






javaScript
- JS基础知识
- JS高级知识
- 前端中的事件流
- 如何让事件先冒泡后捕获
- 什么是闭包?
- 事件委托/事件代理
- mouseover和mouseenter的区别
- js的new操作符做了哪些事情
- bind, apply, call的区别
- js位置参数
- js拖拽功能的实现
- 异步加载js的方法
- Ajax解决浏览器缓存问题
- js的节流和防抖
- js中的垃圾回收机制
- 内存泄漏
- 前端模块化
- 引入多个script标签后出现的问题
- 对象深度克隆的简单实现
- 实现一个once函数,传入函数参数只执行一次
- 将原生的ajax封装成promise
- js监听对象属性的改变
- 如何实现一个私有变量,用getName方法可以访问,不能直接访问
- == 和===、以及Object.is的区别
- setTimeout、setInterval 和 requestAnimationFrame之间的区别
- 用setTimeout来实现setInterval
- js异步
- 实现一个bind函数
- 类的创建和继承(待整理)
- js控制一次加载一张图片,加载完后再加载下一张
- 如何实现sleep的效果
- 获取对象原型的方法
- this指向
- 简单实现Node的Events模块
- js判断类型(待整理)
- 不同数据类型的值的比较,如何转换,有什么规则(待整理)
- 数组常用方法(后整理)
- 如何判断一个数组
- js实现跨域
- Content-Type的值
- ES6(待整理)
- JS中继承实现的几种方式
- webSocket(waiting...)
- cookie、sessionStorage和localStorage(waiting...)
- let、const和var的区别
- 闭包的作用、原理、使用场景
- apply、call和bind
- 事件循环机制
- 事件冒泡和捕获
- 事件代理
- new操作符原理
- JavaScript脚本异步加载
- 深浅拷贝
- instanceof原理
- JSON
- JS相关面试题
- js的语言特性
- 代码的执行顺序
- 去除字符串首尾空格
- 数组去重
- null == undefined ?
- 不同的数据类型的值的比较,是怎么转换的,有什么规则
- js的全排列
- 编写代码满足以下条件(链式调用)
- 写一个函数,第一秒打印1,第二秒打印2
- 对原型链的理解
- 实现寄生组合继承
- map和Object的区别
- 连续多个bind,最后的this指向?
- 正向代理和反向代理的区别
- 箭头函数和普通函数的区别?
- promise.all和promise.allsettled区别
- substring和substr的区别
- Symbol的作用和使用场景
- typeof和instanceof的区别
- for in 和for of区别
- map和forEach是否可以通过break跳出?
- 0.1+0.2不等于0.3?
- requestAnimationFrame和requestIdleCallback?
- mouseover 和 mouseenter
JS基础知识
script元素
| 属性 | 作用 |
|---|---|
| async | 可选。表示应该立即开始下载脚本,但不能阻止其他页面动作,比如下载资源或等待他脚本加载。支队外部脚本文件有效 |
| charset | 可选。使用src属性指定的代码字符集。这个属性很少使用,因为大多数浏览器不在乎它的值。 |
| crossorigin | 可选。配置相关请求的CORS(跨源资源共享)设置。默认不使用CORS。crossorigin="anonymous"配置文件请求不必设置凭据标志。crossorigin="use-credentials"设置凭据标志,意味着出站请求会包含凭据。 |
| defer | 可选。表示在文档解析和显示完成后再执行脚本是没有问题的。只对外部脚本文件有效。在IE7及更早的版本中,对行内脚本也可以指定这个属性 |
| integrity | 可选。允许比对接收到的资源和指定的加密签名以验证子资源完整性(SRI,Subresource Intergrity)。如果接收到的资源的签名与这个属性指定的签名不匹配,则页面会报错,脚本不会执行。这个属性可以用于确保内容分发网络(CDN,Content Delivery Network)不会提供恶意内容 |
| language | 废弃。最初用于表示代码块中的脚本语言(如"JavaScript"、“JavaScript1.2"或"VBScript”)。大多数浏览器都会忽略这个属性,不应该再使用它。 |
| src | 可选。表示包含要执行的代码的外部文件。 |
| type | 可选。代替language,表示代码块中脚本语言的内容类型(也称MIME类型)。按照惯例,这个值始终都是"text/javascript",尽管"text/javascript"和"text/ecmascript"都已经废弃了。JavaScript文件的MIME类型通常是"application/x-javascript",不过给type属性这个值有可能导致脚本被忽略。在非IE浏览器中有效的其他值还有"application/javascript"、“application/ecmascript”。如果这个值时module,则代码会被当成ES6模块,而且只有这时候代码中才能出现import和export关键字 |
-
推迟执行脚本defer
<!DOCTYPE html> <html> <head> <title>example</title> <script defer src="example1.js"></script> <script defer src="example2.js"></script> </head> <body> <!-- 这里是页面内容 --> </body> </html>example1.js文件会在html标签解析结束后执行。HTML5规范要求脚本应该按照它们出现的顺序执行,因此第一个推迟的脚本会在第二个推迟的脚本之前执行,而且两者都会在DOMContentLoaded事件之前执行。
不过在实际当中,推迟执行的脚本不一定总会按顺序执行或者在DOMContentLoaded事件之前执行,因此最好只包含一个这样的脚本。
注意:IE8+及更高版本支持HTML5定义的行为。对于defer属性的支持时从IE4、FF3.5、Safari5和Chrome7开始的。其他所有浏览器则会忽略这个属性,按照通常的做法来处理脚本。所以把要推迟执行的脚本放在页面底部比较好。 -
异步执行脚本 async
从改变脚本处理方式上看,async属性与defer类似。当然两者也都只适合用于外部脚本,都会告诉浏览器立即开始下载。不过,与defer不同的时,标记为async的脚本并不保证能按照它们出现的次序执行。
给脚本添加async属性的目的时高速浏览器,不必等脚本下载和执行完成再加载页面,同样也不必等到该一步脚本下载和执行后再加载其他脚本。
注意,异步脚本不应该在加载期间修改DOM。
一步脚本保证会在页面的load事件前执行,但可能会在DOMContentLoaded之前或之后。<!DOCTYPE html> <html> <head> <title>example</title> <script async src="example1.js"></script> <script async src="example2.js"></script> </head> <body> <!-- 这里是页面内容 --> </body> </html> -
动态加载脚本
let script = document.createElement('script'); script.src = 'gibberish.js'; // script.async = false; document.head.appendChild(script);
数据类型
简单数据类型(也称原始类型、基本数据类型)
undefined
Null
Boolean
Number
String
Symbol:ES6新增
typeof返回值
undefined
boolean
string
number
object
function
symbol
特别注意: typeof null —> object
引用数据类型(待整理)
JS高级知识
前端中的事件流
HTML与javascript交互时通过事件驱动来实现的,例如鼠标点击事件omclick、页面的滚动事件onscroll等等,可以向文档或者文档中的元素添加事件侦听器来预订事件。想要知道这些事件是在什么时候进行调用的,就需要了解一下"事件流"的概念。
什么是事件流:事件流描述的是页面中元素接收事件的顺序。
DOM2级事件流包括下面几个阶段:
- 事件捕获阶段
- 处于目标阶段
- 事件冒泡阶段
DOM2给元素添加事件的函数:addEventListener(事件名, 事件处理函数, 布尔值) 最后这个布尔值参数如果是true,表示在捕获阶段调用事件处理程序;如果时false,表示在冒泡阶段调用事件处理程序。IE只支持事件冒泡。
如何让事件先冒泡后捕获
在DOM标准事件模型中,是先不回后冒泡。
但是如果要实现先冒泡后捕获的效果,对于同一个事件,监听捕获和冒泡,分别对应相应的处理函数,监听到捕获事件,先暂缓执行,直到冒泡事件被捕获后再执行捕获之间。
可以用setTimeout将捕获阶段要进行的操作放入宏队列中,以达到延缓执行的效果。
什么是闭包?
- 闭包产生?
当一个嵌套的内部函数引用了嵌套的外部函数的变量时,就产生了闭包。 - 闭包到底是什么
- 理解一: 闭包时嵌套的内部函数
- 理解二:包含被引用变量的对象
- 注意:闭包存在于嵌套的内部函数中
- 产生闭包的条件
- 函数嵌套
- 内部函数引用了外部函数的数据(变量/函数)
- 闭包的作用
- 使函数内部的变量在函数执行完后,仍然存活在内存中(延长了局部变量的声明周期)
- 让函数外部可以操作(读/写)函数内部的数据(变量/函数)
- 闭包的生命周期
- 产生:在嵌套内部函数定义执行完成时就产生了
- 死亡:在嵌套的内部函数成为垃圾对象时
事件委托/事件代理
简介:事件委托指的是,不在事件的发生地(直接dom)上设置监听函数,而是在其父元素上设置监听函数,利用了事件冒泡原理,父元素可以监听到子元素上事件的触发,通过判断事件发生元素dom的类型,来做出不同的相应。
举例:最经典的就是ul和li标签的事件监听,比如我们在添加事件的时候,采用事件委托机制,不会在li标签上直接添加,而是在ul父元素上添加。
好处:比较适合动态元素的绑定,新添加的子元素也会有监听函数,也可以有事件触发机制。
mouseover和mouseenter的区别
mouseover:当鼠标移入元素或其子元素都会触发事件,所以有一个重复触发,冒泡的过程。对应的移出事件时mouseout。
mouseenter:当鼠标移入元素本身(不包含元素的子元素)会触发事件,也就是不会冒泡,对应的移出事件时mouseleave。
js的new操作符做了哪些事情
- 创建一个空对象obj
- 将空对象obj的隐式原型指向构造函数的显式原型
- 将构造函数绑定到obj并执行构造函数,其返回值假设为res
- 判断res是否为对象,若时则返回res,否则返回obj
let createNew = function() {
// 1. 创建空对象
let obj = {};
// 2. 将argument转换为数组并删除第一个值(即构造函数) 返回被删除的值(构造函数)
let construct = [].shift.call(argument);
// 3. 将创建的实例对象的隐式原型 指向 构造函数的显式原型
obj.__proto__ = construct.prototype;
// 4. 使用apply改变构造函数this的指向到新建的对象,这样obj就可以访问到构造函数中的属性
let res = construct.apply(obj, arguments);
// 5. 若构造函数返回一个对象res那么实例中只能访问到res中的属性
// 所以需要判断res是否为object,若是则返回这个对象res,否则返回obj
return typeof res === 'object' ? res : obj;
}
bind, apply, call的区别
- apply: 调用一个对象的一个方法,用另一个对象替换当前对象
例如:B.apply(A, arguments) ,即A对象应用B对象的方法。 - call: 调用一个对象的一个方法,用另一个对象替换当前对象。
例如:B.call(A,arg1,arg2),即A对象调用B对象的方法。 - bind除了返回是函数以外,它的参数与call一样
js位置参数
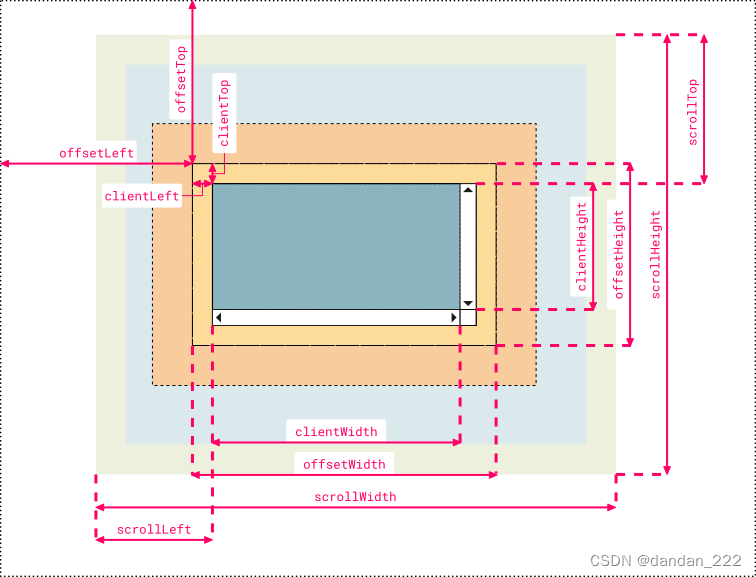
-
clientHeight、clientWidth
只读属性,返回元素的可视区域的高度或宽度,包括padding但是不保存border、滚动条、margin的元素高度
clientHeight = height + padding
clientWidth = width + padding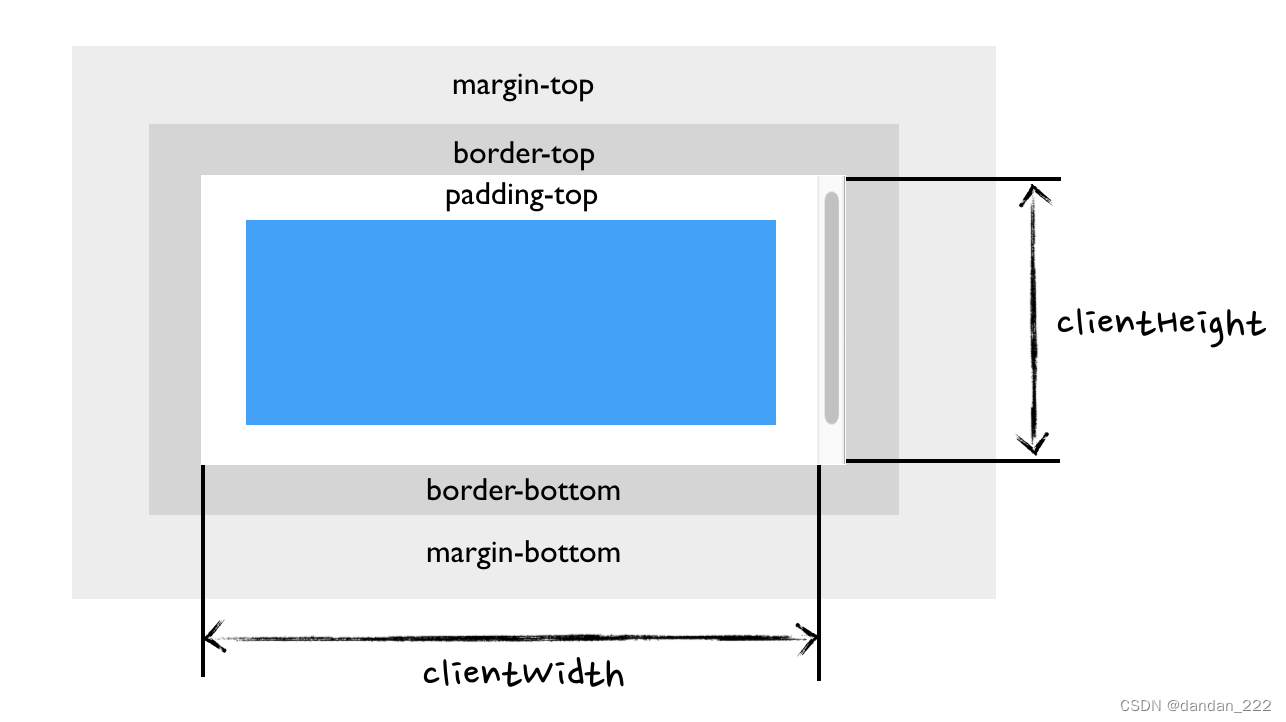
-
offsetHeight、offsetWidth
只读属性,返回元素的像素高度或宽度,宽度包含内边距(padding)和边框(border)、滚动条,不包含外边距(margin),是一个整数,单位是像素 px。
通常,元素的 offsetWidth 是一种元素 CSS 宽度的衡量标准,包括元素的边框、内边距和元素的滚动条(如果存在且渲染的话),不包含 :before或 :after 等伪类元素的宽度。
对于文档的 body 对象,它包括代替元素的 CSS 宽度线性总含量高。浮动元素的向下延伸内容宽度是被忽略的。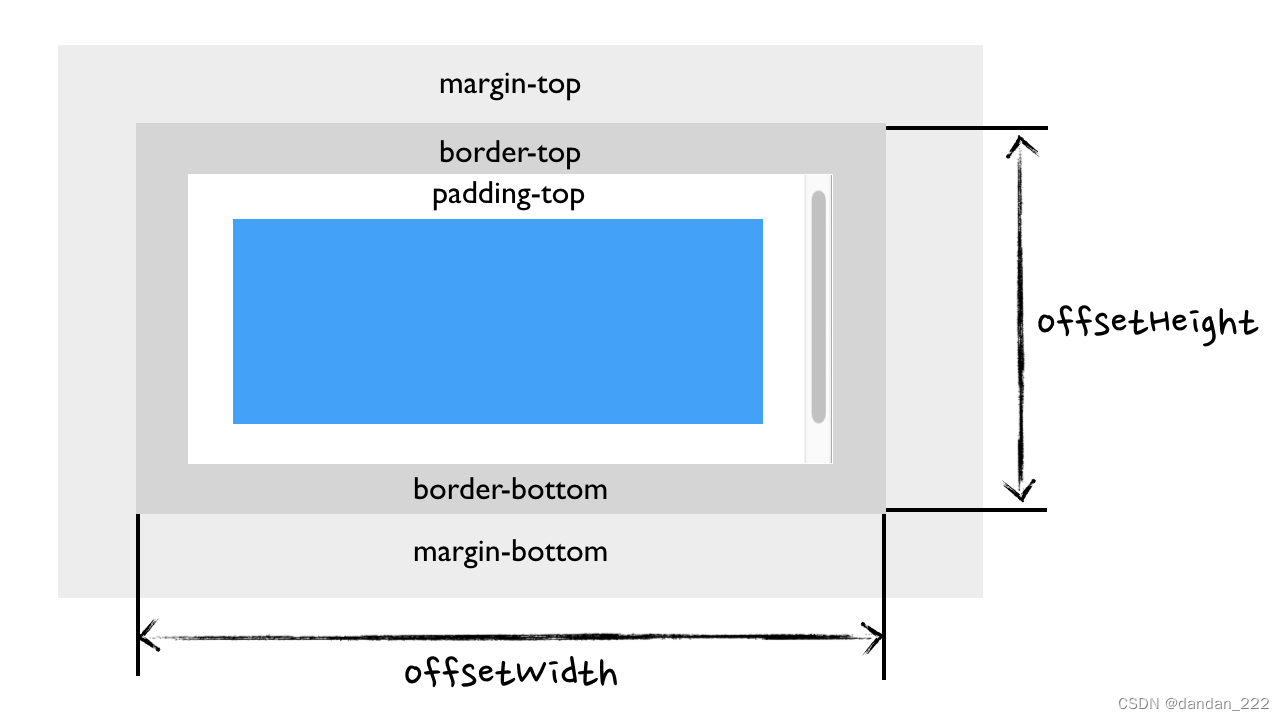
-
scrollWidth、scrollHeight
只读属性,它返回该元素的所有区域宽度或高度,高度包含内边距(padding),不包含外边距(margin)、边框(border)以及滚动被隐藏的部分,是一个整数,单位是像素 px。
scrollWidth 值等于元素在不使用水平滚动条的情况下适合视口中的所有内容所需的最小宽度。 宽度的测量方式与 clientWidth 相同:它包含元素的内边距,但不包括边框,外边距或垂直滚动条(如果存在)。 它还可以包括伪元素的宽度,例如 ::before 或 ::after。 如果元素的内容可以适合而不需要水平滚动条,则其 scrollWidth等于 clientWidth
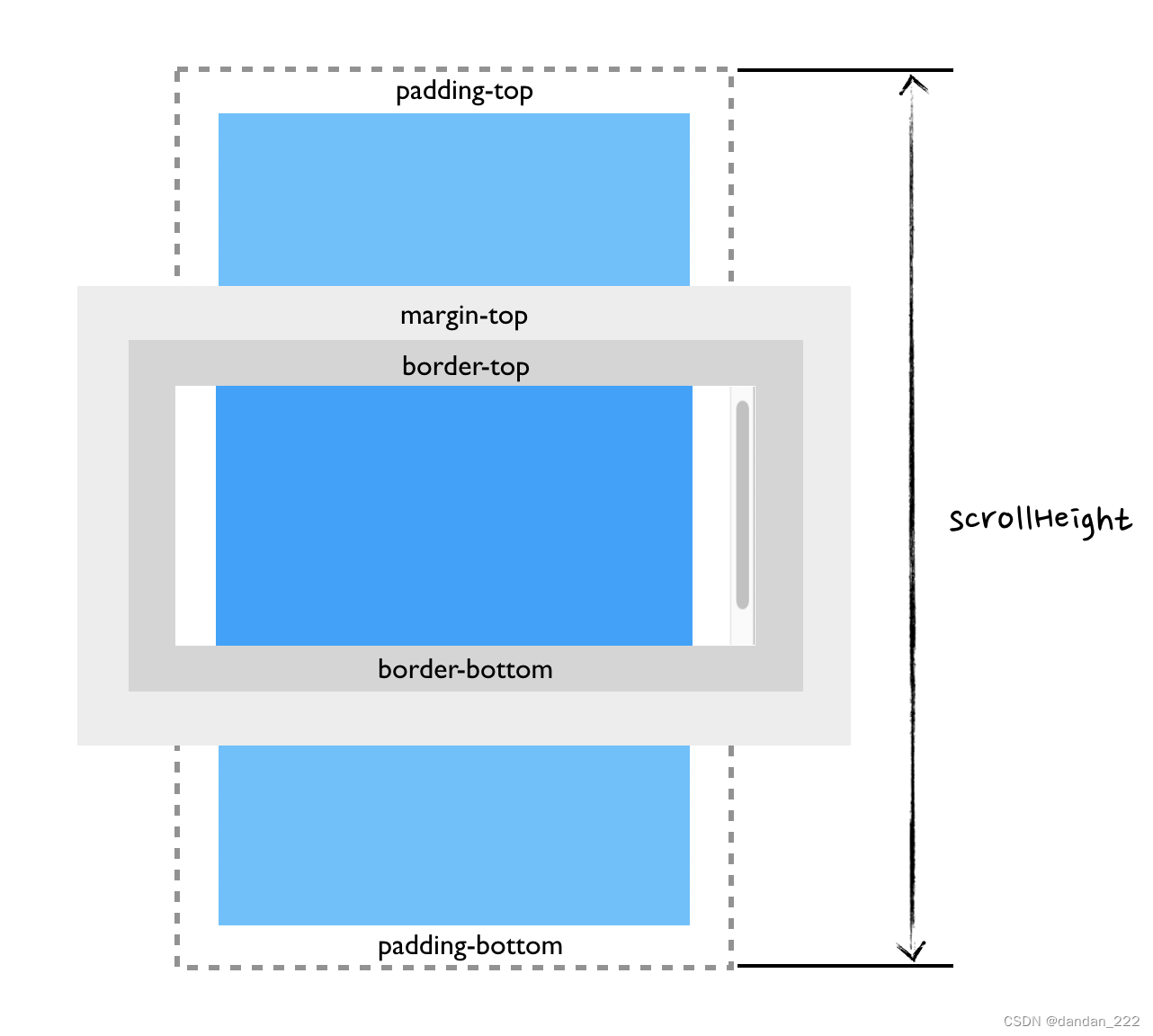
-
clientTop
表示元素顶部边框的厚度 -
scrollTop
代表在有滚动条时,滚动条向下滚动的距离,也就是元素顶部被遮住部分的高度。可读可设置。 -
offsetTop
当前元素顶部距离最近父元素顶部的距离,和有没有滚动条没有关系。只读属性。
js拖拽功能的实现
html
<div class="father">
<div class="child"></div>
</div>
css
* {
padding: 0;
margin: 0;
}
.father {
width: 200px;
height: 400px;
background-color: aquamarine;
position: relative;
marign-top: 30px;
}
.child {
width: 30px;
height: 30px;
background-color: bisque;
border: 1px solid steelblue;
postion: absolute;
top: 0;
left: 0;
}
js
const father = document.querySelector('.father');
const child = father.querySelector('.child');
child.addEventListener('mousedown', function(event) {
let relativeX = event.clientX - child.offsetLeft;
let relativeY = event.clientY - child.offsetTop;
console.log('relativeX:', relativeX, 'relativeY', relativeY);
father.addEventListener('mousemove', mouseMoveHandle);
father.addEventListener('mouseup', mouseUpHandle);
function mouseMoveHandle(event) {
let currentX = event.clientX - relativeX;
let currentY = event.clientY - relativeY;
console.log('clientTop:', father.clientTop);
console.log('offsetTop:', father.offsetTop);
if (currentX < father.offsetLeft) {
currentX = father.offsetLeft;
} else if (currentX > father.offsetLeft + father.offsetWidth - child.offsetWidth) {
currentX = father.offsetLeft + father.offsetWidth - child.offsetWidth;
}
if (currentY < father.clientTop) {
currentY = father.clientTop;
} else if (currentY > father.clientTop + father.clientHeight - child.offsetHeight) {
currentY = father.clientTop + father.clientTop + father.clientHieght - child.offsetHeight;
}
console.log(currentX, currentY);
child.style.left = currentX + 'px';
child.style.top = currentY + 'px';
}
function mouseUpHandle(event) {
father.removeEventListener('mousemove', mouseMoveHandle);
father.removeEventListener('mouseup', mouseUpHandle);
}
});
异步加载js的方法
-
defer异步加载
只有IE9以下能用,异步加载,但要等到dom文档全部解析完(dom树已生成)才会被执行,执行时不会阻塞页面<script type = 'text/javascript' src = 'tools.js' defer = 'defer'> </script>或
<script type = 'text/javascript' src = 'tools.js' defer > </script>也可以将代码写到内部
<script type = 'text/javascript' defer> var a = 123; //写在内部 </script> -
async异步加载
W3C标准方法,异步加载,加载完就执行,执行时不会阻塞页面,async只能加载外部js,不能把js写在script标签里<script type = 'text/javascript' src = 'tool.js' async = 'async'></script>或
<script type = 'text/javascript' src = 'tool.js' async ></script> -
动态创建script标签
以上两种方法不能很好的处理浏览器兼容问题,因此可以使用第三种方法,更加强大,既可异步加载,也可按需加载。const script = document.createElement('script'); //创建dom script.type = 'text/javascript'; //设置 script.src = 'index.js'; //这句执行完 系统就会异步下载指定的文件 ...//其他的操作 document.head.appendChild(script); //script标签插入文档后 系统才会解析这个脚本 否则只是下载但由于系统是异步下载js文件,很可能script标签插入文档的时候,甚至调用js文件中方法的时候,js文件还没有下载完成。
const script = document.createElement('script'); script.type = 'text/javascript'; script.src = 'index.js'; //这句执行完 系统就会异步下载指定的文件 document.head.appendChild(script); //script插入文档后 才会解析这个脚本 否则只是下载 test(); //系统执行这段语句的时候 js文件可能还未加载完 故会报错可以设置定时器,在规定时间后(给js文件下载时间)再执行函数
const script = document.createElement('script'); script.type = 'text/javascript'; script.src = 'index.js'; //这句执行完 系统就会异步下载指定的文件 document.head.appendChild(script); //script插入文档后 才会解析这个脚本 否则只是下载 // test(); setTimeout(function() { //设置定时器 在规定时间后再执行函数 test(); //这个时候js文件已经下载完成 可以执行 },1000);但并不清楚要等待多久js文件才会下载完成,那么有没有一个机制能够进行提醒呢?可以使用load事件(并不是只有window才有load事件,但凡需要下载的就有load事件,比如script)。
const script = document.createElement('script'); script.type = 'text/javascript'; script.src = 'index.js'; //这句执行完 系统就会异步下载指定的文件 script.onload = function() { //script加载(即js文件下载完)完毕才执行函数 test(); } document.head.appendChild(script); //script插入文档后 才会解析这个脚本 否则只是下载script.onload的能够兼容safari、chrome、firefox、opera,只有IE不兼容,IE没有load事件。
但IE有一套自己的方法,IE的script上有一个属性为状态码readyState,默认值是loading,会根据script的加载进度动态地改变属性值,script加载完毕时状态码的值为complete或loaded。
IE也提供了一套监听机制用于监听script的状态码的变化。script.onreadystatechange = function() { //监听script的状态码的变化 if (script.readyState == 'complete' || 'loaded') { //script加载完毕 // 逻辑 } }能够解决浏览器兼容问题的js文件加载完成立即执行函数逻辑的工具方法
function loadScript(url,callback) { //callback回调函数可以是函数、字符串、数组等 const script = document.createElement('script'); script.type = 'text/javascript'; if (script.readyState) { //IE script.onreadystatechange = function() { //监听script的状态码的变化 if (script.readyState === 'complete' || 'loaded') { callback(); //eval(callback) 当callback为字符串(情况1)时,eval可将其当作函数来调用 //obj[callback]() 当callback为字符串(情况2)且所要调用的函数在js文件中是以对象属性的形式存在时 } } } else { //safari、chrome、firefox、opera script.onload = function() { callback(); //eval(callback); //obj[callback](); } } script.src = url; //js文件的下载最好放在绑定监听事件之后,以免状态码在绑定监听事件之前已完成变化就不会被监听到 document.head.appendChild(script); } // loadScript('index.js',test); //会报错 test is not defined 因为在传入test的时候,js文件还在函数中未被加载 loadScript('index.js', function() { //可传入匿名函数 传入时函数内部逻辑不会被解析 test(); }) ; // 或 loadScript('index.js', 'test()'); //传入字符串形式(情况1) // 或 loadScript('index.js', 'test'); //传入字符串形式(情况2)
Ajax解决浏览器缓存问题
浏览器第一次访问服务器的时候,会从服务器下载静态资源(js、css、image等),并将资源文件缓存在浏览器,当再次访问页面时,如果有相同的资源文件就直接到缓存中去加载,这样就会降低服务器的负载,加快用户访问速度。
但是有些情况下会出现bug,比如验证码每次图片不同的情况下,这时候就要避免浏览器的缓存
- 设置header头,禁止浏览器缓存该文件
header("Cache-Control:no-cache"); header("Pragma:no-cache"); header("Expires:-1"); - 在URL后面加上一个随机数: “fresh=” + Math.random();。
- 在URL后面加上时间差:“nowtime=” + new Date().getTime();。
- 如果是使用jQuery,直接这样就可以了$.ajaxSetup({cache:false})。这样页面的所有ajax都会执行这条语句就是不需要保存缓存记录。
js的节流和防抖
- 防抖函数(debounce)
防抖函数是为了防止用户进行一些点击事件、输入文字、浏览器窗口大小resize或者滚动条滚动时,对应绑定的事件发生多次。
触发事件后,在 n 秒内函数只能执行一次,如果触发事件后在 n 秒内又触发了事件,则会重新计算函数延执行时间。
防抖函数的时间段,就相当于给用户的操控时间。
function debounce(func.delay) {
let timeout;
return function() {
// 每当用户输入的时候把前一个setTimeout clear掉
clearTimeout(timeout);
// 然后创建一个新的setTimeout,这样就能保证interval间隔内如果事件持续触发,就不会执行fn函数
timeout = setTimeout(() => {
func.apply(this, arguments);
}, delay);
}
}
// 实际想绑定在scroll事件上的handler
function handler () {
}
// 采用了防抖 绑定监听
// 注意 这里第二个参数debounce(handler, 500)等价于debounce内部的闭包函数
window.addEventListener('scroll', debounce(handler, 500));
- 节流函数(throttle)
节流函数是为了防止用户多次操作同一事件。
在事件触发后的规定时间段内,无法再调用目标函数。
例如,点击发送验证码,在规定时间段内,禁止用户再次点击这个按钮,防止发送多次请求。
节流函数的原理,关键在于获取函数调用时的时间戳。
function throttle(func, delay, mustRun) {
let timeout;
let startTime = new Date();
return function () {
cosnt context = this;
cosnt args = arguments;
let curTime = new Date();
cleartTimeout(timeout);
// 如果达到了规定的出发时间间隔,触发handler两个Date实例对象相减得到相差的毫秒数
if (curTime - startTime >= mustRun) {
func.apply(context, args);
startTime = curTime;
} else { // 没有达到触发时间,重新设置定时器
timeout = setTimeout(func, delay);
}
}
}
// 实际想绑定在scroll事件上的handler
function realFunc() {
console.log('success');
}
// 采用节流函数
window.addEventLister('scroll', throttle(realFunc, 500, 1000));
js中的垃圾回收机制
在js中创建一个变量时,会自动分配内存空间,当变量不再被使用时,垃圾回收机制会自动释放相应的内存空间。
如何判断一个变量不在被使用?方法有两种:
- 引用计数法
原理很简单,就是看一份数据是否还有引用指向它,若没有,那么垃圾回收机制就会回收,其策略是跟踪记录每个变量值被使用的次数。
-
当声明了一个变量并将一个引用类型赋值给该变量时,这个值的引用次数就为 1
-
如果同一个值又被赋给另一个变量,那么引用数加 1
-
如果该变量的值被其他的值覆盖了,则引用次数减 1
-
当这个值的引用次数变为 0 时,说明没有变量在使用,这个值无法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存。
引用计数存存在一个致命的缺陷,当对象间存在循环引用时,引用次数始终不会为0,因此垃圾回收器不会释放它们。
function f() { var o1 = {}; var o2 = {}; o1.a = o2; // o1 引用 o2 o2.a = o1; // o2 引用 o1 return; };在 IE8 以及更早版本的 IE 中, BOM 和 DOM中的对象并不是原生的JS对象,而是使用C++以 COM对象的形式实现的,而 COM对象的垃圾收集机制采用的就是引用计数策略。因此,即使 IE 的 JavaScript引擎是使用标记清除策略来实现的,但JavaScript访问的COM对象依然是基于引用计数策略的。换句话说,只要在IE8及以下版本中涉及 COM对象,就会存在循环引用的问题。下面这个简单的例子,展示了使用 COM对象导致的循环引用问题;
var element = document.getElementById("some_element"); var myObject = new Object{); myObject. element = element; element.someObject = myObject;
- 标记清除法
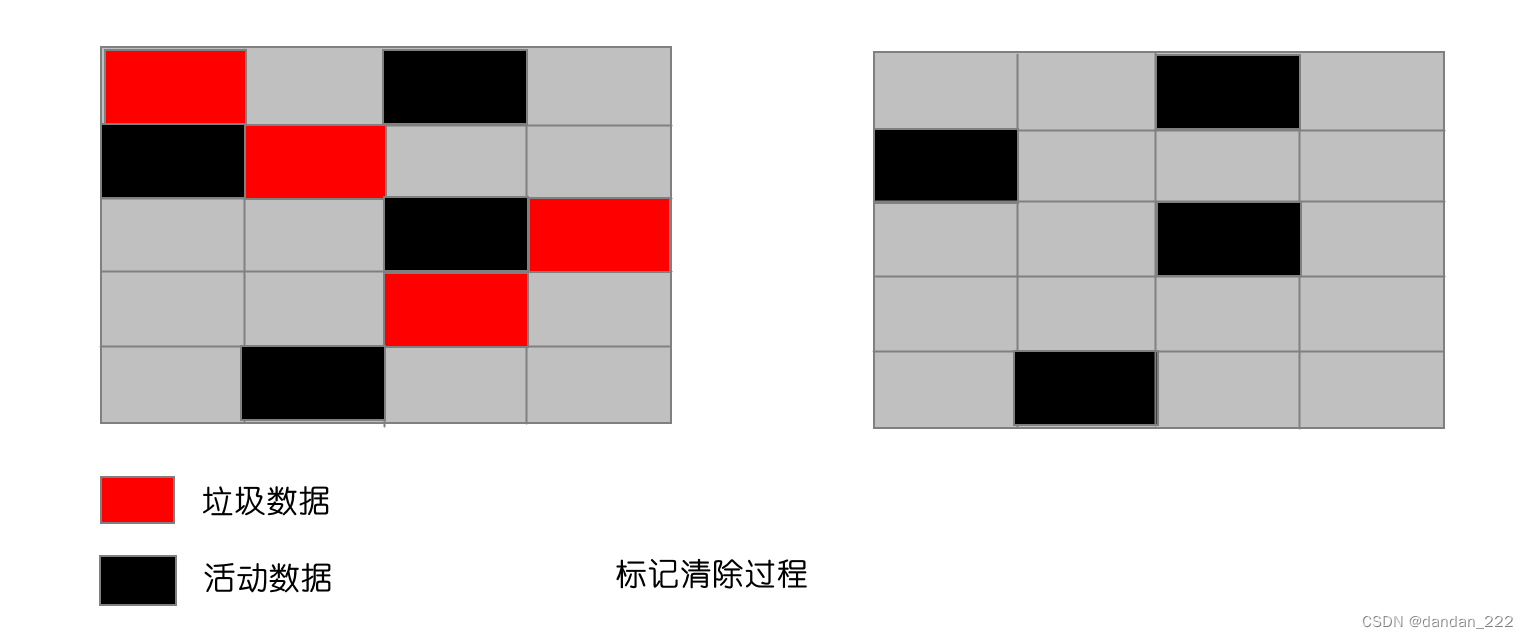
标记清除(Mark-Sweep),目前在 JavaScript引擎 里这种算法是最常用的,到目前为止的大多数浏览器的 JavaScript引擎 都在采用标记清除算法。
此算法可以分为两个阶段,一个是标记阶段(mark),一个是清除阶段(sweep)。- 标记阶段,垃圾回收器会从根对象开始遍历(在js中,通常认定全局对象window做为根)。每一个可以从根对象访问到的对象都会被添加一个标识,于是这个对象就被标识为可到达对象。
- 清除阶段,垃圾回收器会对堆内存从头到尾进行线性遍历,如果发现有对象没有被标识为可到达对象,那么就将此对象占用的内存回收,并且将原来标记为可到达对象的标识清除,以便进行下一次垃圾回收操作。
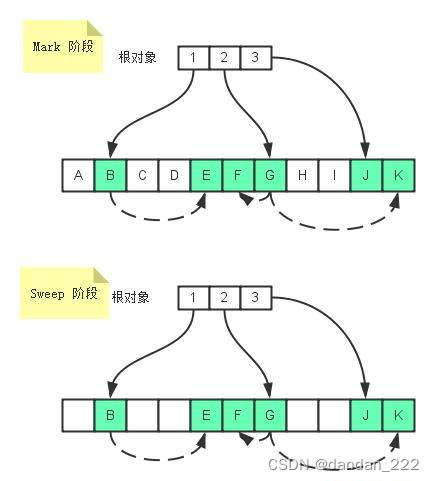
标记清除法会导致内存碎片化。由于空闲内存块是不连续的,容易出现很多空闲内存块,假设我们新建对象分配内存时需要大小为 size,由于空闲内存是间断的、不连续的,则需要对空闲内存列表进行一次单向遍历找出大于等于 size 的块才能为其分配(如下图)
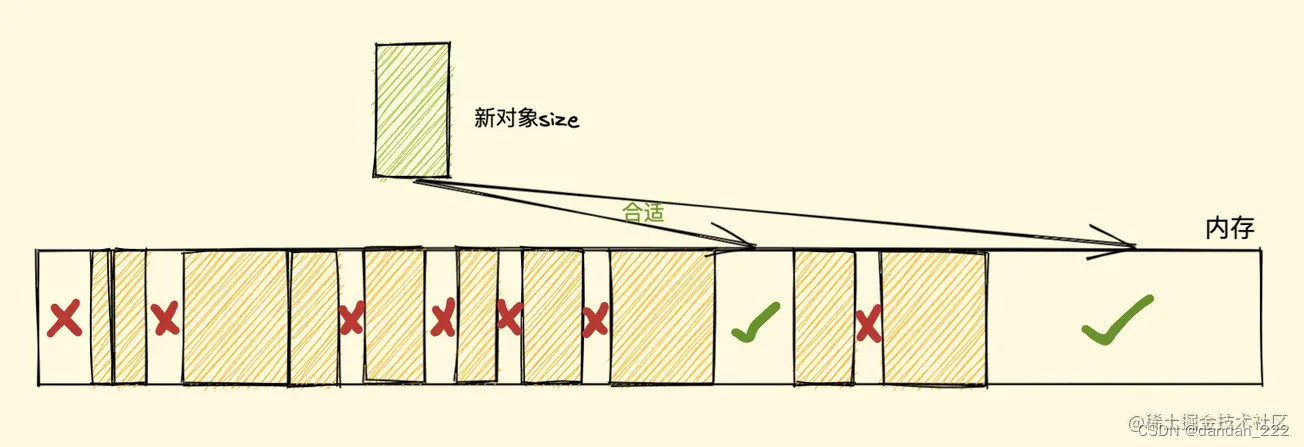
如何找到合适的块呢?可以采取下面三种分配策略
-
First-fit,找到大于等于 size 的块立即返回
-
Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
-
Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回
这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择,但即便是使用 First-fit 策略,其操作仍是一个 O(n) 的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢。
v8引擎的垃圾回收机制
Chrome 浏览器所使用的 V8 引擎采用的分代回收策略,该策略通过区分「临时」与「持久」对象;多回收「临时对象区」(young generation),少回收「持久对象区」(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时。
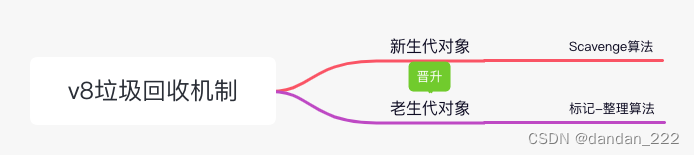
新生代的特点:
- 通常把小的对象分配到新生代
- 新生代的垃圾回收比较频繁
- 通常存储容量在1~8M
新生代-Scavenge算法
该算法将新生代分为两部分,一部分叫做from(对象区域),另一部分叫做to(空闲区域),新加入的对象首先存放在from区域;
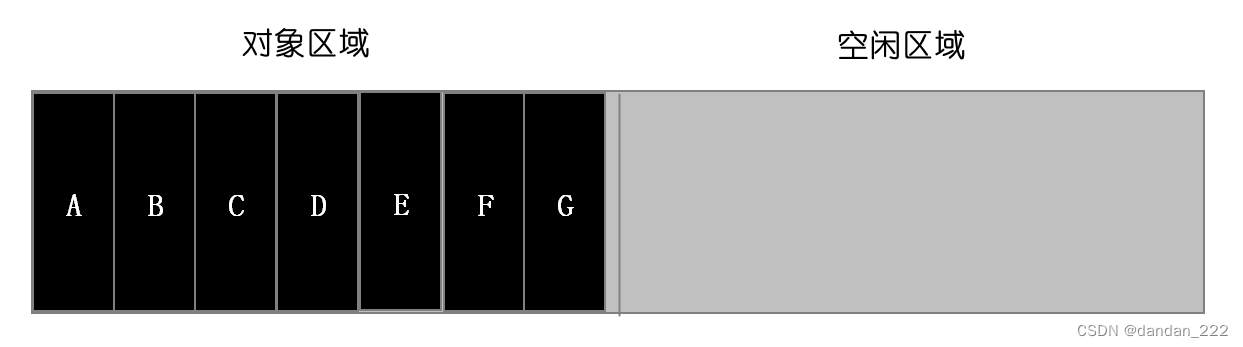
from区域写满的时候,对from区域开始进行垃圾回收。首先对from区域的垃圾进行标记(红色代表标记为垃圾);
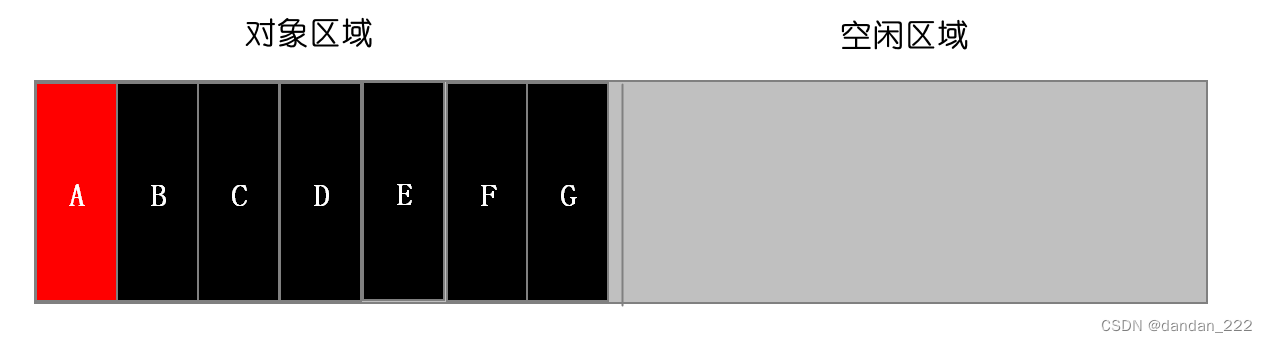
将存活的对象复制到to区域中,并且有序地排列起来,复制后的to区域就没有内存碎片了;
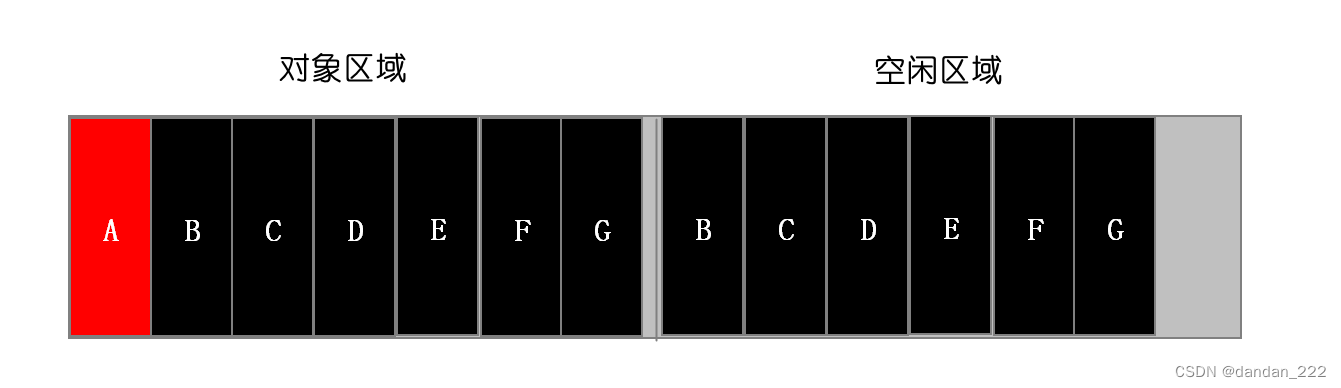
清空from区域
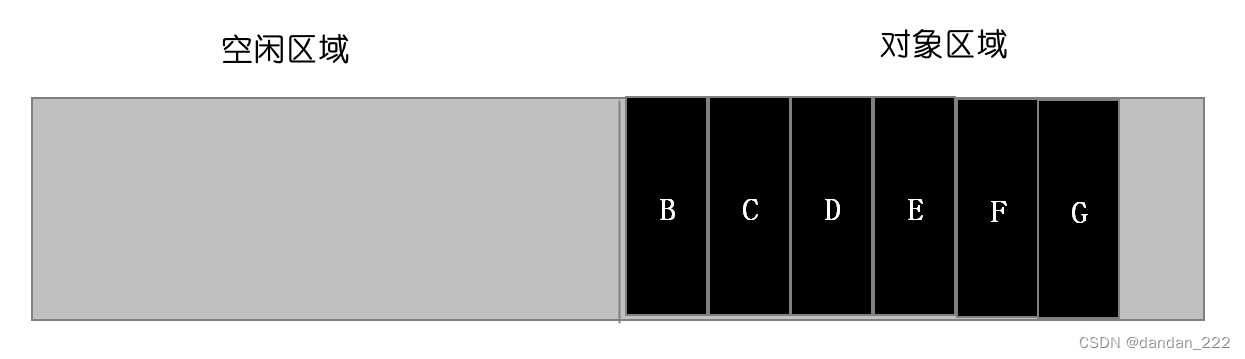
from区域和to区域进行反转,也就是原来的from区域变为to区域,原来的to区域变成from区域。
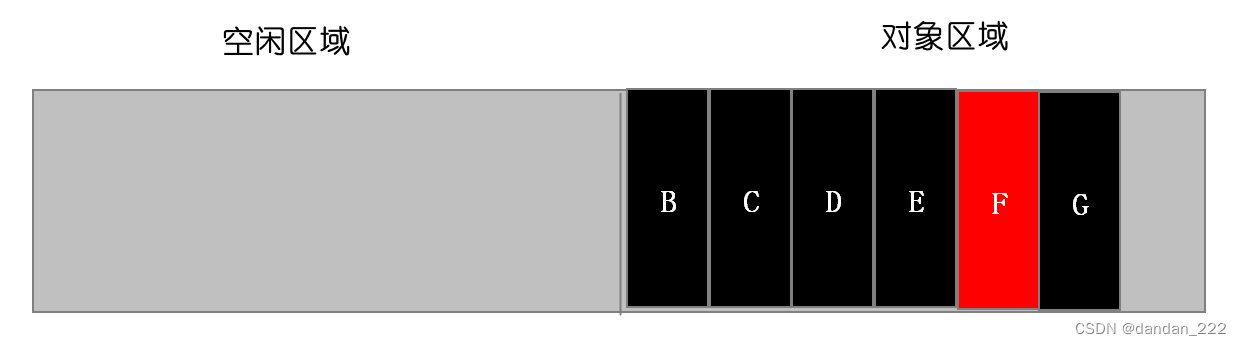
Scavenge算法在时间效率上有着优异的表现,缺点是只能使用堆内存中的一半,如果存储容量过大,就会导致每次清理的时间过长,效率低,因此经过两次垃圾回收之后依然存活的对象会晋升为老生代对象,另外还有一种情况,如果复制一个对象到空闲区时,空闲区空间占用超过了 25%,那么这个对象会被直接晋升到老生代空间中,设置为 25% 的比例的原因是,当完成 Scavenge 回收后,空闲区将翻转成对象区域,继续进行对象内存的分配,若占比过大,将会影响后续内存分配。
老生代的特点:
- 对象占用空间大
- 对象存活时间长
老生代-标记整理法
- 标记:和标记 - 清除的标记过程一样,从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素标记为活动对象;
- 整理:让所有存活的对象都向内存的一端移动
何时执行垃圾回收?
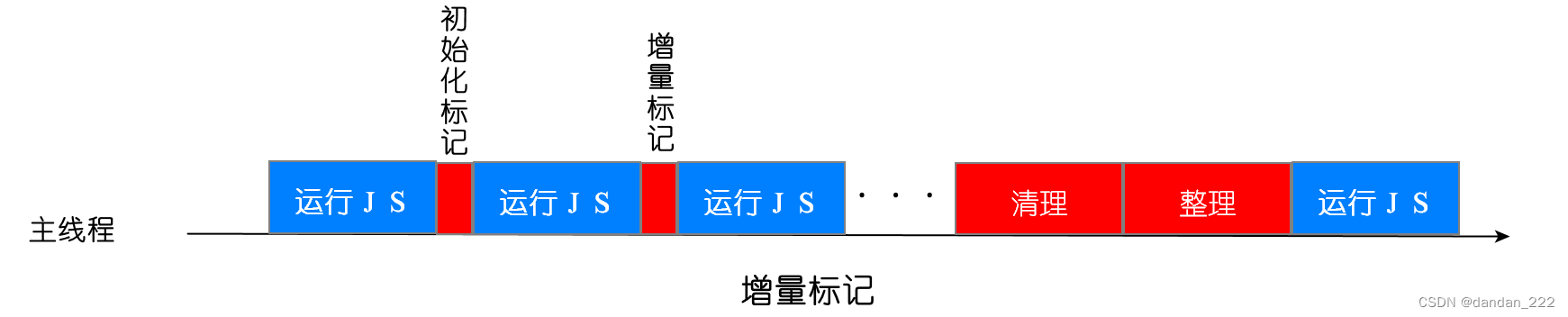
由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)。

为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法
内存泄漏
前端模块化
什么是模块
- 将一个复杂的程序根据一定规则(规范),封装成几个块,然后组合在一起
- 块内部的数据和实现私有化,暴露一些接口与其他模块进行通信
模块化进化过程
-
全局function模式
将不同的功能封装成全局函数
但是存在污染全局命名空间的问题,容易引起命名冲突或数据安全问题,并且模块成员间的关系不容易直接看出。function t1() {} function t2() {} -
namespace模式
将不同的功能封装到对象内部,简单的对象封装。
数据不安全,外部可以直接修改模块内部的数据甚至方法。const testModule = { data: 'test', func1() {}, func2() {} } testModule.data = 'replace'; // 修改模块内部数据 testModule.foo = () => {}; // 修改模块内部方法 -
IIFE模式
通过匿名函数自调用的方式,是一种闭包,将数据和行为封装到匿名函数内部,通过给window添加属性的方式来向外暴露接口。
可以将数据私有化,外部只能通过暴露出的方法进行操作。
但是当模块依赖其他模块时,模块间的依赖关系不明显。<script src="module.js"></script> <script> testModule.func1(); testModule.func2(); console.log(testModule.data); // undefined testModule.data = 'xxxx' //无法修改的模块内部的data testModule.func1(); // 没有改变 </script>(function(window) { const data = 'test'; function func1 () { console.log('func1:', data); } function func2 () { privateFun(); console.log('func2:', data); } function privateFun () { // 私有的内部函数 console.log('privateFun:', data); } window.testModule = { func1, func2 } })(window); -
IIFE模式增强
引入jQuery依赖,现代模块化的基石(function(window, $) { const data = 'test'; function func1 () { console.log('func1:', data); } function func2 () { privateFun(); console.log('func2:', data); } function privateFun () { // 私有的内部函数 console.log('privateFun:', data); } window.testModule = { func1, func2 } })(window, jQuery)<!-- 注意引入顺序,jQuery文件需要在模块文件之前 --> <script src="jquery-x.xx.x.js"></script> <script src="module.js"></script> <script> testModule.func1() </script>通过将其他模块(上述例子中的jQuery库)当做参数传入,这样技能保证模块独立性,也能将模块间的依赖关系明显的显示出来。
模块化优点
- 避免命名冲突(减少命名空间的污染)
- 更好的将功能进行分离,按需加载
- 高复用性
- 高可维护性
引入多个script标签后出现的问题
- 请求过多
依赖多个模块,就会发送多个请求,导致请求过多。 - 依赖模糊
不容易知道多个script标签具体依赖关系是什么,也就是说很容易因为不了解依赖关系导致加载先后顺序出错。 - 难以维护
上述两种原因就导致了很难维护,很可能出现牵一发而动全身的情况,导致项目出现严重的问题。
模块化固然有多个好处,然而一个页面需要引入多个js问题,就会出现以上这些问题。
而这些问题可以通过模块化规范来解决,下面介绍开发中最流行的commonjs,AMD,CMD,ES6规范。
Commonjs
概述
Node应用由模块组成,采用CommonJS模块规范。每个文件就是一个模块,有自己的作用域。在一个文件里边定义的变量、函数、类,都是私有的,对其他文件不可见。在服务器端,模块的加载时运行时同步加载的;在浏览器端,模块需要提前编译打包处理。
特点
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
基本语法
- 暴露模块:module.exports = value 或 exports.xxx = value。
- 引入模块:require(xxx),如果是第三方模块,xxx为模块名;如果时自定义模块,xxx为模块文件路径。
CommonJS暴露的模块到底是什么?
CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。
// example.js
const x = 5;
const addX = funciton (value) {
return value + x;
}
module.exports.x = x;
module.exports.addX = addX;
上面代码通过module.exports输出变量x和函数addX。
const example = require('./example.js');
console.log(example.x); // 5
console.log(example.addX(1)); // 6
require命令用于加载模块文件。require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
模块的加载机制
CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
这点与ES6模块化有重大差异。
// lib.js
let counter = 3;
function incCounter() {
counter ++;
}
module.exports = {
counter,
incCounter
}
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。
// main.js
const { counter, incCounter } = require('./lib');
console.log(counter); // 3
incCounter();
console.log(counter); // 3
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。
这是因为counter是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
服务器端实现
- 下载安装node.js
- 创建项目结构
注意:用npm init自动生成package.json时, package name(包名)不能有中文和大写
|-modules
|-module1.js
|-module2.js
|-module3.js
|-app.js
|-package.json
{
"name": "commonJS-node",
"version": "1.0.0"
}
- 下载第三方模块
npm install uniq --save // 用于数组去重 - 定义模块代码
// module1.js
module.exports = {
msg: 'module1',
foo() {
console.log(this.msg);
}
}
// module2.js
module.exports = funciton () {
console.log('module2');
}
// module3.js
exports.foo = funciton () {
console.log('foo module3');
}
exports.arr = [1, 2, 3];
// app.js文件
// 引入第三方库,应该放置在最前面
let uniq = require('uniq');
let module1 = require('./modules/module1');
let module2 = require('./modules/module2');
let module3 = require('./modules/module3');
module1.foo(); // module1
module2(); // module2
module3.foo(); // foo module3
console.log(module3.arr); // [1, 2, 3]
-
通过node运行app.js
命令行输入 node app.js,运行js文件 -
浏览器端实现(借助Browserify)
(1)创建项目结构|-js |-dist //打包生成文件的目录 |-src //源码所在的目录 |-module1.js |-module2.js |-module3.js |-app.js //应用主源文件 |-index.html //运行于浏览器上 |-package.json { "name": "browserify-test", "version": "1.0.0" }
(2)下载browserify
全局:npm install browserify -g
局部:npm install browserify -save-dev
(3)定义模块代码(同服务器端)
index.html文件要运行在浏览器上,需要借助browserify将app.js文件打包编译,如果直接在index.html引入app.js就会报错。
(4)打包处理js
根目录下运行browserify js/src/app.js -o js/dist/bundle.js
(5)页面引入
在index.html文件中引入<script type="text/javascript" src="js/dist/bundle.js"></script>
!! CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。
由于node主要用于服务器变成,模块文件一半都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。
但是如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。
AMD
AMD规范比CommonJS规范在浏览器端实现要更早,AMD规范是非同步加载模块,允许指定回调函数。
AMD规范基本语法
-
定义暴露模块
// 定义没有依赖的模块 define(funciton () { return 模块xx; });// 定义有依赖的模块 define(['module1', 'module2'], funciton (m1, m2) { return 模块xx; }); -
引入使用模块
require(['module1', 'module2'], function(m1, m2) { });
未使用AMD规范与使用require.js
通过比较两者的实现方法,来说明使用AMD的好处。
-
未使用AMD规范
// dataService.js文件 (function (window) { const msg = 'www.baidu.com'; function getMsg () { return msg.toUpperCase(); } window.dataService = { getMsg }; })(window);// alerter.js文件 (function (window, dataService) { const name = 'Tom'; function showMsg () { alert(dataService.getMsg() + ', ' + name); } window.alerter = { showMsg }; })(window, dataService);// main.js文件 (function (alerter) { alerter.showMsg(); })(alerter);<div><h1>Modular Demo 1: 未使用AMD(require.js)</h1></div> <script type="text/javascript" src="js/modules/dataService.js"></script> <script type="text/javascript" src="js/modules/alerter.js"></script> <script type="text/javascript" src="js/main.js"></script>
结果:
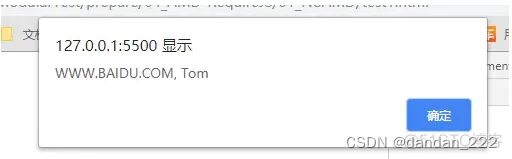
未使用AMD规范时,会发送多个请求,其次引入的js文件顺序不能搞错,否则会报错
- 使用AMD规范
requireJS是一个遵守AMD规范的工具库。
其基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载。
(1)下载require.js,并引入
官网:http://www.requirejs.cn/
github :https://github.com/requirejs/requirejs
(2)创建项目结构
|-js
|-libs
|-require.js
|-modules
|-alerter.js
|-dataService.js
|-main.js
|-index.html
(3)定义require.js的模块代码
// dataService.js文件
// 定义没有依赖的模块
define(funciton() {
const msg = 'www.baidu.com';
function getMsg () {
return msg.toUpperCase();
}
// 暴露模块
return { getMsg }
});
// alerter.js文件
define(['dataService'], function (window, dataService) {
const name = 'Tom';
function showMsg () {
alert(dataService.getMsg() + ', ' + name);
}
// 暴露模块
return { showMsg }
});
// main.js文件
(function() {
require.config({
baseUrl: 'js/', // 基本路径 出发点在根目录下
paths: {
// 映射: 模块标识名:路径
alerter: './modules/alerter', // 此处不能写成alerter.js,会报错
dataService: './modules/dataService'
}
});
require(['alerter'], function (alerter) {
alerter.showMsg();
});
})();
// index.html文件
<!DOCTYPE html>
<html>
<head>
<title>Modular Demo</title>
</head>
<body>
<!-- 引入require.js并指定js主文件的入口 -->
<script data-main="js/main" src="js/libs/requires.js"></script>
</body>
</html>
(4)页面引入require.js模块
在index.html引入<script data-main="js/main" src="js/libs/requires.js" ></script>
在项目中如何引入第三方库?
只需要在上面代码上的基础稍作修改:
// alerter.js文件
define(['dataService', 'jquery'], function(dataService, $) {
let name = 'Tom';
function showMsg() {
alert(dataService.getMsg() + ', ' + name)
}
$('body').css('background', 'green');
return { showMsg };
})
// main.js文件
(function() {
require.config({
baseUrl: 'js/', // 基本路径 出发点在根目录下
paths: {
// 映射: 模块标识名:路径
alerter: './modules/alerter', // 此处不能写成alerter.js,会报错
dataService: './modules/dataService',
jquery: './libs/jquery-1.10.1' //注意:写成jQuery会报错
}
});
require(['alerter'], function (alerter) {
alerter.showMsg();
});
})();
上述代码,是在alerter.js文件中引入jQuery第三方库,main.js文件也要有相应的路径配置。
通过两者的比较,可以得出AMD模块定义的方法非常清晰,不会污染全局环境,能够清楚地显示依赖关系。
AMD模式可以用于浏览器环境,并且允许非同步加载模块,也可以根据需要动态加载模块。
CMD
CMD规范专门用于浏览器端,模块的加载是异步的,模块使用时才会加载执行。
CMD规范整合了CommonJS和AMD规范的特点。
在Sea.js中,所有JavaScript模块都遵循CMD模块定义规范。
(1)CMD规范基本语法
定义暴露模块:
// 定义没有依赖的模块
define(funciton(require, exports, module) {
exports.xxx = value;
module.exports = value;
});
// 定义有依赖的模块
define(funciton(require, exports, module) {
// 引入依赖模块(同步)
const module2 = require('./module2');
// 引入依赖模块(异步)
require.async('./module3', function (m3) {});
// 暴露模块
exports.xxx = value;
});
引入使用模块:
define(funciton (require) {
const m1 = require('./module1');
const m4 = require('./module4');
m1.show();
m4.show();
});
(2)sea.js简单使用教程
-
下载sea.js,并引入
- 官网: seajs.org/
- github: github.com/seajs/seajs
然后将sea.js导入项目:js/libs/sea.js
-
创建项目结构
|-js |-libs |-sea.js |-modules |-module1.js |-module2.js |-module3.js |-module4.js |-main.js |-index.html -
定义sea.js的模块代码
// module1.js文件 define(funciton (require, exports, module) { // 内部变量数据 const data = 'aaa'; // 内部函数 function show() { console.log('module1 show()' + data); } // 向外暴露 exports.show = show; });// module2.js文件 define(funciton(require, exports, module) { module.exports = { msg: 'I Will Back' } });// module3.js define(function(require, exports, module) { const API_KEY = 'abc123'; exports.API_KEY = API_KEY; });// module4.js文件 define(function(require, exports, module) { // 引入依赖模块(同步) const module2 = require('./module2'); function show() { console.log('module4 show() ' + module2.msg); } });// main.js 文件 define(funciton (require) { const m1 = require('./module1'); const m4 = require('./module4'); m1.show(); m4.show(); }); -
在index.html中引入
<script type="text/javascript" src="js/libs/sea.js"></script> <script type="text/javascript"> seajs.use('./js/modules/main') </script>
结果:

ES6模块化
Es6模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。
CommonJS和AMD模块,都只能在运行时确定这些东西。比如,CommonJS模块就是对象,输入时必须查找对象属性。
(1)ES6模块化语法
export命令用于规定模块的对外接口,import命令用于输入其他模块提供功能。
// 定义模块math.js
let basicNum = 0;
const add = function (a, b) {
return a + b;
}
export { basicNum, add };
// 引用模块
import { basicNum, add } form './math';
function test(ele) {
ele.textContent = add(99 + basicNum);
}
使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
export default function () {
console.log('foo');
}
// import-default.js
import customName from './export-default';
customName(); // 'foo'
模块默认输出, 其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
(2)ES6模块与CommonJS模块的差异
- CommonJS模块输出的是一个值的拷贝,ES6模块输出的是值的引用。
- CommonJS模块时运行时加载,ES6模块是编译时输出接口。
第二个差异时因为CommonJS加载的时一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而ES6模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
重点解释第一个差异:
// lib.js
export let counter = 3;
export funciton incCounter() {
counter ++;
}
// main.js
import { counter, incCounter } from './lib';
console.log(counter); // 3
incCounter();
console.log(counter); // 4
ES6模块的运行机制与CommonJS不一样。
ES6模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
(3)ES6-Babel-Browserify使用教程
简单来说就一句话:使用Babel将ES6编译为ES5代码,使用Browserify编译打包js。
- 定义package.json文件
{
"name": "es6-babel-browserify",
"version": "1.0.0"
}
- 安装babel-cli,babel-preset-es2015和browserify
- npm install babel-cli browserify -g
- npm install babel-preset-es2015 --save-dev
- preset预设(将es6转换成es5的所有插件打包)
- 定义.babelrc文件
{
"presets": ["es2015"]
}
- 定义模块代码
// module1.js 文件
// 分别暴露
export function foo() {
console.log('foo() module1');
}
export function bar() {
console.log('bar() module1');
}
// module2.js 文件
// 统一暴露
function fun1() {
console.log('fun1() module2')
}
function fun2() {
console.log('fun2() module2')
}
export { fun1, fun2 }
// module3.js 文件
// 默认暴露 可以暴露任意数据类项,暴露什么数据,接收到就是什么数据
export default () => {
console.log('默认暴露')
}
// app.js 文件
import { foo, bar } from './module1';
import { fun1, fun2 } from './module2';
import module3 form './module3';
foo();
bar();
fun1();
fun2();
module3();
- 编译并在index.html中引入
- 使用Babel将ES6编译为ES5代码(但包含CommonJS语法):babel js/src -d js/lib
- 使用Browserify编译js:browserify js/lib/app.js -o js/lib/bundle.js
然后在index.html文件中引入<script type="text/javascript" src="js/lib/bundle.js"></script>
- 引入第三方库(jQuery为例)
首先安装依赖npm install jquery@1
然后在app.js文件中引入
// app.js文件
import { foo, bar } from 'module1';
import { fun1, fun2 } from 'module2';
import module3 from './module3';
import $ from 'jquery';
foo();
bar();
fun1();
fun2();
module3();
$('body').css('background', 'green');
总结
- CommonJS规范主要用于服务端变成,加载模块是同步的,这并不适合在浏览器环境,因为同步意味着阻塞加载,浏览器资源时异步加载的,因此有了AMD CMD解决方案。
- AMD规范在浏览器环境中异步加载模块,并且可以并行加载多个模块。不过,AMD规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD规范与AMD规范很相似,都用于浏览器变成,依赖就近,延迟执行,可以很容易在Node.js中运行。不过,依赖SPM打包,模块的加载逻辑偏重。
- ES6在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代CommonJS和AMD规范,成为浏览器和服务器通用的模块解决方案。
对象深度克隆的简单实现
// 浅拷贝方式 直接使用
let originObj1 = {a: 1, b: 3, c: 4};
let copyObj1 = originObj1;
originObj1.d = 4;
console.log('直接使用 = 是浅拷贝 拷贝是引用:', originObj1, '\n');
// 首层浅拷贝 数组(slice concat)和对象(... assign)自带的拷贝方法
// 即对目标对象的第一层进行深拷贝,然后后面是浅拷贝
let originArr1 = [1, [2, 2]];
let copyArr1 = originArr1.slice();
copyArr1[0] = 2;
copyArr1[1].push(2);
console.log('Js自带的slice concat ... assign都是首层浅拷贝', originArr1, '\n');
// 忽略undefined function 的深拷贝方法
let originObj2 = { a: 1, b: 2, show: () => {} };
let copyObj2 = JSON.parse(JSON.stringify(originObj2));
copyObj2.c = 3;
console.log('忽略undefined function的深拷贝方法\n', 'originObj2:', originObj2, '\ncopyObj2: ', copyObj2, '\n');
// 递归实现深拷贝
function deepClone(origin) {
const clone = origin instanceof 'array' ? [] : {};
if (typeof origin === 'object') {
for (let key in origin) {
if (origin.hasOwnProperty(key)) {
clone[key] = typeof origin[key] === 'object' ? deepClone(origin[key]) : origin[key];
}
}
}
return clone;
}
实现一个once函数,传入函数参数只执行一次
function once(func) {
let tag = true;
return function () {
if (tag) {
func.apply(null, arguments);
tag = false;
} else {
console.log('不执行');
}
}
}
function func() {
console.log('once');
}
let test = once(func);
test(); // once
test(); // 执行
test(); // 执行
将原生的ajax封装成promise
function ajax(method, url, data) {
// 不同浏览器创建的XMLHttpRequest对象的方法有差异
// IE浏览器使用ActiveObject
// 而其他浏览器使用名为XMLHttpRequest
const XHR = XMLHttpRequest ? new XMLHttpRequest() : new ActiveObject('Microsoft.XMLHTTP');
return new Promist((resolve, reject) => {
XHR.onreadystatechange = function () {
if (XHR.readyState === 4 && (XHR.state >= 200 && XHR.state < 300 || XHR.state === 304)) {
try {
const response = JSON.parse(XHR.responseText);
resolve(response);
} catch(e) {
reject(e);
}
} else {
reject(new Error('Request was unsuccessful:' + XHR.stateText));
}
}
// open() 规定请求的类型、URL以及是否异步处理请求
// send() 方法将请求送往服务器
if (method.toUpperCase === 'GET') {
const arr = [];
for (let key in data) {
arr.push(`${key}=${data[key]}`);
}
const getData = arr.join('&');
XHR.open('GET', url + '?' + getData, true);
} else if (method.toUpperCase === 'POST') {
XHR.open('POST', url, true);
XHR.responseType = 'json'; // 规定预期的服务器相应的数据类型
XHR.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded;charset=utf-8');
XHR.send(data);
}
});
}
js监听对象属性的改变
ES5: defineProperty()
假设对user对象的name属性进行监听,当设置name属性值时,会执行相应的函数
Object.defineProperty(obj, prop, option)
入参用法:
obj:代理对象;
prop:代理对象中的key;
option:配置对象,get、set都在其中配置;
// 对对象的某个属性进行监听
const obj = { name: 'so' }
Object.defineProperty(obj, 'name', {
enumerable: true,
configurable:true,
set: funtion(value) {
name = value;
console.log('set: name:' + value);
},
get: function() {
console.log('set: name:' + value);
}
});
obj.name = 'xx'; // set
对一个对象进行整体响应式监听:
// 监听对象
function observe(obj) {
Object.keys(obj).map(key => {
defineReactive(obj, key, obj[key]);
});
}
function defineReactive(obj, key, v) {
if (typeof(v) === 'object') {
observe(v);
}
// 重定义 get/set
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function () {
console.log('get: ' + v)
return v
},
// 重新设置值时,触发收集器的通知机制
set: function (newV) {
console.log('set: ' + newV)
v = newV
},
})
let data = {a: 1};
// 监视对象
observe(data)
data.a // get: 1
data.a = 2 // set: 2
ES6: Proxy
Proxy 对象用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等) — MDN
const obj = new Proxy(target, handler)
target:要使用 Proxy 包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理)
handler:一个通常以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理 obj 的行为
funtion handle() {
// 改写set方法,监听设置
set: funtion() {},
get: funtion() {}
}
let p = new Proxy({}, handle); // 第一个参数为监听的对象,第二个参数为改写的方法
举例:
const handler = {
get: function (target, name) {
return name in target ? target[name] : 'no prop!'
},
set: function (target, prop, value, receiver) {
target[prop] = value;
console.log('property set: ' + prop + ' = ' + value);
return true;
}
}
const user = new Proxy({}, handler)
user.name = 'sorryhc' // property set: name = sorryhc
console.log(user.name) // sorryhc
console.log(user.age) // no prop!
如何实现一个私有变量,用getName方法可以访问,不能直接访问
function Product() {
let name = 'Tom';
this.getName = function () {
return name;
}
}
const obj = new Product;
console.log(obj.name); // undefined
console.log(obj.getName()); // Tom
== 和===、以及Object.is的区别
console.log(1 == '1'); // true
console.log(null == undefined); // true;
console.log(true == 1); // true
console.log(1 === '1'); // false
console.log(NaN === NaN); // false
console.log(1 === '1'); // false
console.log(Object.is(+0, -0)); // false
console.log(Object.is(NaN, NaN)); // true
setTimeout、setInterval 和 requestAnimationFrame之间的区别
requestAnimationFrame,与setTimeout和setInterval不同,requestAnimationFrame不需要设置时间间隔,大多数电脑显示器的刷新频率是60Hz,大概相当于每秒钟重绘60次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率,用户体验也不会有所提升。因此,最平滑动画的最佳循环间隔是1000ms/s,约等于16.6ms。
RAF采用的是系统时间间隔,不会因为前面的任务影响RAF,但是如果前面的任务多的话,会影响setTimeout和setInterval真正运行的时间间隔。
特点:
- requestAnimationFrame会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率。
- 在隐藏或不可见的元素中,requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的CPU、GPU和内存使用量
- requestAnimationFrame是由浏览器专门为动画提供的API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了CPU开销
用setTimeout来实现setInterval
function mySetInterval(func, timeout) {
function setTime() {
setTimeout(setTime, timeout);
func();
}
setTimeout(setTime, timeout);
}
mySetInterval(() => {
console.log('my setInterval \n');
}, 1000);
js异步
回调函数
在最基本的层面上,JavaScript异步编程是使用回调实现的。回调就是函数,可以传给其他函数。而其他函数会在满足某个条件或发生某个(异步)事件时调用这个函数。
基于以下四个场景,进行回调函数的使用
- 定时器
// 回调函数
function checkForUpdate() {
console.log('checkForUpdate');
}
setTimeout(checkForUpdate, 60000);
- 事件
客户端JavaScript编程几乎全都是事件驱动的。也就是说,不是运行某些预定义的计算,而是等待用户做一些事,然后响应用户的动作。
事件驱动的JavaScript程序在特定上下文中为特定类型的事件注册回调函数,而浏览器在指定的事件发生时调用这些函数。这些回调函数焦作事件处理程序或者事件监听器,通过addEventListen()注册:
let okay = document.querySelector('#confirmUpadateDialog button.okay');
// 回调函数
function applyUpdate() {
console.log('click');
}
okay.addEventListen('click', applyUpdate);
- 网络事件
JavaScript编程中另一个常见的异步操作来源是网络请求。浏览器中运行的JavaScript可以通过类似下面的代码从Web服务器获取数据:
function versionCallback(err, version) {
if (err) {
console.log('Get version error', err);
return ;
}
console.log('version is ', version);
}
function getCurVersionNum(versionCallback) {
const request = new XMLHttpRequest();
request.open('GET', 'http: //www.example.com/version');
request.send();
request.onload = function() {
const { status, responseText, statusText } = request;
if (status === 200) {
versionCallback(null, parseFloat(responseText));
} else {
versionCallback(statusText);
}
}
request.onerror = request.ontimeout = function (e) {
versionCallback(e.type);
}
}
- Node中的回调与事件
Node.js服务器端JavaScript环境底层就是异步的,定义了很多使用回调和事件的API。
读文件
const fs = require('fs');
let options = {
// 默认选项
}
fs.readFile('config.json', 'utf-8', (err, text) => {
if (err) {
console.log('err: ', err);
} else {
Object.assign(options, JSON.parse(text));
}
startProgram(options);
});
function startProgram(options) {
console.log('StartProgram with options:', options);
}
http请求
const https = require('https');
function callback(err, info) {
if (err) {
console.log('Get info error', err);
return ;
}
console.log('info is ', info);
}
function getText(url, callback) {
const request = https.get(url);
request.on('response', response => {
const { httpStatus } = response;
httpStatus.setEncoding('utf-8');
let body = '';
response.on('data', chunk => body += chunk);
response.on('end', () => {
if (httpStatus === 200) {
callback(null, body);
} else {
callback(httpStatus, );
}
});
request.on('error', err => {
callback(err, );
});
});
}
Promise
ES6统一用法,并原生提供了Promise对象。所谓Promise,就是一个对象,用来传递异步操作的消息。它代表了某个未来才会直到结果的事件(通常是异步操作),并且这个事件提供统一的API,可供进一步处理。
有了Promise对象,就可以异步操作以同步操作的流程表达出来,避免了回调地狱的问题。
Promise对象特点:
-
对象的状态不受外界影响。
Promise对象代表一个异步操作,有3种状态:Pending(进行中)、Resolved(已完成,又称Fulfilled)、Rejected(已失败)。只有异步操作的结果可以决定当前是哪一种状态,任何其他操作无法改变这个状态。
-
一旦状态改变就不会再变,任何时候都可以得到这个结果。
Promise对象的状态改变只有两种可能:从Pending变为Resolved和从Pending变为Rejected。只要其中之一发生,状态就凝固了,不会再变,会一直保持这个结果。就算改变已经发生,再对Promise对象添加回调函数,也会立即得到这个结果。这个事件(Event)完全不同。事件的特点是,如果你错过了它,再去监听是得不到结果的。
Promise缺点
- 无法取消,一旦新建它就会立即执行,无法中途取消。
- 不设置回调函数,Promise内部抛出的错误不会反应到外部。
- 当处于Pending状态时,无法得知目前进展到哪一个阶段(刚开始还是即将完成)。
Promise使用
let promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */) {
resolve(value);
} else {
reject(error);
}
});
定时器
function timeout(ms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, ms, 'done');
});
}
timeout(200).then(value => {
console.log(value);
});
图片加载
function loadImageAsync(url) {
return new Promise((resolve, reject) => {
const image = new Image();
image.src = url;
image.onload = function() {
resolve(image);
}
image.onerror = function() {
reject(new Error(url));
}
});
}
ajax操作
const getJSON = function(url) {
return new Promise((resolve, reject) => {
const client = new XMLHttpRequest();
client.open('GET', url);
client.onreadystatechange = handler;
client.responseType = 'json';
client.setRequestHeader('Accept', 'application/json');
client.send();
function handler() {
if (this.readyState !== 4) {
return ;
}
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
}
});
}
getJSON('test.json').then(json => {
console.log('Content is: ', json);
}, error => {
console.error(error);
});
Generator函数与Promise结合
// 使用Generator函数管理流程,遇到异步操作时通常返回一个promise对象
function getFoo() {
return new Promise((resolve, reject) => {
resolve('foo');
});
}
const g = function * () {
try {
const foo = yield getFoo();
console.log(foo);
} catch (e) {
console.log(e);
}
}
function run(generator) {
const it = generator;
function go(result) {
if (result.done) {
return resolt.value;
}
return result.value.then(value => {
return go(it.next(value));
}, error => {
return go(it.throw(error));
});
}
go(it.next());
}
run(g);
Promise方法
- Promise.prototype.then()
Promise实例具有then方法。也就是说,then方法是定义在原型对象Promise.prototype上的。它的作用是为Promise实例添加状态改变时的回调函数。then方法的第一个参数时Resolved状态的回调函数,第二个参数(可选)是Rejected状态的回调函数。
then方法返回的是一个新的Promise实例(注意,不是原来那个Promise实例)。因此可以采用链式写法,即then方法后在调用另一个then(或其他)方法。
getJSON('/posts.json').then(json => {
return json.post;
}).then(post => {
// ...
});
链式调用中的then可以指定一组按照次序调用的回调函数。前一个回调函数有可能返回的还是一个Promise对象(即有异步操作),而后一个回调函数就会等待该Promise对象的状态发生变化,再被调用。
getJSON('1.json').then(post => {
return getJSON(post.commentURL);
}).then(comments => {
console.log('Resolved: ', comments);
}, err => {
console.log('Rejected: ', err);
});
- Promise.prototype.catch()
Promise.prototype.catch方法用于指定发生错误时的回调函数。
getJSON('posts.json').then(posts => {
// ...
}).catch(err => {
console.log('错误:', err);
});
getJSON方法返回一个Promise对象,如果该对象状态变为Resolved,则会调用then方法指定的回调函数;如果异步操作抛出错误,状态就会变为Rejected,就会调用catch方法指定的回调函数处理这个错误。
p.then(val => console.log('fulfilled: ', val))
.catch(err => console.log('错误:', err));
等同于:
p.then(val => console.log('fulfilled: ', val))
.then(null, err => console.log('rejected: ', err));
Promise抛出一个错误,就被catch方法指定的回调函数所捕获。
如果Promise状态已经变成Resolved,再抛出错误是无效的。
let promise = new Promise((resolve, reject) => {
resolve('ok');
});
promise
.then(value => console.log(value)) // ok
.catch(err => console.log(err))
Promise在resolve语句后面再抛出错误,并不会被捕获,等于没有抛出。
Promise对象的错误具有"冒泡"性质,会一直向后传递,直到被捕获为止。也就是说,错误总是会被下一个catch语句捕获。
getJSON('1.json').then(post => {
return getJSON(post.commentURL)
}).then(comments => {
// some code
}).catch(err => {
// 处理前面3个Promise产生的错误,前面三个promise任何一个抛出错误都会被捕获
});
一般来说,不要在then方法中定义Rejected状态的回调函数(即then的第二个参数),而应该总是使用catch方法。
// bad
promise
.then(data => {
// success
}, err => {
// error
});
// good
promise
.then(data => {
// success
})
.catch(err => {
// error
})
使用catch方法指定错误处理的回调函数,更接近同步的写法(try/catch)。跟传统try/catch代码块不同的是,如果没有使用catch方法指定错误处理的回调函数,Promise对象抛出的错误不会传递到外层代码,即不会有任何反应。
const someAsyncThing = function() {
return new Promise((resolve, reject) => {
// 下面一行会报错,因为x没有声明
resolve(x + 2);
});
}
someAsyncThing().then(() => {
console.log('everything is great);
});
// someAsyncThing函数产生的Promise对象会报错,但是由于没有指定catch方法,因而这个错误不会被捕获,也不会传递到外层代码,导致运行后没有任何输出。
const promise = new Promise((resolve, reject) => {
resolve('ok');
setTimeout(function() {
throw new Error('test');
}, 0);
});
promise
.then(value => console.log(value)) // ok
// Uncaught Error: test (无catch方法,抛出错误,就冒泡到最外层,成了未捕获的错误。因为此时Promise的函数体已经运行结束,所以这个错误是在Promise函数体外抛出的)
Node.js有一个unhandledRejection事件,专门监听未捕获的Rejected错误。
第一个参数是错误对象,第二个是报错的Promise实例,可用于了解发生错误的环境信息。
process.on('unhandledRejection', (err, p) => {
console.error(err.stack);
});
需要注意的是,catch方法返回的还是一个Promise对象,因此后面还可以接着调用then方法。
const someAsyncThing = function() {
return new Promise((resolve, reject) => {
// 下面一行会报错,因为x没有声明
resolve(x + 2);
});
}
// 代码运行完catch方法指定的回调函数,会接着运行后面那个then方法指定的回调函数。
// 如果没有报错,则会跳过catch方法
someAsyncThing()
.catch(error => {
console.log('error: ', error);
})
.then(() => {
console.log('carry on');
});
// error: x is not defined
// carry on
下面代码因为没有报错跳过了catch方法,直接执行了后面的then方法。此时要是then方法里面报错,就与前面的catch无关了。
Promise.resolve()
.catch(error => {
console.log('error: ', error);
})
.then(() => {
console.log('carry on');
});
// carry on
catch方法中还能再抛出错误。
下面代码中,catch方法抛出一个错误,因为后面没有别的catch方法,导致这个错误不会被捕获,也不会传递到外层。
const someAsyncThing = function() {
return new Promise((resolve, reject) => {
// 下面一行会报错,因为x没有声明
resolve(x + 2);
});
}
someAsyncThing()
.then(() => {
return someOtherAsyncThing();
})
.catch(error => {
console.log('error: ', error);
// 下面一行会报错,因为y没有声明
y + 2;
})
.then(() => {
console.log('carry on');
});
// error: x is not defined
改写后可以捕获: 第二个catch方法用来捕获前一个catch方法抛出错误
someAsyncThing()
.then(() => {
return someOtherAsyncThing();
})
.catch(error => {
console.log('error: ', error);
// 下面一行会报错,因为y没有声明
y + 2;
})
.catch(err => {
console.log('carry on', err);
});
// error: [ReferenceError: x is not defined]
// carry on [ReferenceError: y is not defined]
- Promise.all()
Promise.all方法用于将多个Promise实例包装成一个新的Promise实例。
const p = Promise.all([p1, p2, p3]);
Promise.all方法的参数不一定是数组,但是必须具有Iterator接口,且返回的每个成员都是Promise实例
p的状态由p1、p2、p3决定,分成两种情况。
(1)只有p1、p2、p3的状态都变成Fulfilled,p的状态才会变成Fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
(2)只要p1、p2、p3中有一个被Rejected,p的状态就变成Rejected,此时第一个被Rejected的实例的返回值会传递给p的回调函数。
const promises = [2, 3, 5, 7, 11, 13].map(id => getJSON(`/post/${id}.json`));
promise.all(promises).then(posts => {
// ...
})
.catch(reason => {
// ...
});
Promise.all()里面接口的执行顺序是按接口的并行执行来的,但是返回值依然是按照其接口的代码的先后顺序来的
-
Promise.race()
Promise.race方法同样是将多个Promise实例包装成一个新的Promise实例。
const p = Promise.all([p1, p2, p3]);
只要p1, p2, p3中有一个实例率先改变状态,p的状态就跟着改变。率先改变的Promise实例的返回值,就传递给p的回调函数。
Promise.race方法的参数与Promise.all方法一样,如果不是Promise实例,就会先调用下面的Promise.resolve方法,将参数转换为Promise实例,再进一步处理。
// 如果指定时间内没有获得结果,就将Promise的状态变为Rejected,否则变为Resolved
const p = Promise.race([
fetch('/resource-that-may-take-a-while'),
new Promise((resolve, reject) => {
setTimeout(() => reject(new Error('request timeout')), 5000)
})
]);
// 5秒内fetch方法无法返回结果,变量p的状态就会变成Rejected,从而触发catch方法指定的回调函数
p
.then(res => console.log(res))
.catch(error => console.log(error))
-
Promise.resolve()
有时需要将现有对象转为Promise对象,Promise.resolve()方法就起到这个作用。
// 下面代码将JQuery生成的deferred对象转换为新的Promise对象
const jsPromise = Promise.resolve($.ajax('/whatever.json'));
Promise.resolve的等价写法:
Promise.resolve('foo)
// 等价于
new Promise(resolve => resolve('foo'))
如果Promise.resolve方法的参数不是具有then方法的对象(又称thenable对象),则返回一个新的Promise对象,且其状态为Resolved。
const p = Promise.resolve('Hello');
p.then(s => console.log(s)) // 'Hello'
// 字符串Hello不属于异步操作(判断方法时它不是具有then方法的对象),返回Promise实例的状态从已生成就是Resolved,所以回调函数会立即执行,Promise.resolve方法的参数会同时传给回调函数。
Promise.resolve方法运行调用时不带参数。所以,如果希望得到一个Promise对象,比较方便的方法就是直接调用Promise.resolve方法。
const p = Promise.resolve(); // 是一个Promise对象
p.then(() => {
// ...
});
如果Promise.resolve方法的参数是一个Promise实例,则会被原封不动地返回。
-
Promise.reject()
Promise.reject(reason)方法也会返回一个新的Promise实例,状态为Rejected。Promise.reject方法的参数reason会被传递给实例的回调函数。
下面代码生成一个Promise对象的实例p,状态为Rejected,回调函数会立即执行。
const p = Promise.reject('error');
// 等同于
new Promise((resolve, reject) => reject('error'))
p.then(null, error => console.log(error)) // 'error'
-
其他方法
不在ES6中,但是有用的方法:
(1)done()
Promise对象的回调链,不管以then方法还是catch方法结尾,要是最后一个方法抛出错误,都有可能无法捕捉到(因为Promise内部的错误不会冒泡到全局)。为此可以提供一个done方法,总是处于回调链的末尾,保证捕获抛出的任何错误。Promise.prototype.done = function (onFulfilled, onRejected) { this.then(onFulfilled, onRejected) .catch(reason => { // 抛出一个全局错误 setTimeout(() => { throw reason }, 0); }) } asyncFunc() .then(f1) .catch(r1) .then(f2) .done();(2)finally()
finally方法用于指定不管Promise对象最后状态如何都会执行的操作。它与done方法最大的区别在于,它接受一个普通的回调函数作为参数,该函数不管怎么样都必须执行。
Promise.prototype.finally = callback => { let P = this.constructor; return this.then( value => P.resolve(callback()).then(() => value), reason => P.resolve(callback()).then(() => throw reason) ) } server.listen(0) .then(() => { }) .finally()
简单实现一个Promise
const PENDING = "pending";
const FULFILLED = "fulfilled";
const REJECTED = "rejected";
function NPromise(executor) {
this.status = PENDING; // 定义状态
this.value = null;
this.reason = null;
executor(this.resolver.bind(this), this.rejecter.bind(this));
}
NPromise.prototype.resolver = function(value) {
if (this.status === PENDING) {
this.status === FULFILLED;
this.value = value;
}
}
NPromise.prototype.rejecter = function(reason) {
if (this.status === PENDING) {
this.status === REJECTED;
this.reason = reason;
}
}
NPromise.prototype.then = function(onFufilled, onRejected) {
//成功状态
if(this.state === 'fulfilled') {
onFufilled(this.value);
}
//失败状态
if(this.state === 'rejected') {
onRejected(this.reason);
}
return new NPromise(function(this.resolver.bind(this), this.rejecter.bind(this)) {});
}
NPromise.prototype.all = function(promises) {
let result = {};
const PROMISELEN = promises.length;
return new NPromise(resolve => {
promises.forEach((promise, index) => {
promise.then(value => {
result[index] = value;
if(Object.keys(result).length === PROMISELEN) {
resolve(Array.from(result));
}
}, err => {
reject(err);
})
});
}
Generator
Generator函数是协程在ES6中的实现,最大特点就是可以交出函数的执行权(即暂停执行)。整个Generator函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用yield语句注明。
function* gen(x) {
yield 1
console.log('A')
yield 2
console.log('B')
yield 3
console.log('C')
return 4;
}
// 定义迭代器对象
const g = gen();
g.next() // 执行 gen 函数,打印为空,遇到 yield 1 停止执行
g.next() // 继续执行函数,打印 A,遇到 yield 2 停止执行
g.next() // 继续执行函数,打印 B,遇到 yield 3 停止执行
g.next() // 继续执行函数,打印 C
调用Generator函数会返回一个内部指针(即遍历器)g。这是Generator函数不同普通函数的另一个地方,即执行它不会返回结果,返回的指针对象。调用指针g的next方法,会移动内部指针(即执行异步任务的第一段),指向第一个遇到yield语句。
在调用 generator 函数时,它只是进行实例化工作,它没有让函数体里面的代码执行,需要通过 next 方法来让它执行。当 next 方法执行时遇到了 yield 就会停止,直到再次调用 next 方法。
next方法返回值的value属性,是Generator函数向外输出数据;next方法还可以接受参数,这是向Generator函数体内输入数据。
function * gen() {
let y = yield x + 2;
return y;
}
const g = gen(1);
g.next(); // { value: 3, done: false }
g.next(2) // { value: 2, done: true }
Generator函数内部还可以部署错误处理代码,捕获函数体外抛出的错误。
通过throw方法抛出错误,意味着,出错的代码和处理错误的代码实现了时间和空间上的分离,这对于异步编程无疑是很重要的。
function* gen(x) {
try {
let y = yield x + 2;
} catch(e) {
console.log(e);
}
return y;
}
let g = gen(1);
g.next();
g.throw('error'); // Generator函数体外使用指针对象的throw方法抛出的错误,可以被函数体的try...catch代码块捕获。
异步任务的封装
let fetch = require('node-fetch');
function* gen() {
const url = 'https: //api.github.com/users/github;
const result = yield fetch(url);
console.log(result.bio);
}
let g = gen();
let result = g.next(); // 执行fetch,返回的是一个Promise对象,因此要用then方法调用下一个next方法
result.value
.then(data => data.json())
.then(data => g.next(data));
Generator函数的自动流程管理-Thunk函数
const fs = require('fs');
const thunkify = require('thunkify');
const readFile = thunkify(fs.readFile);
let gen = function* () {
let f1 = yield readFile('/etc/1');
let f2 = yield readFile('/etc/2');
console.log(f1.toString());
console.log(f2.toString());
}
function run(fn) {
let gen = fn();
// next函数时Thunk的回调函数
function next(err, data) {
let result = gen.next(data);
if (result.done) {
return;
}
result.value(next);
}
next();
}
run(gen);
自动指定的关键是,必须有一种机制自动控制Generator函数的流程,接收和交还程序的执行权。回调函数可以做到这一点,Promise对象也可以做到这一点。
co模块
co模块时著名程序员TJ Holowaychuk于2013年6月发布的一个小工具,用于Generator函数的自动执行。
例:Generator函数读取两个文件
const readFile = function(fileName) {
return new Promise((resolve, reject) => {
fs.readFile(fileName, (err, data) => {
if (err) {
reject(err);
}
resolve(data);
});
});
}
let gen = function* () {
let f1 = yield readFile('/etc/1');
let f2 = yield readFile('/etc/2');
console.log(f1.toString());
console.log(f2.toString());
}
co模块可以不用编写Generator函数的执行器。
const co = require('co');
// co(gen); // 返回一个Promise对象,因此可以用then方法添加回调函数
co(gen).then(() => {
console.log('Generator函数执行完成');
});
co模块的原理
Generator就是一个异步操作的容器。它的自动执行需要一种机制,当异步操作有了结果能够自动交回执行权。
有两种方法可以做到这一点:
- 回调函数。将异步操作包装成Thunk函数,在回调函数中交回执行权。
- Promise对象。将异步操作包装成Promise对象,用then方法交回执行权。
基于Promise对象的自动执行
let fs = require('fs');
let readFile = function(fileName) {
return new Promise((resolve, reject) => {
fs.readFile(fileName, (err, data) => {
if (err) {
reject(err);
}
resolve(data);
});
});
}
let gen = function* () {
let f1 = yield readFile('/etc/1');
let f2 = yield readFile('/etc/2');
console.log(f1.toString());
console.log(f2.toString());
}
// 手动执行,其实就是用then方法层层添加回调函数。
let g = gen();
g.next().value.then(data => {
g.next(data).value.then(data => {
g.next(data);
});
});
// 自动执行
function run(gen) {
let g = gen();
function next(data) {
let result = g.next(data);
if (result.done) {
return result.value;
}
result.value.then(data => {
next(data);
});
}
next();
}
run(gen);
co模块的源码
co就是上面那个自动执行器的扩展,它的源码只有几十行,非常简单。
首先,co函数接受Generator函数作为参数,返回一个Promise对象。
function co(gen) {
let ctx = this;
return new Promise((resolve, reject) => {
});
}
co将Generator函数的内部指针对象的next方法包装成onFulfilled函数。这主要是为了能够捕捉抛出的错误。
function co(gen) {
let ctx = this;
return new Promise((resolve, reject) => {
if (typeof gen === 'function') {
gen = gen.call(ctx);
}
if (!gen || typeof gen.next !== 'function') {
return resolve(gen);
}
function onFulfilled(res) {
let ret;
try {
ret = gen.next(res);
} catch(e) {
return reject(e);
}
next(ret);
}
function next(ret) {
if (ret.done) {
return resolve(ret.value);
}
let value = toPromise.call(ctx, ret.value);
if (value && isPromise(value)) {
return value.then(onFulfilled, onRejected);
}
return onRejected(new Error('xxx'));
}
onFulfilled();
});
}
处理并发的异步操作
// 数组写法
co(function* () {
let res = yield[
Promise.resolve(1),
Promise.resolve(2)
];
console.log(res);
}).catch(onerror);
// 对象写法
co(function* () {
let res = yield{
1: Promise.resolve(1),
2: Promise.resolve(2)
}
console.log(res);
}).catch(onerror);
// 其他
co(function* () {
let values = [n1, n2, n3];
yield values.map(somethingAsync);
});
function somethingAsync(x) {
// do something
return ...
}
async/await(ing)
ES7提供了async函数,使得异步操作变得更加方便。
async函数就是Generator函数的语法糖
const fs = require('fs');
const readFile = function(fileName) {
return new Promise((resolve, reject) => {
fs.readFile(fileName, (err, data) => {
if (err) {
reject(err);
}
resolve(data);
});
});
}
// generator
function* gen() {
let f1 = yield readFile('/test/111');
let f2 = yield readFile('/test/112');
console.log(f1.toString());
console.log(f2.toString());
}
// async/await
const asyncReadFile = async function() {
let f1 = await readFile('/test/111');
let f2 = await readFile('/test/112');
console.log(f1.toString());
console.log(f2.toString());
}
对比之下,可以发现,async函数就是将Generator函数的星号替换成async,将yield替换成await。
async函数对Generator函数的改进:
- 内置执行器
Generator函数的执行必须靠执行器,所以才有了co模块,而async函数自带执行器。也就是说,async函数的执行与普通函数一模一样,只要一行。 - 自动执行
上述代码中调用了asyncReadFile函数,然后它就会自动执行,输出最后结果。完全不像Generator函数,需要调用next方法,或者用co模块,才能得到真正执行,从而得到最终结果。 - 更好的语义
async和await比起星号和yield,语义更清楚。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。 - 更广的适用性
co模块约定,yield命令后面只能时Thunk函数或Promise对象,而async函数的await命令后面可以是Promise对象和原始类型的值(数值、字符串和布尔值,但这时等同于同步操作)。 - 返回值是Promise
async函数的返回值时Promise对象,这比Generator函数的返回值是Iterator对象方便多了,可以用then方法指定下一步的操作。
async函数的实现
async函数的实现就是将Generator函数和自动执行器包装在一个函数中。
async function fn(args) {
// ...
}
// 等同于
function fn(args) {
return spawn(function* () {
// ...
});
}
实现一个bind函数
if (!Function.prototype.bind) {
Function.prototype.bind = function() {
let self = this;
let context = [].shift().call(arguments);
let args = [].slice().call(arguments);
return funciton() {
// 将bind的其余参数 和 调用bind后返回的函数在执行的过程中接收的参数进行拼接,作为一个数组传入apply的第二个阐述中区
self.apply(context, [].concat.call(args, [].slice.call(arguments)));
}
}
}
类的创建和继承(待整理)
js控制一次加载一张图片,加载完后再加载下一张
<div id="pic1">onloading...</div>
const imgList = [];
const srcList = ['./img/account.png', './img/logo.png'];
srcList.forEach((src, index) => {
imgList[index] = new Image();
imgList[index].src = src;
});
console.log(imgList);
imgList.forEach(img => {
img.onload = function () {
alert(`Width: ${this.width}, Height: ${this.height}`);
document.getElementById('pic1').innerHTML = `<img src="${this.src}" />;
}
});
如何实现sleep的效果
// while
function sleep1(delayms) {
const expire = Date.now() + delayms;
while(Date.now() < expire);
console.log('sleep1完成!');
return ;
}
sleep1(500);
// promise
function sleep2(delayms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, delayms);
});
}
sleep2(1000).then(() => {
console.log('sleep2完成!');
});
// async await
function sleep3(delayms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, delayms);
});
}
async function test() {
let temple = await sleep3(1000);
console.log('sleep3完成!');
return temple;
}
test();
// generator函数
function sleep(ms) {
yield new Promise(funciton(resolve, reject) {
setTimeout(resolve, ms);
});
}
sleep(1000).next().value.then(function() {
console.log('sleep4完成!');
});
获取对象原型的方法
console.log(Object.getPropertyOf(Function)); // Function
console.log(Function.__proto__); // Function
console.log(Function.prototype); // Function
this指向
-
普通函数调用(默认绑定,全局环境)
普通函数 this 指向window,因为一般情况下普通函数的调用者都是window。
function fn() { console.log('this: ', this); } fn(); // === window.fn(),指向window -
对象函数调用(隐式绑定,上下文对象)
对象的方法 this指向的是对象。
const obj = { fn: function() { console.log('this: ', this); // this指向是obj } } obj.fn(); -
构造函数调用(new绑定)
构造函数 this 指向实例对象,原型对象里面的this 指向的也是实例对象。
let that; function Person(name, age) { this.name = name; this.age = age; that = this; } Person.prototype.sing = function() { console.log('sing'); } const person = new Person('Tom', 22); console.log(that === person); // true -
定时器函数调用与立即执行函数调用
定时器函数和立即执行函数的this指向都是window
setTimeout(function() { console.log('定时器的this:' + this); }, 1000); // 6. 立即执行函数 this还是指向window (function() { console.log('立即执行函数的this' + this); })(); -
箭头函数的调用
箭头函数不绑定this即箭头函数没有自己的this,如果在箭头函数中使用this,this关键字将指向箭头函数中定义位置中的this(外层的this)。
function foo() { console.log(this); // { name: 'Tom', age: 22 } let _this = this; return () => { console.log(this === _this); // true; } } const obj = { name: 'Tom', age: 22 } const foofn = foo.call(obj) foofn(); -
call、apply、bind(显式绑定)
上述三个方法都可以改变this指向
let obj = { name: 'Tom', age: 22 } function fn(a) { console.log(this); console.log(a); } fn.call(obj, 3); // this: obj, 3 fn.apply(obj, [1, 2]); // this: obj, [1, 2] let newFn = fn.bind(obj, 3); newFn(); // this: obj, 3 -
数组调用
array.forEach(function(curValue, index, arr), thisValue)
thisValue,可选,传递给函数的值一般用this值。如果参数为空,undefined会传递给this值(会输出全局对象)。
除了forEach方法,需要传入this指向的函数还有:every、find、findIndex、map、some
简单实现Node的Events模块
// Events模块的简单使用
const events = require('events');
const EventEmitter = new events.EventEmitter();
EventEmitter.on('SAY', function(params) {
console.log('Hi', params);
});
EventEmitter.emit('SAY', 'Yang');
class EventEmitter {
constructor() {
this.eventHandles = {}; // 保存事件监听函数
}
// 为指定事件添加一个监听器
on(eventType, func) {
if (this.eventHandles[eventType]) {
this.eventHandles[eventType].push(func);
} else {
this.eventHandles[eventType] = [func];
}
}
// 触发事件,执行事件回调函数
emit(eventType, ...rest) {
if (this.eventHandles[eventType]) {
this.eventHandles[eventType].forEach(func => {
// rest 是一个参数数组, 所以这里要使用apply函数来执行func
func.apply(this, rest);
});
}
}
// 从名为eventType的事件监听器数组中溢出指定的func
off(eventType, func) {
if (this.eventHandles[eventType]) {
this.eventHandles[eventType] = this.eventHandles[eventType].filter(f => f !== func);
}
}
// 移除指定事件 eventType的所有监听器
removeAllListers(eventType) {
if (this.eventHandles[eventType]) {
delete this.eventHandles[eventType];
}
}
// 添加单次func到指定的事件监听器
once(eventType, func) {
let reFunc = (...rest) => {
func.apply(this, res);
this.off(eventType, reFunc);
}
this.on(eventType, reFunc);
}
// 返回名为eventType的事件监听器数组副本
listener (eventType) {
return this.eventHandles[eventType];
}
}
js判断类型(待整理)
不同数据类型的值的比较,如何转换,有什么规则(待整理)
数组常用方法(后整理)
- 改变原数组的方法
fill、pop、push、shift、unshift、splice、sort、reverse - 不改变原数组的方法
concat、every、some、filter、find、findIndex、forEach、indexOf、join、lastIndexOf、map、reduce、reduceRight、slice
如何判断一个数组
- Object.prototype.toString.call()做判断
const arr = [1, 2];
Object.prototype.toString.call(arr).slice(8, -1) === 'Array'; // true是Array
- 通过原型链做判断
arr.__proto__ === Array.prototype; // true是Array
- 通过ES6 Array.isArray() 方法
Array.isArray(arr); // true是Array
- 通过instanceof
arr instanceof Array; // true是Array
- 通过Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(arr); // true是Array
js实现跨域
CORS
跨域资源共享(CORS)是一种机制,它使用额外的HTTP头来告诉浏览器,让运行在一个origin(domain)上的Web应用被准许访问来自不同源服务器上的指定的资源。
当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域HTTP请求。
CORS需要浏览器和服务器同时支持,整个CORS过程都是浏览器完成的,无需用户参与。因此实现CORS的关键就是服务器,只要服务器实现了CORS请求,就可以跨源通信。
浏览器将CORS分为简单请求和非简单请求:
简单请求
简单请求不会触发CORS预检请求。如果满足下述两个条件,就可以看作是简单请求:
1. 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
2. HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
简单请求过程
对于简单请求,浏览器会直接发出CORS请求,它会在请求头信息中增加一个Orign字段,该字段用来说明本次请求来自哪个源(协议+端口+域名),服务器会根据这个值来决定是否同意这次请求。如果Orign指定的域名在许可范围之内,服务器返回的响应头会多出以下信息:
Access-Control-Allow-Origin: http: //xxx // 与origin一致
Access-Control-Allow-Credentials: true // 是否允许发送cookie
Access-Control-Expose-Headers: xxx // 指定返回其他字段的值
Content-Type: text/html; charset=utf-8 // 文档类型
如果Origin指定的域名不在许可范围内,服务器会返回一个正常的HTTP响应,但是没有Access-Control-Allow-Origin头部信息,这样浏览器就可以知道出错了。这个错误无法通过状态码识别,可能返回的状态码可能是200。
简单请求中,服务器内,至少需要设置Access-Control-Allow-Origin字段。
非简单请求
非简单请求,是对服务器有特殊邀请的请求,例如请求方法为DELETE、PUT等。
非简单请求的CORS请求会在正式通信之前进行一次HTTP查询请求,称为预检请求。该请求用于浏览器询问服务器,当前所在网页是否在服务器允许访问的范围内,以及可以使用的HTTP请求方式和头信息字段。只有当浏览器得到肯定的恢复,才会进行正式的HTTP请求,否则报错。
预检请求使用OPTIONS方法,表示这个请求是来询问的。
头信息的关键字段是Origin,表示请求来自哪个源,除此之外,头信息中还包括两个字段:
- Access-Control-Request-Method
该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法。 - Access-Control-Request-Headers
该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段。
服务器在收到浏览器的预检请求,会根据头信息的三个字段来进行判断,如果返回的头信息在中有Access-Control-Allow-Origin这个字段就是允许跨域请求,如果没有,就是不同意这个预检请求,会报错。
服务器回应的CORS的字段如下:
Access-Control-Allow-Origin: http://xxx // 允许跨域的源地址
Access-Control-Allow-Methods: GET, POST, PUT // 服务器支持的所有跨域请求的方法
Access-Control-Allow-Headers: X-Custom-Header // 服务器支持的所有头信息字段
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Max-Age: 1728000 // 用来指定本次预检请求的有效期
只要服务器通过了预检请求,在以后每次CORS请求都会自带一个Origin头信息字段。服务器的回应,也都会有一个Access-Control-Allow-Origin头信息字段。
在非简单请求中,至少需要设置以下字段:
'Access-Control-Allow-Origin'
'Access-Control-Allow-Methods'
'Access-Control-Allow-Headers'
如何减少OPTIONS请求次数:
OPTIONS请求次数过多就会损耗页面加载的性能,降低用户体验服。所以尽量要减少OPTIONS请求的次数,可以在服务端返回请求时在返回头部添加:Access-Control-Max-Age: number。它表示预检请求的返回结果可以被缓存多久,单位是秒。该字段只对完全一样的URL的缓存设置生效,所以设置了缓存时间,在这个时间范围内,再次发送请求,就不需要再进行预检请求了。
CORS中Cookie相关问题:
在CORS请求中,如果想要传递Cookie,需要满足以下三个条件:
-
Access-Control-Allow-Credentials设置为true
-
Access-Control-Allow-Origin 设置为非*的具体源地址
-
在请求中设置withCredentials
默认情况下跨域请求,浏览器发送的请求是不携带cookie的。但是可以通过设置withCredentials来传递cookie。// 原生xml const xhr = new XMLHttpRequest(); xhr.withCredentials = true; // axios axios.defaults.withCredentials = true;
JSONP
原理时利用script标签没有跨域限制,通过script标签src属性,发送带有callback参数的GET请求,服务端接口返回数据拼凑到callback函数中,返回给浏览器,浏览器解析执行,从而前端在callback函数拿到返回的数据。
JSONP的缺点:
- 仅支持get方法
- 不安全,可能会遭受XSS攻击
原生JS实现
<script>
const script = document.createElement('script');
script.type = 'text/javascript';
script.src = 'http://www.domain.com:8080/login?user=admin&callback=jsonpCallback'; // callback对应回调函数名(jsonpCallback),方便后端返回时执行这个前端定义的回调函数
// 回调函数
function jsonpCallback(res) {
console.log(JSON.stringify(res));
}
</script>
服务端返回:
jsonpCallback({"success": true, "user": "admin"});
Vue axios实现
this.$http = axios;
this.$http.jsonp('http://www.domain.com:8080/login', {
params: {},
jsonp: 'jsonpCallback'
}).then(res => {
console.log(res);
});
后端node代码
const querystring = require('querystring');
const http = require('http');
const server = http.createServer();
server.on('request', (req, res) => {
const params = querystring.parse(req.url.split('?')[1]);
const fn = params.callback;
// jsonp返回设置
res.writeHead(200, {'Content-Type': 'text/javascript'});
res.write(fn + `(${JSON.stringify(params)})`);
res.end();
});
server.listen('8080');
console.log('server is running at port 8080...');
postMessage
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一。
可以解决下面问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的iframe消息传递
- 上面三个场景的跨域的数据传递
用法:
postMessage(data, origin)方法接受两个参数
data: html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()方法进行序列化
origin: 协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源,设置为"/"。
- a.html: (domin.com/a.html)
<iframe id="iframe" src="/b.html" style="display: none" ></iframe>
<script>
const iframe = document.getElementById('iframe');
iframe.onload = function() {
const data = {
name: 'Tom'
}
// 向domain传送跨域数据
iframe.contentWindow.postMessage(JSON.stringify(data), '/');
}
// 接受domain返回数据
window.addEventListener('message', e => {
console.log('data from domain' + e.data);
}, false);
</script>
- b.html: (domain.com/b.html)
<script>
window.addEventListener('message', e => {
const data = JSON.parse(e.data);
if (data) {
data.number = 16;
// 返回数据
window.parent.postMessage(JOSN.stringify(data), '/');
}
}, false);
</script>
nginx代理
本质与CORS跨域原理一样,通过配置文件设置请求响应头Access-Control-Allow-Origin等字段。
-
nginx配置解决iconfont跨域
浏览器跨域访问js、css、img等常规静态资源是同源策略许可的,但iconfont字体文件例外,可以在nginx的静态在资源服务器中加入以下配置:
location / { add_header Access-Control-Allow-Origin *; } -
nginx反向代理接口跨域
跨域问题:同源策略仅是针对浏览器的安全策略。服务端调用HTTP接口,只是使用HTTP协议,不需要同源策略,也就不存在跨域问题。
思路:通过Nginx配置一个代理服务器域名(与domain相同,端口不同)作为跳板机,反向代理访问domain接口,并且可以顺便修改cookie中的domain信息,方便当前域cookie写入,实现跨域访问。
#proxy服务器配置 server { listen 81; server_name www.domain.com; location / { proxy_pass http://www.domain.com:8080; #反向代理 proxy_cookie_domain www.domain.com www.domain1.com; # 修改cookie里域名 index index.html index.htm; # 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用 add_header Access-Control-Allow-Origin http://www.domain1.com; # 当前端只跨域不带cookie时,可为* add_header Access-Control-Allow-Credentials true; } }
nodejs中间件代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启用一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证。
使用node + express +http-proxy-middleware搭建一个proxy服务器
前端代码
const xhr = new XMLHttpRequest();
// 前端开关: 浏览器是否读取cookie
xhr.withCredentials = true;
// 访问http-proxy-middleware代理服务器
xhr.open('get', 'http://www.domain1.com/3000/login?user=admin', true);
xhr.send();
中间件服务器代码
const express = require('express');
const proxy = require('http-proxy-middleware');
const app = express();
app.use('/', proxy({
// 代理跨域目标接口
target: 'http://www.domain.com:8080',
changeOrigin: true,
// 修改响应头信息,实现跨域并允许带cookie
onProxyRes: function(proxyRes, req, res) {
res.header('Access-Control-Allow-Origin', 'http:// www.domain1.com');roxyRes: function(proxyRes, req, res) {
res.header('Access-Control-Allow-Credentials', 'true');
},
// 修改响应信息中的cookie域名
cookieDomainRewrite: 'www.domain1.com' // false表示不修改
}));
app.listen(3000);
console.log('Proxy server is listen at port 3000...');
document.domain + iframe跨域
该方案仅限于主域相同,子域不同的跨域应用场景。
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
-
父窗口(domain.com/a.html)
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe> <script> document.domain = 'domain.com'; let a = 'a'; </script> -
子窗口(child.comain.com/a.html)
<script> document.domain = 'domain.com'; // 获取父窗口中的数据 console.log('get js data from parent --->' + window.parent.a); </script>
location.hash + iframe跨域
原理:
通过中间页c来实现a与b的跨域通信。
三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信
实现:
A域:a.html -> B域:b.html -> A域:c.html
a.html与b.html 不同域,只能通过hash值单向通信,同理c.html与b.html也不同域也只能单向通信,但是a.html与c.html同域,所以c.html可以通过window.parent.parent访问a.html所有对象。
a.html: domain1.com/a.html
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display: none;"></iframe>
<script>
const iframe = document.getElementById('iframe');
// 向b.html传hash值
setTimeout(funciton() {
iframe.src = iframe.src + '#user=admin';
}, 1000);
// 开放给同方法域c.html的回调方法
function onCallback(res) {
console.log('data from c.html -->', res);
}
</script>
b.html: domain2.com/b.html
<iframe id="iframe" src="http://www.domain1.com/c.html" style="display: none;" ></iframe>
<script>
const iframe = document.getElementById('iframe');
// 监听a.html传来的hash值,再传给c.html
window.onhashchange = function() {
iframe.src = iframe.src + location.hash;
}
</script>
c.html: domain1.com/c.html
<script>
// 监听b.html传来的hash值
window.onhashchange = function() {
// 通过操作同域a.html的js回调,将结果传回
window.parent.parent.onCallback('hello:' + location.hash.replace('#user=', ''));
}
</script>
window.name + iframe跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的name值(2MB)。
a.html:(domian1.com/a.html)
const proxy = function(url, callback) {
let state = 0;
const iframe = document.createElement('iframe');
// 加载跨域页面
iframe.src = url;
// onload事件会触发2次,第1次加载跨域页,并留存数据于window.name
iframe.onload = function() {
if (state === 1) {
// 第2次onload(同域proxy页)成功后,读取同域window.name中的数据
callback(iframe.contentWindow.name);
destoryFrame();
} else if (state === 0) {
// 第一次onload(跨域页)成功后,切换到同域代理页面
iframe.contentWindow.location = 'http://www.domain1.com/proxy.html';
state = 1;
}
}
document.body.appendChild(iframe);
// 获取数据后销毁iframe,释放内存;确保数据不会被其他域的iframe js访问
function destoryFrame() {
iframe.contentWindow.write('');
iframe.contentWindow.close();
document.body.removeChild(iframe);
}
}
proxy('http://domian2.com/b.html', data => {
console.log(data);
});
proxy.html:(domian1.com/proxy.html)
中间代理页,与a.html同域,内容为空即可
b.html:(domian2.com/b.html)
<script>
window.name = 'b.html data';
</script>
通过iframe的src属性由外域转向本地域,跨域数据由iframe的window.name从外域传递到本地域。这样就可以绕过浏览器的跨域访问限制,但是又是安全操作。
WebSocket协议跨域
WebSocket协议跨域,WebSocket protocol是一种HTML5新的协议。
它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术很好的实现。
原声WebSocket API使用不方便,可以使用Socket.io,它很好地封装了WebSocket接口,提供了更简单、灵活的接口,也对不支持WebSocket的浏览器提供了向下兼容。
前端代码
<div>
name: <input text="text" />
</div>
<script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.js" />
<script>
const socket = io('http://www.domain2.com:8080');
socket.on('connect', function() {
// 监听服务端消息
socket.on('message', function(msg) {
console.log('data from server:', msg);
});
//监听服务端关闭
socket.on('disconnet', function() {
console.log('Server socket has closed.');
});
});
document.getElementsByTagName('input')[0].onblur = function() {
socket.send(this.value);
}
</script>
Nodejs
const http = require('http');
const socket = require('socket.io');
// 启动http服务
const server = http.createServer(function(req, res) {
res.writeHead(200, {
'Content-type': 'text/html'
});
res.end();
});
server.listener('8080');
console.log('Server is running at port 8080...');
// 监听socket连接
socket.listen(server).on('connection', function(client) {
// 接收信息
client.on('message', function(msg) {
client.send('hello: ' + msg);
console.log('data from client: --->' + msg);
});
// 断开处理
client.on('disconnect', function() {
console.log('Client socket has closed.');
});
});
Content-Type的值
application/x-www-form-urlencoded:浏览器原生form表单,如果不设置enctype属性,最终会以该方式提交数据。
multipart/form-data:使用表单上传文件时,必须让form的enctyped设置为这个值。
application/json:高速服务端消息主体是序列化后的JSON字符串。
text/xml:是一种使用HTTP作为传输协议,XML作为编码方式的远程调用规范。
ES6(待整理)
JS中继承实现的几种方式
原型链继承
ECAM-262把原型链定义为ECMAScript的主要继承方式。
其基本思想就是通过原型继承多个引用类型的属性和方法。
构造函数、原型和实例的关系:每个构造函数都有一个原型对象,原型有一个属性指回构造函数,而实例有一个内部指针指向原型。
如果原型是另一个类型的实例,就意味着这个原型本身有一个内部指针指向另一个原型,相应地另一个原型也有一个指针指向另一个构造函数,这样就在实例和原型之间构造了一条原型链。
将父类的实例作为子类的原型,他的特点是实例时子类的实例也是父类的实例,父类新增的原型方法和属性,子类都能够访问,并且原型链继承简单易于实现,缺点是来自原型对象的所有属性被所有实例共享,无法实现多继承,无法向父类构造函数传参。
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
}
function SubType() {
this.subproperty = false;
}
// 继承SuperType
SubType.prototype = new SuperType();
SubType.prototype.getSubValue = function() {
return this.subproperty;
}
let instance = new SubType();
console.log(instance.getSuperValue()); // true
- 默认原型
实际上,原型链中还有一环。默认情况下,所有引用类型都继承自Object,这也是通过原型链实现的。任何函数的默认原型都是一个Object的实例,这意味着这个实例有一个内部指针指向Object.prototype。这也是为什么自定义类型能够继承包括toString()、valueOf()在内的所有默认方法的原因。 - 原型与继承关系
原型与实例的关系可以通过两种方式来确定。
第一种方式是使用instanceof操作符,如果一个实例的原型链中出现过相应的构造函数,则instanceof返回true。
第二种方式时使用isPrototypeOf()方法。原型链中的每个原型都可以调用这个方法。只要原型链中包含这个原型,这个方法就返回true。 - 关于方法
子类有时候需要覆盖父类的方法,或者增加父类没有的方法。为此,这些方法必须在原型赋值之后再添加到原型上。
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
}
function SubType() {
this.subproperty = false;
}
// 继承SuperType
SubType.prototype = new SuperType();
// 新方法
SubType.prototype.getSubValue = function() {
return this.subproperty;
}
// 覆盖已有的方法,原型链上的getSuperValue方法被遮盖
SubType.prototype.getSuperValue = function() {
return false;
}
let instance = new SubType();
console.log(instance.getSuperValue()); // false
注意:以对象字面量方式创建原型方法会破坏之前的原型链,因为这相当于重写原型链。
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
}
function subType() {
this.subproperty = false;
}
// 继承SuperType
SubType.prototype = new SuperType();
// 通过对象字面量添加新方法,会导致上一行无效,覆盖后的原型是一个Object,不再是SuperType
SubType.prototype = {
getSubValue() {
return this.subproperty;
}
someOtherMethod() {
return false;
}
}
let instance = new SubType();
console.log(instance.getSuperValue()); // 出错
- 原型链的问题
原型链虽然是实现继承的强大工具,但它也有问题。
主要问题出现在原型中包含引用值的时候。原型中包含的引用值会在所有实例间共享,这也是为什么属性通常在构造函数中定义而不会在原型上定义的原因。在使用原型实现继承时,原型实际上变成了另一个类型的实例。这意味着原先的实例变成了原型的属性。
function SuperType() {
this.colors = ['red', 'blue', 'green'];
}
function SubType() {}
// 继承SuperType
SubType.prototype = new SuperType();
let instance1 = new SubType();
instance1.colors.push('black');
console.log(instance1.colors); // ['red', 'blue', 'green', 'black']
let instance2 = new SubType();
console.log(instance2.colors); // ['red', 'blue', 'green', 'black']
原型链的第二个问题是,子类型在实例化时不能给父类型的构造函数传参。事实上,无法在不影响所有对象实例的情况下把参数传进父类的构造函数。
上述两个问题,导致原型链继承的方式基本不会被单独使用。
盗用构造函数继承
为了解决原型包含引用值导致的继承问题
基本思路:在子类构造函数中调用父类构造函数。
因为函数就是在特定上下文中执行代码的简单对象,所以可以使用apply和call方法以新创建的对象为上下文执行构造函数
funciton SuperType() {
this.colors = ['red', 'blue', 'green'];
}
function SubType() {
SuperType.call(this);
}
let instance1 = new SubType();
instance1.colors.push('black);
console.log(instance1.colors); // ['red', 'blue', 'green', 'black']
let instance2 = new SubType();
console.log(instance1.colors); // ['red', 'blue', 'green']
通过使用call或者apply方法,SuperType构造函数在为SubType的实例创建新对象的上下文中执行,这相当于新的SubType对象上运行了SuperType()函数中的所有初始化代码。
- 传递参数
相比于使用原型链,盗用构造函数的一个优点就是可以在子类构造函数中向父类构造函数传参。
function SuperType(name) {
this.name = name;
}
function SubType() {
// 继承SuperType并传参
SuperType.call(this, 'Nicholas');
this.age = 29;
}
let instance1 = new SubType();
console.log(instance1.name); // Nicholas
console.log(instance1.age); // 29
为了确保SuperType构造函数不会覆盖SubType定义的属性,可以在调用父类构造函数之后再给子类实例添加额外的属性。
- 盗用构造函数的问题
盗用构造函数的主要缺点,也是使用构造函数模式自定义类型的问题:必须在构造函数中定义方法,因此函数不能重用,此外,子类也不能访问父类原型上定义的方法,因此所有类型只能使用构造函数模式。由于存在这样问题,盗用构造函数基本上也不能单独使用。
组合继承
有时候也叫伪经典继承,综合了原型链和盗用构造函数,将两者的优点集中了起来。
基本思路时使用原型链继承原型上的属性和方法,而通过盗用构造函数继承实例继承。
这样即可以把方法定义在原型上实现重用,又可以让每个实例都有自己的属性。
function SuperType(name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
}
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SubType.prototype = new SuperType;
SubType.prototype.sayAge = function () {
console.log(this.age);
}
let instance1 = new SubType('Nicholas', 29);
instance1.colors.push('black');
console.log(instance1.colors); // ['red', 'blue', 'green', 'black']
instance1.sayName(); // Nicholas
instance1.sayAge(); // 29
let instance2 = new SubType('Grey', 27);
console.log(instance2.colors); // ['red', 'blue', 'green']
instance2.sayName(); // Grey
instance2.sayAge(); // 27
组合继承弥补了原型链和盗用构造函数的不足,是JavaScript中使用最多的继承模式。而且组合继承也保留了instanceof操作符和isPrototypeOf()方法识别合成对象的能力。
原型式继承
2006年,Douglas Crockford在《Javascript中的原型式继承》中提出,出发点是即使不自定义类型也可以通过原型实现对象之间的信息共享。
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
let person = {
name: 'Nicholas',
friends: ['Shelby', 'Court', 'van']
}
let anotherPerson = object(person);
anotherPerson.name = 'Greg';
anotherPerson.friends.push('Rob');
let yetAnotherPerson = object(person);
yetAnotherPerson.name = 'Linda';
yetAnotherPerson.friends.push('Barbie');
console.log(person.friends); // ['Shelby', 'Court', 'van', 'Rob', 'Barbie']
object()函数会创建一个临时构造函数,将传入的对象赋值给这个构造函数的原型,然后返回这个临时类型的一个实例。
本质上,object() 是对传入的对象执行了一次浅复制。
原型式继承适用于:有一个对象,需要在它的基础上再创建一个新对象。
需要把这个对象先传给object(),然后再对返回的对象进行适当的修改。在这个例子中,person对象定义了另一个对象也应该共享的信息,把它传给object()之后会返回一个新对象。这个新对象的原型是person,意味着它的原型上既有原始值属性又有引用值属性,这意味着person.friends不仅是person的属性,也会跟着anotherPerson和yetAnotherPerson共享。这里实际上克隆了两个person。
ECMAScript5通过增加object.create()方法将原型式继承的概念规范化了。这个方法接受两个参数:作为新对象原型的对象,以及给新方法定义额外属性的对象(可选)。在只有一个参数时,Object.create()方法与上文中的object方法效果相同。
let person = {
name: 'Nicholas',
friends: ['Shelby', 'Court', 'van']
}
let anotherPerson = Object.create(person);
anotherPerson.name = 'Greg';
anotherPerson.friends.push('Rob');
let yetAnotherPerson = Object.create(person);
yetAnotherPerson.name = 'Linda';
yetAnotherPerson.friends.push('Barbie');
console.log(person.friends); // ['Shelby', 'Court', 'van', 'Rob', 'Barbie']
Object.create()的第二个参数与Object.defineProperties()的第二个参数一样:每个新增属性都通过各自的描述符来描述。以这种方式添加的属性会屏蔽原型对象上的同名属性
let person = {
name: 'Nicholas',
friends: ['Shelby', 'Court', 'van']
}
let anotherPerson = Object.create(person, {
name: {
value: 'Greg"
}
});
console.log(anotherPerson.name); // 'Greg'
原型式继承非常适合不需要单独创建构造函数,但仍需要在对象间共享信息的场合。但要记住,属性中包含的引用值始终会在相关对象间共享,跟使用原型模式是一样的。
寄生式继承
与原型式继承比较接近,也是Crockford首倡的一种模式。
寄生式继承背后的思路类似于寄生构造函数和工厂模式:创建一个实现继承的函数,以某种方式增强对象,然后返回这个对象。
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
function createAnother(o) {
let clone = object(o); // 通过调用函数创建一个新对象
clone.sayHi = function() { // 以某种方式增强对象
console.log('hi');
}
return clone;
}
let person = {
name: 'Nicholas',
friends: ['Shelby', 'Court', 'van']
}
let anotherPerson = createAnother(person);
anotherPerson.sayHi(); //
寄生式继承同样适合主要关注对象,而不在乎类型和构造函数的场景。object()函数不是寄生式继承所必需的,任何返回对象的函数都可以在这里使用。
寄生组合继承
组合继承其实也存在效率问题。最主要的效率问题就是父类构造函数始终会被调用两次:一次是在创建子类型原型时调用,另一次是在子类构造函数中调用。本质上,子类原型最终是要包含超类对象的所有实例属性,子类构造函数只要在执行时重写自己的原型就行。
function SuperType(name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
}
function SubType(name, age) {
SuperType.call(this, name); // 第一次调用
this.age = age;
}
SubType.prototype = new SuperType(); // 第二次调用
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function() {
console.log(this.age);
}
寄生式组合继承通过盗用构造函数继承属性,但使用混合式原型链继承方法。
基本思路是不通过调用父类构造函数给子类原型赋值,而是取得父类原型的一个副本。说到底就是使用寄生式继承来继承父类原型,然后将返回的对象赋值给了子类原型。
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
// 寄生式组合继承的核心逻辑
function inheritProperty(subType, SuperType) {
let prototype = object(SuperType.prototype);
prototype.constructor = subType;
subType.prototype = prototype;
}
function SuperType(name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
}
function SubType(name, age) {
SuperType.call(this, name); // 第一次调用
this.age = age;
}
inheritProperty(SubType, SuperType);
SubType.prototype.sayAge = function() {
console.log(this.age);
}
webSocket(waiting…)
cookie、sessionStorage和localStorage(waiting…)
-
cookie是什么?
cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。
cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下。属性:
- Domain,告诉浏览器允许访问cookied的主机,默认设置为cookie的统一主机。
- Path,指定访问cookieb必须存在的请求URL中的路径。处理将cookiex限制到域之外,还可以通过路径来限制它。路径属性为Path=/store的cookiez只能在路径/store及其子路径/store/cart、/store/gadgets等上访问。
- Expires/Max-size,用来设置过期时间。若设置其值为一个时间,那么当到达此时间后,cookie就会失效。不设置的话默认值是Session,意思是cookie会和session一起失效。当浏览器关闭后,cookie会失效。
- Secure,具有Secure属性的cookie仅可以通过安全的HTTPS协议发送到服务器,而不会通过HTTP协议。有助于通过使cookie无法通过不安全的连接访问来防止中间人攻击。除非网站使用不安全的HTTP连接,否则应该始终将此属性与所有cookie一起使用。
- HTTPOnly,该属性限制cookie只能通过服务端访问。因此,只有服务端可以通过响应头设置它们,然后浏览器会将它们与每个后续请求头一起发送到服务器,并且它们将无法通过客户端JavaScript访问。
-
sessionStorage是什么?
-
localStorage是什么?
-
区别
- 生命周期
Cookie:可设置失效时间,否则默认认为关闭浏览器后失效
LocalStorage:除非被手动清除,否则永久保存
SessionStorage:仅在当前网页会话下有效,关闭页面或浏览器后会被清除 - 存放数据
Cookie:4k左右
LocalStorage、SessionStorage:可以保存5M的信息 - http请求
Cookie:每次都会携带在http头中,如果使用cookie保存过多数据会带来性能问题。
LocalStorage、SessionStorage:仅在客户端即浏览器中保存,不参与和服务器的通信。 - 易用性
Cookie:需要程序员自己封装,原生的cookie接口不友好
LocalStorage、SessionStorage:既可采用原声接口,亦可再次封装 - 应用场景
从安全性来说,因为每次http请求都会携带cookie信息,这样子浪费了带宽,所以cookie应该尽可能的少用,此外cookie还需要指定作用域,不可以跨域调用,限制很多,但是识别用户登陆来说,cookie还是比storage好用,其他情况下可以用storage,localStorage可以用来在页面传递参数,sessionStorage可以用来保存一些临时的数据,防止用户刷新页面后丢失了一些参数。
let、const和var的区别
- 块级作用域
块作用域由{}包括,let和const具有块级作用域,var不存在。
块级作用域解决了两个ES5中的问题:- 内层变量可以覆盖外层变量
- 用来计数的循环变量泄露到全局
- 变量提升
var存在变量提升,let和const不存在变量提升,只能在声明之后使用,否则报错。
暂时性死区
在使用let、const声明变量之前,变量不可用(由于无变量提升)。在语法上,称为暂时性死区。
使用var声明的变量不存在暂时性死区。 - 给全局添加属性
浏览器的全局对象是window。
var声明的变量为全局变量,并且会将其添加到全局对象的属性中。
let和const不会。 - 重复声明
var声明变量时,可以重复声明,后声明覆盖先声明的变量。
const和let不允许重复声明变量。 - 初始值设置
在声明变量时,var和let可以不设置初始值,而const必须设置初始值。 - 指针指向
let和const都是ES6新增的用于创建变量的语法。
let创建的变量可以改变指针指向(重新赋值);
const创建的变量不允许改变指针的指向(不可重新赋值,但是引用类型是不允许更改地址,属性可以修改)。
| 区别 | var | let | const |
|---|---|---|---|
| 块级作用域 | × | ✓ | ✓ |
| 变量提升 | ✓ | × | × |
| 添加全局变量 | ✓ | × | × |
| 重复声明变量 | ✓ | × | × |
| 暂时性死区 | ✓ | ✓ | |
| 必须设置初始值 | × | × | ✓ |
| 改变指针指向 | ✓ | ✓ | × |
闭包的作用、原理、使用场景
一个函数和对其周围状态的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。通俗来说,闭包其实就是一个可以访问其他函数内部变量的函数。即一个定义在函数内部的函数,或者说闭包是个内嵌函数。
通常情况下,函数内部变量是无法在外部访问的(全局变量和局部变量的区别),因此使用闭包的作用,就具备实现了能在外部访问某个函数内部变量的功能,让这些内部变量的值始终可以保存在内存中:
function fn() {
let var1 = 1; // 内部变量,正常情况下作为函数内局部变量,函数外无法访问
return function() { // 闭包
console.log(var1); // 可以外函数外result调用时,访问内部变量var1
}
}
var result = fn();
result(); // 1
闭包概念为JavaScript中访问函数内变量提供了途径和遍历。
当访问一个变量的时候,代码解释器首先在当前的作用域查找,若没有,则去父级作用域查找,直到找到改变量或者不存在于父级作用域中,这样的链路就是作用域链。
每个子函数都会拷贝上级的作用域,形成一个作用域链:
let a = 1;
function fn() {
let a = 2;
function fn2() {
let a = 3;
console.log(a); // 3
}
fn2();
}
fn();
闭包产生的本质就是:当前环境中存在指向父级作用域的引用。
那是不是只有返回函数才能产生了闭包,其实不是,只需要让父级作用域的引用存在即可。
let fn3;
function fn1() {
let a = 2;
fn3 = function() {
console.log(a);
}
}
fn1();
fn3();
闭包的表现形式及应用场景:
- 在定时器、事件监听、Ajax请求、Web Workers或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。
// 定时器 setTimeout(() => { console.log('1'); }, 1000); // 事件监听 const a = document.getElementById('#a'); a.addEventListener('click', () => { console.log('click); }); - 作为函数参数传递的形式
let a = 1; function foo() { let a = 2; function baz() { console.log(a); } bar(baz); } function bar(fn) { // 闭包 fn(); } foo(); - IIFE(立即执行函数),创建了闭包,保存了全局作用域(window)和当前函数的作用域,因此可以输出全局的变量
var a = 1; (function IIFE() { // 匿名函数用于独立的作用域 console.log(2); // 1 })(); - 结果缓存(备忘模式)
function add(n) { return n + 1; } function memorizerAdd(fn) { const cache = {}; return function(...args) { const key = JSON.stringify(args); // 将add函数的参数序列化为字符串,将它当做cache的索引 const computedNum = cache[key] || (cache[key] = fn.apply(fn, args)); // 存在索引不再计算,直接取值 return computedNum; } } let memorizerAdder = memorizerAdd(add); memorizerAdder(1); // 输出:2 cache: {'[1]': 1} memorizerAdder(1); // 输出:2 cache: {'[1]': 1} memorizerAdder(2); // 输出:3 cache: {'[1]': 1, '[2]': 3}
和闭包相关的循环输出问题
如何输出1、2、3、4、5
for(var i = 1; i <= 5; i++) {
setTimeout(() => {
console.log(i); // 由于setTimeout是宏任务,执行setTimeout时,寻找i时,会找到全局window上的i,此时i已经是6,所以输出5个6
}, 0);
}
- IIFE
for(var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(() => {
console.log(j);
}, 0);
})(i);
}
- ES6 let
for(let i = 1; i <= 5; i++) {
setTimeout(() => {
console.log(j);
}, 0);
}
- 定时器的第三个参数
setTimeout从第三个入参位置开始往后,可以传入无数个参数,这些参数会作为回调函数的附加参数存在。
for (var i = 1; i <= 5; i ++) {
setTimeout(() => {
console.log(j);
}, 0, i);
}
apply、call和bind
- 相同点:
都是改变this的指向,传入的第一个参数都是绑定this指向,在非严格模式中,如果第一个参数是null或undefined,会把全局对象(浏览器时window)作为this的值,要注意的是,在严格模式中,null和undefined是不同的。 - call和apply的区别
只有一个区别,call传入的是参数列表,apply传入的是数组,也可以是类数组。 - bind和call、apply的区别
bind返回的是一个改变了this指向的函数,便于稍后调用,而call和apply会立即调用;
bind和call很像,传入的也是参数列表,但是可以多次传入,不需要像call,一次传入。
- call函数的实现
步骤:
- 判断调用对象是否为函数,即便是定义在函数原型上的,也可能出现使用call调用的情况
- 判断传入上下文对象是否存在,若无,默认设置为window
- 处理传入的参数,截取第一个参数后的所有参数
- 将函数作为上下文对象的一个属性
- 使用上下文对象来调用这个方法,并保存返回结果
- 删除刚才新增的属性
- 返回结果
Function.prototype.newCall = function(context) {
// 判断调用对象
if(typeof this !== 'function') {
console.log('调用 error');
}
// 获取参数
let args = [...arguments].slice(1, );
let result = null;
let fn = this;
// 判断context是否传入,若未传入,设置为window
context = context || window;
context.fn = this;
result = context.fn(...args);
delete context.fn;
return result;
}
- apply函数的实现
步骤:
- 判断调用对象是否为函数,即便是定义在函数原型上的,也可能出现使用apply调用的情况
- 判断传入上下文对象是否存在,若无,默认设置为window
- 将函数作为上下文对象的一个属性
- 判断参数值是否传入
- 使用上下文对象来调用这个方法,并保存返回结果
- 删除刚才新增的属性
- 返回结果
Function.prototype.newApply = function(context) {
// 判断调用对象
if(typeof this !== 'function') {
console.log('调用 error');
}
// 判断context是否传入,若未传入,设置为window
context = context || window;
context.fn = this;
const args = arguments[1] || [];
result = context.fn(...args);
delete context.fn;
return result;
}
- bind函数的实现
步骤:
- 判断调用对象是否为函数,即便是定义在函数原型上的,也可能出现使用bind调用的情况
- 保存当前函数的应用,获取其余传入参数值
- 创建一个函数返回
- 函数内部使用apply来绑定函数调用,需要判断函数作为构造函数的情况,这时需要传入当前函数的this给apply,其余情况都传入指定的上下文对象
Function.prototype.newBind = function(context) {
// 判断调用对象
if(typeof this !== 'function') {
console.log('调用 error');
}
const args = [...arguments].slice(1, );
const fn = this;
return function Fn() {
// fn instanceof Fn作为构造函数的情况
const realContext = fn instanceof Fn ? fn : context;
const realArgs = args.concat(...arguments); // 多次传入
return fn.apply(realContext, realArgs);
}
}
事件循环机制
浏览器事件循环
JavaScript任务分为两种:
- 同步任务
在主线程上排队执行的任务,一个任务执行完毕,才会执行下一个任务 - 异步任务
不进入主线程,而是放在任务队列中,若有多个异步任务,则需要在任务队列中排队等待,任务队列类似缓冲区,任务下一步会被移入执行栈,然后主线程执行调用栈的任务
- 执行栈
执行栈是一个存储函数调用的栈结构,遵循先入后出的原则,主要负责跟踪所有要执行的代码。每当函数执行完成,就会从堆栈中pop(弹出)该执行完成的函数;如果有代码需要执行,就会push进执行栈中。
JavaScript按照先进后出的方式对执行栈中的方法进行执行,每次执行方法,都会生成该方法独有的执行环境(上下文),当方法执行完成后,将当前方法的执行环境销毁,并从栈中弹出该方法,然后执行栈顶的下一个方法。

- 任务队列
任务队列使用队列结构,用来保存异步任务,遵循先入先出的原则。
主要负责将新的任务发送到队列中进行处理。
任务队列根据任务种类又分为微任务(micro task)和宏任务(macro task)队列。 - 宏任务和微任务
- 宏任务
每次只会执行队列内的一个任务。
script(整体代码)、setTimeout、setInterval、I/O、UI rendering、setImmediate(Node.js) - 微任务
每次会执行队列里的全部任务。假设微任务队列内有 100 个 Promise,它们会一次过全部执行完。这种情况下极有可能会导致页面卡顿。如果在微任务执行过程中继续往微任务队列中添加任务,新添加的任务也会在当前事件循环中执行,很容易造成死循环。
Promise.then、MutationObserve、process.nextTick(Node.js)、Object.observe(废弃)等
宏任务和微任务的执行顺序: 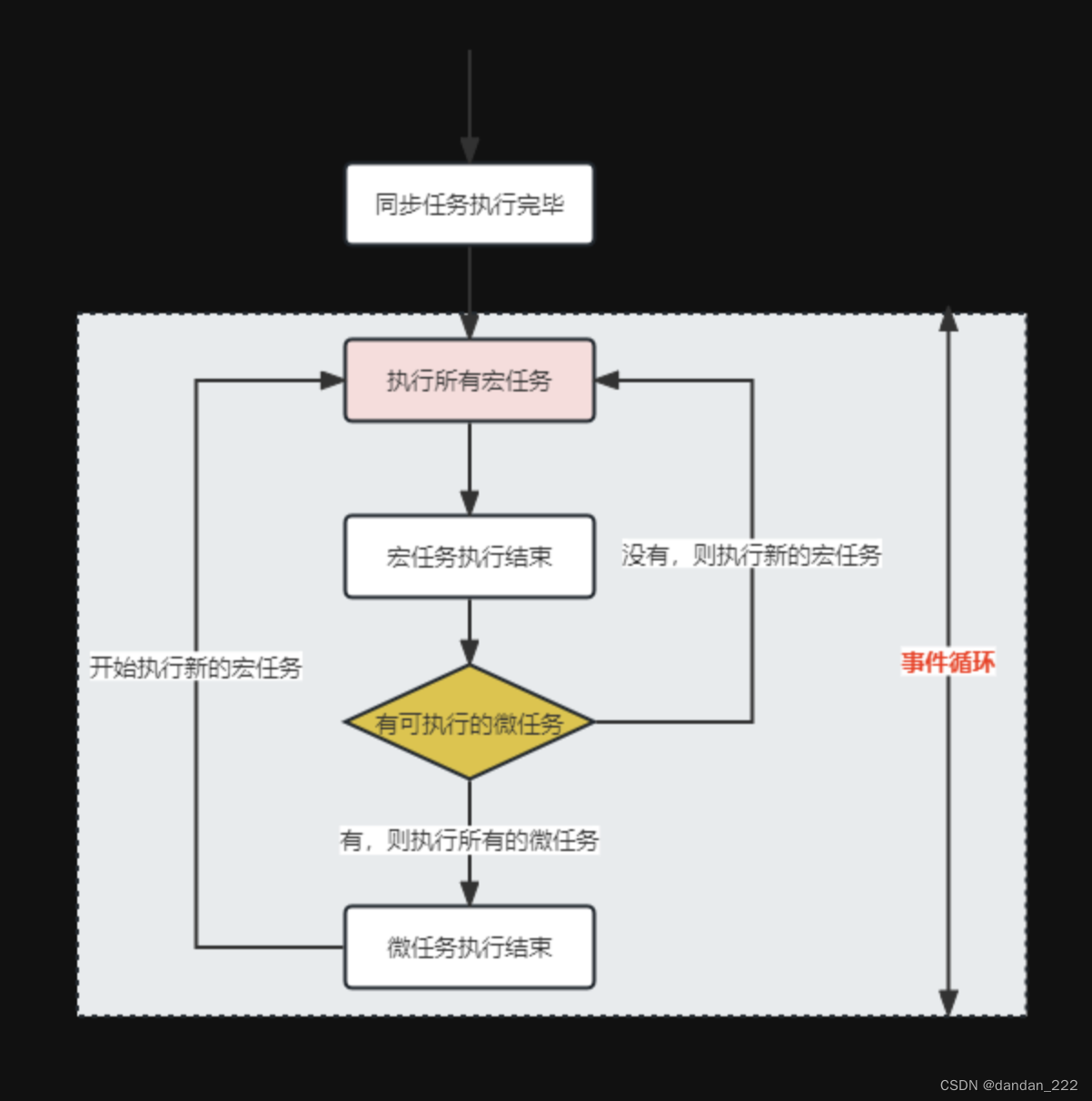

4. JavaScript任务执行顺序
同步代码按照顺序排在执行栈中,然后一次执行。当遇到异步任务时,将其放入对应的宏任务或微任务的任务队列中。
当执行栈中的所有同步代码执行完成后,从异步任务队列中取出已完成异步任务的回调(先微任务后宏任务),并将其放入执行栈中继续执行,如此循环,直到执行完所有的任务。
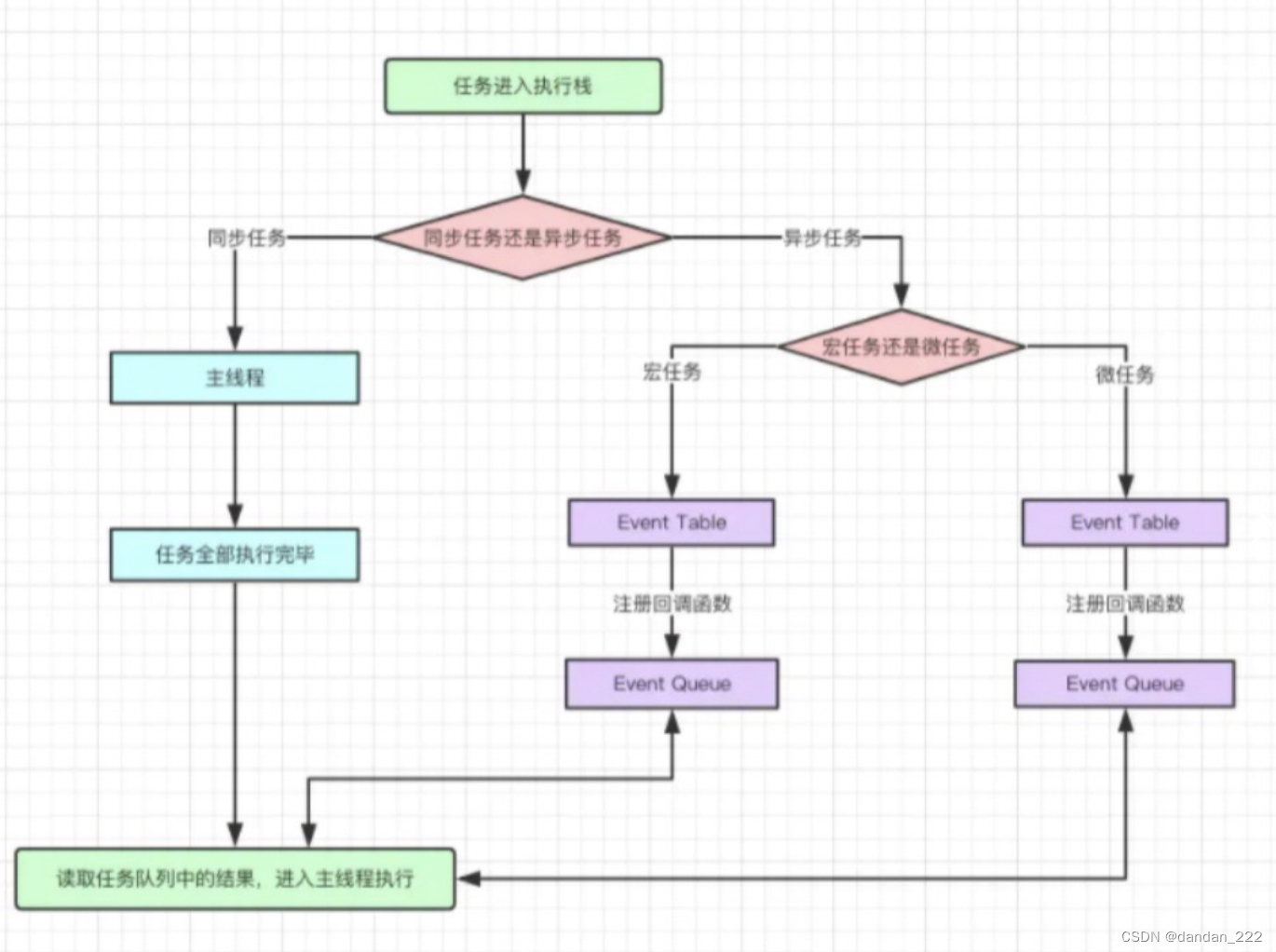
示例题1
async function method() {
console.log(1); // 1
new Promise((resolve) => resolve()).then(() => console.log(2));
new Promise((resolve) => {
setTimeout(() => {
resolve();
new Promise((resolve) => resolve()).then(() => console.log(3));
}, 0);
}).then(() => console.log(4));
await method3();
console.log(5);
const n = await method2();
console.log(n);
}
function method2() {
const promise = new Promise((resolve) => {
console.log(6);
setTimeout(() => {
console.log(7);
resolve(8);
}, 0);
});
return promise;
}
function method3() {
const promise = new Promise((resolve) => {
console.log(9);
resolve();
});
return promise;
}
function main() {
method();
new Promise((resolve) => {
resolve();
}).then(() => {
console.log(10);
});
console.log(11);
}
main();
console.log(12);
输出结果: 1 9 11 12 2 5 6 10 4 3 7 8
示例题2
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
输出结果:
script start
async2 end
Promise
script end
async1 end
promise1
promise2
setTimeout
示例题3
(function() {
setTimeout(() => {
console.log(0);
});
new Promise(resolve => {
console.log(1);
setTimeout(() => {
resolve();
Promise.resolve().then(() => console.log(2));
console.log(3);
});
Promise.resolve().then(() => console.log(4));
}).then(() => {
console.log(5);
Promise.resolve().then(() => console.log(8));
setTimeout(() => console.log(6));
});
console.log(7);
})();
输出结果:
1 7 4 0 3 5 2 8 6
示例题4
(function() {
setTimeout(() => {
console.log(0);
});
new Promise(resolve => {
console.log(1);
setTimeout(() => {
resolve();
Promise.resolve().then(() => {
console.log(2);
setTimeout(() => console.log(3));
Promise.resolve().then(() => console.log(4));
});
});
Promise.resolve().then(() => console.log(5));
}).then(() => {
console.log(6);
Promise.resolve().then(() => console.log(7));
setTimeout(() => console.log(8));
});
console.log(9);
})();
输出结果:1 9 5 0 6 2 7 4 8 3
Node.js事件循环(ing)
-
事件循环机制
当Node.js启动时,它会初始化一个事件循环,来处理输入的脚本,这个脚本可能进行异步API的调用、调度计时器或调用process.nextTick(),然后开始处理事件循环。
JavaScript和Node.js是基于v8引擎的,浏览器中包含的异步方式在NodeJS中也是一样的。除此之外,Node.js中还有一些其他的异步形式:- 文件I/O:异步加载本地文件
- setImmediate:与setTimeout设置0ms类似,在某些同步任务完成后立即执行
- process.nextTick():在某些同步任务完成后立即执行
- server.close、socket.on(‘close’, …)等:关闭回调
Node.js中的Event Loop和浏览器中完全不同。Node.js使用V8作为解析引擎,并在I/O处理使用自己设计的libuv。
libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一下底层特性,对外提供统一的API,事件循环机制也是在libuv中实现的。
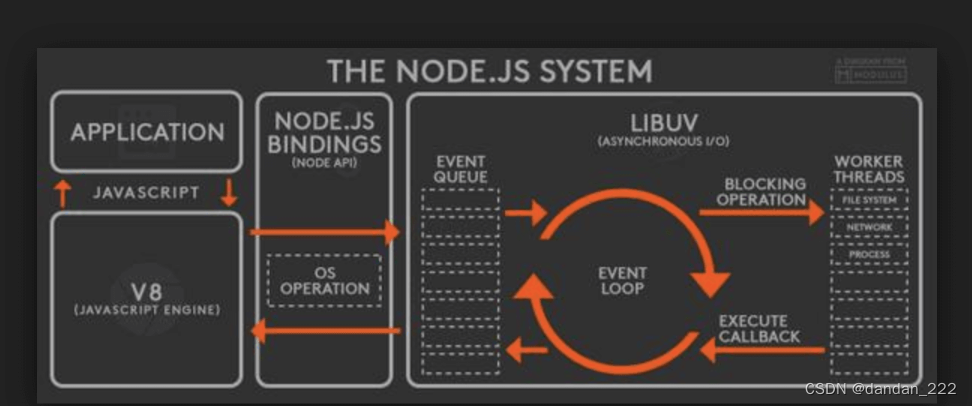
- V8引擎解析js脚本
- 解析后的代码,调用Node API
- libuv库负责Node API的执行。将不同任务分配给不同的线程,形成Event Loop,以异步的方式将执行结果返回给V8引擎
- V8引擎将结果返回给用户
- 宏任务微任务
Node.js事件循环的异步队列也分为两种:宏任务和微任务队列
- 宏任务
setTimeout、setInterval、setImmediate、script、I/O操作,等 - 微任务
process.nextTick、Promise.then等
- 事件循环的流程
+--------------------------+
| |
| timers | 计时器阶段:处理 setTimeout() 和 setInterval() 定时器的回调函数。
| |
+--------------------------+
| |
| pending callbacks | 待定回调阶段:用于处理系统级别的错误信息,例如 TCP 错误或者 DNS 解析异常。
| |
+--------------------------+
| |
| idle, prepare | 仅在内部使用,可以忽略不计。
| |
+--------------------------+
| |
| poll | 轮询阶段:等待 I/O 事件(如网络请求或文件 I/O 等)的发生,然后执行对应的回调函数,并且会处理定时器相关的回调函数。
| | 如果没有任何 I/O 事件发生,此阶段可能会使事件循环阻塞。
+--------------------------+
| |
| check | 检查阶段:处理 setImmediate() 的回调函数。check 的回调优先级比 setTimeout 高,比微任务要低
| |
+--------------------------+
| |
| close callbacks | 关闭回调阶段:处理一些关闭的回调函数,比如 socket.on('close')。
| |
+--------------------------+
事件冒泡和捕获
两种不同的事件传播方式,默认是事件冒泡。
区别:传播方向不同
-
冒泡(Bubbling)
事件从具体的元素(文档中嵌套层次最深的节点)开始向外传播,直到最不具体的节点(文档)。
例如,用户点击子元素,子元素上的事件处理程序先执行,然后事件向上传播,依次执行父元素、祖先元素上的事件处理程序,直到文档中的根元素为止。 -
捕获(Capturing)
事件从最不具体的节点开始向内传播,直到最具体的节点。
例如,用户点击一个子元素,事件从文档中的根节点开始,先执行根元素上的事件处理程序,然后事件向内传播,依次执行子节点、孙子节点上的事件处理程序。默认情况下,事件处理程序采用的是事件冒泡方式。
可以通过事件处理程序中用event.stopPropagation()方法来阻止事件冒泡或捕获过程。
事件捕获的支持,在某些浏览器中并不太好,需要在实践中根据实际情况选择合适的事件传播方式。
事件代理
通过将事件处理程序添加到父元素上,从而来管理子元素的事件处理,当子元素触发事件时,事件会冒泡到父元素,交由父元素来处理子元素触发的事件。
优点
可以减少事件处理程序数量、减轻页面的负担,提高代码性能和可维护性。
使用场景
- 动态添加元素
动态添加子元素,例如ul-li,将事件处理程序添加在ul上。
如果每个子元素都添加事件处理程序,会使代码变得冗长且难以维护。此时,可以将事件处理程序添加到父元素上,由父元素来管理子元素的时间处理。 - 性能优化
当页面中有大量的元素需要添加事件处理程序时,事件代理能够减少事件处理程序的数量,从而提高页面的性能。 - 代码简洁
通过时间代理,减少冗余的代码,让代码更简洁,提高代码的可读性。
事件代理也存在一些限制,比如不能处理一些需要特定事件目标的事件(比如鼠标位置、滚动信息等的事件)。
new操作符原理
new操作符的执行过程:
- 首先创建一个新的对象
- 设置原型,将对象的原型设置为函数的prototype对象。
- 让函数的this指向这个对象,执行构造函数的代码(为这个对象添加属性)。
- 判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
function objectFactory() {
let newObject = null;
let constructor = Array.prototype.shift.call(arguments);
let result = null;
// 判断参数是否是一个函数
if (typeof constructor !== 'funciton') {
console.log('type error');
return;
}
// 新建一个空对象,对象的原型为构造函数的prototype对象
newObject = Object.create(constructor.prototype);
result = constructor.apply(newObject, arguments);
let flag = result && (typeof result === 'object' || typeof result === 'function');
return flag ? result : newObject;
}
objectFactory(构造函数, 初始化参数);
JavaScript脚本异步加载
script标签中使用defer或async属性可以实现脚本异步加载,否则浏览器会立即加载并执行指定的脚本,这样就有可能阻塞后续文档的加载。
defer和async属性都是异步加载外部的JavaScript脚本文件,它们都不会阻塞页面的解析
两个属性的区别:
- 执行顺序
多个带async属性的标签,不保证加载顺序
多个带defer属性的标签,会按照加载顺序执行 - 脚本是否并行执行
async属性,表示后续文档的加载和执行与JavaScript脚本的加载和执行是并行进行的,即异步执行;
defer属性,加载后续文档的过程和JavaScript脚本的加载是并行进行的,JavaScript脚本需要等到文档所以元素解析完成之后,DOMContentLoaded(初始HTML文档完全加载和解析时,触发DOMContentLoaded,不需要等待样式表、图像和子框架页面加载,事件用于检测HTML页面是否完全加载完毕)事件触发之前执行。
蓝色下载,红色执行,绿色解析,灰色html解析暂停
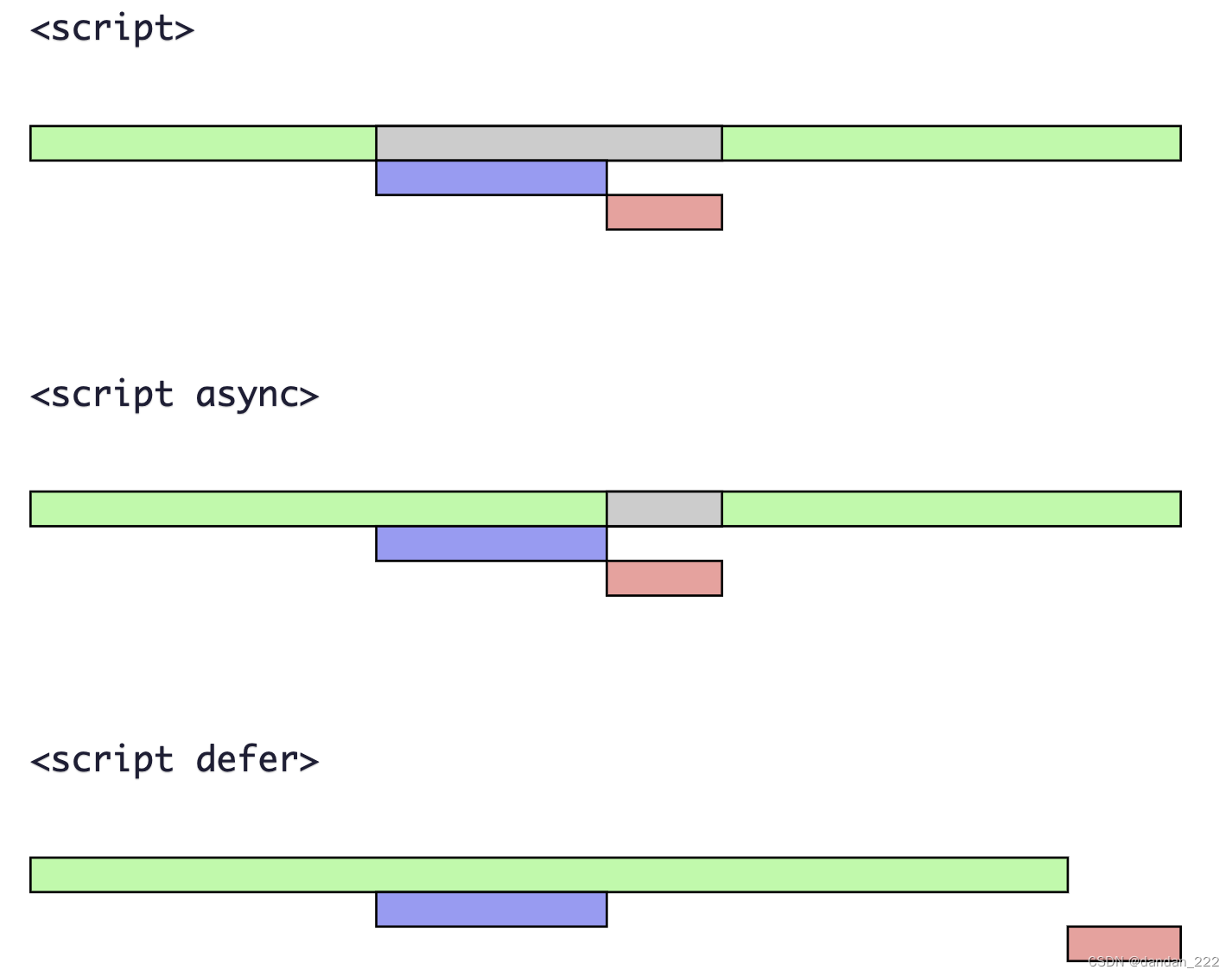
深浅拷贝
浅拷贝
一个新的对象对原始对象的属性值进行精确地拷贝。
- 拷贝对象是基本数据类型,拷贝的就是基本数据类型的值;
- 拷贝对象是引用数据类型,拷贝的就是内存地址,如果其中一个对象的引用内存地址发生改变,另一个拷贝的对象也会发生变化。
- 直接赋值
let obj1 = {a: 1};
let obj2 = obj1;
obj1.a = 2;
console.log(obj1); // {a: 2}
console.log(obj2); // {a: 2}
console.log(obj1 === obj2); // true
- Object.assign
ES6新增的object方法,用于js对象的合并等,该方法接受的第一个参数时目标对象,其余参数是源对象Object.assign(target, source1, ...)。
注:- 如果目标对象和源对象有同名属性,或者多个源对象有同名属性,则后面的属性会覆盖前面的属性。
- 如果assign函数只有一个参数,当参数为对象时,直接返回该对象;当参数不是对象时,将参数转为对象然后返回。
- null和undefined不能转换为对象,所以第一个参数target不能为null或undefined,会报错。
- 它不会拷贝对象的继承属性,不会拷贝对象的不可枚举的属性,可以拷贝Symbol类型的属性。
const target = { a: 1 };
const obj1 = { a: 2, b: 1 };
const obj2 = { c: 3, d: 4 };
Object.assign(target, obj1, obj2);
console.log(target); // { a: 2, b: 1, c: 3, d: 4 }
- 扩展运算符…
构建字面量对象的时候,可以使用扩展运算符进行属性的拷贝。缺点与Object.assign一样
let obj1 = { a: 1, b: { xx: 1 } };
let obj2 = { ...obj1 };
obj1.a = 2;
console.log(obj1); // { a: 2, b: { xx: 1 } }
console.log(obj2); // { a: 1, b: { xx: 1 } }
obj1.b.xx = 22;
console.log(obj1); // { a: 2, b: { xx: 22 } }
console.log(obj2); // { a: 1, b: { xx: 22 } }
- 数组方法实现数组浅拷贝
- Array.prototype.slice
省略两个参数,可以实现数组的浅拷贝。
let arr = [1, 2, 3, 4];
console.log(arr.slice()); // [1, 2, 3, 4]
console.log(arr.slice() === arr); // true
- Array.prototype.concat
省略两个参数,可以实现数组的浅拷贝。
let arr = [1, 2, 3, 4];
console.log(arr.concat()); // [1, 2, 3, 4]
console.log(arr.concat() === arr); // true
- 手写
function sCopy(obj) {
if (!obj || typeof obj !== 'object') {
return ;
}
let result = Array.isArray(obj) ? [] : {};
for (key in obj) {
if (Object.hasOwnProperty(key)) {
result[key] = obj[key]
}
}
return result;
}
深拷贝
- 对于简单类型直接拷贝它的值
- 对于引用数据类型,在堆内存中开辟一块内存用于存放复制的对象,并把原有的引用类型数据拷贝过来,这两个对象相互独立,属于两个不同的内存地址,修改其中一个,另一个不受影响
- JSON.parse(JSON.stringify())
常用,但是当对象中有函数、undefined、symbol时,当使用JSON.stringify方法进行处理后,都会消失
当对象中有循环引用时,会出错
let obj1 = { a: 0, b: { c: 1 } }
let obj2 = JOSN.parse(JSON.stringify(obj1));
obj1.a = 1;
obj1.b.c = 2;
console.log(obj1); // { a: 1, b: { c: 2 } }
console.log(obj2); // { a: 0, b: { c: 1 } }
注意:
- 无法拷贝不可枚举的属性
- 无法拷贝对象的原始链
- 拷贝RegExp引用类型会变成空对象
- 对象中含有NaN、Infinity以及-Infinity,JSON序列化的结果会变成null
- 无法拷贝对象的循环引用,即对象成环(obj[key] = obj)
- 函数库lodash的_.cloneDeep方法
let lodash = require('lodash');
let obj1 = {
a: 1,
b: { c: {d: 2} },
e: [1, 2, 3]
}
let obj2 = lodash.cloneDeep(obj1);
console.log(obj2.b.c === obj1.b.c); // false
- 手写
- 递归
问题:
不能赋值不可枚举的属性以及Symbol类型
只针对普通的引用类型的值做递归赋值,对于Array、Date、RegExp、Error、Function这样的引用类型不能正确的拷贝
对象的属性里面有循环引用,无法解决
递归太深会引发栈内存溢出
function deepClone(source) {
if (source instanceof Object === false) {
return source;
}
let result = Array.isArray(source) ? [] : {};
for (let i in source) {
if (Object.hasOwnProperty(i)) {
const sourceItem = source[i];
if (sourceItem instanceof Object) {
result[i] = deepClone(sourceItem);
} else {
result[i] = sourceItem;
}
}
}
return result;
}
- 栈
将待拷贝的对象放入栈中,循环直到栈为空,深度优先遍历
能够解决递归爆栈的问题,但是循环引用的问题依然存在
function deepCloneLoop(x) {
const root = {};
const loopList = [{
parent: root,
key: undefined,
data: x
}];
while(loopList.length) {
const node = loopList.pop();
const { parent, key, data } = node;
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
for (let k in data) {
if (data.hasOwnProperty(k)) {
const dataItem = data[k];
if (typeof dataItem === 'object') {
loopList.push({
parent: res,
key: k,
data: dataItem
});
} else {
res[k] = dataItem;
}
}
}
}
return root;
}
- 栈解决循环引用问题
引入一个数组,用来存储以及拷贝的数组,每次循环遍历对象,先判断是否在该数组中,如果在则不执行
function cloneForce(x) {
const root = {};
const loopList = [{
parent: root,
key: undefined,
data: x
}];
const uniqueList = []; // 引入数组
while(loopList.length) {
const node = loopList.pop();
const { parent, key, data } = node;
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
const uniqueFlag = find(uniqueList, data);
if (uniqueFlag) {
parent[key] = uniqueData.target;
continue;
}
uniqueData.push({
target: res,
source: data
});
for (let k in data) {
if (data.hasOwnProperty(k)) {
const dataItem = data[k];
if (typeof dataItem === 'object') {
loopList.push({
parent: res,
key: k,
data: dataItem
});
} else {
res[k] = dataItem;
}
}
}
}
return root;
}
function find(arr, item) {
for (let arrItem of arr) {
const { source, target } = arrItem;
if (source === item) {
return true;
}
}
return false;
}
instanceof原理
instanceof运算符用于判断构造函数的prototype属性是否出现在对象的原型链中的任何位置。
function MyInstanceof(left, right) {
let proto = left.__proto__;
// proto = Object.getPrototypeOf(left)
let prototype = right.prototype;
while (true) {
if (!proto) {
return false;
}
if (proto === prototype) {
return true;
}
proto = proto.__proto__;
// proto = Object.getPrototypeOf(proto)
}
}
JSON
JS相关面试题
js的语言特性
- 运行在客户端浏览器上
- 脚本语言、解释型语言,不用预编译,直接解析执行代码
- 弱类型语言,较为灵活
- 与操作系统无关,跨平台的语言
代码的执行顺序
setTimeout(function() {
console.log(1);
}, 0);
new Promise((resolve, reject) => {
console.log(2);
resolve();
}).then(function() {
console.log(3);
}).then(function() {
console.log(4);
});
process.nextTick(function() {
console.log(5);
});
console.log(6);
运行结果:2 6 5 3 4 1
去除字符串首尾空格
if (!string.prototype.trim) {
string.prototype.trim = funciton() {
// ^ => 以...为开始
// \s => space 空格
// + => 一个或多个
// | => 或者
// $ => 以...为结尾
// g => global 全局
return string(this).replace(/^\s+|\s+$/g, '');
}
}
if (' dog '.trim() === 'dog') {
console.log('字符串去除空格成功!');
}
数组去重
// 法一:indexOf循环去重
function unique1(arr) {
if (!Array.isArray(arr)) {
return ;
}
let res = [];
arr.forEach(value => {
if (res.indexOf(value) === -1) {
res.push(value);
}
});
return res;
}
// 法二:ES6 Set去重; Array.from(new Set(array))
// 不用考虑兼容性,这种去重的方法代码最少。这种方法还无法去掉"{}"空对象
function unique2(arr) {
// Array.from(arr) 用于将类数组对象转换为数组对象
return Array.from(new Set(arr));
}
// 法三:Object键值对去重;把数组的值存成Object的key值,比如Object[value1] = true,在判断另一个值的时候,如果Object[value2]存在的话,就说明该值是重复的。
function unique3(arr) {
const obj = {};
arr.forEach(value => {obj[value] = true});
return Object.keys(obj);
}
null == undefined ?
比较相等性之前,不能将null和undefined转换成任何值,但要记住null == undefined会返回true
虽然undefined和null的语义和场景不同,但总而言之,它们都表示的是一个无效的值。
ECMAScript规范认为,既然null和undefined的行为很相似,并且都表示一个无效的值,那么它们所表示的内容也具有相似性。
undefined与null区别:目前null和undefined基本是同义的,只有一些细微的差别,null表示没有对象,undefined表示缺少值,就是此处应该有一个值但是还没有定义,因此undefined==null返回false
不要试图通过转换数据类型来解释这个结论,因为:
Number(null); // 0
Number(undefined); // NaN
NaN == 0 //false
但===会返回false,因为全等操作 === 在比较相等性的时候,不会主动转换分项的数据类型,而两者又不属于同一种类型
undefined === null // false,类型不相同
undefined !== null // true
不同的数据类型的值的比较,是怎么转换的,有什么规则
js的全排列
const _permute = arr => {
// 结果集数组
const res = [];
let path = '';
// 调用backTracking函数
// 参数1:需要全排的数组 参数2:数组的长度 参数3:used数组记录当前元素是否已被使用
fullpermutate(arr, arr.length, []);
// 返回最后的结果
return res;
// 递归函数
function fullpermutate(n, k, used) {
// 当获取的元素个数等于传入数组长度时(此时说明找到了一组结果)
if (path.length === k) {
// 将这组数据存进结果集数组
res.push(path);
// 结束递归
return;
}
for (let i = 0; i < k; i++) {
if (used[i]) continue; // 当前元素已被使用, 结束此次循环
path = path + n[i]; // 将符合条件的元素存进path数组
used[i] = true; // 并将该元素标为true,表示已使用同支
fullpermutate(n, k, used);
path = path.substring(0, path.length - 1);
used[i] = false;
}
}
};
console.log(_permute([1, 2, 3, 4]));
编写代码满足以下条件(链式调用)
- Hero(‘37er’);执行结果为: Hi!This is 37er
- Hero(‘37er’).kill(1).recover(30);执行结果为: Hi!This is 37er Kill 1 bug Recover 30 Bloods
- Hero(‘37er’).sleep(10).kill(2);执行结果为:Hi!This is 37er (等待10s后)Kill 2 bugs
function Hero(str) {
this.name = str;
this.time = 0;
console.log(`Hi!This is ${this.name}`);
this.kill = num => {
let killStr = `Kill ${num} bug`;
if (num >= 2) {
killStr += 's';
}
if (this.time) {
const t = setTimeout(() => {
console.log(killStr);
clearTimeout(t);
}, 1000 * this.time);
} else {
console.log(killStr);
}
return this;
}
this.sleep = time => {
this.time = time;
return this;
}
this.recover = recoverNum => {
console.log(`Recover ${recoverNum} Bloods`);
return this;
}
return this;
}
Hero('37er');
Hero('37er').kill(1).recover(30);
Hero('37er').sleep(10).kill(2);
写一个函数,第一秒打印1,第二秒打印2
let块级作用域
for (let i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}
闭包
for (let i = 0; i < 5; i++) {
(function(i) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}(i));
}
对原型链的理解
JavaScript对象都有一个内部的[[Prototype]]属性,也称为原型(prototype),它指向另一个对象或者null。当我们访问一个对象的属性或方法时,如果该对象本身没有这个属性或方法,JavaScript会沿着它的原型链一层层向上查找,直到找到该属性或方法或者原型链到达顶端(即Object.prototype,它是所有对象的祖先)为止。
通过原型链,我们可以实现继承、属性的共享和方法的复用。当我们创建一个对象时,可以通过指定它的原型来继承原型上的属性和方法。在查找属性或方法时,如果对象本身没有这个属性或方法,就可以在其原型上查找。这样可以避免在每个对象上都复制一份相同的属性和方法分,从而节省内存。
需要注意的是,如果在原型链上的某个属性被修改了,那么所有继承自该原型的对象都会受到影响。因此,应该谨慎地修改原型上的属性和方法。另外,通过对象的constructor属性,可以访问到其构造函数,从而可以判断一个对象的类型。
实现寄生组合继承
寄生组合继承是一种继承方式,它通过组合使用构造函数继承和原型继承的方法,实现了高效而且正确的继承方式。具体实现步骤如下:
-
定义父类及其属性和方法
function Person(name) { this.name = name; this.colors = ['red', 'green', 'blue']; } Person.prototype.sayName = function() { consolee.log(this.name); } -
定义一个子类,通过调用父类构造函数,实现属性的继承;
function Child(name, age) { Person.call(this, name); this.age = age; } -
将子类的原型指向一个父类的实例,实现方法的继承并避免父类构造函数被调用多次;
Child.prototype = new Person(); // Child.prototype = Object.create(Person.prototype); Child.prototype.constructor = Child; -
在子类的原型上添加子类自己的方法;
Child.sayAge = funciton() { console.log(this.age); }
完整代码
function Person(name) {
this.name = name;
}
Person.prototype.sayName = funciton() {
console.log(this.name);
}
function Child(name, age) {
Person.call(this, name);
this.age = age;
}
Child.prototype = Object.create(Person.prototype);
Child.prototype.constructor = Child;
Child.prototype.sayAge = function() {
console.log(this.age);
}
let child = new Child('Ami', 22);
child.sayName(); // 'Ami'
child.sayAge(); // 22
map和Object的区别
map和Object都是JavaScript中常用的数据结构,但它们有以下区别:
- 键的类型:Map中的键可以是任意数据类型,包括对象、数组、函数等,而对象中的键必须是字符串或Symbol类型。
- 键值对的顺序:Map中的键值对是按照插入的顺序存储的,而对象中的键值对则没有顺序。
- 大小的获取:Map提供了size属性来获取其大小,而对象则需要手动遍历键值对来获取其大小。
- 原型链:对象中的键值对可能会存在于原型链中,而Map中的键值对则不会受到原型链的影响。
- 迭代器:Map提供了迭代器来遍历其键值对,而对象则需要手动遍历键值对。综上所述,Map相对于对象更加灵活,同时也更加常用于需要存储多个键值对且需要保留插入顺序的场景。
连续多个bind,最后的this指向?
JavaScript中,连续多次调用bind方法,最终函数的this由第一次调用bind方法的参数决定。
const o1 = {a: 1};
const o2 = {a: 2};
const o3 = {a: 3};
function getNum() {
console.log(this.a);
}
const fn = getNum.bind(o1).bind(o2).bind(o3);
fn(); // 1
正向代理和反向代理的区别
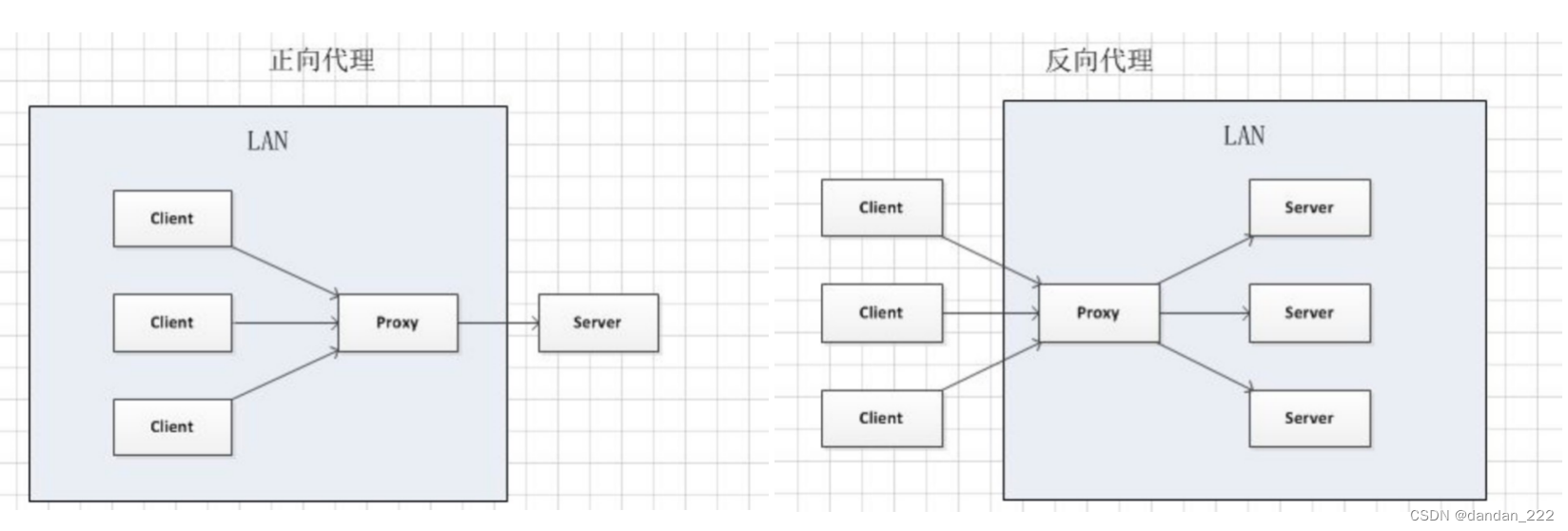
正向代理和反向代理结构一样,都是client-proxy-server,它们主要的区别就是proxy在哪一方设置。
- 正向代理,proxy由client设置,隐藏client
客户端想获取服务器的数据,但是因为很多原因无法直接获取。
于是客户端设置了一个代理服务器,并指定目标服务器,之后代理服务器向目标服务器转交请求并将获取的数据发送给客户端。
本质上起到了对真实服务器隐藏客户端的目的。
实现正向代理需要修改客户端,比如浏览器修改配置。 - 反向代理,proxy由server设置,隐藏server
服务器为了能够将工作负载到多个服务器来提高网站性能(负载均衡)等目的,当其收到请求后,首先根据转发规则来确定请求真实的目标服务器,然后将请求转发到该目标服务器。
本质上起到了对客户端隐藏真实服务器的作用。
一般使用反向代理后,需要修改DNS让域名解析到代理服务器ip,这样浏览器无法得知真正的服务器ip,也就不需要修改浏览器配置。
箭头函数和普通函数的区别?
- 更简洁
() => {} // 无参数,直接写一个空括号
a => {} // 一个参数,可以省略参数的括号
(a, b, c) => {} // 多个参数,括号内逗号分隔
() => 1; ==> () => { return 1; } // 函数体只有一句,并且时return语句,可以省略大括号
() => void fn(); // 函数体不需要返回值,且只有一个一句,可以语句前加void关键字,省略大括号
- 箭头函数无this
箭头函数不会创建自己的this,所以没有自己的this,它只会在自己的父作用域(上一层)中继承this。所以箭头函数的this指向在定义时就确定了,之后不会改变。 - 箭头函数继承来的this指向永远不会改变(call、apply、bind方法也无法改变); 箭头函数不能作为构造函数使用。
var key = 'global';
var obj = {
key: 'obj',
a: function() {
console.log(this.key);
},
b: () => {
console.log(this.key);
}
}
obj.a(); // 'obj'
obj.b(); // 'global'
obj.b.call({key: 'xxx'}); // 'global'
new obj.a(); // undefined
new obj.b(); // Uncaught TypeError: obj.b is not a constructor
- 箭头函数无arguments
箭头函数没有自己的arguments对象。在箭头函数中访问到的arguments实际上是获取了外层函数的arguments。 - 箭头函数没有prototype
- 箭头函数不能用作Generator函数,不能使用yield关键字
promise.all和promise.allsettled区别
- 返回值
- Promise.all的返回值是一个Promise对象,当所有Promise实例都成功时,返回Promise对象的状态为fulfilled,其结果是一个包含所有实例结果的数组;当有一个Promise实例失败时,返回的Promise对象的状态为rejected,其结果是一个包含所有实例执行结果的数组,数组中的每个元素都是一个对象,包含该Promise实例的状态和结果信息。
- Promise.allSettled的返回值也是一个Promise对象,其结果是一个包含所有Promise实例执行结果的数组,数组中的每个元素都是一个对象,包含该Promise实例的状态和结果信息。
- 处理方式
- Promise.all在所以Promise实例都被resolved或者有一个Promise实例被rejected时,会立即终止其他Promise实例的执行,即也可能存在一些Promise实例没有充分利用。
- Promise.allSettled会等到所有Promise实例都执行完毕后才返回结果,可以充分利用每个Promise实例的执行结果。
因此,当需要同时执行多个Promise实例。且需要在所有实例都执行完毕后再进行处理时,应该所以Promise.allSettled;当需要在多个Promise实例中只有有一个被rejected就终止执行,并且只需要返回成功实例的结果时,应该使用Promise.all。
substring和substr的区别
两个方法都是截取字符串,参数用法不同:
- substring(start, end) 截取两个索引间的字符
- start:需要截取的第一个字符的索引,返回字符串的首字母位置
- end:可选。0 - 字符串长度间的整数,不包含结束位置的字符
- substr(start, length)
- start: 提取字符的位置。允许为负值,str.length + start,其中str.length为字符串的长度(例如start为-1, str.length + (-1),则是字符串的最后一个)
- length: 可选。需要提取的字符数。
Symbol的作用和使用场景
ES6中引入的新数据类型,它表示一个唯一的常量,通过Symbol函数来创建对应的数据类型,创建时可以添加变量描述,该变量描述在传入时会被强行转换成字符串进行存储:Symbol属性类型比较适合用于两类场景:常量值和对象属性。
let a = Symbol('1');
let b = Symbol(1);
a.description === b.description // true;
let c = Symbol({id: 1});
c.description // [object Object]
let d = Symbol('1');
d === a // false
- 避免常量值重复
function getValue(key) {
switch(key) {
case 'A':
...
case 'B':
...
}
}
getValue('B');
这段代码对调用者很不友好,因为代码中使用了魔术字符串(Magic String,指代码中多次出现、与代码形成强耦合的某一个具体的字符串或者数值),导致调用getValue函数时需要查看函数代码才能找到参数key的可选值。所以可以将参数key的值以常量的方式声明:
const KEY = {
a: 'A',
b: 'B'
}
function getValue(key) {
switch(key) {
case KEY.a:
...
case KEY.b:
...
}
}
getValue(KEY.a);
但这样还是会出现在KEY常量中加入一个key,对应的值与其他key重复的情况:
const KEY = {
a: 'A',
b: 'B',
c: 'B'
}
getValue(KEY.b) === getValue(KEY.c) // true
// 在这种场景下更适合用Symbol,因为不需要关心值本身,只关心值的唯一性
const KEY = {
a: Symbol(),
b: Symbol(),
c: Symbol(),
}
- 避免对象属性覆盖
函数fn需要传入的对象参数添加一个临时属性user,但是可能对象中已经有这个属性了,如果直接赋值就会覆盖之前的值。此时就可以使用Symbol来避免这个问题。创建一个Symbol数据类型的变量,然后将该变量作为对象参数的属性进行赋值和读取,这样就能避免覆盖的情况:
function fn(obj) {
const symbol = Symbol();
obj[symbol] = 'zzz';
}
使用需要注意:
- symbol生成的值作为属性或者方法的时候,一定要保存下来,否则后续无法使用
- for循环遍历对象的时候是无法遍历出symbol的属性和方法的
Object.getOwnPropertySymbols() // 可以单独取出Symbol
- 不能做任何运算
- 类型转化的时候不可转化为数值
- 后面括号可以传入一个字符串,只是一个标记,方便我们阅读,没有任何意义
- 无法作为构造函数使用,无法new
typeof和instanceof的区别
typeof与instanceof都是判断数据来下的方法,区别主要有两点:
- 返回值不同
typeof返回一个运算符的基本类型
instanceof返回布尔值 - 可以判断的数据类型不同
instanceof可以准确判断引用数据类型,但是不能正确判断原始数据类型
typeof虽然key判断元素数据类型(null除外),但是无法判断引用数据类型(function除外)
for in 和for of区别
for of ES6新增,可以用来遍历数组、类数组对象、字符串、Set、Map以及Generator对象
for in ES3,为了遍历对象而生
主要区别:
- 获取值不同
for of遍历获取对象的键值
for in获取对象的键名 - 是否遍历原型链
for in会遍历对象的整个原型链,性能非常差
for of只遍历当前对象不会遍历原型链 - 遍历返回值不同
对于数组的遍历而言,
for in会返回数组中所有可枚举的属性(包括原型链上可枚举的属性)
for of只返回数组下标对应的属性值
map和forEach是否可以通过break跳出?
均无法使用,但是可以通过抛出Error,用try catch去捕获错误,从而终止循环。
const list = [1, 2, 3, 4, 5];
try {
list.map(item => {
if (item === 3) {
throw new Error();
}
console.log(item);
});
} catch(e) {
console.log(e);
}
try {
list.forEach(item => {
if (item === 3) {
throw new Error();
}
console.log(item);
});
} catch(e) {
console.log(e);
}
0.1+0.2不等于0.3?
计算机通过二进制的方式存储数据
0.1的二进制是0.0001100110011001100…(1100循环)
0.2的二进制是0.00110011001100…(1100循环)
JavaScript如何处理无限循环二进制小数
遵循IEEE 754标准,使用64位固定长度来表示,也就是标准的double双精度浮点数。
在二进制科学表示法中,双精度浮点数的小数部分最多只能保留52位,再加上前面的1,其实就是保留53位有效数字,剩余的要舍去,遵从「0舍1入」原则。
所以0.1和0.2的二进制数相加转换为十进制就是:0.30000000000000004
requestAnimationFrame和requestIdleCallback?
都是浏览器提供的用于在下一次浏览器重绘之前执行指定函数的方法,它们的作用类似。
- requestAnimationFrame
告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。回调函数执行次数通常是每秒 60 次,但在大多数遵循 W3C 建议的浏览器中,回调函数执行次数通常与浏览器屏幕刷新次数相匹配。
示例
const element = document.getElementById('some-animate');
let start, previousTimeStamp;
let done = false;
function step(timeStamp) {
if (start === undefined) {
start = timeStamp;
}
const elapsed = timeStamp - start;
if (previousTimeStamp !== timeStamp) {
// 这里使用 Math.min() 确保元素在恰好位于 200px 时停止运动
const count = Math.min(0.1 * elapsed, 200);
element.style.transform = `translate(${count}px)`;
if (count === 200) {
done = true;
}
}
if (elapsed < 2000) {
previousTimeStamp = timeStamp;
if (!done) {
window.requestAnimationFrame(step);
}
}
}
window.requestAnimationFrame(step);
- requestIdleCallback
方法插入一个函数,这个函数将在浏览器空闲时期被调用。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。
requestIdleCallback(callback, options)
// options可选
// { timeout:如果指定了 timeout,并且有一个正值,而回调在 timeout 毫秒过后还没有被调用,那么回调任务将放入事件循环中排队强制执行,即使这样做有可能对性能产生负面影响。 }
callback函数接受deadline对象作为参数
deadline对象有两个属性:
timeRemaining() 返回当前帧还剩余的毫秒数
didTimeout指定的事件是否过期
示例
function sleep(duration) {
const time = new Date().getTime();
while (new Date().getTime() - time < duration) {}
}
const taskList = [
function () {
console.log("开始执行任务 1");
sleep(30);
console.log("已经完成任务 1");
},
function () {
console.log("开始执行任务 2");
sleep(30);
console.log("已经完成任务 2");
},
function () {
console.log("开始执行任务 3");
sleep(50);
console.log("已经完成任务 3");
}
];
function lowWork(deadline) {
while((deadline.timeRemaining() > 0 || deadline.didTimeout) && taskList.length > 0) {
console.log("本帧还剩余:" + deadline.timeRemaining() + "ms", deadline.didTimeout);
doSomeWork();
}
if (taskList.length > 0) {
window.requestIdleCallback(lowWork);
}
function doSomeWork() {
const task = taskList.shift();
task();
}
}
window.requestIdleCallback(lowWork);
区别:
4. 回调函数执行时机
- requestAnimationFrame的回调函数在下一次浏览器重绘之前执行,通常为每秒60次(60fps);
- requestIdleCallback的回调函数在浏览器空闲时执行,即浏览器没有其它任务执行时,通常为每秒几次(取决于浏览器)。
- 回调函数的参数
- requestAnimationFrame的回调函数会被传入一个时间戳参数,表示当前帧开始渲染的时间;
- requestIdleCallback的回调函数会传入一个IdleDeadline对象,包含了当前空闲时间的一下信息。
总结:
需要在下一次浏览器重绘之前执行某些操作时,使用requestAnimationFrame;
需要在浏览器空闲时间执行一些较为耗时的操作时,使用requestIdleCallback,该方法需要注意的是,其回调函数可能会在多次空闲时间内执行,因此应该根据实际情况合理地控制回调函数的执行次数和执行时间,以避免占用过多的浏览器资源;
这两个方法可以避免造成页面卡顿或阻塞,提高用户体验。
mouseover 和 mouseenter
- 触发条件不同
mouseover:在鼠标指针进入元素或元素的子元素时触发,即当鼠标指针从元素外部移入元素边界内时触发;
mouseenter:只在鼠标指针进入元素时触发,进入元素的子元素不会再次触发。 - 事件冒泡不同
mouseover:会冒泡,鼠标从子元素移出到父元素也会触发。
mouseenter:不会冒泡,只在进入元素时触发。
总结:
需要鼠标指针进入元素或其子元素时都触发事件时,使用mouseover;
需要只在鼠标指针进入元素时触发事件时,使用mouseenter,但是由于mouseenter不会冒泡,因此可能存在子元素上触发了mouseenter,但父元素上并没有触发的情况。
















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









