







关于mysql的分区理论这里不做过多解释,下面来实际操作,由于mysql的分区技术是从mysql5.1以后才出现的,所以要保证mysql的版本要在5.1以上,这里我使用的是mysql5.1.60版本,操作系统是linux系统。
首先登录mysql服务器,使用show plugins来查看是否支持分区技术
mysql> show plugins;
+------------+--------+----------------+---------+---------+
| Name | Status | Type | Library | License |
+------------+--------+----------------+---------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| SPHINX | ACTIVE | STORAGE ENGINE | NULL | GPL |
+------------+--------+----------------+---------+---------+
8 rows in set (0.00 sec)
当我们看到partition选项的status属性为active时,就说明数据库是支持分区的。
下面创建一张表
create table t1(id int) egngine=myisam;查看mysql的数据文件,在test文件夹下,我们可以看到有三个文件,一个结构文件,一个数据文件,一个索引文件
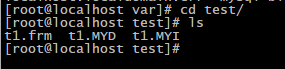
下面我们继续创建一张t2表,并采用HSAH分区来进行创建
create table t2(
id int
)
engine=myisam
partition by hash(id)
partitions 4;下面看一下test文件下会发生什么变化
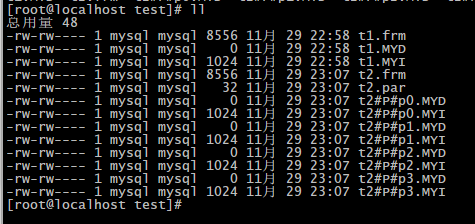
test下除了t1表的三个文件外,还多了t2表的10个文件:.frm文件是结构文件,.par文件说明是采用分区,其他的8个文件则是分区产生的数据文件和索引文件。
上面我们看到了一般表和分区表的表结构的不同,下面我们再来看一下分区表查询时的优势所在。
下面我们新建2张表,一张非分区表,一张分区表;
create table no_part_tab(
c1 int default null,
c2 varchar(30) default null ,
c3 date default null
)engine=myisam;分区表:
create table part_tab(
c1 int default null,
c2 varchar(30) default null ,
c3 date default null
)engine=myisam
partition by range(year(c3))(
partition p0 values less than(1997),
partition p1 values less than(1998),
partition p2 values less than(1999),
partition p3 values less than(2000),
partition p4 values less than(2001),
partition p5 values less than(2002),
partition p6 values less than maxvalue
);下面往分区表中插入数据
delimiter $
create procedure load_data()
begin
declare v int default 0;
while v<6000000
do
insert into part_tab
values
(v,"test partition",adddate('1995-01-01',(rand(v)*36520) mod 3652));
set v=v+1;
end while;
end$
delimiter ;
call load_data();这里写了一个存储,往分区表中插入了600万行数据进行测试
接着向no_part_tab插入同样的数据
insert into no_part_tab select * from part_tab;查看一下表格,
mysql> select count(*) from part_tab;
+----------+
| count(*) |
+----------+
| 6000000 |
+----------+
1 row in set (0.13 sec)
mysql> select count(*) from no_part_tab;
+----------+
| count(*) |
+----------+
| 6000000 |
+----------+
1 row in set (0.01 sec)
下面我们来查询一下这两张表,做一下测试,现在,2张表都没有加索引
先来查询part_tab表
mysql> select count(*) from part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31';
+----------+
| count(*) |
+----------+
| 598029 |
+----------+
1 row in set (0.66 sec)
下面是no_part_tab表
mysql> select count(*) from no_part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31';
+----------+
| count(*) |
+----------+
| 598029 |
+----------+
1 row in set (5.62 sec)
我们能够明显的发现,2次查询的差距还是比较大的,下面,我们来解析一下这两条sql
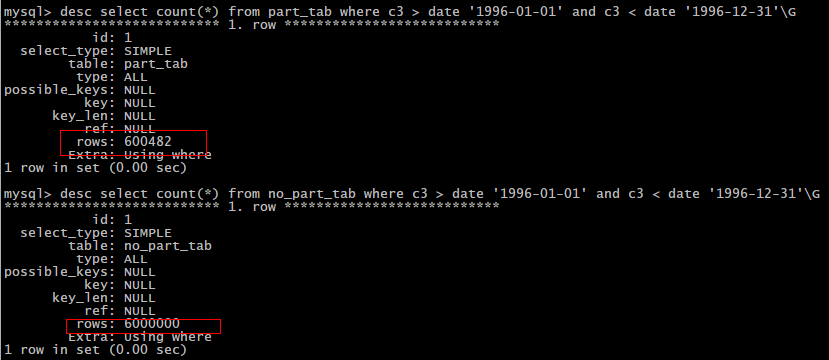
通过desc我们可以知道两者查询差距的原因,那么为什么查询分区表的时候搜索的行数少呢,那是因为我们的1997-01-01到1991-12-12的数据就存储在p0分区内,所以只要搜索p0分区即可,大大减少了搜索所需的时间
下面我们为2张表添加索引
alter table part_tab add index in_c3(c3);
alter table no_part_tab add index in_c3(c3);创建索引的时间较长,下面我们继续进行上面的操作,看看现在查询的结果是什么
mysql> select count(*) from part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31';
+----------+
| count(*) |
+----------+
| 598029 |
+----------+
1 row in set (1.02 sec)
下面是no_part_tab表
mysql> select count(*) from no_part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31';
+----------+
| count(*) |
+----------+
| 598029 |
+----------+
1 row in set (0.98 sec)
我们发现2者是相差无几的,甚至未分区表还要快一点,这是又是分区表的索引是分表建立的,有7个分区就有7个索引文件,所以查询的时候就会比查询一个索引文件的要慢一点
下面我们用desc来查看一下
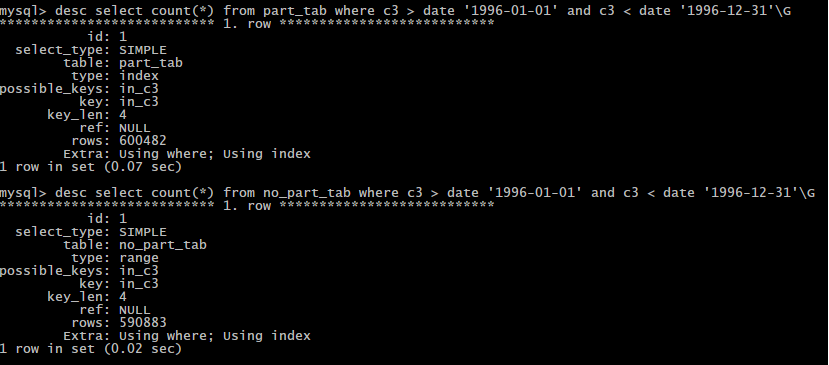
我们可以发现,未分区表的查询rows要略少于分区表的rows,这也是未分区表略快的原因
下面我们增加一个未索引字段来查询
mysql> select count(*) from part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31' and c2="he
llo";
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.61 sec)
mysql> select count(*) from no_part_tab where c3 > date '1996-01-01' and c3 < date '1996-12-31' and c2="hello";
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (4.94 sec)
我们发现未分区表的查询速度明显慢了,这是由于part_tab只查询的60多行,而no_part_tab查询了600万行,差距是明显的
这样我们的mysql分区实验就完成了















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









