







首先来了解下什么是朴素贝叶斯。。。
http://zh.wikipedia.org/wiki/%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%88%86%E7%B1%BB%E5%99%A8
来使用贝叶斯学习文本分类据说是目前最好的算法之一,现在拿一个例子来详细说明:
这里是用来过滤网上留言板的内容,分为辱骂的和同情的两类,首先会创建一系列的样本用来学习,然后会根据学习得到的概率来预测现在得到的留言的类别。
详细的介绍可以参考维基百科。
在应用朴素贝叶斯分类时的两个主要问题是
(1)决定怎么将任意文档表示为属性值的形式
(2)其次要决定如何估计朴素贝叶斯分类器需要的概率
针对第一个问题,可以用文档内的每一个单词来表示属性,例如:
'my dog has flea problems help please'
可以表示为'my', 'dog', 'has', 'flea', 'problems', 'help', 'please'这7个属性
文本可以被一些单词集标注,而这个单词集是独立分布的,在给定的C类文本中第i个单词出现的概率可以表示为:
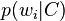
对于一个给定类别C,单词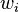 的文本D,概率表示为
的文本D,概率表示为
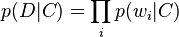
我们要回答的问题是文档D属于类C的概率是多少,即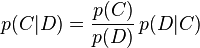
问题大致就是这样,我们需要用python来实现
第一步创建数据集
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec返回的是数据和类别
第二步收集Examples中所有单词,标点符号以及其他记号,这里为了简单只有单词
def createVocabList(dataset):
vocabSet = set([])
for document in dataset:
#print set(document)
vocabSet = vocabSet | set(document)
return list(vocabSet)这里是收集了数据集中所有的单词,用到了python中的set
第三步,把输入数据转为0,1代表了我们得到的所有单词是否出现在输入集中
def setOfWord2Vec(vocablist,inputset):
returnVec = [0] * len(vocablist)
for word in inputset:
if word in vocablist:
returnVec[vocablist.index(word)] = 1
else :
print " the word: %s is not in my vocabulary" % word
return returnVec这里主要是为了计算后面的概率方便而转化的,后面会用到
第四步:计算概率
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory) / float(numTrainDocs)
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Denom += sum(trainMatrix[i])
p0Num += trainMatrix[i]
p1Vect =log(p1Num / p1Denom)
p0Vect =log(p0Num / p0Denom)
return p0Vect,p1Vect,pAbusive首先初始化p(wi|c1)和p(wi|c0)的分子和分母
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0接下来就是判断整条消息属于某个类别的概率,就要计算p(w0|1)p(w1|1)p(w2|1)的形式,这里对代码把握的还是不到位,先搁浅,明天再好好研究下
第五步:进行分类
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify*p1Vec) + log(pClass1)
p0 = sum(vec2Classify*p0Vec) + log(1.0-pClass1)
if p1 > p0:
return 1
else:
return 0def testingNB():
listOPost,listClass = loadDataSet()
myvocablist = createVocabList(listOPost)
# print myvocablist
# print setOfWord2Vec(myvocablist,listOPost[0])
# print setOfWord2Vec(myvocablist,listOPost[3])
tainMat = []
for postinDoc in listOPost:
tainMat.append(setOfWord2Vec(myvocablist,postinDoc))
print tainMat
print listClass
p0V,p1V,pAb = trainNB0(array(tainMat),array(listClass))
testEntry = ['love','my','dalmation']
thisDoc = array(setOfWord2Vec(myvocablist,testEntry))
print testEntry,'classifide as ',classifyNB(thisDoc,p0V,p1V,pAb)暂时写到这里明天继续
参考文献:
machine learning in action
机器学习 Tom M.Mitchell,曾华军,张银奎等译















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









