







命令
从机执行 slaveof [master.ip] [master.port]开始主从同步,用配置文件也可以
过程简述
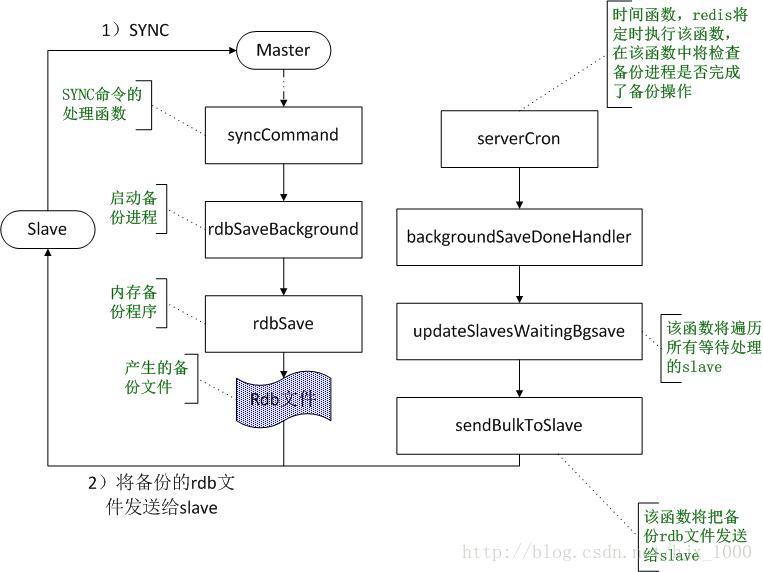
1、slave >>> 发送PSYNC命令 >>> master
2、master 调用 bgsave命令 fork 一个后台子进程生产 rdb 文,并在缓冲区中记录从现在开始执行的写命令。
3、master 发送 rdb 文件到 slave,slave 丢弃自己所有的数据并阻塞自己,专心做 rdb 读取,数据恢复。
4、在这个过程中,master接收了client的写命令会记录在复制缓冲区,发送给slave进行同步
5、之后master再接收写命令,先记录缓冲区,再发送给slave
第2步的细节过程如下
复制缓冲区
默认大小为1M,由master维护的一个固定长度的FIFO队列,它的作用是缓存已经传播出去的命令。
当master进行命令传播时,不仅将命令发送给所有slave,还会将命令写入到复制积压缓冲区里面。
全量复制的时候,master的数据更新(读写操作,主动过期删除等)会临时存放在backlog中待全量复制完成后增量发到slave
复制偏移量(offset)
对应复制缓冲区中的字符偏移,笔者认为,就简单理解为Kafka里的offset也可以
slave断线重连
主从节点之间已经初步实现了数据同步,
往后的 master,会将收到的每一条写命令发送给 slave 并 添加到复制缓冲区并根据字节数计算更新自己的偏移量,slave 收到传输过来的命令后也一样更新自己的偏移量。
这样,只要主从节点的偏移量相同就说明主从节点之间的数据是同步的。
复制缓冲区大小是固定的,新的写命令进来以后,旧的数据就会出队列。
如果某个 slave 断线重连之后,依然向 master 发送 PSYNC 命令并携带自己的偏移量,
master 判断该偏移量是否还在缓冲区区间内,如果在则直接将该偏移量往后的所有偏移量对应的命令发送给 slave,无需重新进行全量复制。
数据丢失情况
1、主从复制是异步的,丢数据的可能必然存在。
2、脑裂引发的问题
(脑裂描述:某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着。
此时哨兵可能就会认为master宕机了,然后开启选举将其他slave切换成了master。集群里就会有两个master,也就是所谓的脑裂。)
此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了。
因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据
透过现象看本质
1、复制是异步的,主从天然不对等,主机被物理破坏了,不存在什么主从切换,你现在只能启动从机临时顶一顶,数据丢失是必然的。
2、主从切换的机制问题:【一个slave挂到新的master上去,自己的数据会清空,重新从新master复制数据】
3、脑裂问题比上述1、2更严重的是,不光把存量数据丢了,还把client新发来的数据也弄丢了。
及时止损
数据丢失的问题是解决不了的。只能通过配置的方式尽量让数据丢失的少一些
// 表示 master 至少有 1 个副本连接,默认0
min-slaves-to-write 1
// 数据复制和同步的延迟不能超过 10 秒,默认10
min-slaves-max-lag 10
上述配置要求:至少有1个slave,数据复制和同步的延迟不能超过10秒。
如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了。














 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









