





我们已经介绍了一些解析术语,同时列出了Java , C# , Python和JavaScript中用于解析的主要工具和库。 在本文中,我们将更深入地介绍解析中使用的概念和算法,以便您可以更好地了解这个迷人的世界。
我们在本文中尝试了实用性。 我们的目标是帮助从业者,而不是解释全部理论。 我们只是解释您需要了解什么才能理解和构建解析器。
在定义了解析之后,文章分为三个部分:
- 大局观 。 我们在其中描述解析器的基本术语和组件的部分。
- 文法 。 在这一部分中,我们解释语法的主要格式以及编写它们时最常见的问题。
- 解析算法 。 在这里,我们讨论所有最常用的解析算法,并说出它们的优点。
解析的定义
根据语法规则对输入进行分析以组织数据
有几种定义解析的方法。 但是要点保持不变:解析意味着找到我们得到的数据的基础结构。
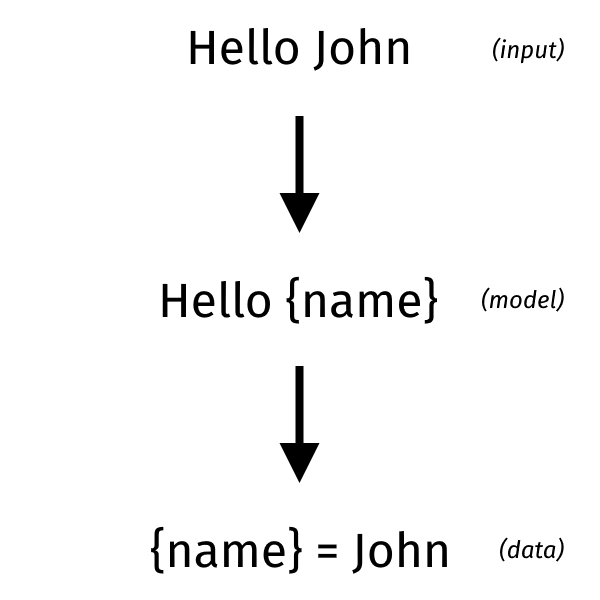
从某种意义上讲,解析可以看作是模板的逆向:识别结构并提取数据。 相反,在模板中,我们有一个结构,并用数据填充它。 在解析的情况下,您必须根据原始表示来确定模型。 在进行模板制作时,您必须将数据与模型结合起来以创建原始表示。 原始表示形式通常是文本,但也可以是二进制数据。
从根本上进行分析是必要的,因为不同的实体需要数据采用不同的形式。 解析允许以特定软件可以理解的方式转换数据。 明显的例子是程序:它们是由人类编写的,但必须由计算机执行。 因此,人们以一种他们可以理解的形式编写它们,然后软件以一种可以被计算机使用的方式对其进行转换。
但是,即使在具有不同需求的两个软件之间传递数据时,也可能需要解析。 例如,当您必须序列化或反序列化一个类时,它是必需的。
大图景

在本节中,我们将描述解析器的基本组件。 我们不是在给您正式的解释,而是实际的解释。
常用表达
可以由模式定义的字符序列
正则表达式经常被吹捧为不应该用于解析的东西。 这不是严格正确的,因为您可以使用正则表达式来解析简单的输入。 问题在于某些程序员只知道正则表达式。 因此,他们使用它们来尝试解析所有内容,甚至包括本不该解析的内容。 结果通常是一系列非常脆弱的正则表达式。
您可以使用正则表达式来解析一些较简单的语言,但这不包括大多数编程语言。 甚至看起来很简单HTML也是如此。 实际上,只能用正则表达式解析的语言称为正则语言。 有一个正式的数学定义,但这超出了本文的范围。
尽管该理论的一个重要结果是规则语言也可以由有限状态机解析或表达。 也就是说,正则表达式和有限状态机同样强大。 这是原因,因为它们用于实现词法分析器,我们将在后面看到。
可以通过一系列正则表达式定义常规语言,而更复杂的语言则需要更多内容。 一个简单的经验法则是:如果一种语言的语法具有递归或嵌套的元素,则它不是常规语言。 例如,HTML可以在任何标签内包含任意数量的标签,因此它不是常规语言,并且无论多么聪明,都不能仅使用正则表达式进行解析。
语法的正则表达式
典型程序员对正则表达式的熟悉使它们经常用于定义语言的语法。 更准确地说,它们的语法用于定义词法分析器或解析器的规则。 例如,规则中使用Kleene星号 ( * )表示特定元素可以出现零次或无限次。
规则的定义不应与实际词法分析器或解析器的实现方式混淆。 您可以使用语言提供的正则表达式引擎来实现词法分析器。 但是,通常将语法中定义的正则表达式转换为实际的有限状态机,以获得更好的性能。
解析器的结构
现在阐明了正则表达式的作用后,我们可以看一下解析器的一般结构。 完整的解析器通常由两部分组成: lexer (也称为扫描器或标记器 )和适当的解析器。 解析器需要词法分析器,因为它不能直接在文本上工作,而是在词法分析器产生的输出上工作。 并非所有解析器都采用这种两步模式:一些解析器不依赖于单独的词法分析器,而是将这两个步骤结合在一起。 它们称为无扫描程序解析器 。
一个词法分析器和一个解析器按顺序工作:词法分析器扫描输入并生成匹配的令牌,然后解析器扫描令牌并生成解析结果。
让我们看下面的示例,并想象我们正在尝试解析一个加法。
437 + 734 词法分析器扫描文本和发现4 , 3 , 7 ,然后一个空格( ) 词法分析器的工作是识别字符437构成NUM类型的一个令牌。 然后,词法分析器找到一个+符号,它与PLUS类型的第二个令牌相对应,最后找到另一个NUM类型的令牌。 
解析器通常将组合词法分析器生成的令牌并将其分组。
词法分析器和解析器使用的定义称为规则或产生式 。 在我们的示例中,词法分析器规则将指定一个数字序列与一个NUM类型的标记相对应,而解析器规则将指定一个数字序列在NUM,PLUS,NUM类型的标记与一个求和表达式相对应。
现在通常会找到可以生成词法分析器和解析器的套件。 过去,更常见的是将两种不同的工具结合在一起:一种用于生成词法分析器,另一种用于生成解析器。 例如,古老的lex&yacc对就是这种情况:使用lex可以生成一个词法分析器,而使用yacc则可以生成解析器
无扫描解析器
无扫描程序的解析器的操作有所不同,因为它们直接处理原始文本,而不是处理由词法分析器生成的令牌列表。 也就是说,无扫描器的解析器可以充当词法分析器和解析器的组合。
虽然出于调试目的而知道特定的解析工具是否为无扫描程序的解析器当然很重要,但是在许多情况下定义语法并不重要。 那是因为您通常仍然定义模式,该模式将字符序列分组以创建(虚拟)令牌; 然后将它们结合起来以获得最终结果。 这仅仅是因为这样做更方便。 换句话说,无扫描器解析器的语法看起来非常类似于具有单独步骤的工具的语法。 同样,您不应混淆为方便起见定义事物的方式以及事物在幕后的工作方式。
语法
形式语法是语法上描述语言的一组规则
此定义有两个重要部分:语法描述了一种语言,但是此描述仅与语言的语法有关,与语义无关。 也就是说,它定义了它的结构,但没有定义它的含义。 如有必要,必须以其他方式检查输入含义的正确性。
举例来说,假设我们要定义在该段定义显示的语言的语法。
HELLO: "Hello"
NAME: [a-zA-Z]+
greeting: HELLO NAME 该语法接受诸如"Hello Michael"和"Hello Programming" 。 它们在语法上都是正确的,但是我们知道“编程”不是一个名称。 因此在语义上是错误的。 语法未指定语义规则,并且语法分析器未验证它们。 您将需要以其他方式确保所提供名称的有效性,例如,将其与有效名称数据库进行比较。
语法剖析
要定义语法的元素,让我们来看一个使用最常用的格式描述语法的示例: Backus-Naur Form(BNF) 。 此格式有许多变体,包括扩展Backus-Naur形式 。 扩展变体的优点是包括一种表示重复的简单方法。 另一个值得注意的变体是增强 Backus-Naur形式 ,主要用于描述双向通信协议。
Backus-Naur语法中的典型规则如下所示:
<symbol> ::= __expression__ <simbol>是一个非终结符 ,这意味着可以用右边的元素组__expression__代替它 。 元素__expression__可以包含其他非终止符号或终止符号。 终端符号就是那些不会显示为<symbol>的符号 语法中的任何地方。 终端符号的典型示例是字符串,例如“ Hello”。
规则也可以称为生产规则 。 从技术上讲,它定义了非终结点和非终结点集以及右侧的终结点之间的转换。
文法的类型
解析中主要使用两种语法: 常规语法和无上下文语法 。 通常,一种语法对应一种相同的语言:常规语法定义常规语言,依此类推。 但是,还有一种较新的语法,称为解析表达语法 (PEG),其功能与上下文无关的语法同样强大,因此可以定义上下文无关的语言。 两者之间的区别在于规则的符号和解释。
正如我们已经提到的,两种语言处于复杂性层次结构中:常规语言比无上下文语言更简单。
区分这两种语法的一种相对简单的方法是,规则语法的__expression__表示规则的右侧,可能只是以下一种:
- 空字符串
- 单个终端符号
- 单个终端符号,后跟非终端符号
实际上,这很难检查,因为一种特定的工具可以允许在一个定义中使用更多的终端符号。 然后,工具本身将自动将该表达式转换为等效的一系列表达式,这些表达式均属于上述三种情况之一。
因此,您可以编写与常规语言不兼容的表达式,但是该表达式将以适当的形式进行转换。 换句话说,该工具可以为编写语法提供语法糖。
在后面的段落中,我们将详细讨论各种语法及其格式。
Lexer
词法分析器将标记序列中的字符序列转换
词法分析器也称为扫描器或标记器 。 词法分析器在解析中扮演着重要的角色,因为它们将初始输入转换成一种形式,该形式可以由适当的解析器管理,该解析器可以在以后的阶段工作。 通常,词法分析器比解析器更容易编写。 尽管在某些特殊情况下两者都非常复杂,例如在C的情况下(请参阅lexer hack )。
词法分析器工作的一个非常重要的部分是处理空白。 在大多数情况下,您希望词法分析器放弃空白。 那是因为否则解析器将不得不检查每个单个令牌之间是否存在空格,这将很快变得令人讨厌。
在某些情况下,您不能执行此操作,因为空格与语言有关,例如在Python中用于标识代码块的情况。 即使在这些情况下,通常还是词法分析器处理将相关空白与无关空白区分开的问题。 这意味着您希望词法分析器了解与解析相关的空白。 例如,在解析Python时,您希望词法分析器检查空格是否定义缩进(相关)或关键字if和以下表达式之间的空格(无关)。
Lexer结束和解析器开始的地方
鉴于词法分析器几乎只与解析器结合使用,因此两者之间的分界线有时可能会模糊。 这是因为解析必须产生对程序的特定需求有用的结果。 因此,不仅有一种解析某些内容的正确方法,而且您只关心满足您需求的一种方法。
例如,假设您正在创建一个程序,该程序必须解析服务器的日志以将其保存在数据库中。 为此,词法分析器将识别一系列数字和点并将其转换为IPv4令牌。
IPv4: [0-9]+ "." [0-9]+ "." [0-9]+ "." [0-9]+然后,解析器将分析令牌序列,以确定它是否是消息,警告等。
如果您开发的软件必须使用IP地址来识别访问者的国家,那将会发生什么呢? 可能您希望词法分析器标识地址的八位位组以供以后使用,并使IPv4成为解析器元素。
DOT : "."
OCTET : [0-9]+
ipv4 : OCTET DOT OCTET DOT OCTET DOT OCTET这是一个示例,说明由于目标不同,如何以不同的方式解析相同的信息。
解析器
在解析的上下文中,解析器不仅可以引用执行整个过程的软件,还可以引用用于分析词法分析器生成的令牌的正确解析器。 这仅仅是由于解析器处理了整个解析过程中最重要和最困难的部分而导致的。 最重要的是,我们指的是用户最在乎并会实际看到。 实际上,正如我们所说,词法分析器是一个帮助解析器工作的助手。
无论如何,您的意思是解析器的输出是代码的组织结构,通常是树。 该树可以是解析树或抽象语法树 。 它们都是树,但是它们在表示实际编写的代码和由解析器定义的中间元素的紧密程度方面有所不同。 有时两者之间的界限可能会模糊,我们将在后面的段落中更好地看到它们之间的差异。
选择树的形式是因为它是在不同细节级别使用代码的简单自然的方法。 例如,C#中的一个类有一个主体,该主体由一个语句,块语句组成,该语句是用大括号括起来的语句列表,依此类推……
句法与语义正确性
解析器是编译器或解释器的基本部分,但当然可以是多种其他软件的一部分。 例如,在我们的文章使用Roslyn从C#源代码生成图表中,我们解析了C#文件以生成图表。
解析器只能检查一段代码的语法正确性,但是编译器也可以在检查同一段代码的语义有效性的过程中使用其输出。
让我们看一个在语法上正确但在语义上不正确的代码示例。
int x = 10
int sum = x + y 问题在于,永远不会定义一个变量( y ),因此如果执行,程序将失败。 但是,解析器无法知道这一点,因为它不跟踪变量,而只是查看代码的结构。
相反,编译器通常会第一次遍历解析树,并保留所有已定义变量的列表。 然后,它再次遍历解析树,并检查是否正确定义了所使用的变量。 在此示例中,它们不是,它将引发错误。 因此,这是解析树也可用于由编译器检查语义的一种方法。
无扫描仪解析器
无扫描器的解析器 ,或更常见的是无词器的解析器 ,是一种在单个步骤中执行令牌化(即令牌中字符序列的变换 )和正确解析的解析器。 从理论上讲,具有单独的词法分析器和解析器是可取的,因为它可以使目标更清晰地分离,并可以创建更具模块化的解析器。
对于无法在词法分析器和解析器之间进行清晰区分的语言,无扫描器解析器是一种更好的设计。 一个示例是标记语言的解析器,在特殊语言中插入了特殊标记。 它还可以帮助处理传统词法难于处理的语言,例如C。这是因为无扫描器的解析器可以更轻松地处理复杂的标记化。
解析实际编程语言时遇到的问题
从理论上讲,当代解析被设计为处理真实的编程语言,实际上,某些真实的编程语言存在挑战。 至少,使用普通的解析生成器工具解析它们可能会更困难。
上下文相关部分
解析工具传统上设计为处理上下文无关的语言,但有时这些语言是上下文敏感的。 可能是为了简化程序员的生活,或者仅仅是因为设计不当。 我记得曾读过一篇关于程序员的文章,该程序员认为它可以在一周内为C生成解析器,但随后发现了很多极端情况,以至于一年后他仍在研究它。
上下文敏感元素的典型示例是所谓的软关键字,即可以在某些位置被视为关键字,但可以用作标识符的字符串。
空格
空白在某些语言中起着重要作用。 最著名的示例是Python,其中语句的缩进指示它是否属于特定代码块。
在大多数地方,即使在Python中,空格也无关紧要:单词或关键字之间的空格并不重要。 真正的问题是缩进,它用于识别代码块。 处理它的最简单方法是在行的开头检查缩进并转换为适当的令牌,即,当缩进与前一行不同时创建令牌。
实际上,缩进增加或减少时,词法分析器中的自定义函数会生成INDENT和DEDENT标记。 这些标记起类似C的语言的作用,用大括号括起来:它们指示代码块的开始和结束。
这种方法使词法化上下文敏感,而不是上下文无关。 这使解析变得复杂,您通常不希望这样做,但是在这种情况下,您不得不这样做。
多种语法
另一个常见的问题是一种语言实际上可能包含一些不同的语法。 换句话说,同一源文件可能包含遵循不同语法的代码段。 在有效分析的上下文中,同一源文件包含不同的语言。 最著名的例子可能是C或C ++预处理程序,它实际上是一种相当复杂的语言,可以神奇地出现在任何随机C代码中。
许多现代编程语言中都存在注释,这是一个较容易处理的情况。 除其他事项外,它们还可以用于在代码到达编译器之前对其进行处理。 他们可以命令注释处理器以某种方式转换代码,例如在执行带注释的代码之前执行特定功能。 它们更易于管理,因为它们只能出现在特定的位置。
悬空的其他
悬空的else是解析与if-then-else语句链接的链接时的常见问题。 由于else子句是可选的,因此if语句的序列可能不明确。 例如这个。
if one
then if two
then two
else ??? 不清楚else属于第一个if或第二个。
公平地说,这在很大程度上是语言设计的问题。 大多数解决方案并没有真正使解析变得如此复杂,例如,要求包含一个endif或需要使用块来分隔if语句(如果包含else子句), if会使解析变得复杂。
但是,也有一些语言不提供解决方案,也就是说,它们是模棱两可的,例如(您猜对了)C。常规方法是将else与最近的if语句相关联,这使得解析对上下文敏感。
解析树和抽象语法树
有两个相关的术语,有时有时可以互换使用: 解析树和抽象语法树 (AST)。 从技术上讲,解析树也可以称为具体语法树(CST),因为它至少应与AST相比,更具体地反映输入的实际语法。
从概念上讲,它们非常相似。 它们都是树 :有一个根,它的节点代表整个源代码。 根节点具有子节点,这些子节点包含代表代码越来越少的子树,直到树中出现单个标记(终端)为止。
区别在于抽象级别:解析树可能包含程序中出现的所有标记以及可能的一组中间规则。 AST而是解析树的完善版本,其中仅维护与理解代码有关的信息。 我们将在下一节中看到一个中间规则的示例。
AST和解析树中可能都缺少某些信息。 例如,注释和分组符号(即括号)通常不被表示。 对于程序来说,诸如注释之类的东西是多余的,而分组符号则由树的结构隐式定义。
从解析树到抽象语法树
解析树是更接近具体语法的代码表示。 它显示了解析器实现的许多细节。 例如,通常每个规则对应于特定类型的节点。 解析树通常由用户在AST中转换,可能需要解析器生成器的一些帮助。 一个公共帮助允许注释语法中的某些规则,以从生成的树中排除相应的节点。 另一个选择是如果某些节点只有一个子节点,则可以折叠这些节点。
这是有道理的,因为解析树是解析过程的直接表示,因此更易于为解析器生成。 但是,通过程序的以下步骤,AST更简单,更容易处理。 它们通常包括您可能希望在树上执行的所有操作:代码验证,解释,编译等。
让我们看一个简单的示例,以显示解析树和AST之间的区别。 让我们从一个示例语法开始。
// lexer
PLUS: '+'
WORD_PLUS: 'plus'
NUMBER: [0-9]+
// parser
// the pipe | symbol indicate an alternative between the two
sum: NUMBER (PLUS | WORD_PLUS) NUMBER 在此语法中,我们可以使用符号加号( + )或字符串plus作为运算符来定义总和。 假设您必须解析以下代码。
10 plus 21这些可能是结果分析树和抽象语法树。
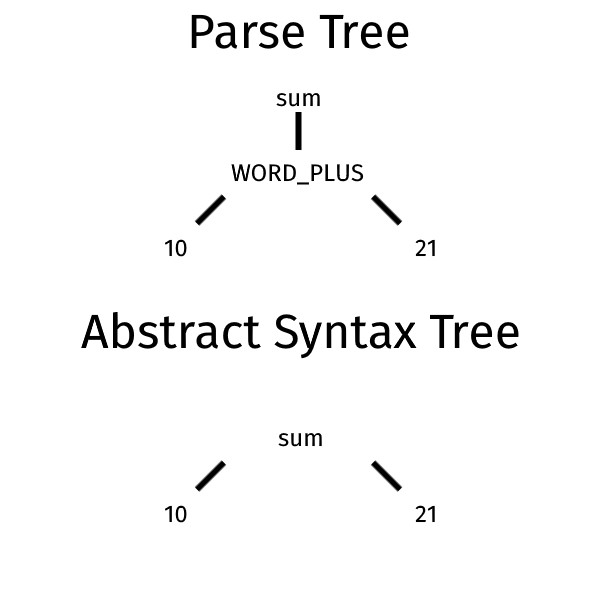
在AST中,特定操作员的指示消失了,剩下的就是要执行的操作。 特定运算符是中间规则的示例。
一棵树的图形表示
解析器的输出是一棵树,但是该树也可以以图形方式表示。 这是为了使开发人员更容易理解。 一些解析生成器工具可以使用DOT语言(一种用于描述图形的语言)输出文件(树是一种特殊的图形)。 然后,将此文件馈入一个程序,该程序可以从该文本描述(例如Graphviz )开始创建图形表示。
基于前面的求和示例,让我们看一个.DOT文本。
digraph sum {
sum -> 10;
sum -> 21;
}适当的工具可以创建以下图形表示。
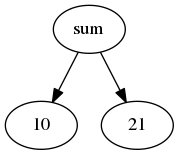
如果您想了解更多DOT,请阅读我们的文章语言服务器协议:带有Visual Studio Code的DOT的语言服务器 。 在那篇文章中,我们展示了如何创建一个可以处理DOT文件的Visual Studio Code插件。
文法

语法是用于描述语言的一组规则,因此研究规则的格式很自然。 但是,典型语法中也有一些元素可能需要进一步注意。 其中一些是由于语法还可以用于定义其他职责或执行某些代码的事实。
典型的语法问题
首先,我们将讨论一些特殊的规则或您在解析中可能遇到的问题。
丢失的代币
如果您阅读语法,您可能会遇到许多语法,其中仅定义了一些标记,而并非全部。 像这样的语法:
NAME : [a-zA-Z]+
greeting : "Hello" NAME 令牌"Hello"没有定义,但是由于您知道解析器处理令牌,因此您可能会问自己这怎么可能。 答案是某些工具会为您生成字符串文字的相应标记,以节省您的时间。
请注意,只有在某些条件下才可能这样做。 例如,如果您定义了单独的词法分析器和解析器语法,则必须使用ANTLR自己定义所有标记。
左递归规则
在解析器的上下文中,一个重要的功能是对左递归规则的支持。 这意味着规则从对自身的引用开始。 有时,该引用也可能是间接的,也就是说,它可能出现在第一个引用的另一条规则中。
考虑例如算术运算。 一个加法器可以描述为两个由加号( + )分隔的表达式,但是加法器的操作数可以是其他加法器。
addition : expression '+' expression
multiplication : expression '*' expression
// an expression could be an addition or a multiplication or a number
expression : multiplication | addition | [0-9]+在此示例中, 表达式通过规则加法和乘法包含对自身的间接引用。
此说明还匹配5 + 4 + 3类的多个加法项。 那是因为它可以解释为expression (5) ('+') expression(4+3) (规则加法:第一个表达式对应于选项[0-9] +,第二个表达式是另一个加法)。 然后4 + 3本身可以分为两个部分: expression(4) ('+') expression(3) (规则附加:第一个和第二个表达式都对应于选项[0-9] +)。
问题在于,某些解析器生成器可能无法使用左递归规则。 另一种选择是一长串表达式,它还要注意运算符的优先级。 不支持此类规则的解析器的典型语法看起来与此类似:
expression : addition
addition : multiplication ('+' multiplication)*
multiplication : atom ('*' atom)*
atom : [0-9]+如您所见,这些表达式以优先顺序相反的顺序定义。 因此,解析器会将优先级较低的表达式放在三个表达式中的最低级别。 因此将首先执行它们。
一些解析器生成器支持直接的左递归规则,但不支持间接的规则。 请注意,通常问题出在解析算法本身,它不支持左递归规则。 因此,解析器生成器可以以正确的方式转换写为左递归的规则,以使其与算法一起工作。 从这个意义上讲,左递归支持可能是(非常有用的)语法糖。
左递归规则如何转换
从一个解析器生成器到另一个解析器生成器,转换规则的特定方式有所不同,但是逻辑保持不变。 表达式分为两组:带有运算符和两个操作数的表达式以及原子的表达式。 在我们的示例中,唯一的原子表达式是数字( [0-9]+ ),但是它也可以是括号之间的表达式( (5 + 4) )。 这是因为在数学中,括号用于增加表达式的优先级。
拥有这两个组之后:维护第二个组的成员的顺序,然后反转第一个组的成员的顺序。 原因是人类基于先到先得的原则进行推理:更容易按照其优先顺序来编写表达式。
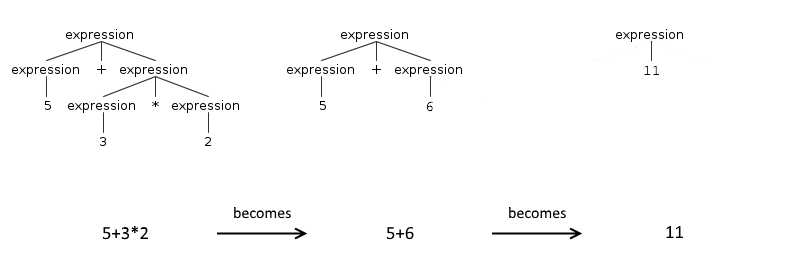
但是,解析的最终形式是一棵树,它以不同的原理运行:您开始在树叶上工作并上升。 这样,在此过程结束时,根节点将包含最终结果。 这意味着在解析树中,原子表达式位于底部,而带有运算符的原子表达式则按相反的顺序出现。
谓词
谓词 ,有时也称为句法或语义谓词 ,是仅在满足特定条件时才匹配的特殊规则。 条件由编写语法的工具支持的编程语言中的代码定义。
它们的优点是它们允许某种形式的上下文相关的解析,这有时在匹配某些元素时不可避免。 例如,它们可以用来确定在定义软关键字的字符序列是在将用作关键字的位置(例如,先前的标记可以紧随关键字之后)还是简单的标识符。
缺点是它们减慢了解析速度,并使语法依赖于所述编程语言。 这是因为条件是用编程语言表示的,因此必须进行检查。
嵌入式动作
嵌入式操作标识每次匹配规则时执行的代码。 由于规则被代码包围,它们具有明显的缺点,使语法难以阅读。 此外,就像谓词一样,它们打破了描述语言的语法与操纵解析结果的代码之间的分隔。
不那么复杂的解析生成器通常将动作用作当节点匹配时轻松执行某些代码的唯一方法。 使用这些解析器生成器,唯一的选择是遍历树并自己执行正确的代码。 相反,更高级的工具允许使用访问者模式在需要时执行任意代码,并且还可以控制树的遍历。
它们还可以用于添加某些标记或更改生成的树。 虽然很丑陋,但这可能是处理复杂语言(如C)或特定问题(如Python中的空白)的唯一实用方法。
格式
语法有两种主要格式:BNF(及其变体)和PEG。 许多工具实现了这些理想格式的自己的变体。 一些工具完全使用自定义格式。 常见的自定义格式包括三部分语法:选项和自定义代码,然后是词法分析器部分,最后是解析器。
由于类似BNF的格式通常是无上下文语法的基础,因此您也可以像CFG格式一样识别它。
巴科斯-瑙尔形式及其变体
Backus–Naur形式 (BNF)是最成功的形式,甚至是PEG的基础。 但是,它非常简单,因此不经常以其基本形式使用。 通常使用更强大的变体。
为了说明为什么需要这些变体,让我们在BNF中显示一个示例:字符描述。
<letter> ::= "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z"
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
<character> ::= <letter> | <digit>可以将符号<letter>转换为英语字母中的任何字母,尽管在我们的示例中,仅小写字母有效。 <digit>也会发生类似的过程,它可以指示备用数字中的任何数字。 第一个问题是您必须逐一列出所有替代方案。 您不能像使用正则表达式一样使用字符类。 这很烦人,但通常很容易管理,除非您必须列出所有Unicode字符。
一个更棘手的问题是,没有简单的方法来表示可选元素或重复项。 因此,如果要这样做,则必须依赖布尔逻辑和替代( | )符号。
<text> ::= <character> | <text> <character>该规则指出, <text>可以由字符或较短的<text>后面跟随<character>组成 。 这将是“狗”一词的解析树。
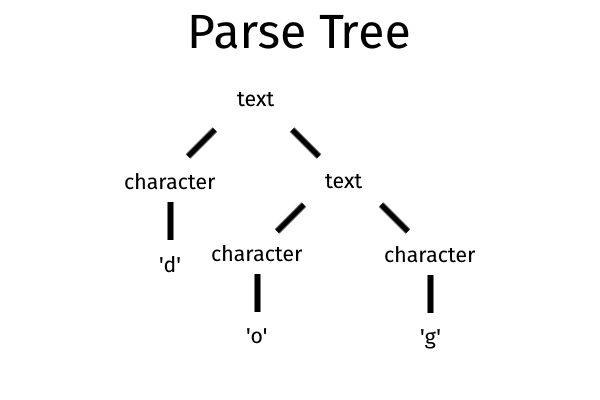
BNF还有许多其他局限性:使用空字符串或语法中格式(例如::= )所使用的符号会使情况变得复杂,它具有冗长的语法(例如,您必须在<和>之间包含终端),等等
扩展巴科斯-纳尔形式
为了解决这些局限性,Niklaus Wirth创建了扩展Backus-Naur形式 (EBNF),其中包括来自他自己的Wirth语法符号的一些概念。
EBNF是现代解析工具中最常用的形式,尽管工具可能会偏离标准符号。 EBNF具有更简洁的表示法,并采用更多的运算符来处理串联或可选元素。
让我们看看如何用EBNF编写前面的示例。
letter = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" ;
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
character = letter | digit ;
text = character , { character } ; 现在,借助串联运算符( , )和可选的符号( { .. } ),可以更轻松地描述文本符号。 生成的解析树也将更简单。 标准EBNF仍然存在一些问题,例如不熟悉的语法。 为了克服这个问题,大多数解析工具采用了受正则表达式启发的语法,并且还支持字符类之类的其他元素。
如果您需要对该格式的深入了解,可以阅读我们关于EBNF的文章。
ABNF
增强型BNF (ABNF)是BNF的另一种变体,主要是为了描述双向通信协议而开发的,并由IETF用几份文档进行了形式化(请参阅RFC 5234和更新)。
ABNF可以像EBNF一样高效,但是它有一些怪癖,限制了它在互联网协议之外的采用。 例如,直到最近,该标准仍要求以不区分大小写的方式匹配字符串,这在许多编程语言中匹配标识符都是一个问题。
ABNF has a different syntax from EBNF, for example the alternative operator is the slash ( / ), and sometimes it is plainly better. For instance, there is no need for a concatenation operator. It also has a few more things than standard EBNF. For instance, it allows you to define numeric ranges, such as %x30-39 that is equivalent to [0-9] . This is also used by the designers themselves, to include standard character classes-like basic rules that the end user can use. An example of such rule is ALPHA, that is equivalent to [a-zA-Z] .
聚乙二醇
Parsing Expression Grammar (PEG) is a format presented by Brian Ford in a 2004 paper . Technically it derives from an old formal grammar called Top-Down Parsing Language (TDPL). However a simple way to describe is: EBNF in the real world.
In fact it looks similar to EBNF, but also directly support things widely used, like character ranges (character classes). Although it also has some differences that are not actually that pragmatic, like using the more formal arrow symbol ( ← ) for assignment, instead of the more common equals symbol ( = ). The previous example could be written this way with PEG.
letter ← [a-z]
digit ← [0-9]
character ← letter / digit
text ← character+ As you can see, this is the most obvious way a programmer would write it, with character classes and regular expression operators. The only anomalies are the alternative operator ( / ) and the arrow character, and in fact many implementation of PEG use the equals character.
The pragmatic approach is the foundation of the PEG formalism: it was created to describe more naturally programming languages. That is because context-free grammar has its origin in the work to describe natural languages. In theory, CFG is a generative grammar, while PEG an analytic grammar.
The first should be a sort of recipe to generate only the valid sentences in the language described by the grammar. It does not have to be related to the parsing algorithm. Instead the second kind define directly the structure and semantics of a parser for that language.
PEG vs CFG
The practical implications of this theoretical difference are limited: PEG is more closely associated to the packrat algorithm, but that is basically it. For instance, generally PEG (packrat) does not permits left recursion. Although the algorithm itself can be modified to support it, this eliminate the linear-time parsing property. Also, PEG parsers generally are scannerless parsers.
Probably the most important difference between PEG and CFG is that the ordering of choices is meaningful in PEG, but not in CFG. If there are many possible valid ways to parse an input, a CFG will be ambiguous and thus will return an error. By usually wrong we mean that some parsers that adopt CFGs can deal with ambiguous grammars. For instance, by providing all possible valid results to the developer and let him sort it out. Instead PEG eliminate ambiguity altogether because the first applicable choice will be chosen, thus a PEG can never be ambiguous.
The disadvantage of this approach is that you have to be more careful in listing possible alternatives, because otherwise you could have unexpected consequences. That is to say some choices could never be matched.
In the following example doge will never be matched, since dog comes first it will be picked each time.
dog ← 'dog' / 'doge'It is an open area of research whether PEG can describe all grammars that can be defined with CFG, but for all practical purposes they do.
Parsing Algorithms

In theory parsing is a solved problem, but it is the kind of problem that keep being solved again and again. That is to say that there are many different algorithms, each one with strong and weak points, and they are still improved by academics.
In this section we are not going to teach how the implement every one of the parsing algorithm, but we are going to explain their features. The goal is that you can choose with more awareness which parsing tool to use, or which algorithm to study better and implement for your custom parser.
总览
Let's start with a global overview of the features and strategies of all parsers.
Two Strategies
There are two strategies for parsing: top-down parsing and bottom-up parsing . Both terms are defined in relation to the parse tree generated by the parser. In a simple way:
- a top-down parser tries to identity the root of the parse tree first, then it moves down the subtrees, until it find the leaves of the tree.
- a bottom-up parses instead starts from the lowest part of the tree, the leaves, and rise up until it determines the root of the tree.
Let's see an example, starting with a parse tree.
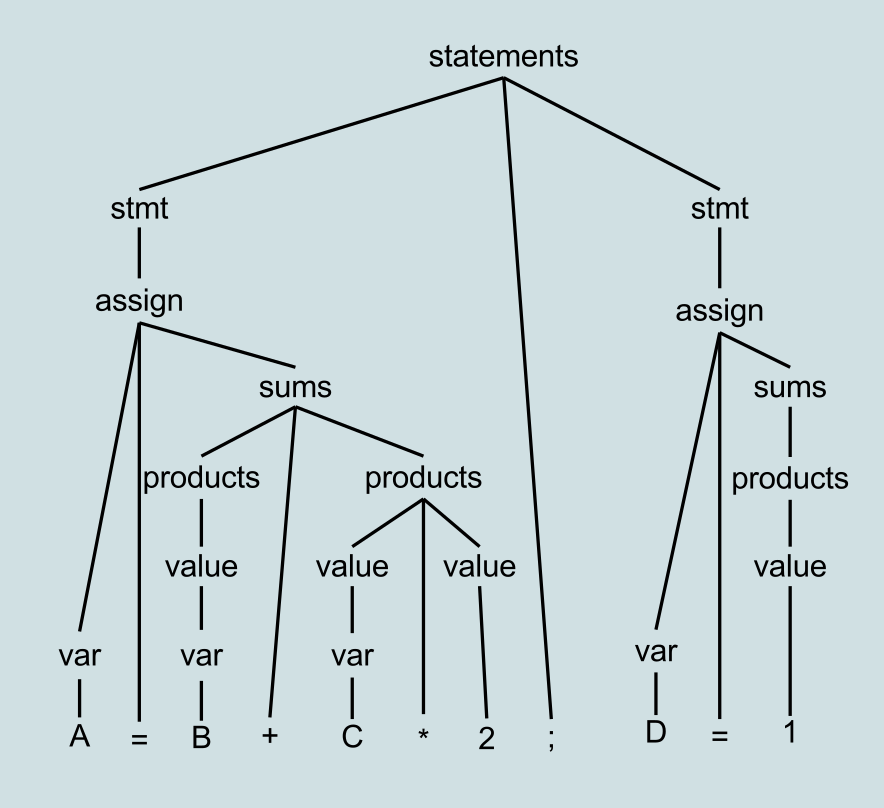
Example Parse Tree from Wikipedia
The same tree would be generate in a different order, by a top-down and a bottom-up parser. In the following images the number indicate the order in which the nodes are created.
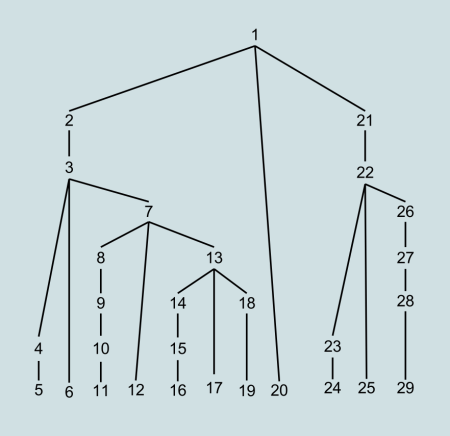
Top-down order of generation of the tree (from Wikipedia)
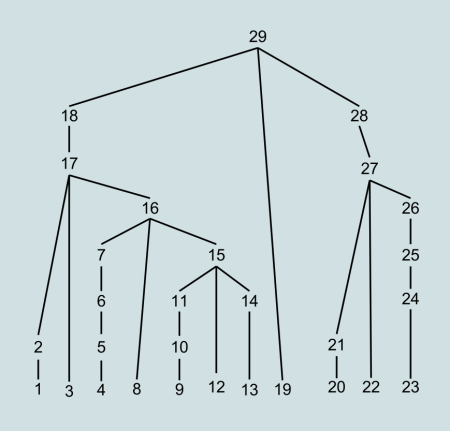
Bottom-up order of generation of the tree (from Wikipedia)
Traditionally top-down parsers were easier to build, but bottom-up parsers were more powerful. Now the situation is more balanced, mostly because of advancement in top-down parsing strategies.
The concept of derivation is closely associated to the strategies. Derivation indicates the order in which the nonterminal elements that appears in the rule, on the right, are applied to obtain the nonterminal symbol, on the left. Using the BNF terminology, it indicates how the elements that appear in __expression__ are used to obtain <symbol>. The two possibilities are: leftmost derivation and rightmost derivation . The first indicate the rule are applied from left to right, while the second indicate the opposite.
A simple example: imagine that you are trying to parse the symbol result which is defined as such in the grammar.
expr_one = .. // stuff
expr_two = .. // stuff
result = expr_one 'operator' expr_two You can apply first the rule for symbol expr_one and then expr_two or vice versa. In the case of leftmost derivation you pick the first option, while for rightmost derivation you pick the second one.
It is important to understand that the derivation is applied depth-first or recursively. That is to say, it is applied on the starting expression then it is applied again on the intermediate result that is obtained. So, in this example, if after applying the rule corresponding to expr_one there is a new nonterminal, that one is transformed first. The nonterminal expr_two is applied only when it becomes the first nonterminal and not following the order in the original rule.
Derivation is associated with the two strategies, because for bottom-up parsing you would apply rightmost derivation, while for top-down parsing you would choose leftmost derivation. Note that this has no effect on the final parsing tree, it just affects the intermediate elements and the algorithm used.
Common Elements
Parsers built with top-down and bottom-up strategies shares a few elements that we can talk about.
Lookahead and Backtracking
The terms lookadhead and backtracking do not have a different meaning in parsing than the one they have in the larger computer science field. Lookahead indicates the number of elements, following the current one, that are taken into consideration to decide which current action to take.
A simple example: a parser might check the next token to decide which rule to apply now. When the proper rule is matched the current token is consumed, but the next one remains in the queue.
Backtracking is a technique of an algorithm. It consists in finding a solution to a complex problems by trying partial solutions, and then keep checking the most promising one. If the one that is currently tested fails, then the parser backtracks (ie, it goes back to the last position that was successfully parsed) and try another one.
They are especially relevant to LL , LR and LALR parsing algorithms, because parsers for language that just needs one lookahead token are easier to build and quicker to run. The lookahead tokens used by such algorithms are indicated between parentheses after the name of the algorithm (eg, LL(1), LR( k )). The notation (*) indicate that the algorithm can check infinite lookahead tokens, although this might affect the performance of the algorithm.
Chart Parsers
Chart parsers are a family of parsers that can be bottom-up (eg, CYK) or top-down (eg, Earley). Chart parsers essentially try to avoid backtracking, which can be expensive, by using dynamic programming . Dynamic programming , or dynamic optimization, is a general method to break down larger problem in smaller subproblems.
A common dynamic programming algorithm used by chart parser is the Viterbi algorithm . The goal of the algorithm is to find the most likely hidden states given the sequence of known events. Basically given the tokens that we know, we try to find the most probable rules that have produced them.
The name chart parser derives from the fact that the partial results are stored in a structure called chart (usually the chart is a table). The particular technique of storing partial results is called memoization . Memoization is also used by other algorithms, unrelated to chart parsers, like packrat .
Automatons
Before discussing parsing algorithms we would like to talk about the use of automatons in parsing algorithms. Automaton are a family of abstract machines, among which there is the well known Turing machine .
When it comes to parsers you might here the term (Deterministic) Pushdown Automaton (PDA) and when you read about lexers you would hear the term Deterministic Finite Automaton (DFA). A PDA is more powerful and complex than a DFA (although still simpler than a Turing machine).
Since they define abstract machines, usually they are not directly related to an actual algorithm. Rather, they describe in a formal way the level of complexity that an algorithm must be able to deal with. If somebody says that to solve problem X you need a DFA, he means that you need an algorithm as equally powerful as a DFA.
However since DFA are state machines in the case of lexer the distinction is frequently moot . That is because state machines are relative straightforward to implement (ie, there are ready to use libraries), so most of the time a DFA is implemented with a state machine. That is why we are going to briefly talk about DFA and why they are frequently used for lexers.
Lexing With a Deterministic Finite Automaton
DFA is a (finite-)state machine, a concept with which we assume you are familiar. Basically, a state machine has many possible states and a transition function for each of them. These transition functions govern how the machine can move from one state to a different one in response to an event. When used for lexing, the machine is fed the input characters one at a time until it reach an accepted state (ie, it can build a token).
They are used for a few reasons:
- it has been proven that they recognize exactly the set of regular languages, that is to say they are equally powerful as regular languages
- there are a few mathematical methods to manipulate and check their properties (eg, whether they can parse all strings or any strings)
- they can work with an efficient online algorithm (see below)
An online algorithm is one that does not need the whole input to work. In the case of a lexer, it means that can recognize a token as soon as its characters are seen by the algorithm. The alternative would be that it needed the whole input to identify each token.
In addition to these properties is fairly easy to transform a set of regular expressions in a DFA, which makes possible to input the rules in a simple way that is familiar to many developers. Then you can automatically convert them in a state machine that can work on them efficiently.
Tables of Parsing Algorithms
We provide a table to offer a summary of the main information needed to understand and implement a specific parser algorithm. You can find more implementations by reading our articles that present parsing tools and libraries for Java , C# , Python and JavaScript .
The table lists:
- a formal description, to explain the theory behind the algorithm
- a more practical explanation
- one or two implementations, usually one easier and the other a professional parser. Sometimes, though, there is no easier version or a professional one.
To understand how a parsing algorithm works you can also look at the syntax analytic toolkit . It is an educational parser generator that describes the steps that the generated parser takes to accomplish its objective. It implements a LL and a LR algorithm.
The second table shows a summary of the main features of the different parsing algorithms and for what they are generally used.
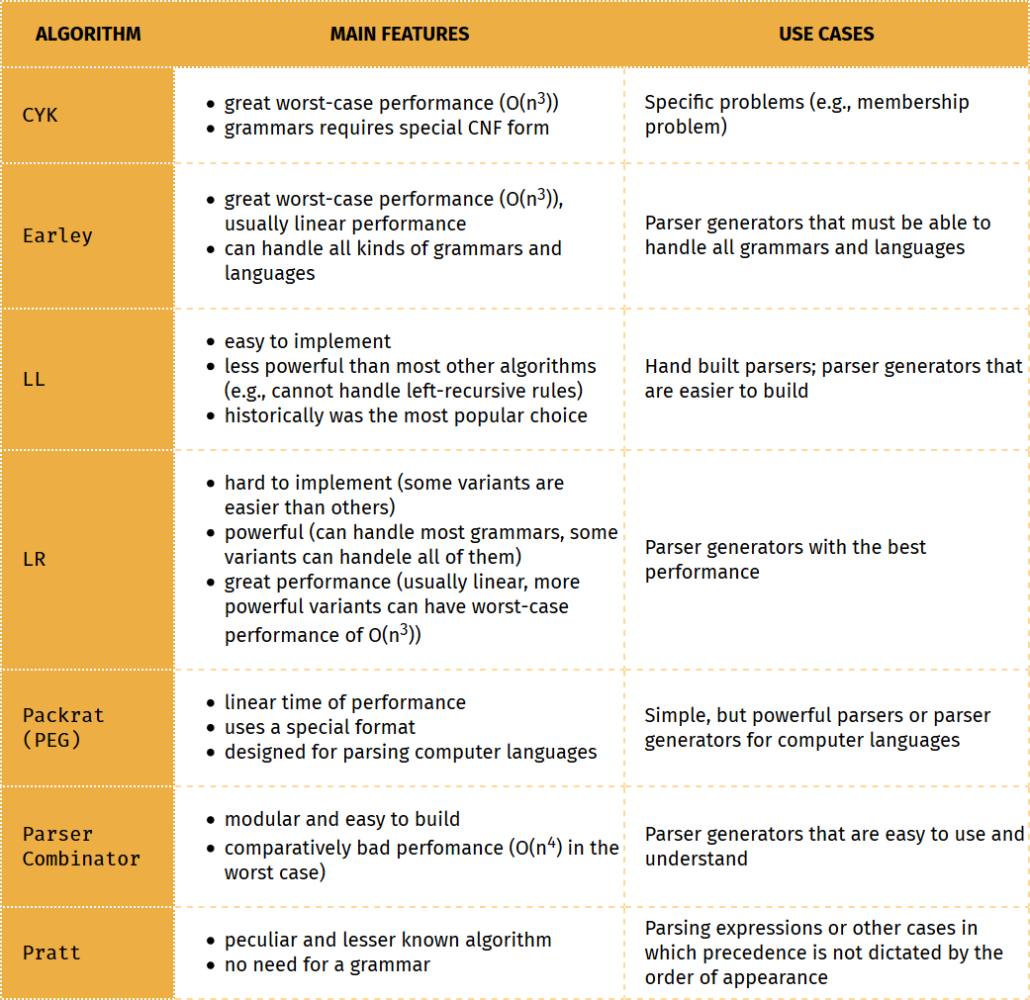
Top-down Algorithms
The top-down strategy is the most widespread of the two strategies and there are several successful algorithms applying it.
LL Parser
LL ( L eft-to-right read of the input, L eftmost derivation) parsers are table-based parsers without backtracking, but with lookahead. Table-based means that they rely on a parsing table to decide which rule to apply. The parsing table use as rows and columns nonterminals and terminals, respectively.
To find the correct rule to apply:
- firstly the parser look at the current token and the appropriate amount of lookahead tokens
- then it tries to apply the different rules until it finds the correct match.
The concept of LL parser does not refers to a specific algorithm, but more to a class of parsers. They are defined in relations to grammars. That is to say an LL parser is one that can parse a LL grammar. In turn LL grammars are defined in relation to the number of lookahead tokens that are needed to parse them. This number is indicated between parentheses next to LL, so in the form LL( k ).
An LL( k ) parser uses k tokens of lookahead and thus it can parse, at most, a grammar which need k tokens of lookahead to be parsed. Effectively the concept of LL( k ) grammar is more widely employed than the corresponding parser. Which means that LL( k ) grammars are used as a meter when comparing different algorithms. For instance, you would read that PEG parsers can handle LL(*) grammars.
The Value Of LL Grammars
This use of LL grammars is due both to the fact that LL parser are widely used and that they are a bit restrictive. In fact, LL grammars does not support left-recursive rules. You can transform any left-recursive grammar in an equivalent non-recursive form, but this limitation matters for a couple of reasons: productivity and power.
The loss of productivity depends on the requirement that you have to write the grammar in a special way, which takes time. The power is limited because a grammar that might need 1 token of lookahead, when written with a left-recursive rule, might need 2-3 tokens of lookahead, when written in a non-recursive way. So this limitation is not merely annoying, but it is limiting the power of the algorithm, ie, the grammars it can be used for.
The loss of productivity can be mitigated by an algorithm that automatically transforms a left-recursive grammar in a non-recursive one. ANTLR is a tool that can do that, but, of course, if you are building your own parser, you have to do that yourself.
There are two special kind of LL( k ) grammars: LL(1) and LL(*). In the past the first kinds were the only one considered practical, because it is easy to build efficient parsers for them. Up to the point that many computer languages were purposefully designed to be described by a LL(1) grammar. An LL(*), also known as LL-regular , parser can deal with languages using an infinite amount of lookahead tokens.
On StackOverflow you can read a simple comparison between LL parsers and Recursive Descent parsers or one between LL parsers and LR parsers .
Earley Parser
The Earley parser is a chart parser named after its inventor Jay Earley. The algorithm is usually compared to CYK, another chart parser, that is simpler, but also usually worse in performance and memory . The distinguishing feature of the Earley algorithm is that, in addition to storing partial results, it implement a prediction step to decide which rule is going to try to match next.
The Earley parser fundamentally works by dividing a rule in segments, like in the following example.
// an example grammar
HELLO : "hello"
NAME : [a-zA-Z]+
greeting : HELLO NAME
// Earley parser would break up greeting like this
// . HELLO NAME
// HELLO . NAME
// HELLO NAME . Then working on this segments, that can be connected at the dot ( . ), tries to reach a completed state, that is to say one with the dot at the end.
The appeal of an Earley parser is that it is guaranteed to be able to parse all context-free languages, while other famous algorithms (eg, LL, LR) can parse only a subset of them. For instance, it has no problem with left-recursive grammars. More generally, an Earley parser can also deal with nondeterministic and ambiguous grammars.
It can do that at the risk of a worse performance (O(n 3 )), in the worst case. However it has a linear time performance for normal grammars. The catch is that the set of languages parsed by more traditional algorithms are the one we are usually interested in.
There is also a side effect of the lack of limitations: by forcing a developer to write the grammar in certain way the parsing can be more efficient. Ie, building a LL(1) grammar might be harder for the developer, but the parser can apply it very efficiently. With Earley you do less work, so the parser does more of it.
In short, Earley allows you to use grammars that are easier to write, but that might be suboptimal in terms of performance.
Earley Use Cases
So Earley parsers are easy to use, but the advantage, in terms of performance, in the average case might be non-existent. This makes the algorithm great for an educational environment or whenever productivity is more relevant than speed.
In the first case is useful, for example, because most of the time the grammars your users write work just fine. The problem is that the parser will throw at them obscure and seemingly random errors. Of course the errors are not actually random, but they are due to the limitations of an algorithm that your users do not know or understand. So you are forcing the user to understand the inner workins of your parser to use it, which should be unnecessary.
An example of when productivity is more important than speed might be a parser generator to implement syntax highlighting, for an editor that need to support many languages. In a similar situation, being able to support quickly new languages might be more desirable than completing the task as soon as possible.
Packrat (PEG)
Packrat is often associated to the formal grammar PEG, since they were invented by the same person: Bryan Ford. Packrat was described first in his thesis: Packrat Parsing: a Practical Linear-Time Algorithm with Backtracking . The title says almost everything that we care about: it has a linear time of execution, also because it does not use backtracking.
The other reason for its efficiency it is memoization: the storing of partial results during the parsing process. The drawback, and the reason because the technique was not used until recently, is the quantity of memory it needs to store all the intermediate results. If the memory required exceed what is available, the algorithm loses its linear time of execution.
Packrat also does not support left-recursive rules, a consequence of the fact that PEG requires to always choose the first option. Actually some variants can support direct left-recursive rules, but at the cost of losing linear complexity.
Packrat parsers can perform with an infinite amount of lookahead, if necessary. This influence the execution time, that in the worst case can be exponential.
Recursive Descent Parser
A recursive descent parser is a parser that works with a set of (mutually) recursive procedures, usually one for each rule of the grammars. Thus the structure of the parser mirrors the structure of the grammar.
The term predictive parser is used in a few different ways: some people mean it as a synonym for top-down parser, some as a recursive descent parser that never backtracks.
The opposite to this second meaning is a recursive descent parser that do backtracks. That is to say one that find the rule that matches the input by trying each one of the rules in sequence, and then it goes back each time it fails.
Typically recursive descent parser have problems parsing left-recursive rules, because the algorithm would end up calling the same function again and again. A possible solution to this problem is using tail recursion. Parsers that use this method are called tail recursive parsers .
Tail recursion per se is simply recursion that happens at the end of the function. However tail recursion is employed in conjuction with transformations of the grammar rules. The combination of transforming the grammar rules and putting recursion at the end of the process allows to deal with left-recursive rules.
Pratt Parser
A Pratt parser is a widely unused, but much appreciated (by the few that knows it) parsing algorithm defined by Vaughan Pratt in a paper called Top Down Operator Precedence . The paper itself starts with a polemic on BNF grammars, which the author argues wrongly are the exclusive concerns of parsing studies. This is one of the reasons for the lack of success. In fact the algorithm does not rely on a grammar, but works directly on tokens, which makes it unusual to parsing experts.
The second reason is that traditional top-down parsers works great if you have a meaningful prefix that helps distinguish between different rules. For example, if you get the token FOR you are looking at a for statement. Since this essentially applies to all programming languages and their statements, it is easy to understand why the Pratt parser did not change the parsing world.
Where the Pratt algorithm shines is with expressions. In fact, the concept of precedence makes impossible to understand the structure of the input simply by looking at the order in which the tokens are presented.
Basically, the algorithm requires you to assign a precedence value to each operator token and a couple of functions that determines what to do, according to what is on the left and right of the token. Then it uses these values and functions to bind the operations together while it traverse the input.
While the Pratt algorithm has not been overtly successful it is used for parsing expressions. It is also adopted by Douglas Crockford (of JSON fame) for JSLint.
Parser Combinator
A parser combinator is a higher-order function that accepts parser functions as input and return a new parser function as output. A parser function usually means a function that accepts a string and output a parse tree.
A parser combinator is modular and easy to build, but they are also slower (the have O(n 4 ) complexity in the worst case) and less sophisticated. They are typically adopted for easier parsing tasks or for prototyping. In a sense the user of a parser combinator builds the parser partially by hand, but relying on the hard word done by whoever created the parser combinator.
Generally they do not support left recursive rules, but there are more advanced implementations that do just that. See, for example, the paper Parser Combinators for Ambiguous Left-Recursive Grammars , that also manages to describe an algorithm that has polynomial time of execution.
Many contemporary implementations are called monadic parser combinator , since they rely on the structure of functional programming called monad . Monads are a fairly complex concept that we cannot hope to explain here. However basically a monad is able to combine functions and actions relying on a data type. The crucial feature is that the data type specifies how its different values can be combined.
The most basic example is the Maybe monad. This is a wrapper around a normal type, like integer, that returns the value itself when the value is valid (eg, 567), but a special value Nothing when it is not (eg, undefined or division by zero). Thus you can avoid using a null value and unceremoniously crashing the program. Instead the Nothing value is managed normally, like it would manage any other value.
Bottom-up Algorithms
The bottom-up strategy main success is the family of many different LR parsers. The reason of their relative unpopularity is because historically they have been harder to build, although LR parser are also more powerful than traditional LL(1) grammars. So we mostly concentrate on them, apart from a brief description of CYK parsers.
This means that we avoid talking about the more generic class of Shift-reduce Parser , which also includes LR parsers.
We only say that shift-reduce algorithms works with two steps:
- Shift : read one token from the input, that becomes a new (momentarily isolated) node
- Reduce : once the proper rule is matched join the resulting tree with a precedent existing subtree
Basically the shift step read the input until completion, while the reduce join the subtrees until the final parse tree is built.
CYK Parser
The Cocke-Younger-Kasami (CYK) it has been formulated independently by the three authors. Its notability is due to a great worst-case performance (O(n 3 )), although it is hampered by a comparatively bad performance in most common scenarios.
However the real disadvantage of the algorithm is that it requires the grammars to be expressed in the Chomsky normal form .
That is because the algorithm relies on the properties of this particular form to be able to split the input in half to trying matching all the possibilities. Now, in theory, any context-free grammar can be transformed in a corresponding CNF, but this is seldom practical to do by hand. Imagine being annoyed by the fact that you cannot use left-recursive rules and being asked to learn a special kind of form…
The CYK algorithm is used mostly for specific problems. For instance the membership problem: to determine if a string is compatible with a certain grammar. It can also be used in natural language processing to find the most probable parsing between many options.
For all practical purposes, if you need to parser all context-free grammar with a great worst-case performance, you want to use an Earley parser.
LR Parser
LR ( L eft-to-right read of the input, R ightmost derivation) parsers are bottom-up parsers that can handle deterministic context-free languages in linear time, with lookahead and without backtracking. The invention of LR parsers is credited to the renown Donald Knuth.
Traditionally they have been compared, and competed, with LL parsers. So there is a similar analysis related to the number of lookahead tokens necessary to parse a language. An LR( k ) parser can parse grammars that need k tokens of lookahead to be parsed. However LR grammars are less restrictive, and thus more powerful, than the corresponding LL grammars. For example, there is no need to exclude left-recursive rules.
Technically, LR grammars are a superset of LL grammars. One consequence of this is that you need only LR(1) grammars, so usually the ( k ) is omitted.
They are also table-based, just like LL-parsers, but they need two complicate tables. In very simple terms:
- one table tells the parser what to do depending on the current token, the state is in and the tokens that can possibly follow the current one (l ookahead sets )
- the other one tells the parser to which state move next
LR parsers are powerful and have great performance, so where is the catch? The tables they need are hard to build by hand and can grow very large for normal computer languages, so usually they are mostly used through parser generators. If you need to build a parser by hand, you would probably prefer a top-down parser.
Simple LR and Lookahead LR
Parser generators avoid the problem of creating such tables, but they do not solve the issue of the cost of generating and navigating such large tables. So there are simpler alternatives to the Canonical LR(1) parser , described by Knuth. These alternatives are less powerful than the original one. They are: Simple LR parser (SLR) and Lookahead LR parser (LALR). So in order of power we have: LR(1) > LALR(1) > SLR(1) > LR(0).
The names of the two parsers, both invented by Frank DeRemer, are somewhat misleading: one is not really that simple and the other is not the only one that uses lookahead. We can say that one is simpler, and the other rely more heavily on lookahead to make decisions.
Basically they differ in the tables they employ, mostly they change the what “to do” part and the lookahead sets. Which in turn pose different restrictions on the grammars that they can parse. In other words, they use different algorithms to derive the parsing tables from the grammar.
A SLR parser is quite restrictive in practical terms and it is not very used. A LALR parser instead works for most practical grammars and it is widely employed. In fact the popular tools yacc and bison works with LALR parser tables.
Contrary to LR grammars, LALR and SLR grammars are not a superset of LL grammars. They are not easily comparable: some grammars can be covered by one class and not the other or vice versa.
Generalized LR Parser
Generalized LR parsers (GLR) are more powerful variants of LR parsers. They were described by Bernard Land, in 1974, and implemented the first time by Masaru Tomita, in 1984. The reason for GLR existence is the need to parse nondeterministic and ambiguous grammars.
The power of a GLR parser is not found on its tables, which are equivalent to the one of a traditional LR parser. Instead it can move to different states. In practice, when there is an ambiguity it forks new parser(s) that handle that particular case. These parsers might fail at a later stage and be discarded.
The worst-case complexity of a GLR parser is the same of an Earley one (O(n 3 )), though it may have better performance with the best case of deterministic grammars. A GLR parser is also harder to build than an Earley one.
摘要
With this great (or at least large) article we hope to have solved most of the doubts about parsing terms and algorithms. What the terms means and why to pick a certain algorithm instead of another one. We have not just explained them, but we have given a few pointers for common issues with parsing programming languages.
For reason of space we could not provide a detailed explanation of all parsing algorithms. So we have also provided a few links to get a deeper understanding of the algorithms: the theory behind them and an explanation of how they work. If you are specifically interested in building things like compiler and interpreters, you can read another of our articles to find resources to create programming languages .
If you are just interested in parsing you may want to read Parsing Techniques , a book that is as comprehensive as it is expensive. It obviously goes much more in depth what we could, but it also cover less used parsing algorithms.
翻译自: https://www.javacodegeeks.com/2017/09/guide-parsing-algorithms-terminology.html















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}