










持续分享有用、有价值、精选的优质大数据面试题
致力于打造全网最全的大数据面试专题题库

111、Hadoop中libjars参数的作用及使用?
参考答案:
(1)作用:指定MR第三方jar包
(2)使用:hadoop jar wordcount.jar com.dajiangtai.WordCount -libjars $LIBJARS input output 注:libjars这个参数一定要放到类名的后面,参数的前面。这样就可以方便使用第三方jar包了。
112、Hadoop的性能调优从哪些方面着手?
参考答案:
一、硬件方面(网络,多磁盘,多机架)---系统集成人员来做 ,机架分开,节点均匀放置。
二、操作系统参数调优
a)多个网卡:多网卡绑定,做负载均衡或者主备
b)磁盘:多个磁盘挂载到不同目录下,存放数据做计算的磁盘不要做raid
c)增大同时打开的文件数目的上线
d)关闭swap 分区,避免内存与磁盘交换数据(内存不足)
e)设置合理的预读取缓冲区大小(磁盘I/O是瓶颈,CPU 和 内存配置一般较高)
f)文件系统的选择与配置 :Linux有很多文件系统,比如ext3和ext4,不同文件系统性能有差异。ext4性能可靠性更好
g)I/O调度器选择:CFQ (Completely Fair Scheduler(完全公平调度器))(cfq)、Noop 调度器(noop)、截止时间调度器(deadline)
三、jvm层面
a)http://www.cnblogs.com/edwardlauxh/archive/2010/04/25/1918603.html
b)使用最新稳定版jdk
c)gc算法 选择
d) 如何监控jvm
jstat -gcutil 12122 1000
jvisualvm+jstatd
四、hadoop层面性能调优
1、守护进行内存调优
a)NameNode和DataNode内存调整在hadoop-env.sh文件中 NameNode:
export HADOOP_NAMENODE_OPTS="-Xmx512m -Xms512m -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" DataNode: export HADOOP_DATANODE_OPTS="-Xmx256m -Xms256m -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" -Xmx -Xms这两个参数一般保持一致,以避免每次垃圾回收完成后JVM重新分配内存。
b)REsourceManager和NodeManager内存调整在yarn-env.sh文件中 REsourceManager: export YARN_RESOURCEMANAGER_HEAPSIZE=1000 默认 export YARN_RESOURCEMANAGER_OPTS="..........."可以覆盖上面的值 NodeManager: export YARN_NODEMANAGER_HEAPSIZE=1000 默认 export YARN_NODEMANAGER_OPTS="";可以覆盖上面的值 常驻内存经验配置: namenode:16G datanode:2-4G ResourceManager:4G NodeManager:2G Zookeeper:4G Hive Server:2G
2、mr中间目录要配置多个,分散IO压力 http://hadoop.apache.org/docs/r2.6.0/ 查看yarn-default.xml 分散IO压力 yarn.nodemanager.local-dirs yarn.nodemanager.log-dirs
配置文件mapred-default.xml: mapreduce.cluster.local.dir
配置文件hdfs-default.xml:提高可靠性 dfs.namenode.name.dir dfs.namenode.edits.dir dfs.datanode.data.dir
3、mr中间结果要压缩
a)配置mapred-site.xml文件中配置 mapreduce.map.output.compress true mapreduce.map.output.compress.codec org.apache.hadoop.io.compress.SnappyCodec 程序运行时指定参数 hadoop jar /home/hadoop/tv/tv.jar MediaIndex -Dmapreduce.compress.map.output=true -Dmapreduce.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec /tvdata /media
b)使用合理的压缩算法(cpu和磁盘) cpu:如果是cpu的瓶颈,可以更换速度快的压缩算法 磁盘:如果是磁盘的瓶颈,可以更换压缩力度大的压缩算法 一般情况我们使用snappy 压缩,比较均衡
4、hdfs文件系统中避免,大量小文件存在 。
5、根据具体情况,在Map节点使用Combiner,减少输出结果。
6、重用Writable类型,比如 声明一个对象Text word = new Text(); map(),reduce()方法里面重用。
7、根据集群节点具体情况,调整task的并行度 设置map和reduce最大任务个数: mapreduce.tasktracker.map.tasks.maximum mapreduce.tasktracker.reduce.tasks.maximum 设置map和reduce 单个任务内存大小: mapreduce.map.memory.mb 1G 默认 mapreduce.reduce.memory.mb 1G 默认。
113、Hadoop中通过拆分任务到多个节点运行来实现并行计算,但某些节点运行较慢会拖慢整个任务的运行,Hadoop采用什么机制应对这个情况?
参考答案:
Speculative Execution 推测执行
(1)推测执行(Speculative Execution)是指在分布式集群环境下,因为程序BUG,负载不均衡或者资源分布不均等原因,造成同一个job的多个task运行速度不一致,有的task运行速度明显慢于其他task(比如:一个job的某个task进度只有10%,而其他所有task已经运行完毕),则这些task拖慢了作业的整体执行进度,为了避免这种情况发生,Hadoop会为该task启动备份任务,让该speculative task与原始task同时处理一份数据,哪个先运行完,则将谁的结果作为最终结果。
(2)推测执行优化机制采用了典型的以空间换时间的优化策略,它同时启动多个相同task(备份任务)处理相同的数据块,哪个完成的早,则采用哪个task的结果,这样可防止拖后腿Task任务出现,进而提高作业计算速度,但是,这样却会占用更多的资源,在集群资源紧缺的情况下,设计合理的推测执行机制可在多用少量资源情况下,减少大作业的计算时间。
114、MapReduce二次排序原理?
参考答案:
1、简述
默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用到二次排序了。
2、详细过程
1)Map起始阶段
在Map阶段,使用job.setInputFormatClass()定义的InputFormat,将输入的数据集分割成小数据块split,同时InputFormat提供一个RecordReader的实现。在这里我们使用的是TextInputFormat,它提供的RecordReader会将文本的行号作为Key,这一行的文本作为Value。这就是自定 Mapper的输入是 的原因。然后调用自定义Mapper的map方法,将一个个键值对输入给Mapper的map方法。
2)Map最后阶段
在Map阶段的最后,会先调用job.setPartitionerClass()对这个Mapper的输出结果进行分区,每个分区映射到一个Reducer。每个分区内又调用job.setSortComparatorClass()设置的Key比较函数类排序。可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass()设置 Key比较函数类,则使用Key实现的compareTo()方法。
3)Reduce阶段
在Reduce阶段,reduce()方法接受所有映射到这个Reduce的map输出后,也会调用job.setSortComparatorClass()方法设置的Key比较函数类,对所有数据进行排序。然后开始构造一个Key对应的Value迭代器。这时就要用到分组,使用 job.setGroupingComparatorClass()方法设置分组函数类。只要这个比较器比较的两个Key相同,它们就属于同一组,它们的 Value放在一个Value迭代器,而这个迭代器的Key使用属于同一个组的所有Key的第一个Key。最后就是进入Reducer的 reduce()方法,reduce()方法的输入是所有的Key和它的Value迭代器,同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
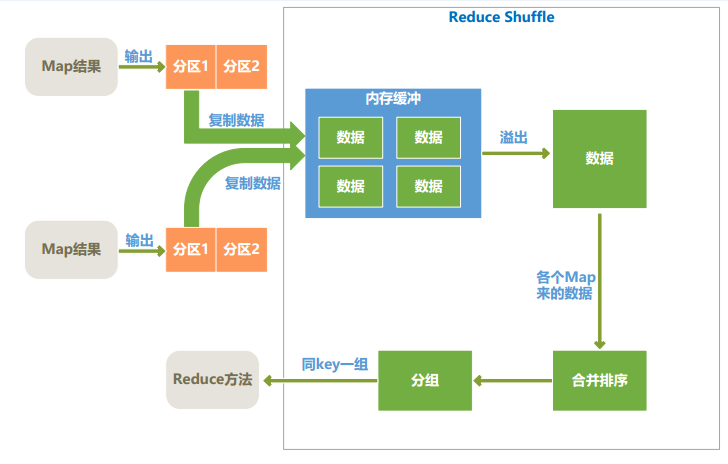
115、分析MapReduce数据处理及shuffle的流程,以及各个阶段的先后顺序。
参考答案:
1)MapReduce数据处理流程

2)Map端shuffle过程

3)Reduce端的shuffle过程
















 3273
3273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











