







当我们需要备份数据库时,需要导出数据,我们一般是使用mysqldump命令来进行数据的导出,下面我们先来试验一下,
首先创建一张表
CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8创建t1表,只有一个字段,往数据表中插入几行数据
insert into t1 values(1),(2),(3);然后开始备份

可以看到已经导出的数据
下面这样我们就备份完毕了,我们可以查看一下test.sql
--
-- Table structure for table `t1`
--
DROP TABLE IF EXISTS `t1`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `t1`
--
LOCK TABLES `t1` WRITE;
/*!40000 ALTER TABLE `t1` DISABLE KEYS */;
INSERT INTO `t1` VALUES (1),(2),(3);
/*!40000 ALTER TABLE `t1` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
这只是一部分,我们可以看到里面有一大堆表结构的语句和表创建的语句,当我们的数据量非常大的时候,导出的速度就可想而知,于是我们就需要在导出的时候避开这些语句,这里就要用到load的infile和outfile来导入导出数据
我们先来看下outfile的语法
Syntax:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
下面举个例子
select * from t1 into outfile "/tmp/test.sql"这样就可以把t1表的所有列都导出来,当然,也可以只导出某一列的数据
这是导出,下面看下导入
导入要用到我们的load data来实现,看下语法
Syntax:
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...]
同样的一个例子来说明
load data infile "/tmp/test.sql" into table t1
load data infile "/tmp/test.sql" into table t1(id)下面进行一下实际操作,在t1表中插入1000万行数据
mysql> select count(*) from t1;
+----------+
| count(*) |
+----------+
| 10485760 |
+----------+
1 row in set (0.00 sec)
下面来导出数据
mysql> select * from t1 into outfile "/tmp/outfile.sql";
Query OK, 10485760 rows affected (2.43 sec)
发现导出的速度非常快,1000万行数据只需要2秒多
下面看一下outfile.sql中的数据是什么样子的
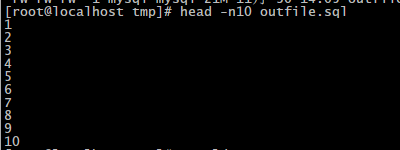
我们发现,文件中只有数据,而不存在表的结构和其他不相干的语句,这样就大大减少了导出数据的量
下面来导入数据,这里需要注意的是,有outfile导出的数据不包含表结构,所以,我们不能够删除表或者数据库来进行操作
下面我们清空一下t1表,进行一下操作
mysql> truncate t1;
Query OK, 0 rows affected (0.12 sec)
mysql> select count(*) from t1;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
下面使用load data infile来导入
mysql> load data infile "/tmp/outfile.sql" into table t1;
Query OK, 10485760 rows affected (12.46 sec)
Records: 10485760 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select count(*) from t1;
+----------+
| count(*) |
+----------+
| 10485760 |
+----------+
1 row in set (0.00 sec)
发现导入的速度也是不慢的
下面为了对比一下mysqldump的导出,来用mysqldump进行一下操作

对比一下outfile,mysqldump导出花费了大约12秒,大概是outfile的5倍左右
下面看一下这两个文件的大小

可以看到mysqldump导出的数据是outfile的2倍,这也就说明了outfile的优势所在。
因此,当有海量数据时,使用outfile和load data infile的速度会更快,消耗的资源更少。















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









