





以前,我们设置了Scala应用程序 ,以便在hadoop上执行简单的字数统计。
接下来是将我们的应用程序上载到HDInsight。
因此,我们将继续在HDInsight上创建Hadoop集群。 
然后,我们将创建hadoop集群。
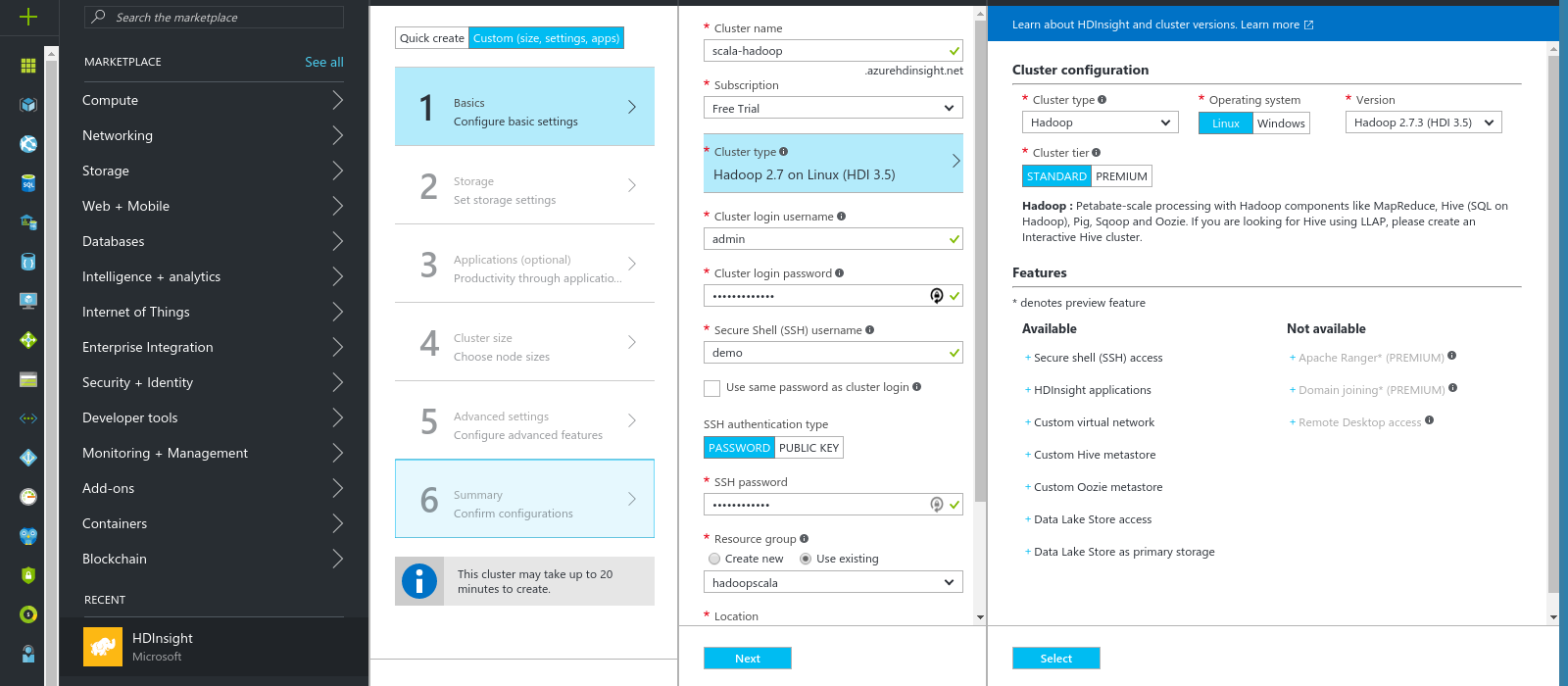
如您所见,我们指定了管理控制台凭据和ssh用户来登录头节点。
我们的hadoop集群将由一个Azure存储帐户提供支持。
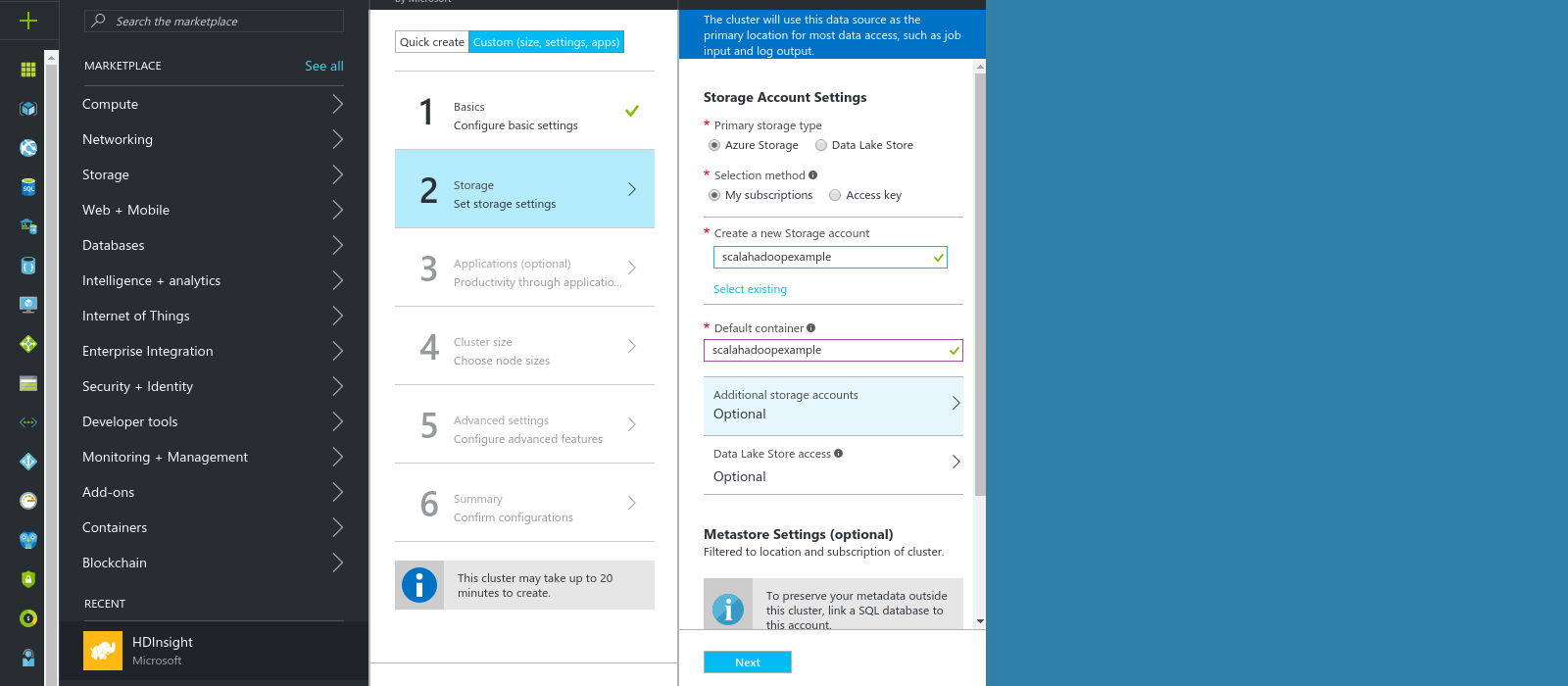
然后是时候将我们的文本文件上传到Azure存储帐户了。
有关使用azure cli管理存储帐户的更多信息,请查看官方指南 。 任何文本文件都可以。
azure storage blob upload mytext.txt scalahadoopexample example/data/input.txt现在我们可以使用ssh到我们的Hadoop节点。
首先,我们运行HInsight hadoop集群随附的示例。
hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar wordcount /example/data/input.txt /example/data/results检查结果
hdfs dfs -text /example/data/results/part-r-00000然后我们准备将scala代码scp到我们的hadoop节点并以wordcount的形式发布。
hadoop jar ScalaHadoop-assembly-1.0.jar /example/data/input.txt /example/data/results2并再次检查结果
hdfs dfs -text /example/data/results2/part-r-00000而已! HDinsight使它变得非常简单!
翻译自: https://www.javacodegeeks.com/2017/02/run-scala-implemented-hadoop-jobs-hdinsight.html















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









