Qwen)系列在 Hugging Face 和 OpenCompass 等评测平台上均表现优异,并持续迭代更新。除模型外,阿里还在训练平台、部署框架、评测工具等多个系统维度构建了较为完善的开源体系。
凭借在数据维度上的显著优势,Ai2 在综合影响力榜单中排名第六。尽管它不像 OpenAI 或 Google 那样频繁推出大语言模型,但在数据开源领域,Ai2 的影响力不可小觑——它是全球最活跃的数据集开源贡献者之一。其发布的 C4 数据集被广泛用于主流语言模型的训练,成为重要的资源之一。此外,Ai2 还推出了训练数据集 OLMo-mix-124(https://huggingface.co/datasets/allenai/olmo-mix-1124),进一步巩固了其在自然语言处理领域的研究基础。
另一家备受关注的中国机构是 DeepSeek,近来在大模型开源社区中持续活跃。其陆续发布的 DeepSeek Coder、DeepSeek-V3 和 R1 等系列模型,不仅在性能上表现亮眼,而且实现了完整开源,在 Hugging Face 等平台上广受关注。特别是在 MoE(专家混合)架构上的探索,展现了其在模型创新方面的深度实力。凭借模型质量、系统架构和社区响应等多方面的快速提升,DeepSeek 本次成功跻身全球第九名,成为国内新兴 AI 力量中的现象级代表。
OpenAI 排名第十,本质上属于“有限开源”的代表,但其影响力仍不容小觑。虽然 OpenAI 核心模型如 GPT-4 和 GPT-3 并未开源,影响了其在模型维度的得分,但其早期开放的 GPT-2、Whisper 等项目,至今仍被广泛应用于学术和工业界。

开源共建 AI 技术体系全生态
以上便是本次榜单的核心内容。最后,为了进一步推动评估体系向行业标准化迈进,CSDN联合多家机构起草《人工智能大模型技术体系开源影响力评估方法》白皮书,并计划于 5月中旬,在 2025 年国家人工智能标准化总体组工作会议暨全国信标委“标准周”活动正式对外发表,敬请关注。
同时,随着多模态技术的广泛应用,模型能力边界不断扩展,数据来源日益多样,评测标准也日趋精细,当前的评估权重设置可能难以全面反映最新技术演进。为此,我们也将持续对评估框架进行动态优化,引入更科学的权重调整机制,更好适配多模态大模型与具身智能的发展趋势,确保榜单体系具备公平性、合理性与前瞻性。
在此,本次评选所依据的“大模型技术体系开源影响力评估框架”已在 GitHub、GitCode 上开源:
GitHub地址: https://github.com/brucecui0120/OSIR-LMTS
GitCode地址:https://gitcode.com/brucec/OSIR-LMTS
我们鼓励广大参与者共同完善评估方法、推荐数据平台或资源渠道,提升数据完整度与准确性,推动构建可信、可用的中国开源大模型生态基础。
扫描下方二维码,即可参与



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









