





编者注:不要错过有关如何使用Apache Spark创建数据管道应用程序的新的免费按需培训课程-在此处了解更多信息。
这篇文章将帮助您开始在MapR沙盒上将Apache Spark GraphX和Scala一起使用。 GraphX是用于图并行计算的Apache Spark组件,它建立在称为图论的数学分支上。 它是一个位于Spark核心之上的分布式图形处理框架。
一些图形概念概述
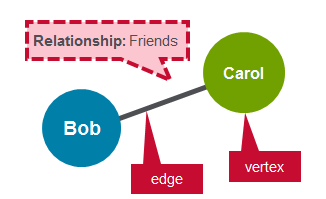
图形是用于对对象之间的关系进行建模的数学结构。 图由连接它们的顶点和边组成。 顶点是对象,边缘是它们之间的关系。
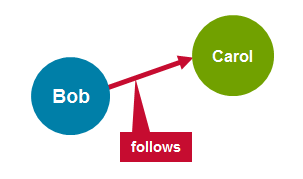
有向图是边缘具有与之关联的方向的图。 有向图的一个示例是Twitter关注者。 用户Bob可以跟随用户Carol,而并不意味着用户Carol跟随用户Bob。
正则图是每个顶点具有相同数量边的图。 常规图的一个示例是Facebook朋友。 如果Bob是Carol的朋友,那么Carol也是Bob的朋友。
GraphX属性图
GraphX通过弹性分布式属性图扩展了Spark RDD。
属性图是有向多重图,可以有多个平行的边。 每个边和顶点都有与之关联的用户定义的属性。 平行边允许相同顶点之间存在多种关系。
在本活动中,您将使用GraphX分析航班数据。
情境
作为简单的开始示例,我们将分析三个航班。 对于每个航班,我们都有以下信息:
| 始发机场 | 目的地机场 | 距离 |
| 财务总监 | ORD | 1800英里 |
| ORD | DFW> | 800英里 |
| DFW | SFO> | 1400英里 |
在这种情况下,我们将机场表示为顶点,将路线表示为边。 对于我们的图形,我们将有三个顶点,每个顶点代表一个机场。 机场之间的距离是一个路线属性,如下所示: 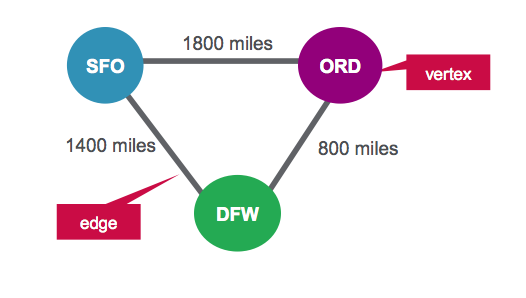
机场顶点表
| ID | 属性 |
| 1个 | 财务总监 |
| 2 | ORD |
| 3 | DFW |
路线边表
| SrcId | 目的地编号 | 属性 |
| 1个 | 2 | 1800 |
| 2 | 3 | 800 |
| 3 | 1个 | 1400 |
软件
本教程将在包含Spark的MapR沙盒上运行。
- 您可以从此处下载代码和数据以运行这些示例:
- 使用spark-shell命令启动后,本文中的示例可以在Spark shell中运行。
- 您还可以按照独立的应用程序运行代码,如MapR Sandbox上的Spark入门教程中所述。
启动Spark Interactive Shell
如使用Mapr Sandbox上的Spark入门所述 ,使用密码为userid user01的用户登录到MapR Sandbox。 使用以下命令启动Spark Shell:
$ spark-shell定义顶点
首先,我们将导入GraphX包。
(在代码框中,注释为绿色,输出为蓝色)
import org.apache.spark._
import org.apache.spark.rdd.RDD
// import classes required for using GraphX
import org.apache.spark.graphx._我们将机场定义为顶点。 顶点具有ID,并且可以具有与之关联的属性或属性。 每个顶点包括:
- 顶点ID→ID(长)
- 顶点属性→名称(字符串)
机场顶点表
| ID | 物产(V) |
| 1个 | 财务总监 |
我们定义具有以上属性的RDD,然后将其用于顶点。
// create vertices RDD with ID and Name
val vertices=Array((1L, ("SFO")),(2L, ("ORD")),(3L,("DFW")))
val vRDD= sc.parallelize(vertices)
vRDD.take(1)
// Array((1,SFO))
// Defining a default vertex called nowhere
val nowhere = "nowhere"定义边
边缘是机场之间的路线。 边必须具有源,目的地并且可以具有属性。 在我们的示例中,边包括:
- 边缘原点ID→src(长)
- 边缘目标ID→目标(长)
- 边属性距离→距离(长)
路线边表
| srcid | 目的地 | 物业(E) |
| 1个 | 12 | 1800 |
我们定义具有以上属性的RDD,然后将其用于边缘。 边缘RDD的格式为(src id,dest id,distance)。
// create routes RDD with srcid, destid, distance
val edges = Array(Edge(1L,2L,1800),Edge(2L,3L,800),Edge(3L,1L,1400))
val eRDD= sc.parallelize(edges)
eRDD.take(2)
// Array(Edge(1,2,1800), Edge(2,3,800))创建属性图
要创建图形,您需要具有一个顶点RDD,边缘RDD和一个默认顶点。
创建一个称为图的属性图。
// define the graph
val graph = Graph(vRDD,eRDD, nowhere)
// graph vertices
graph.vertices.collect.foreach(println)
// (2,ORD)
// (1,SFO)
// (3,DFW)
// graph edges
graph.edges.collect.foreach(println)
// Edge(1,2,1800)
// Edge(2,3,800)
// Edge(3,1,1400)1.那里有几个机场?
// How many airports?
val numairports = graph.numVertices
// Long = 32.有几条路线?
// How many routes?
val numroutes = graph.numEdges
// Long = 33.哪些路线> 1000英里的距离?
// routes > 1000 miles distance?
graph.edges.filter { case Edge(src, dst, prop) => prop > 1000 }.collect.foreach(println)
// Edge(1,2,1800)
// Edge(3,1,1400)4. EdgeTriplet类通过添加分别包含源和目标属性的srcAttr和dstAttr成员来扩展Edge类。
// triplets
graph.triplets.take(3).foreach(println)
((1,SFO),(2,ORD),1800)
((2,ORD),(3,DFW),800)
((3,DFW),(1,SFO),1400)5.排序并打印出最长的路线
// print out longest routes
graph.triplets.sortBy(_.attr, ascending=false).map(triplet =>
"Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").collect.foreach(println)
Distance 1800 from SFO to ORD.
Distance 1400 from DFW to SFO.
Distance 800 from ORD to DFW.使用GraphX分析实际飞行数据
情境
我们的数据来自http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time 。 我们正在使用2015年1月的航班信息。对于每个航班,我们都有以下信息:
| 领域 | 描述 | 示例值 |
| dOfM(String) | 一个月中的某天 | 1个 |
| dOfW(字符串) | 星期几 | 4 |
| 载体(字符串) | 运营商代码 | 机管局 |
| tailNum(String) | 飞机的唯一标识符-尾号 | N787AA |
| flnum(Int) | 航班号 | 21 |
| org_id(字符串) | 始发机场ID | 12478 |
| origin(字符串) | 始发机场代码 | 肯尼迪 |
| dest_id(字符串) | 目的地机场编号 | 12892 |
| dest(字符串) | 目的地机场代码 | 洛杉矶国际机场 |
| crsdeptime(Double) | 预定出发时间 | 900 |
| deptime(双精度) | 实际出发时间 | 855 |
| depdelaymins(Double) | 出发延迟分钟 | 0 |
| crsarrtime(双精度) | 预定到达时间 | 1230 |
| arrtime(双人) | 实际到达时间 | 1237 |
| arrdelaymins(双人间) | 到达延迟分钟 | 7 |
| crselapsedtime(双精度) | 经过时间 | 390 |
| dist(Int) | 距离 | 2475 |
在这种情况下,我们将机场表示为顶点,将路线表示为边。 我们对可视化机场和航线感兴趣,并希望了解有出发或到达的机场的数量。
- 您可以从此处下载代码和数据以运行这些示例: https : //github.com/caroljmcdonald/sparkgraphxexample
如使用Mapr Sandbox上的Spark入门所述 ,使用密码为userid user01的用户登录到MapR Sandbox。 使用scp将样本数据文件rita2014jan.csv复制到沙箱主目录/ user / user01。
使用以下命令启动Spark shell:
$ spark-shell定义顶点
首先,我们将导入GraphX包。
(在代码框中,注释为绿色,输出为蓝色)
import org.apache.spark._
import org.apache.spark.rdd.RDD
import org.apache.spark.util.IntParam
// import classes required for using GraphX
import org.apache.spark.graphx._
import org.apache.spark.graphx.util.GraphGenerators下面我们使用Scala案例类来定义与csv数据文件相对应的飞行模式。
// define the Flight Schema
case class Flight(dofM:String, dofW:String, carrier:String, tailnum:String, flnum:Int, org_id:Long, origin:String, dest_id:Long, dest:String, crsdeptime:Double, deptime:Double, depdelaymins:Double, crsarrtime:Double, arrtime:Double, arrdelay:Double,crselapsedtime:Double,dist:Int)下面的函数将数据文件中的一行解析为Flight类。
// function to parse input into Flight class
def parseFlight(str: String): Flight = {
val line = str.split(",")
Flight(line(0), line(1), line(2), line(3), line(4).toInt, line(5).toLong, line(6), line(7).toLong, line(8), line(9).toDouble, line(10).toDouble, line(11).toDouble, line(12).toDouble, line(13).toDouble, line(14).toDouble, line(15).toDouble, line(16).toInt)
}下面,我们将csv文件中的数据加载到弹性分布式数据集(RDD)中 。 RDD可以具有转换和动作 ,first()动作返回RDD中的第一个元素。
// load the data into a RDD
val textRDD = sc.textFile("/user/user01/data/rita2014jan.csv")
// MapPartitionsRDD[1] at textFile
// parse the RDD of csv lines into an RDD of flight classes
val flightsRDD = textRDD.map(parseFlight).cache()我们将机场定义为顶点。 顶点可以具有与之关联的属性。 每个顶点具有以下属性:
- 机场名称(字符串)
机场顶点表
| ID | 物产(V) |
| 10397 | ATL |
我们定义具有以上属性的RDD,然后将其用于顶点。
// create airports RDD with ID and Name
val airports = flightsRDD.map(flight => (flight.org_id, flight.origin)).distinct
airports.take(1)
// Array((14057,PDX))
// Defining a default vertex called nowhere
val nowhere = "nowhere"
// Map airport ID to the 3-letter code to use for printlns
val airportMap = airports.map { case ((org_id), name) => (org_id -> name) }.collect.toList.toMap
// Map(13024 -> LMT, 10785 -> BTV,…)定义边
边缘是机场之间的路线。 边必须具有源,目的地并且可以具有属性。 在我们的示例中,边包括:
- 边缘原点ID→src(长)
- 边缘目标ID→目标(长)
- 边缘属性距离→距离(长)
路线边表
| srcid | 目的地 | 物业(E) |
| 14869 | 14683 | 1087 |
我们定义具有以上属性的RDD,然后将其用于边缘。 边缘RDD具有以下形式(src id,dest id,distance)。
// create routes RDD with srcid, destid, distance
val routes = flightsRDD.map(flight => ((flight.org_id, flight.dest_id), flight.dist)).distinctdistinct
routes.take(2)
// Array(((14869,14683),1087), ((14683,14771),1482))
// create edges RDD with srcid, destid , distance
val edges = routes.map {
case ((org_id, dest_id), distance) =>Edge(org_id.toLong, dest_id.toLong, distance) }
edges.take(1)
//Array(Edge(10299,10926,160))创建属性图
要创建图形,您需要具有一个顶点RDD,边缘RDD和一个默认顶点。
创建一个称为图的属性图。
// define the graph
val graph = Graph(airports, edges, nowhere)
// graph vertices
graph.vertices.take(2)
Array((10208,AGS), (10268,ALO))
// graph edges
graph.edges.take(2)
Array(Edge(10135,10397,692), Edge(10135,13930,654))6.那有几个机场?
// How many airports?
val numairports = graph.numVertices
// Long = 3017.有几条路线?
// How many airports?
val numroutes = graph.numEdges
// Long = 40908.哪些路线的距离> 1000英里?
// routes > 1000 miles distance?
graph.edges.filter { case ( Edge(org_id, dest_id,distance))=> distance > 1000}.take(3)
// Array(Edge(10140,10397,1269), Edge(10140,10821,1670), Edge(10140,12264,1628))9. EdgeTriplet类通过添加分别包含源和目标属性的srcAttr和dstAttr成员来扩展edge类。
// triplets
graph.triplets.take(3).foreach(println)
((10135,ABE),(10397,ATL),692)
((10135,ABE),(13930,ORD),654)
((10140,ABQ),(10397,ATL),1269)10.排序并打印出最长的路线
// print out longest routes
graph.triplets.sortBy(_.attr, ascending=false).map(triplet =>
"Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").take(10).foreach(println)
Distance 4983 from JFK to HNL.
Distance 4983 from HNL to JFK.
Distance 4963 from EWR to HNL.
Distance 4963 from HNL to EWR.
Distance 4817 from HNL to IAD.
Distance 4817 from IAD to HNL.
Distance 4502 from ATL to HNL.
Distance 4502 from HNL to ATL.
Distance 4243 from HNL to ORD.
Distance 4243 from ORD to HNL.11.计算最高度顶点
// Define a reduce operation to compute the highest degree vertex
def max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = {
if (a._2 > b._2) a else b
}
val maxInDegree: (VertexId, Int) = graph.inDegrees.reduce(max)
//maxInDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,152)
val maxOutDegree: (VertexId, Int) = graph.outDegrees.reduce(max)
//maxOutDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,153)
val maxDegrees: (VertexId, Int) = graph.degrees.reduce(max)
//maxDegrees: (org.apache.spark.graphx.VertexId, Int) = (10397,305)
// Get the name for the airport with id 10397
airportMap(10397)
//res70: String = ATL12.哪个机场的来回航班最多?
// get top 3
val maxIncoming = graph.inDegrees.collect.sortWith(_._2 > _._2).map(x => (airportMap(x._1), x._2)).take(3)
maxIncoming.foreach(println)
(ATL,152)
(ORD,145)
(DFW,143)
// which airport has the most outgoing flights?
val maxout= graph.outDegrees.join(airports).sortBy(_._2._1, ascending=false).take(3)
maxout.foreach(println)
(10397,(153,ATL))
(13930,(146,ORD))
(11298,(143,DFW))网页排名
另一个GraphX运算符是PageRank。 这是基于Google PageRank算法的。
PageRank通过确定哪些顶点与其他顶点的边缘最多,来衡量图形中每个顶点的重要性。 在我们的示例中,我们可以使用PageRank通过测量哪些机场与其他机场的联系最多来确定哪些机场最重要。
我们必须指定公差,这是收敛的量度。
13.根据PageRank,最重要的机场是哪些?
// use pageRank
val ranks = graph.pageRank(0.1).vertices
// join the ranks with the map of airport id to name
val temp= ranks.join(airports)
temp.take(1)
// Array((15370,(0.5365013694244737,TUL)))
// sort by ranking
val temp2 = temp.sortBy(_._2._1, false)
temp2.take(2)
//Array((10397,(5.431032677813346,ATL)), (13930,(5.4148119418905765,ORD)))
// get just the airport names
val impAirports =temp2.map(_._2._2)
impAirports.take(4)
//res6: Array[String] = Array(ATL, ORD, DFW, DEN)许多重要的图形算法是迭代算法,因为顶点的性质取决于他们的邻居,这取决于他们的邻居的性能特性。 Pregel是Google研发的一种迭代图处理模型,它使用在图的顶点之间传递的一系列消息迭代序列。 GraphX实现类似于Pregel的批量同步消息传递API。
使用GraphX中的Pregel实现时,顶点只能将消息发送到相邻的顶点。
Pregel运算符在一系列超级步骤中执行。 在每个超级步骤中:
- 顶点从上一个超级步骤接收入站消息的总和
- 他们为顶点属性计算一个新值
- 在下一个超级步骤中,它们将消息发送到相邻顶点
当没有更多消息剩余时,Pregel运算符将结束迭代,并返回最终图形。
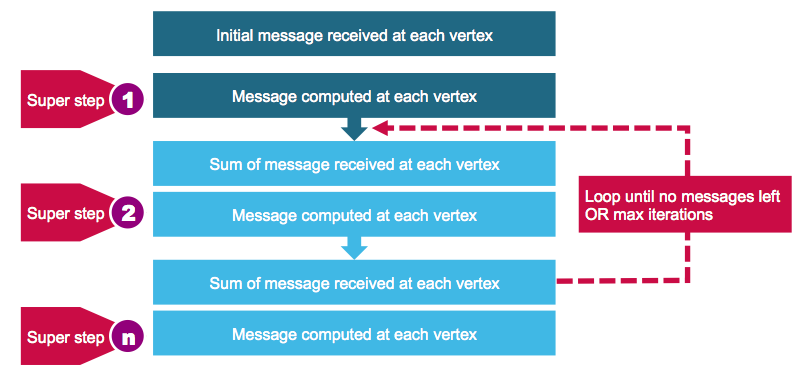
下面的代码使用Pregel使用以下公式计算最便宜的机票来计算机票。
50 +距离/ 20
// starting vertex
val sourceId: VertexId = 13024
// a graph with edges containing airfare cost calculation
val gg = graph.mapEdges(e => 50.toDouble + e.attr.toDouble/20 )
// initialize graph, all vertices except source have distance infinity
val initialGraph = gg.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
// call pregel on graph
val sssp = initialGraph.pregel(Double.PositiveInfinity)(
// Vertex Program
(id, dist, newDist) => math.min(dist, newDist),
triplet => {
// Send Message
if (triplet.srcAttr + triplet.attr < triplet.dstAttr) {
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else {
Iterator.empty
}
},
// Merge Message
(a,b) => math.min(a,b)
)
// routes , lowest flight cost
println(sssp.edges.take(4).mkString("\n"))
Edge(10135,10397,84.6)
Edge(10135,13930,82.7)
Edge(10140,10397,113.45)
Edge(10140,10821,133.5)
// routes with airport codes , lowest flight cost
ssp.edges.map{ case ( Edge(org_id, dest_id,price))=> ( (airportMap(org_id), airportMap(dest_id), price)) }.takeOrdered(10)(Ordering.by(_._3))
Array((WRG,PSG,51.55), (PSG,WRG,51.55), (CEC,ACV,52.8), (ACV,CEC,52.8), (ORD,MKE,53.35), (IMT,RHI,53.35), (MKE,ORD,53.35), (RHI,IMT,53.35), (STT,SJU,53.4), (SJU,STT,53.4))
// airports , lowest flight cost
println(sssp.vertices.take(4).mkString("\n"))
(10208,277.79)
(10268,260.7)
(14828,261.65)
(14698,125.25)
// airport codes , sorted lowest flight cost
sssp.vertices.collect.map(x => (airportMap(x._1), x._2)).sortWith(_._2 < _._2)
res21: Array[(String, Double)] = Array(PDX,62.05), (SFO,65.75), (EUG,117.35)想了解更多?
在此博客文章中,您学习了如何在MapR沙盒上将Apache Spark GraphX和Scala一起使用。 如果您对GraphX有任何疑问,请在下面的评论部分中提问。
翻译自: https://www.javacodegeeks.com/2016/03/get-started-using-apache-spark-graphx-scala.html















 6848
6848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









