




 本文深入解析了PriorityQueue的数据结构和核心方法,包括offer和poll等关键操作的实现原理,以及内部的小顶堆结构如何维护和调整。
本文深入解析了PriorityQueue的数据结构和核心方法,包括offer和poll等关键操作的实现原理,以及内部的小顶堆结构如何维护和调整。
PriorityQueue分析
入门小demo
@Test
public void testPriorityQueue(){
PriorityQueue<String> queue = new PriorityQueue<>();
queue.offer("b");
queue.offer("b");
queue.offer("b");
queue.offer("b");
queue.offer("b");
queue.offer("a");
queue.offer("a");
int size = queue.size();
for (int i = 0; i < size; i++) {
System.out.println(queue.poll());
}
}
结果
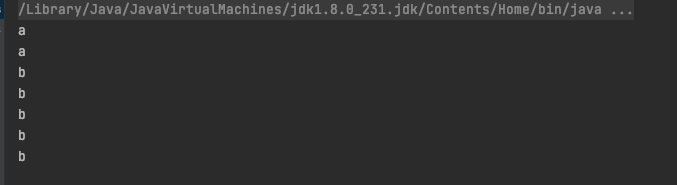
PriorityQueue 是一个优先级的队列,支持元素利用Comparable接口来排序。并且不支持存放null。
它基于数组实现了一个小头堆(小头堆意思就是根节点比子节点小,相反,大头堆就是根节点比子节点大。体现在Java里面就是Comparable接口的返回值)每次出队的时候都是队头,并且一直维护小头堆。入队都是在队尾,也一直维护小头堆。
并且基于数组的实现的堆,是一个完全二叉树,因为数组下标总是连续的,存放的时候都是连续的。
简单的介绍就是这样,下面看具体的代码分析。
1. 属性分析
private static final long serialVersionUID = -7720805057305804111L;
// 默认的容量,
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 利用数组实现堆,并且是小头堆,对于一个节点来说,如果更节点为数组 下标为n的元素,他两个子节点元素的下标的位置为[2*n+1](左子树)和 [2*(n+1)](右子树),如果指定了comparator,就用comparator,如果没有就用自然顺序,
transient Object[] queue;
// 元素的数量
private int size = 0;
// 指定的comparator
private final Comparator<? super E> comparator;
// 快速失败机制,之前在ArrayList里面说过,这里就不在继续说了
transient int modCount = 0;
2. 构造方法分析
从构造方法可以看出,可以指定容量和comparator。并且在构造方法的时候就直接创建出数组了,不像ArrayList一样,一开始的时候不创建。并且还支持传入一个Collection对象,并且赋值操作,
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
如果参数类型是SortedSet,先赋值comparator,然后将SortedSet,变为数组,赋值给PriorityQueue的queue。同样的,对于PriorityQueue来说,也是这样的操作,对于其他的Collection,先是变为数组后,有一个构建堆的操作。
public PriorityQueue(Collection<? extends E> c) {
if (c instanceof SortedSet<?>) {
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
initElementsFromCollection(ss);
}
else if (c instanceof PriorityQueue<?>) {
PriorityQueue<? extends E> pq = (PriorityQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
initFromPriorityQueue(pq);
}
else {
this.comparator = null;
// 这个方法里面有构建堆的操作
initFromCollection(c);
}
3. 主要的方法分析
offer
public boolean offer(E e) {
// 非空检查
if (e == null)
throw new NullPointerException();
// 快速失败
modCount++;
// 这扩容居然是在一次操作之前,不像HashMap一样,在操作之后扩容。
int i = size;
if (i >= queue.length)
// 扩容操作,具体会在下面扩容分析里面讲解
grow(i + 1);
// size++;
size = i + 1;
// 一开始肯定为0,队头元素存放值
if (i == 0)
queue[0] = e;
else
// 构建堆。
// i表示要插入的位置,i是上一次队列的长度,也就是这一次要插入的位置的下标。
siftUp(i, e);
return true;
}
siftUp 分析(新增元素的时候构建堆)
如果指定了comparator,就按照指定的comparator来比较。否则就按照默认的,其实这俩方法差不了多少,不过就是比较的部分,一个用的是自己的,一个用的是指定的comparator的。所以,这里值分析一个siftUpComparable方法
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
siftUpComparable分析
k表示要插入的位置,x表示要插入位置的值。
private void siftUpComparable(int k, E x) {
// 上来先强转,如果说元素没有实现Comparable接口或者它是null,这里肯定会报异常。
Comparable<? super E> key = (Comparable<? super E>) x;
// 不能在根节点位置上插入。
while (k > 0) {
// 找到要插入位置的父节点。
int parent = (k - 1) >>> 1;
// 拿到值
Object e = queue[parent];
// 如果说父节点比要插入的key小,那么直接在要插入的位置上插入就可以。否则就说明,要插入的值,比父节点还要小,那就要继续往上找了,一直找到一个符合的节点。
if (key.compareTo((E) e) >= 0)
break;
// 走到这里,就说明不符合,只能继往上找了,继续往上找,肯定能找到一个位置,所以,就得把父节点往下移动移动,
// 将父节点下移动
queue[k] = e;
// 下一次的操作就从父节点开始,继续找,
k = parent;
}
// 赋值操作
queue[k] = key;
}
这里的操作看代码不好理解,这里画一个图便于理解,图中的例子和开头的代码例子对应。
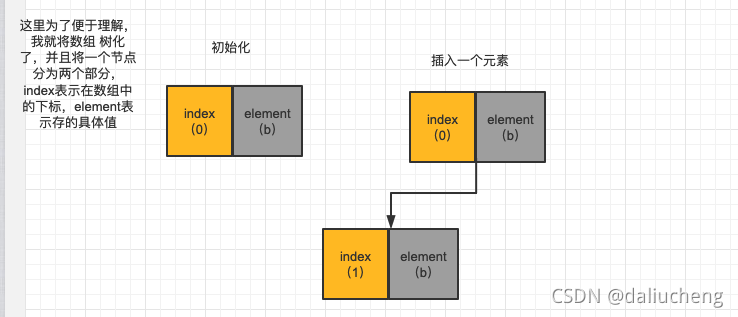
也可以根据这个图来验证一下下标为n的元素,他两个子节点元素的下标的位置为[2*n+1](左子树)和 [2*(n+1)](右子树)这个是否正确。
第一次插入之后,根据上面的逻辑找到要插入节点(下标为1的位置)的父节点,判断父节点是否比要插入的key小,发现不满足,就直接在要插入节点(下标为1的位置)直接插入值就好了。
下面的几个都是这样的逻辑,一直到a插入的时候,发生了变化
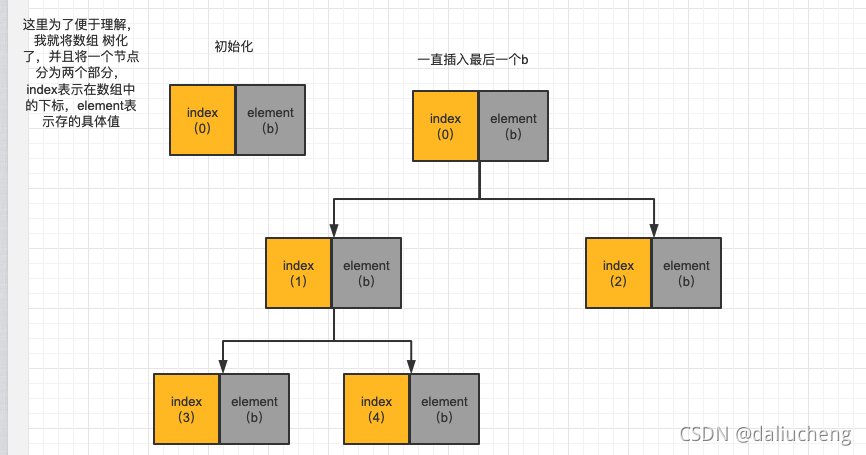
开始插入a之后。
- 找到父节点开始判断和比较。
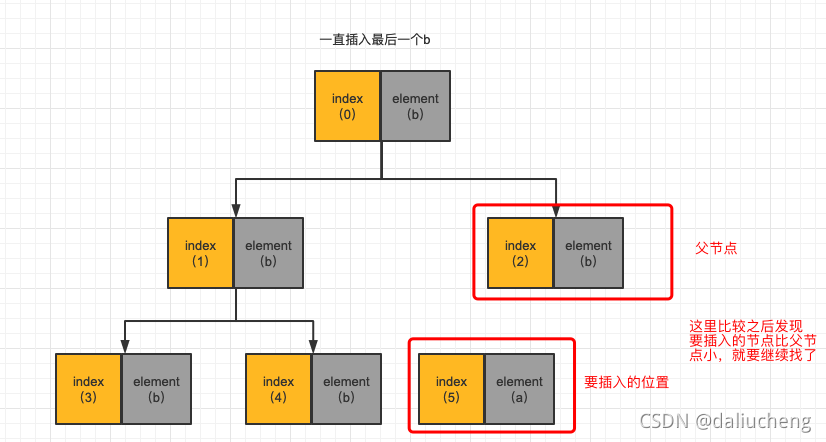
- 发现 不满足条件,这个时候将父节点下移,子节点上移,继续找。
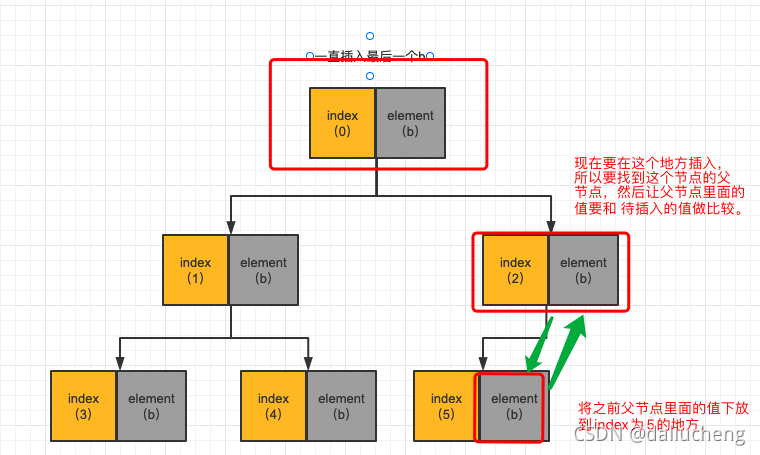
-
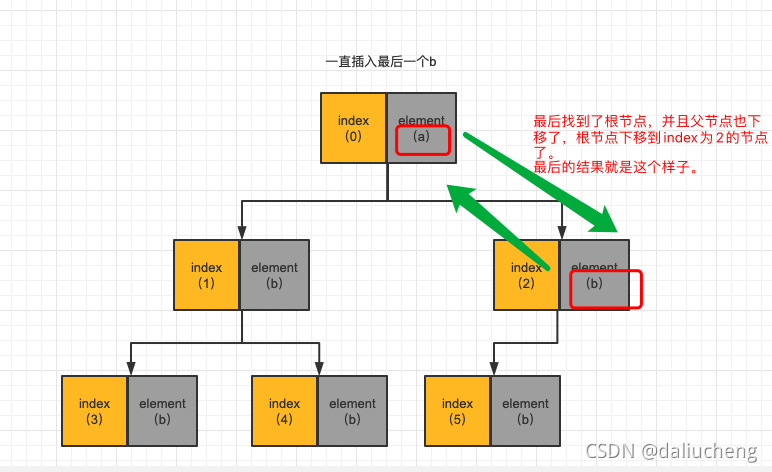
一直找,找到满足条件之后放值
自然而然,在插入一个a的话,树应该长下面的这个样?
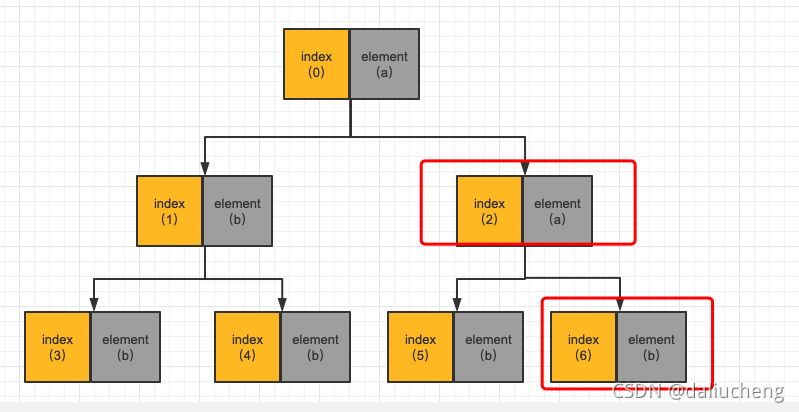
也产生了父节点下移。子节点上升。
这里就产生了一个问题,在遍历的时候如果按照数组的顺序遍历,很明显,顺序不对。所以,他出队的顺序是怎么样的。这就很有意思了。出队的时候他可是完全按照优先级的顺序的。
poll
将队头元素出队,并且将队尾元素变为null,将之前队尾元素所在下标位置变为null,将队尾元素插入到队头位置。
问题?
-
为啥要出队头元素(index=0的元素)
因为这是一个堆,还是一个小头堆,所以,index=0的元素(队头)就是整个堆中最小的元素。让他出队没有问题
-
为啥要将队尾元素插入到index=0的位置。而不是随便的位置
因为这是一个堆,还是一个小头堆,并且要保持堆的完整性,在第一个位置插入元素之后,会引起整个堆中元素结构的变动。也就是说,会再次调整堆。如果随便插入一个位置,那这个位置上面的部分就不需要调整了?所以,直接从0开始,要的就是要引起整个堆中元素的变动。
public E poll() {
if (size == 0)
return null;
// --size
int s = --size;
// 快速失败
modCount++;
// 拿到第一个元素(队头的元素是整个树的根节点,是最小的,每次出队也是出它,这没有问题。)
E result = (E) queue[0];
// 拿到队尾元素
E x = (E) queue[s];
// 队尾元素变为null
queue[s] = null;
if (s != 0)
//将队尾元素插入到第一个位置(队头)
siftDown(0, x);
return result;
}
siftDown分析
如果指定了comparator,就按照指定的comparator来比较。否则就按照默认的,其实这俩方法差不了多少,不过就是比较的部分,一个用的是自己的,一个用的是指定的comparator的。所以,这里值分析一个siftDownComparable方法
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
siftDownComparable分析
k表示要插入的元素的位置,
x表示元素
private void siftDownComparable(int k, E x) {
// 还是变为Comparable。
Comparable<? super E> key = (Comparable<? super E>)x;
// 停止查找的条件。 size/2 这就是树的高度
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
// 找到要插入位置的左子树。
int child = (k << 1) + 1; // assume left child is least
// 拿到左子树的值
Object c = queue[child];
// 找到右子树
int right = child + 1;
// right< size 不满足,说明没有右子树。
// 如果有右子树,并且右子树比左子树小,那么最小的元素就是右子树。
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
// 总的来说,一直到这里,就是为了确定要插入位置的子节点中最小的值和位置。
// 如果要插入的节点的值比 最小的值还小,那没话说,就是最小的。直接赋值就可以。否则就要进行交换了,将子节点上移,然后继续找。一直不满足条件
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
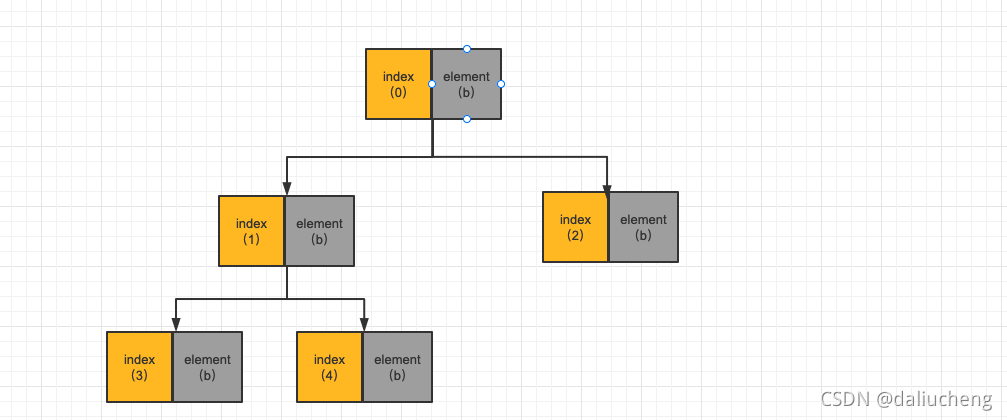
这里的操作看代码不好理解,这里画一个图便于理解,图中的例子和开头的代码例子对应。
这里开始的图是offer里面的图。
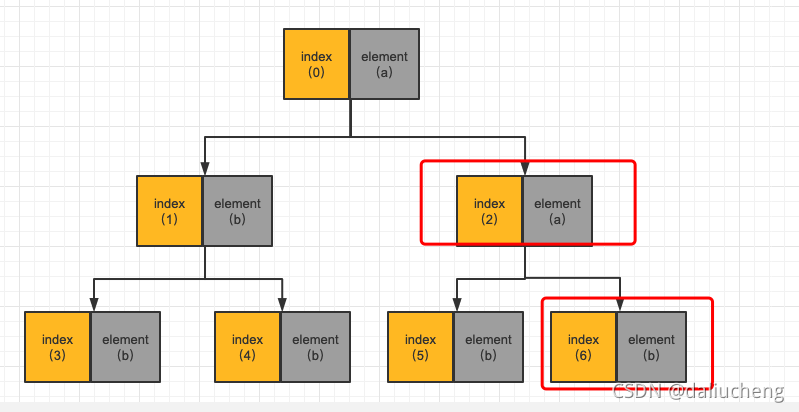
先要要poll一次。根据上面的代码逻辑,看看会发送什么事情。
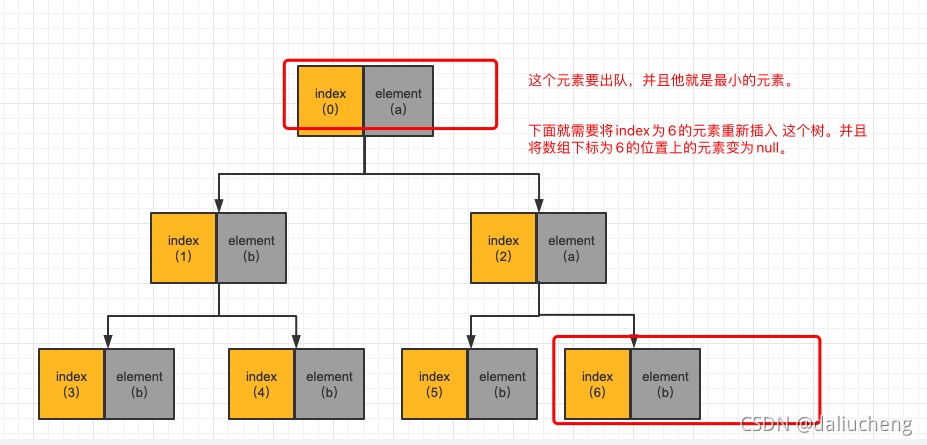
重新插入index为6的元素b
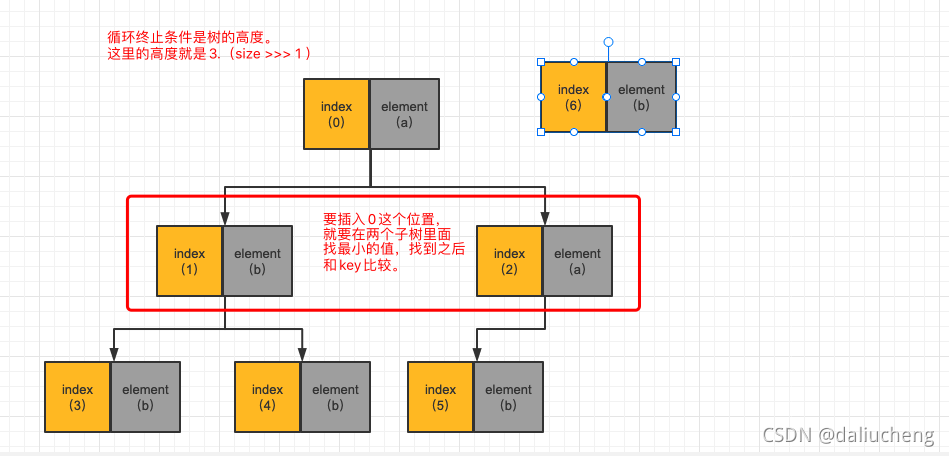
这个时候发现index为2的元素最小,可是index为6的元素没有它小,那就说明index为2的元素是整个堆中最小的。就需要上移,然后当前插入的位置变为了index为2。继续判断
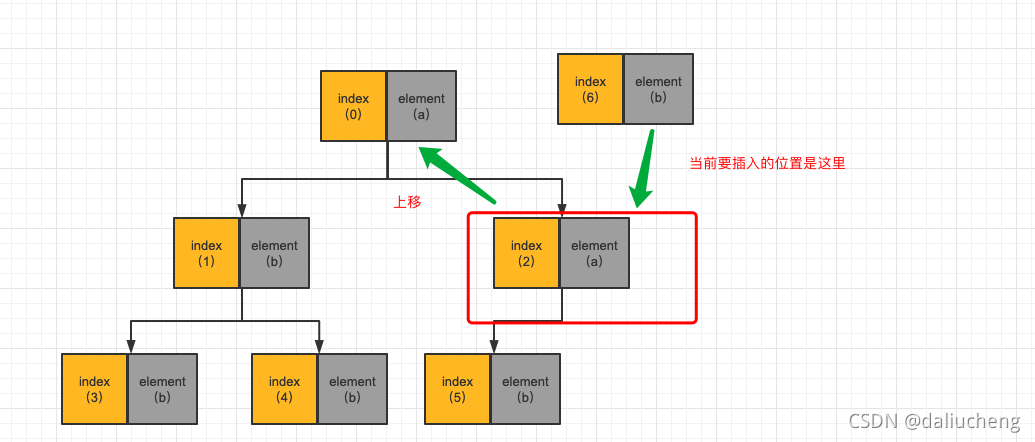
最后这个树就变成了下面的这个样子
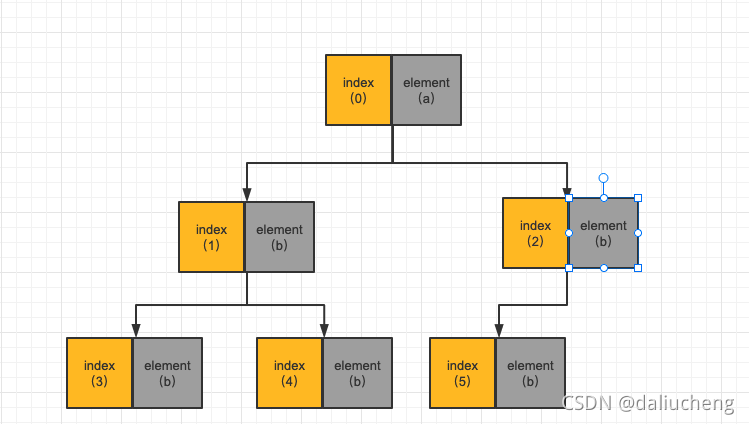
同样的,如果在调用一个poll方法,在出队一次,就变成
4. 扩容分析
只要设计到数组,肯定就有扩容操作。
// 既然是数组,而且还没有链表,那简单,直接拷贝就可了。
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// 这里就很清晰了,如果容量太小就就double,否则就增强50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
//private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 直接拷贝一个新数组就好了,核心方法
queue = Arrays.copyOf(queue, newCapacity);
}
// 这就是一个保险措施。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
别的方法就不分析了,核心说清楚就好了。
关于PriorityQueue的分析就分析到这里了。 如有不正确的地方,欢迎指出。谢谢。

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









