





当我们构建服务体系结构(面向服务的体系结构,微服务,下一个版本等)时,我们最终会通过网络进行更多的调用。 网络是危险的 。 我们尝试在服务中建立冗余,以便我们可以体验系统中的故障并继续前进并处理客户的请求。 构建冗余,弹性系统这一难题的重要部分是智能的,可感知应用程序的负载平衡。 马特·克莱因 ( Matt Klein)最近写了一篇关于现代负载平衡的很棒的文章 ,您应该现在就停止阅读。
断路器模式一直是构建大型,有弹性的分布式系统的重要模式,尤其是那些旨在作为“微服务”在“云”中运行的系统。 通过断路器实现,我们尝试将网络呼叫“短路”到似乎遭受重复性故障的系统。 断路是智能的,可感知应用程序的负载平衡的子功能。 您要么是显式的负载平衡,要么是隐式发生的。 让我们看看使用Netflix Hystrix进行电路中断的一些方法,以及与Envoy Proxy进行比较的方法。
断路
我们使用断路功能来帮助防止部分或全部级联故障。 我们希望控制/减少/消除不正常系统的流量,因此我们不会继续使它们过载并阻止它们恢复。 例如,如果您的搜索服务呼唤推荐服务以获得个性化搜索结果,并且推荐服务因许多不同的调用而返回错误,也许我们应该在一段时间内停止调用它? 也许我们重试的次数越多,我们对该系统施加的压力越大,就导致它进一步退化? 在一段时间内,我们可能会决定仅“快速失败”,并且不允许呼叫推荐服务。 这种方法在本质上类似于断路器在房屋电气系统中的工作方式。 如果遇到故障,则应断开电路以保护系统的其余部分。 断路器模式迫使我们的应用程序处理我们的网络调用可能并且确实会失败的事实,并有助于保护整个系统免受级联故障的影响。 它关系到系统组件的健康状况,以及是否应将流量路由到它们 。
Netflix OSS Hystrix
Netflix OSS于2012年发布了一种名为Netflix OSS Hystrix的 断路器实现 。 Hystrix是用于获取断路行为的客户端Java库。 Hystrix 提供以下行为 。
摘自“ 使Netflix API更具弹性 ”:
- 自定义回退-在某些情况下,服务的客户端库提供了我们可以调用的回退方法,或者在其他情况下,我们可以使用API服务器上本地可用的数据(例如Cookie或本地JVM缓存)来生成回退响应
- 静默失败—在这种情况下,fallback方法仅返回一个空值,如果被调用的服务提供的数据对于将发送回请求客户端的响应是可选的,则该方法很有用
- 快速失败-用于需要数据或没有良好回退并导致客户端获得5xx响应的情况下。 这可能会对设备UX产生负面影响,这不是理想的选择,但可以保持API服务器正常运行,并在出现故障的服务再次可用时使系统快速恢复。
断路功能可以通过几种不同的方式触发 。
摘自“ 使Netflix API更具弹性 ”:
- 对远程服务的请求超时
- 用于与服务依赖项进行交互的线程池和有界任务队列的容量为100%
- 用于与服务依赖项进行交互的客户端库引发异常
hystrix电路断开的流程图可以在这里看到 :
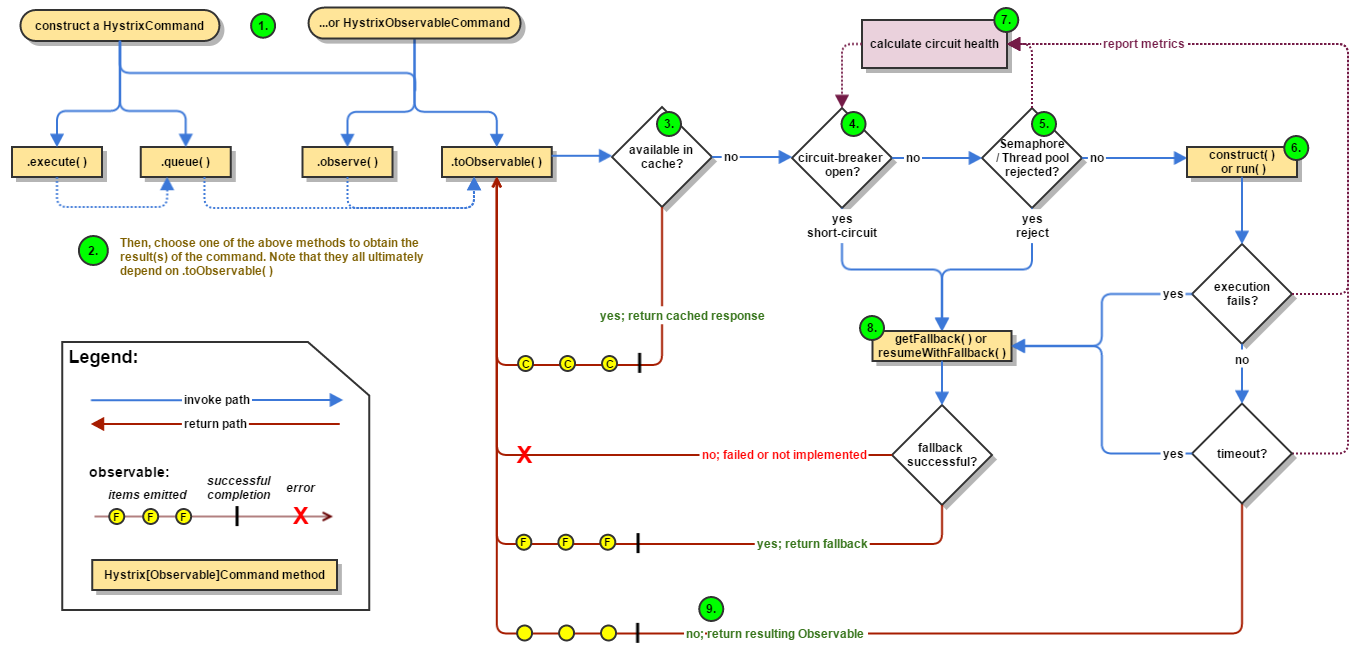
Netflix Hystrix 允许对网络交互进行非常细粒度的控制 。 Hystrix允许我们根据进行的呼叫类型,以非常精确的配置来处理与之交互的“上游”集群。 例如,如果我们正在调用推荐引擎,则可能正在发出很多不变异数据的请求(非写操作)。 如果我们进行查询,读取参考数据等,那么那些断路配置可能比变异/写入数据的调用更为宽松。
另一个重要的考虑因素是,Hystrix非常清楚地对待故障/超时没有区别,出于发生故障的电路中断的目的。 也就是说,它可能发生在传输中或客户端代码本身中。 Hystrix可以检测断路阈值,而不管发生故障的位置。
最后,正如我之前提到的那样:断路实际上只是智能的,可感知应用程序的负载平衡的一项特殊功能。 在这种情况下,“应用程序感知”部分是原义的:它是应用程序中的一个库。 在Netflix OSS生态系统中,您还可以将Hystrix与Netflix OSS Ribbon之类的东西配对,后者是另一个用于执行客户端负载平衡的应用程序库。
服务网格的演进
随着您的服务体系结构变得越来越异构,您会发现很难(或不切实际)将服务实现限制为特定的库,框架甚至语言。 随着服务网格的发展,我们看到其中一些弹性模式,例如断路,在基础架构中作为独立于语言/框架的解决方案实现。 服务网格可以定义为:
A decentralized application-networking infrastructure
between your services that provides security, resiliency,
observability, and routing control.服务网格可能在其“数据平面”中依赖于不同的L7(应用级)代理来实现诸如重试,超时,断路器等的弹性功能。在此博客文章中,我们将介绍Envoy代理的方法断路。 Envoy代理是Istio Service Mesh的默认开箱即用代理,因此此处所述的行为也适用于Istio 。
特使代理/ Istio服务网格
Envoy将其断路功能视为负载平衡和运行状况检查的子集。 Envoy从通信到实际的后端群集中分离出了其“路由”问题(选择要与之交谈的群集)。 这是一个重要的考虑因素,也是使Envoy超越其他负载平衡器实现中发现的粗粒度弹性配置的原因。 Envoy可能有许多不同的“路线”,它们试图将流量映射到适当的后端。 这些后端称为“集群”,每个集群可以具有自己的集群特定配置以实现负载平衡。 每个群集还可以具有自己的配置,用于被动运行状况检查(异常值检测)。 实际上,有少数几个使节配置可以共同提供开篇段落中描述的断路功能。 让我们看看其中的每一个。
我们可以这样定义出站集群:
"clusters": [
{
"name": "httpbin_service",
"connect_timeout_ms": 5000,
"type": "static",
"lb_type": "round_robin",
"hosts": [
{
"url": "tcp://172.17.0.2:8080"
},{
"url": "tcp://172.17.0.3:8080"
}
], 在此示例中,我们可以看到我们有一个名为httpbin_service的集群,我们将使用round_robin负载均衡,并且将在两个主机之间实现均衡。 让我们添加Envoy的断路器配置
断路器
"circuit_breakers": {
"default": {
"max_connections": 1,
"max_pending_requests": 1,
"max_retries": 3
} 在这里,我们针对HTTP 1.x工作负载。 我们将出站连接数限制为1 ,将最大未决请求数限制为1 。 我们还定义了最大重试次数。 在某些方面,这种限制连接池和请求数量的行为类似于Netflix Hystrix可以提供的隔板 。 如果我们的应用程序打开的连接数超过了这些设置(实际上有一些余地-这些不是硬性限制),我们将看到Envoy为这些呼叫打开电路并在其报告统计信息中报告这些事件。 请参阅此博客文章,详细介绍
离群值检测
到目前为止,我们已经看到Envoy所说的“断路”实际上更接近于连接池隔板 。 为了获得“开路”行为,Envoy执行了一种称为离群值检测的操作 。 Envoy在其负载均衡池中为特定群集保留有关不同端点的操作的统计信息。 如果检测到异常行为,则可以将该端点从负载平衡池中弹出。 让我们看一下离群值检测的示例配置:
"outlier_detection" : {
"consecutive_5xx": 1,
"max_ejection_percent": 100,
"interval_ms": 1000,
"base_ejection_time_ms": 60000
} 此配置在与上游主机的通信中显示“如果我们有1 5xx”错误,则应将其标记为运行状况不佳,并将其暂时从该集群的负载平衡池中删除。 我们还将max_ejection_percent配置为100这意味着我们愿意弹出遇到这些故障的所有主机。 这个设置是非常特殊的环境,你会想要照顾配置它。 理想情况下,我们将尽我们所能路由到主机,以免造成部分或级联故障。 默认情况下,Envoy会将max_ejection_percent设置为10 。
我们还将弹出基准时间设置为6000毫秒。 主机从负载平衡池中弹出的实际时间是此“基准”设置乘以其弹出次数。 这使我们可以更严厉地惩罚似乎一直不太可靠的主机。
集群恐慌
我们还应该注意Envoy离群值检测和负载平衡。 如果异常检测已弹出过多的主机, 我们可能会进入群集全局“紧急”模式 ,这意味着代理将忽略它认为负载平衡池的运行状况,并再次开始路由到所有主机。 这是一个非常强大的内置功能。 在分布式系统中,您必须意识到,有时您在“理论”中对世界的看法是不正确的,最好将其降级为不鼓励级联失败的模式。 另一方面,您可以控制此恐慌百分比 (默认情况是,如果弹出50%以上的负载平衡池,Envoy会惊慌)并提高恐慌阈值(> 50%)甚至完全禁用(将其设置为0 )。 将其设置为0会使Envoy的断路功能之间的行为与Netflix Hystrix更加相似。
细粒度的断路策略
库方法的好处之一是我们可以应用细粒度的应用感知断路策略。 Hystrix文档使用对单个上游群集的不同读/查询/写调用的示例。 例如, 来自Hystrix常见问题解答 :
Often a single network route via a cluster of loadbalancers
will serve many different types of functionality that end
up in several different HystrixCommands.
Each HystrixCommand needs the ability to set different
throughput constraints, timeout values and fallback strategies.使用Envoy,我们可以通过路由匹配来完成相同的外科手术断路策略,该路由匹配指定我们要对哪些确切的集群调用进行操作并通过特定的集群策略进行操作。
使用Istio进行细粒度的断路器
我们可以使用Istio更高级别的配置来指定细粒度的群集和断路。 在Istio中,我们使用DestinationPolicies配置负载平衡和断路策略。 这是在Istio中指定断路功能的策略的示例:
metadata:
name: reviews-cb-policy
namespace: default
spec:
destination:
name: reviews
labels:
version: v1
circuitBreaker:
simpleCb:
maxConnections: 100
httpMaxRequests: 1000
httpMaxRequestsPerConnection: 10
httpConsecutiveErrors: 7
sleepWindow: 15m
httpDetectionInterval: 5m电路跳闸该怎么办?
断路难题的最后一部分是当我们达到断路阈值时发生的事情。 使用Hystrix,后备的概念已内置到库中,并且可以由库进行编排。 在Hystrix中,我们可以执行诸如缓存结果,回退到默认值之类的操作,甚至可以通过调用不同的服务来采用替代路径。 我们还可以获得有关失败原因的非常详细的信息,并做出特定于应用程序的决策。
使用服务网格,目前没有用于故障上下文传播的专用库,故障原因更加不透明。 这并不意味着我们的应用程序不能进行后备操作(针对传输错误和特定于客户端的错误)。 我认为对于任何应用程序的协议来说,无论是否使用特定于库的框架,都必须始终遵守其为客户保留的承诺,这一点非常重要。 如果发现它无法完成预期的操作,则应找到一种适当降级的方法。 幸运的是,您不需要特定于应用程序的框架。 大多数语言具有内置的错误和异常捕获和处理功能。 在这些异常路径中应实现后备。
概括
- 断路是负载均衡器的一种特殊行为
- Hystrix仅执行断路功能; 负载平衡可以与功能区(或任何客户端负载平衡库)配对
- Hystrix将“后备”的概念视为库/框架问题,并将其放在首位
- Envoy已将电路中断和异常检测作为其负载平衡实现的一部分
- 特使“断路”更像Hystrix隔板,“异常检测”更类似于Hystrix断路器
- Envoy有许多默认的经过生产/战役测试的功能,例如恐慌阈值
- 服务网格缺乏将故障上下文提供回应用程序的能力(目前!敬请期待!)















 2248
2248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}