





在本系列的第一篇文章中,我们了解了如何使用Spark Testing Base对 Spark Streaming操作进行单元测试。 在这里,我们将看到如何使用Docker Compose进行集成测试。
什么是集成测试
我们之前看到了有关单元和集成测试的讨论。 再次,由于我们要保持重点,我们将使用具有以下特征的集成测试定义:
- 网络集成:我们的代码应调用网络以与第三方依赖项集成。 然后,我们的集成测试工作的一部分将是在存在网络问题的情况下验证我们代码的行为。
- 框架集成:框架试图产生可预测且直观的API。 但是,情况并非总是如此,集成测试可以验证我们的假设。
什么是Docker Compose
Docker为虚拟化提供了轻量级和安全的范例。 因此,Docker是设置和处置用于集成测试的容器(进程)的理想人选。 您可以将应用程序或外部依赖项包装在Docker容器中,并轻松管理其生命周期。
协调一堆容器的关系,执行顺序或共享资源可能很麻烦且乏味。 可以使用Docker Compose代替使用Bash脚本烘焙自己的解决方案。
控制生命周期
管理流程应如何以及何时启动,停止或进入不同状态是流程生命周期管理的一部分。 在集成测试时,让我们对这种管理进行一些考虑。
- 如果从时间或空间角度来看,该过程的设置成本很高,那么维护整个测试套件开始的过程可能会很方便。
- 如果过程是有状态的,那可能会成问题。 如果是这种情况,我们需要确保在测试之间对数据进行分区,因此测试不会互相踩脚趾。
- 如果隔离数据变得太复杂,我们可以处置与每个测试或逻辑测试组关联的过程,以确保我们使用干净的表。
- 另一种方法是删除测试生成的数据。 测试后删除数据存在以下问题:难以诊断测试是否失败,如果测试在灾难性的中间失败,则可能无法删除数据。 我的首选方法是在开始每次测试之前删除数据。
- 很难说一个过程已经完全“分解”。 某些进程可能已分配了PID,但直到发生一些预热后才准备好接收消息。 由于没有通用的解决方案,这使管理变得非常复杂。
将测试依赖项与构建系统耦合。
在本文中,我们将探索Docker Compose来控制外部依赖关系。 Docker Compose是一种打包应用程序的轻量级方式,但是即使启动容器也要花费一些时间(通常与进程本身的启动时间有关)。
因此,我们将采用每个测试套件一次启动容器的方法。
plugins.sbt
addSbtPlugin("com.tapad" % "sbt-docker-compose" % "1.0.11")build.sbt
lazy val dockerComposeTag = "DockerComposeTag"
enablePlugins(DockerComposePlugin)
testOptions in Test += Tests.Argument(TestFrameworks.ScalaTest, "-l", dockerComposeTag),
composeFile := baseDirectory.value + "/docker/sbt-docker-compose.yml",
testTagsToExecute := dockerComposeTag
)我从示例中复制了最相关的部分。 如您所见,我们正在使用sbt-docker-compose库。 这意味着我们正在将测试(至少是它们的依赖项)与构建系统( sbt ) 耦合 。 这可能是一个问题,因为我们只能将解决方案锁定在这个特定的构建提供程序上,但是像往常一样,在每个技术决策中都需要权衡取舍。
运行sbt dockerComposeTest时,将执行所有标记有DockerComposeTag测试。 该命令将设置和拆除sbt-docker-compose.yml中定义的容器:
version: '2'
services:
cassandra:
image: cassandra:2.1.14
ports:
- "9042:9042"
kafka:
image: spotify/kafka:latest
ports:
- "9092:9092"
- "2181:2181"
environment:
ADVERTISED_HOST: localhost # this must match the docker host ip
ADVERTISED_PORT: 9092编写Spark Streaming集成测试
现在我们已经准备好测试基础架构,我们可以编写我们的第一个集成测试。 让我们记住我们要测试的代码:
val lines = ingestEventsFromKafka(ssc, brokers, topic).map(_._2)
val specialWords = ssc.sparkContext.cassandraTable(keyspace, specialWordsTable)
.map(_.getString("word"))
countWithSpecialWords(lines, specialWords)
.saveToCassandra(keyspace, wordCountTable)def countWithSpecialWords(lines: DStream[String], specialWords: RDD[String]): DStream[(String, Int)] = {
val words = lines.flatMap(_.split(" "))
val bonusWords = words.transform(_.intersection(specialWords))
words.union(bonusWords)
.map(word => (word, 1))
.reduceByKey(_ + _)
} 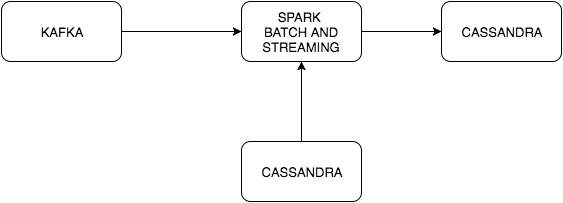
从Kafka接收事件,该流与包含特殊单词的Cassandra表结合在一起。 这些事件包含用空格分隔的单词,我们想对该流中的单词进行计数(如果一个单词出现两次)。 有两个外部依赖项,因此我们的sbt-docker-compose.yml必须为我们启动这些依赖项。
class WordCountIT extends WordSpec
with BeforeAndAfterEach
with Eventually
with Matchers
with IntegrationPatience {
object DockerComposeTag extends Tag("DockerComposeTag")
var kafkaProducer: KafkaProducer[String, String] = null
val sparkMaster = "local[*]"
val cassandraKeySpace = "kafka_streaming"
val cassandraWordCountTable = "word_count"
val cassandraSpecialWordsTable = "special_words"
val zookeeperHostInfo = "localhost:2181"
val kafkaTopic = "line_created"
val kafkaTopicPartitions = 3
val kafkaBrokers = "localhost:9092"
val cassandraHost = "localhost"
override protected def beforeEach(): Unit = {
val conf = new Properties()
conf.put("bootstrap.servers", kafkaBrokers)
conf.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
conf.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
kafkaProducer = new KafkaProducer[String, String](conf)
}我们使用ScalaTest中的 WordSpec定义了一个测试。 其余代码基本上是为我们的测试做准备。
"Word Count" should {
"count normal words" taggedAs (DockerComposeTag) in {
val sparkConf = new SparkConf()
.setAppName("SampleStreaming")
.setMaster(sparkMaster)
.set(CassandraConnectorConf.ConnectionHostParam.name, cassandraHost)
.set(WriteConf.ConsistencyLevelParam.name, ConsistencyLevel.LOCAL_ONE.toString)
eventually {
CassandraConnector(sparkConf).withSessionDo { session =>
session.execute(s"DROP KEYSPACE IF EXISTS $cassandraKeySpace")
session.execute(s"CREATE KEYSPACE IF NOT EXISTS $cassandraKeySpace WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 };")
session.execute(
s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraWordCountTable
|(word TEXT PRIMARY KEY,
|count COUNTER);
""".stripMargin
)
session.execute(
s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraSpecialWordsTable
|(word TEXT PRIMARY KEY);
""".stripMargin
)
session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraWordCountTable;")
session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraSpecialWordsTable;")
}
createTopic(zookeeperHostInfo, kafkaTopic, kafkaTopicPartitions)
val ssc = new StreamingContext(sparkConf, Seconds(1))
SampleStreaming.start(ssc, kafkaTopic, kafkaTopicPartitions, cassandraHost, kafkaBrokers,
cassandraKeySpace, cassandraWordCountTable, cassandraSpecialWordsTable)
import ExecutionContext.Implicits.global
Future {
ssc.awaitTermination()
}
produceKafkaMessages()
eventually {
ssc.cassandraTable(cassandraKeySpace, cassandraWordCountTable).cassandraCount shouldEqual 2
}
}
}
}噪声很大,但是此测试基本上在做以下事情:
- 设置Spark Conf。 我们需要先做它,因为spark-cassandra-connector需要它
- 在Cassandra中执行一些DDL和DML。 键空间和表(如果尚不存在),并为了防止万一,将其截断,因此我们可以从一个干净的表开始。 在这个特定示例中,我们只想计算生成的行数,因此我们不在乎特殊的单词,但是用数据填充该表会更容易。
- 我们创建Kafka主题,Spark Streaming将使用该主题来提取数据。
def createTopic(zookeeperHostInfo: String, topic: String, numPartitions: Int) = {
val timeoutMs = 10000
val zkClient = new ZkClient(zookeeperHostInfo, timeoutMs, timeoutMs, ZKStringSerializer)
val replicationFactor = 1
val topicConfig = new Properties
AdminUtils.createTopic(zkClient, topic, numPartitions, replicationFactor, topicConfig)
}- 我们使用火花流上下文启动火花流应用程序。
- 现在我们的火花流已准备就绪,可以使用消息了,我们将单个消息发布到该Kafka主题中。
def produceKafkaMessages() = {
val record = new ProducerRecord[String, String](kafkaTopic, "Hi friend Hi")
kafkaProducer.send(record)
}- 计算的结果将类似于:嗨-> 2,朋友->1。这是Cassandra的'word_count'表中的两行。 这就是我们最终将在测试中所做的断言(在实际应用中,断言会更加复杂,但是示例仅说明了一点)。
结论
即使看起来有很多代码,用于集成测试火花流应用程序的大多数位都与在外部依赖项中设置数据有关。 使用适当的抽象,可以很高兴地进行这些测试。
在下一篇文章中,我们将看到如何在没有Docker Compose的情况下进行集成测试,直接从ScalaTest控制那些依赖项。















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









