





在第一部分(第一部分)中,我们通过看一个具体的示例介绍了一种在不破坏当前请求流和业务价值的情况下将微服务引入我们的体系结构的策略。 在第二部分中 ,我们开始研究与我们的架构策略和目标相符的伴随技术。 在第三部分中,我们继续第二部分的解决方案,重点关注如何添加可能需要与整体(至少在最初)共享数据的新服务,并将其添加到一些更复杂的部署方案中。 我们还将探索与Arquillian Algeron进行的消费者合同测试,以及如何使用它来处理服务体系结构中的API更改。
在Twitter或http://blog.christianposta.com上关注( @christianposta ),以获取最新更新和讨论。
技术领域
我们将使用的技术(在第II,III和IV部分中)可以帮助我们指导这一旅程:
- 开发人员服务框架( Spring Boot , WildFly , WildFly Swarm )
- API设计( APICur.io )
- 数据框架( Spring Boot Teiid , Debezium.io )
- 集成工具( Apache Camel )
- 服务网格( Istio服务网格 )
- 数据库迁移工具( Liquibase )
- 暗启动/功能标记框架( FF4J )
- 部署/ CI-CD平台( Kubernetes / OpenShift )
- Kubernetes开发人员工具( Fabric8.io )
- 测试工具( Arquillian , Pact / Arquillian Algeron , Hoverfly , Spring-Boot测试 , RestAssured , Arquillian Cube )
如果您想继续,我正在使用的示例项目基于http://developers.redhat.com上的TicketMonster教程,但已进行了修改,以显示从单片到微服务的演变。 您可以在github上找到代码和文档(文档仍在进行中!): https : //github.com/ticket-monster-msa/monolith
在第二部分中 ,我们沿着添加新的微服务(订单/预订)的路径走了,该服务将从整体中分离出来。 我们通过使用Hoverfly模拟合适的API来开始这一步骤
将API与实现连接
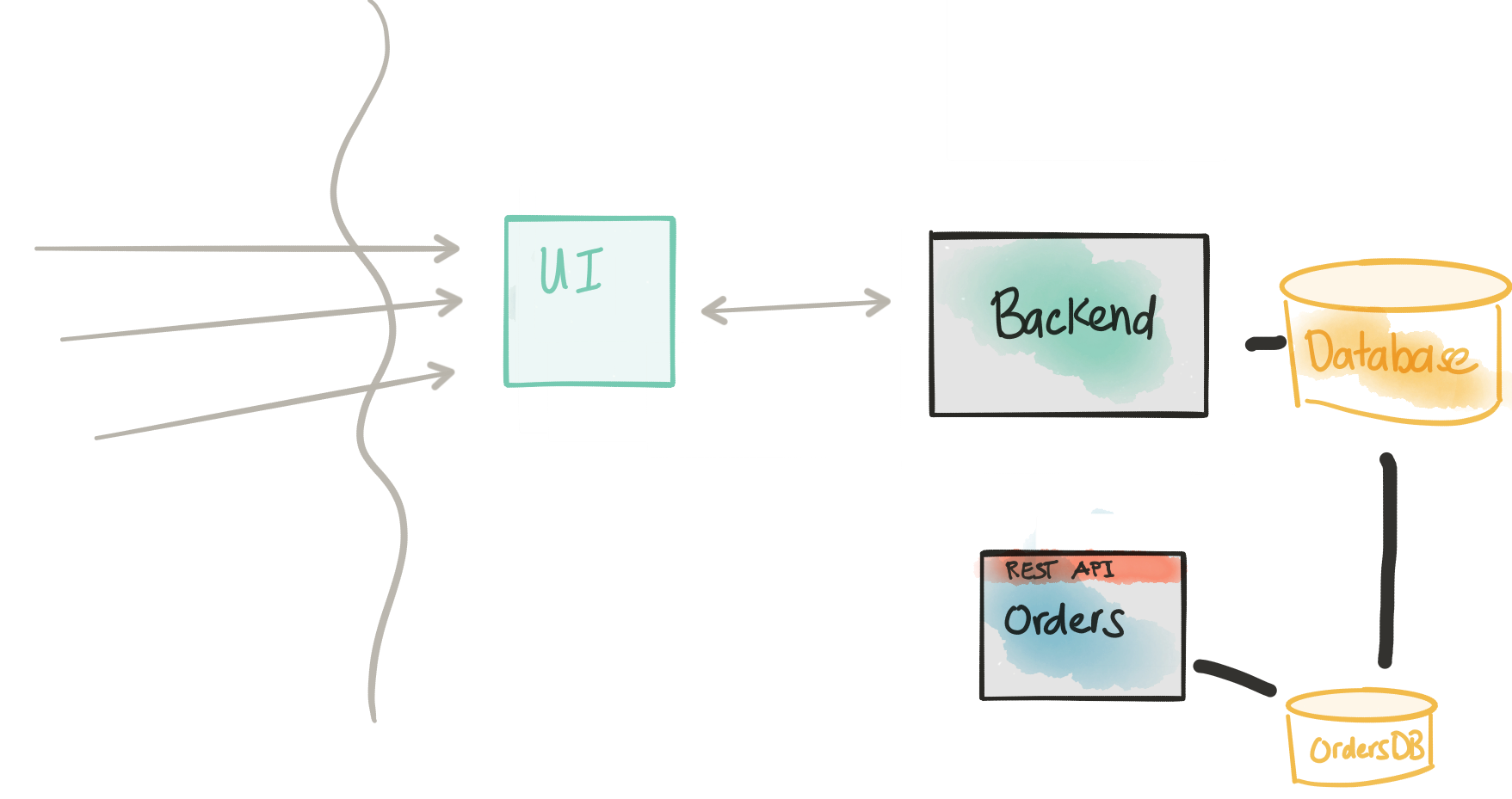
重新考虑注意事项
- 提取的/新的服务具有一个数据模型,根据定义,该数据模型与整体数据模型紧密耦合
- 整体很可能没有提供正确级别的API来获取此数据
- 即使获得数据也要整形数据需要大量样板代码
- 我们可以暂时直接连接到后端数据库以进行只读查询
- 整体数据库很少(如果有的话)更改其数据库
在第一部分中,我们暗示了一种解决方案,该解决方案涉及直接连接到Monolith数据库。 在我们的示例中,我们需要这样做,因为该数据库中的数据最初将是我们试图从整体中分解的新Orders服务的命脉。 另外,我们想引入这项新服务,使其能够承担负载,并与整体中的内容保持一致; 即,我们将同时运行两个一段时间。 请注意,这种操作恰好是我们分解工作的核心:我们不能仅仅神奇地开始调用一个新的微服务,该微服务正确封装了预订/订购的所有逻辑而又不影响当前的负载。
如果我们不想直接连接到整体数据库,我们有什么选择? 我可以想到一些……如果您想提出其他建议,请随时对我发表评论或发推文 :
- 使用整体展示的现有API
- 创建一个专门用于访问整体数据库的新API; 我们需要数据时随时调用
- 从整体到新服务进行ETL,因此我们已经有了数据
使用现有的API
如果可以做到,请务必进行探索。 但是,通常,现有的API通常是粗粒度的,不适合用于较低级别的用途,并且可能需要大量按摩才能进入您希望在新服务中使用的所需数据模型。 对于本示例中的新服务( Orders服务)中的每个来电,您需要查询(可能有多个端点)旧式/整体式API,并根据自己的喜好设计响应。 除非您开始采取让捷径/旧版API /数据模型强烈影响新服务的数据模型的捷径,否则这并没有本质上的问题。 即使至少在我的示例中,数据模型起初可能是相似的,我们还是要快速迭代(使用DDD)并获得正确的域模型,而不仅仅是标准化的数据模型。
创建一个新的底层API
如果现有的Monolith API粒度太粗(或根本不存在),或者您不想促进重用,则可以创建自己的较低级API,以直接连接到Monolith的数据库,并在新的Orders服务可能需要的级别公开数据。 这也可能是可接受的解决方案。 另一方面,我所经历的是,新的Orders服务最终向此新的较低层接口编写了许多查询/ API调用,并对响应进行了内存中联接(类似于上一个选项)。 还可能感觉像我们正在实现数据库。 同样,此操作本质上没有错,但是,这为Orders服务留下了很多样板代码来编写–其中很多都用作临时的临时解决方案。
从整体到新服务进行ETL
在某些时候,我们确实可能需要这样做。 但是,在我们研究新服务的域模型时,我们可能不想处理旧的整体结构。 此外,我们打算同时运行新服务和整体服务; 我们希望两者都能吸引流量。 如果我们采用ETL方法,那么我们将需要一种使Orders服务保持最新状态的方法,因为事情可能会Swift失去同步。 这最终是一场噩梦。
作为新Orders服务的开发人员,我们想从对我们的服务有意义的领域模型(请注意:我没有说数据模型–有所不同)的角度进行思考。 我们希望尽可能消除外部实现的影响,这些影响可能会损害我们的域模型。 区别在于:数据模型显示了我们系统中的(静态)数据之间如何相互关联,并可能为如何将数据存储在持久层中提供了指导。 领域模型用于描述我们领域的解决方案空间的行为 ,并且倾向于更多地关注用例/事务行为。 即,我们用来传达问题所在的概念或模型。 DDD大师沃恩•弗农(Vaughn Vernon) 撰写了大量的文章,详细论述了这种区别 。
我在Ticket Monster订单服务的Orders服务中使用的解决方案是使用一个名为Teiid的开源项目,该项目有助于减少/消除将数据模型转化为理想域模型的样板。 传统上,Teiid一直是一种数据联合软件,能够提取不同的数据源(关系数据库,NoSQL,平面文件等)并将其显示为单个虚拟视图。 通常,数据分析人员将使用它来汇总数据以用于报告等目的,但是我们对开发人员如何使用它来解决上述问题更加感兴趣。 幸运的是,来自Teiid社区的人们,尤其是Ramesh Reddy ,为Teiid和Spring Boot创建了一些不错的扩展,以帮助消除解决该问题所伴随的样板。
介绍Teiid Spring Boot
再次重申一下问题:我们必须专注于服务的域模型,但是最初,支持域模型的数据仍将位于我们的整体/后端数据库中。 我们是否可以将整体数据模型的结构与我们所需的领域模型虚拟合并,并消除处理这些数据的样板代码?
通过Teiid Spring Boot ,我们可以专注于我们的Domain模型,就像使用任何模型一样,使用JPA @Entity注释对它们进行注释,并将它们映射到我们自己的新数据库,并虚拟地映射Monolith的数据库。 要开始使用teiid-spring-boot您需要导入以下依赖项:
< dependency >
< groupId >org.teiid.spring</ groupId >
< artifactId >teiid-spring-boot-starter</ artifactId >
< version >1.0.0-SNAPSHOT</ version > </ dependency > 这是一个入门项目,它将与Spring的自动配置魔术挂钩,并尝试建立我们的虚拟数据库(由Monolith的数据库和此服务拥有的实际物理数据库支持)。
现在,我们需要在Spring Boot中为每个后端定义数据源。 在此示例中,我使用了两个MySQL数据库,但这仅是一个细节。 我们不仅限于两个数据源相同,也不限于RDBM。 这是一个例子:
spring.datasource.legacyDS.url=jdbc:mysql: //localhost:3306/ticketmonster?useSSL=false spring.datasource.legacyDS.username=ticket spring.datasource.legacyDS.password=monster spring.datasource.legacyDS.driverClassName=com.mysql.jdbc.Driver spring.datasource.ordersDS.url=jdbc:mysql: //localhost:3306/orders?useSSL=false spring.datasource.ordersDS.username=ticket spring.datasource.ordersDS.password=monster spring.datasource.ordersDS.driverClassName=com.mysql.jdbc.Driver 让我们还配置teiid-spring-boot来扫描我们的域模型以查看它们到整体的虚拟映射。 在application.properties添加以下内容:
spring.teiid.model. package =org.ticketmonster.orders.domain Teiid Spring Boot允许我们将映射指定为@Entity定义上的注释。 这是一个示例( 请参阅github上的完整实现和完整的域对象集 ):
@SelectQuery ("SELECT s.id, s.description, s.name, s.numberOfRows AS number_of_rows, s.rowCapacity AS row_capacity, venue_id, v.name AS venue_name FROM legacyDS.Section s JOIN legacyDS.Venue v ON s.venue_id=v.id;") @Entity @Table (name = "section" , uniqueConstraints= @UniqueConstraint (columnNames={ "name" , "venue_id" })) public class Section implements Serializable {
@Id
@GeneratedValue (strategy = IDENTITY)
private Long id;
@NotEmpty
private String name;
@NotEmpty
private String description;
@NotNull
@Embedded
private VenueId venueId;
@Column (name = "number_of_rows" )
private int numberOfRows;
@Column (name = "row_capacity" )
private int rowCapacity; 在上面的示例中,我们使用@SelectQuery定义了旧数据源( legacyDS.* )和我们自己的域模型之间的映射。 注意,通常这些映射可能具有大量的JOIN等,以使数据以适合我们模型的正确形状; 最好在注释中编写一次JOIN,然后尝试在REST API中编写大量样板代码来处理该代码(不仅是查询,还包括实际映射到我们预期的域模型)。 在上述情况下,我们只是将整体数据库的数据映射到我们的域模型-但是如果我们需要在自己的数据库中合并该怎么办? 可以完成类似的操作( 请参见Ticket.java实体中的完整impl ):
@SelectQuery( "SELECT id, CAST(price AS double), number, rowNumber AS row_number, section_id, ticketCategory_id AS ticket_category_id, tickets_id AS booking_id FROM legacyDS.Ticket " + "UNION ALL SELECT id, price, number, row_number, section_id, ticket_category_id, booking_id FROM ordersDS.ticket" ) 请注意,在此示例中,我们将两个视图(来自Monolith数据库和我们自己的本地Orders数据库)与关键字UNION ALL合并。 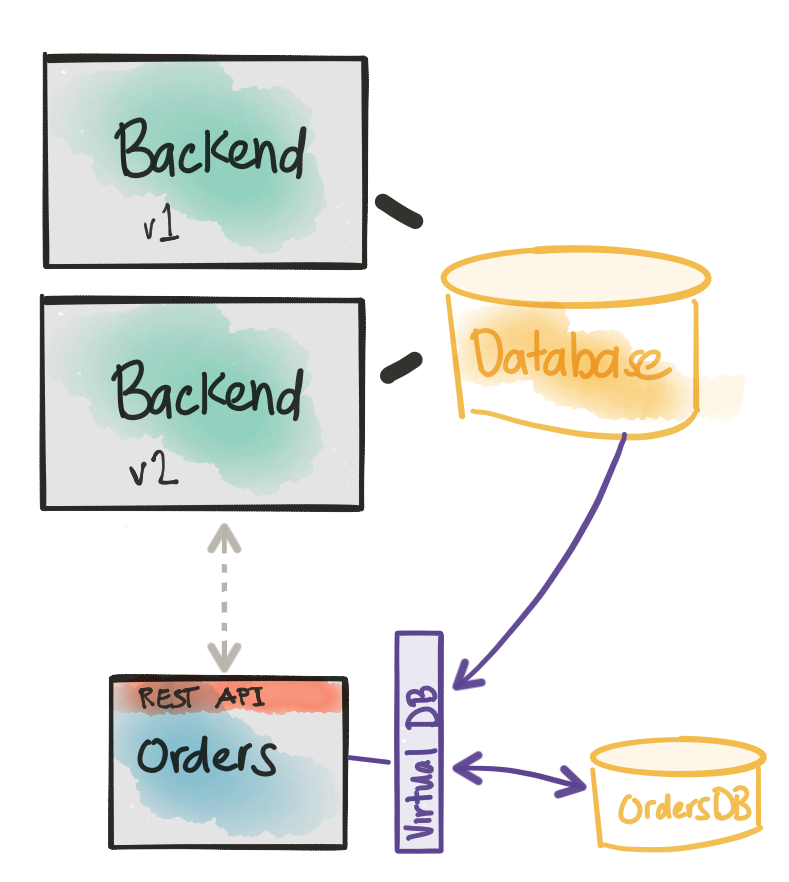
那更新或插入呢?
例如,我们的Orders服务应该存储订单/预订。 我们可以在Booking DDD实体/集合上添加@InsertQuery批注,如下所示:
@InsertQuery ( "FOR EACH ROW \n" +
"BEGIN ATOMIC \n" +
"INSERT INTO ordersDS.booking (id, performance_id, performance_name, cancellation_code, created_on, contact_email ) values (NEW.id, NEW.performance_id, NEW.performance_name, NEW.cancellation_code, NEW.created_on, NEW.contact_email);\n" +
"END" ) 请参阅文档,以获取我们可以使用的其余teiid-spring-boot批注 。
当我们保留一个新的Booking (JPA,Spring Data等)时,您可以在这里看到,虚拟数据库知道将其存储到我们自己的Orders数据库中。 如果您更喜欢使用Spring Data ,仍然可以使用teiid-spring-boot 。 这是来自teiid-spring-boot样本的示例 :
public interface CustomerRepository extends CrudRepository<Customer, Long> {
@Query ( "select c from Customer c where c.ssn = :ssn" )
Stream<Customer> findBySSNReturnStream( @Param ( "ssn" ) String ssn); } 如果我们有适当的teiid-spring-boot映射注释,则该spring-data存储库将正确理解我们的虚拟数据库层,并让我们按预期的方式处理域模型。
重申 这是微服务分解初始步骤的时间点解决方案; 并非最终解决方案。 我们仍在此处运行的示例中对此进行迭代。 我们打算减少手工制作贴图/平移等可能引起的混淆和麻烦。
如果您仍然想建立一个简单的API来对Monolith数据库进行低级数据访问(同样,这是一个临时解决方案),那么teiid-spring-boot仍然是您的朋友。 使用我们与teiid-spring-boot进行的odata集成,您可以非常快速地公开这种API,而无需代码。 请检出odata模块以获取更多信息(注意,我们仍在为该项目开发更多文档!)
在分解的这一点上,我们应该使用适当的API,域模型来实现我们的Orders服务的实现,连接到我们自己的数据库,并临时创建一个到我们的整体数据库的虚拟映射,以供我们在域模型中使用。 接下来,我们需要将其部署到生产中并进行暗启动。
开始将影子流量发送到新服务(暗启动)

重新考虑注意事项
- 将新的Orders服务引入代码路径会带来风险
- 我们需要以受控方式将流量发送到新服务
- 我们希望能够将流量引导到新服务以及旧代码路径
- 我们需要检测和监视新服务的影响
- 我们需要将交易标记为“综合”交易的方式,因此我们不会陷入麻烦的业务一致性问题
- 我们希望将此新功能部署到某些同类/组/用户
沿着下面的部分,我的这一部分,我们要修改的整体,使我们的新呼叫Orders服务。 如第一部分所述,我们将使用迈克尔·费瑟(Michael Feather)的书中的一些技术来包装/扩展整体中的现有逻辑,以调用新服务。 例如,对于createBookings实现,我们的整体看起来像这样:
@POST @Consumes (MediaType.APPLICATION_JSON) public Response createBooking(BookingRequest bookingRequest) {
try {
// identify the ticket price categories in this request
Set<Long> priceCategoryIds = bookingRequest.getUniquePriceCategoryIds();
// load the entities that make up this booking's relationships
Performance performance = getEntityManager().find(Performance. class , bookingRequest.getPerformance());
// As we can have a mix of ticket types in a booking, we need to load all of them that are relevant,
// id
Map<Long, TicketPrice> ticketPricesById = loadTicketPrices(priceCategoryIds);
// Now, start to create the booking from the posted data
// Set the simple stuff first!
Booking booking = new Booking();
booking.setContactEmail(bookingRequest.getEmail());
booking.setPerformance(performance);
booking.setCancellationCode( "abc" );
// Now, we iterate over each ticket that was requested, and organize them by section and category
// we want to allocate ticket requests that belong to the same section contiguously
Map<Section, Map<TicketCategory, TicketRequest>> ticketRequestsPerSection
= new TreeMap<Section, java.util.Map<TicketCategory, TicketRequest>>(SectionComparator.instance());
for (TicketRequest ticketRequest : bookingRequest.getTicketRequests()) {
final TicketPrice ticketPrice = ticketPricesById.get(ticketRequest.getTicketPrice());
if (!ticketRequestsPerSection.containsKey(ticketPrice.getSection())) {
ticketRequestsPerSection
.put(ticketPrice.getSection(), new HashMap<TicketCategory, TicketRequest>());
}
ticketRequestsPerSection.get(ticketPrice.getSection()).put(
ticketPricesById.get(ticketRequest.getTicketPrice()).getTicketCategory(), ticketRequest);
} 实际上,此代码还有很多其他内容–就像任何好的独石一样,还有很长很复杂的方法,可能很难理解正在发生的事情。 我们将其更改为以下内容:
@POST @Consumes (MediaType.APPLICATION_JSON) public Response createBooking(BookingRequest bookingRequest) {
Response response = null ;
if (ff.check( "orders-internal" )) {
response = createBookingInternal(bookingRequest);
}
if (ff.check( "orders-service" )) {
if (ff.check( "orders-internal" )) {
createSyntheticBookingOrdersService(bookingRequest);
}
else {
response = createBookingOrdersService(bookingRequest);
}
}
return response; } 此方法更小,更有条理并且更易于遵循。 但是,这是怎么回事? ff.check(...)这是什么?
这里要说明的关键一点是,我们正在尽可能少地改变整体。 理想情况下,我们有单元/组件/集成/系统测试,以帮助验证我们所做的更改不会破坏任何内容。 如果不是,则进行战术重构以能够进行测试。
作为我们所做的更改的一部分,我们不想更改现有的调用流程:我们将旧的实现移到名为createBookingInternal的方法上,并保持原样。 但是,我们还添加了一个新方法,该方法将负责调用Orders服务的新代码路径。 我们将使用一个功能标记库 ,它将允许我们做几件事:
- 完全运行时/配置控制,可用于订单的实施
- 禁用新功能
- 同时启用新功能和旧功能
- 完全切换到新功能
- 取消切换所有功能
我们使用的是Feature Flags 4 Java(FF4j) ,但其他语言还有其他选择,包括托管的SaaS提供程序,如Launch Darkly 。 当然,您可以编写自己的框架来执行此操作,但是这些现有项目提供了开箱即用的功能。 这与用于控制发布的Facebook(及其他)框架非常相似。 请返回有关部署和发行版之间区别的讨论。
要使用FF4j,我们将依赖项添加到pom.xml
< dependency >
< groupId >org.ff4j</ groupId >
< artifactId >ff4j-core</ artifactId >
< version >${ffj4.version}</ version > </ dependency > 然后,我们可以在ff4j.xml文件中声明功能(并对其进行分组,等等。 有关更复杂的功能/分组功能的更多详细信息 ,请参见ff4j文档 :
< features >
< feature uid = "orders-internal" enable = "true" description = "Continue with legacy orders implementation" />
< feature uid = "orders-service" enable = "false" description = "Call new orders microservice" /> </ features > 然后,我们可以实例化一个FF4j对象,并使用它来测试代码中是否启用了功能:
FF4j ff4j = new FF4j( "ff4j.xml" ); if (ff4j.check( "special-feature" )){
doSpecialFeature(); } 开箱即用的实现使用ff4j.xml配置文件来指定功能。 然后可以在运行时等切换功能(见下文),但是在继续之前,我想指出,功能及其各自的状态(启用/禁用)应由任何类型的非持久存储支持。琐碎的部署。 请查看ff4j网站上的FeatureStore文档 。
我们还需要一种在运行时配置/影响功能状态的方法。 FF4j具有一个Web控制台 ,您可以部署它来查看/影响应用程序中功能的状态: 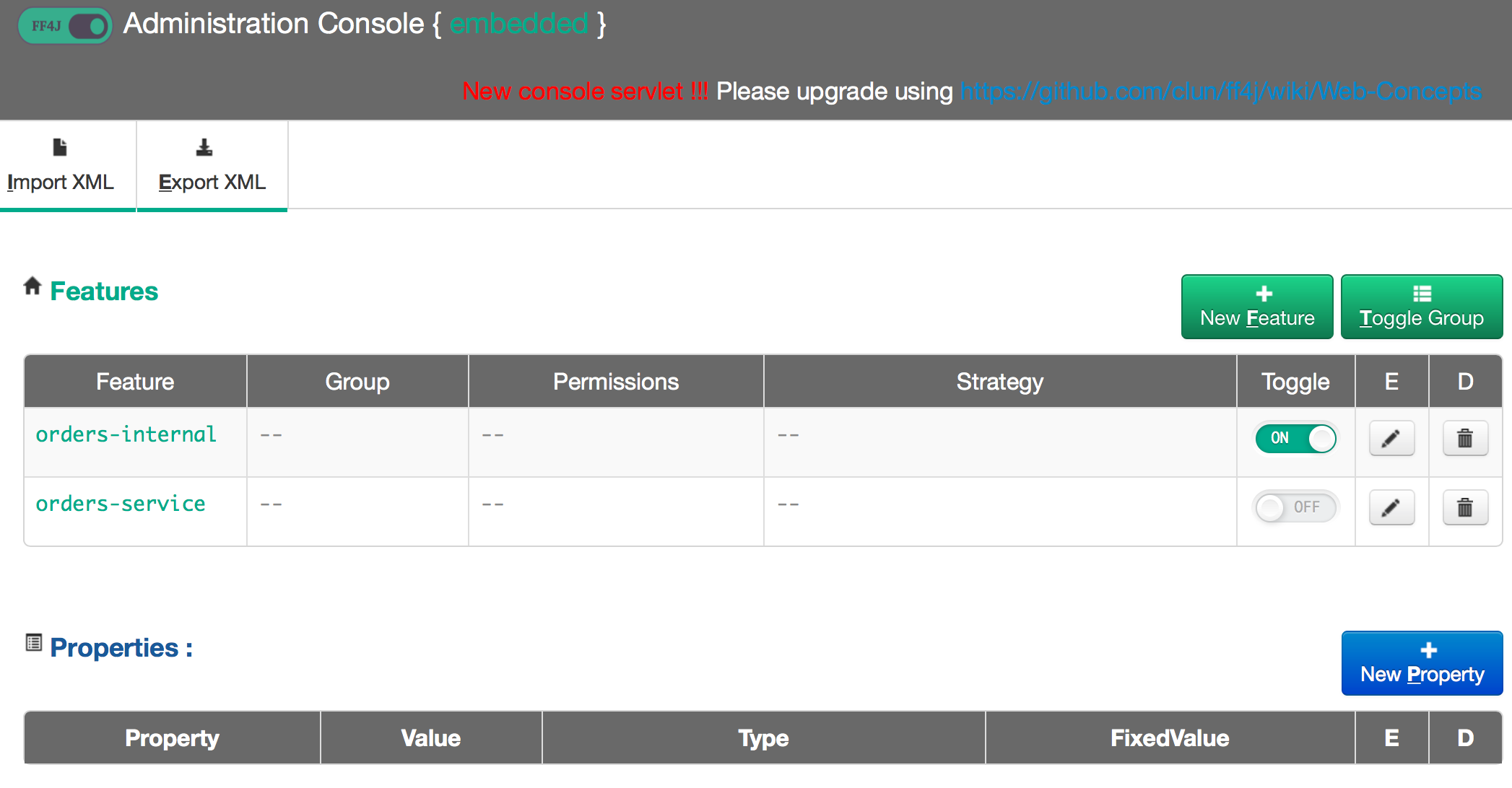
默认情况下,我们将仅在启用旧版功能的情况下进行部署。 也就是说,默认情况下,我们不应在代码执行路径和服务行为上看到任何变化。 然后,我们可以取消此部署,并使用功能标记来同时启用旧代码路径和调用我们的新Orders服务的新路径。 对于某些服务,我们可能只需要启用第二个代码路径就无需再多加注意了。 但是对于某些会改变状态的事物,我们需要一种方法来表明这是“测试”或“综合”交易。 在我们的案例中,当我们同时启用了旧代码路径和新代码路径时,我们会将发送到Orders服务的消息标记为“合成”。 这向Orders服务提供了一个提示,即我们应该将其作为常规请求进行处理,然后丢弃或回滚结果。 这对于了解新代码路径在做什么并为我们提供与旧路径进行比较的机会(即比较结果,副作用,时间/延迟影响等)非常有价值。 如果仅启用新的代码路径并禁用旧的代码路径,我们将发送实时请求(不包含综合指示符/标志)。
指定服务合同
在这一点上,我们可能应该编写代码以将整体连接到新的Orders服务,以进行预订和订单流处理。 现在,这是个好时机,当巨石表达其在调用Orders服务时可能关心的合同或数据方面的任何要求时。 当然, Orders服务是一项独立的自治服务,并承诺提供一定的功能/ SLA / SLO等,但是当我们开始构建分布式系统时,重要的是要了解有关服务交互的假设并使之明确。
通常,我们从提供者的角度考虑合同。 在这种情况下,我们从消费者的角度看问题。 消费者实际上从服务提供商那里使用或看重什么? 我们是否可以将此反馈提供给提供商,以便他们可以了解服务的实际用途以及在更改服务时应注意的事项; 即,我们不想破坏现有的兼容性。 我们将利用以消费者为导向的合同的思想来帮助使假设变得明确。 我们将使用一个名为Pact的项目 ,该项目是一种语言不可知的文档格式,用于指定服务之间的合同(重点是消费者驱动的合同)。 我相信Pact是由澳大利亚科技公司DiUS的人们创办的 。 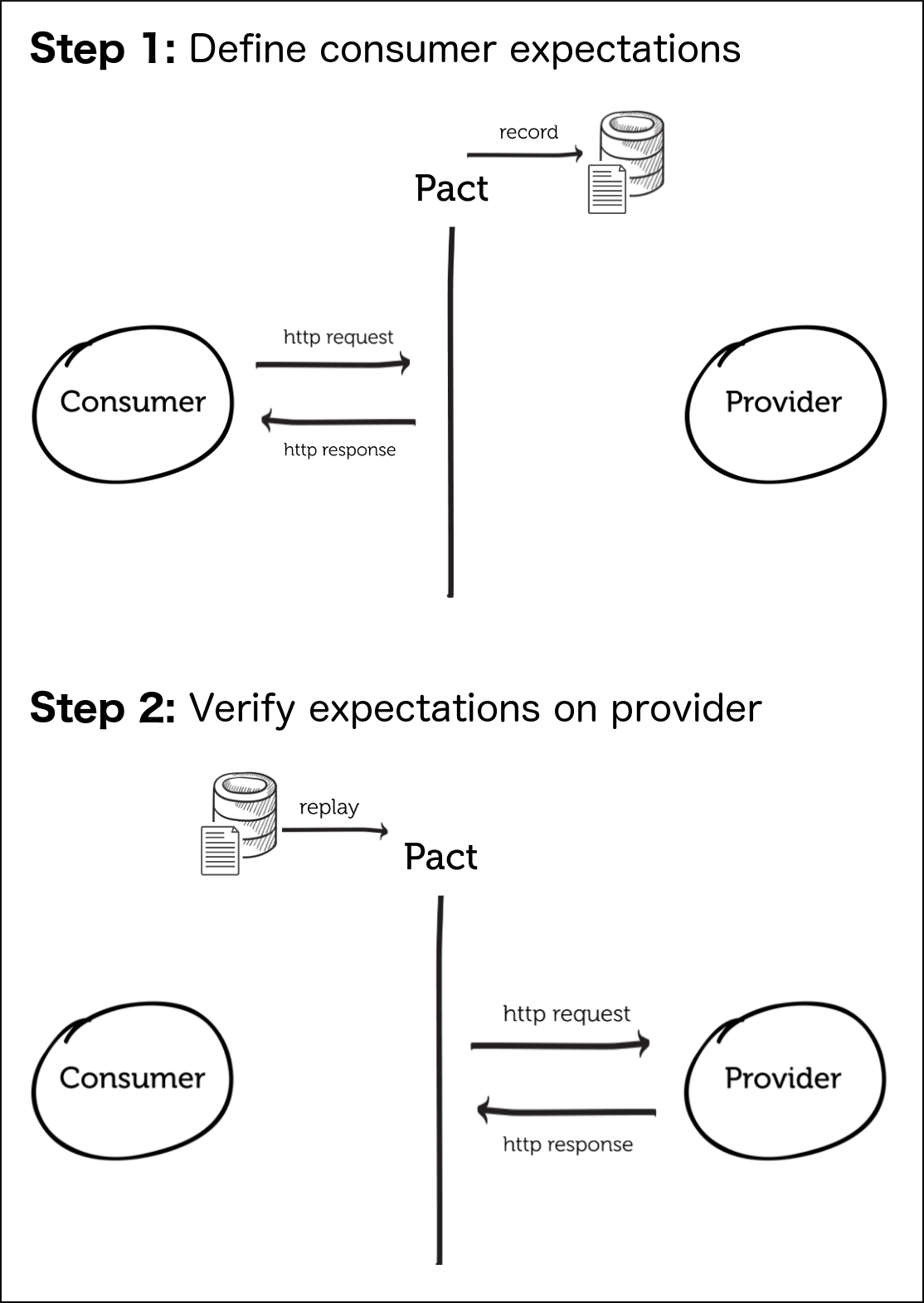
上图来自Pact文档
让我们看一下来自后端服务的示例。 我们将为我们的backend-v2应用程序创建一个消费者合同规则,该规则概述了服务提供商( Orders服务)的期望。 当我们向/rest/bookings发出POST HTTP请求时,我们可以声明一些期望。
@Pact (provider= "orders_service" , consumer= "test_synthetic_order" ) public RequestResponsePact createFragment(PactDslWithProvider builder) {
RequestResponsePact pact = builder
.given( "available shows" )
.uponReceiving( "booking request" )
.path( "/rest/bookings" )
.matchHeader( "Content-Type" , "application/json" )
.method( "POST" )
.body(bookingRequestBody())
.willRespondWith()
.body(syntheticBookingResponseBody())
.status( 200 )
.toPact();
return pact; } 当我们调用提供程序服务并传递特定的正文时,我们期望HTTP 200和与我们的合同匹配的响应。 让我们来看看。 首先,这是我们指定预订请求正文的方式:
private DslPart bookingRequestBody(){
PactDslJsonBody body = new PactDslJsonBody();
body
.integerType( "performance" , 1 )
.booleanType( "synthetic" , true )
.stringType( "email" , "foo@bar.com" )
.minArrayLike( "ticketRequests" , 1 )
.integerType( "ticketPrice" , 1 )
.integerType( "quantity" )
.closeObject()
.closeArray();
return body; } Pact-jvm允许我们使用pact-jvm-junit模块连接到我们最喜欢的测试框架(在本例中为JUnit)。 如果我们使用Arquillian (应该是这样)进行组件和集成测试,则可以使用Arquillian Algeron将 Pact纳入我们的Arquillian测试中。 Alegeron通过使其易于在Arquillian测试中使用而扩展了Pact,并且还添加了您必须自行构建的功能(这对于CI / CD管道至关重要):自动将合同发布至合同经纪人并提取合同的功能测试时从经纪人处获得。 我强烈建议您看看Arquillian和Arquillian Algeron对Java应用程序进行消费者合同测试。
我们可以创建PactDslJsonBody片段,并仅使用“通配符”或“在此字段中传递任何内容”语义。 例如, body.integerType("attr_name", default_value)使我们指定“将存在一个名为X的属性,具有默认值”。如果我们省略默认值参数,则该值实际上可以是任何值。 在此代码段中,我们仅指定请求的结构。 请注意,我们指定了一个名为synthetic的属性,并且对于此属性为true请求,我们期望其响应具有特定的结构。
这是我们声明我们的消费者合同(响应)的地方:
private DslPart syntheticBookingResponseBody() {
PactDslJsonBody body = new PactDslJsonBody();
body
.booleanType( "synthetic" , true );
return body; } 这是一个非常简单的示例:对于此测试,我们期望响应具有一个synthetic: true属性synthetic: true 。 这很重要,因为在发送综合预订时,我们要确保Orders服务确认确实将其视为综合请求。 如果运行此测试并成功完成,我们将在目标构建目录中获得该Pact合同(即,在我的情况下,它进入./target/pacts
{
"provider" : {
"name" : "orders_service"
},
"consumer" : {
"name" : "test_synthetic_order"
},
"interactions" : [
{
"description" : "booking request" ,
"request" : {
"method" : "POST" ,
"path" : "/rest/bookings" ,
"headers" : {
"Content-Type" : "application/json"
},
"body" : {
"synthetic" : true ,
"performance" : 1 ,
"ticketRequests" : [
{
"quantity" : 100 ,
"ticketPrice" : 1
}
],
"email" : "foo@bar.com"
},
"matchingRules" : {
"header" : {
"Content-Type" : {
"matchers" : [
{
"match" : "regex" ,
"regex" : "application/json"
}
],
"combine" : "AND"
}
},
"body" : {
"$.performance" : {
"matchers" : [
{
"match" : "integer"
}
],
"combine" : "AND"
},
"$.synthetic" : {
"matchers" : [
{
"match" : "type"
}
],
"combine" : "AND"
},
"$.email" : {
"matchers" : [
{
"match" : "type"
}
],
"combine" : "AND"
},
"$.ticketRequests" : {
"matchers" : [
{
"match" : "type" ,
"min" : 1
}
],
"combine" : "AND"
},
"$.ticketRequests[*].ticketPrice" : {
"matchers" : [
{
"match" : "integer"
}
],
"combine" : "AND"
},
"$.ticketRequests[*].quantity" : {
"matchers" : [
{
"match" : "integer"
}
],
"combine" : "AND"
}
},
"path" : {
}
},
"generators" : {
"body" : {
"$.ticketRequests[*].quantity" : {
"type" : "RandomInt" ,
"min" : 0 ,
"max" : 2147483647
}
}
}
},
"response" : {
"status" : 200 ,
"headers" : {
"Content-Type" : "application/json; charset=UTF-8"
},
"body" : {
"synthetic" : true
},
"matchingRules" : {
"body" : {
"$.synthetic" : {
"matchers" : [
{
"match" : "type"
}
],
"combine" : "AND"
}
}
}
},
"providerStates" : [
{
"name" : "available shows"
}
]
}
],
"metadata" : {
"pact-specification" : {
"version" : "3.0.0"
},
"pact-jvm" : {
"version" : ""
}
} } 在这里,我们可以将合同放入Git , 合同经纪人或共享文件系统中 。 在提供方( Orders服务)上,我们可以创建一个组件测试,以验证提供方服务确实满足了消费者合同中的期望。 请注意,您可能有许多消费者合同,我们可以对所有合同进行测试(尤其是如果我们对提供者服务进行了更改–我们可以进行影响测试,以查看我们服务的下游用户可能受到的影响)。
@RunWith (PactRunner. class ) @Provider ( "orders_service" ) @PactFolder ( "pact/" ) public class ConsumerContractTest {
private static ConfigurableApplicationContext applicationContext;
@TestTarget
public final Target target = new HttpTarget( 8080 );
@BeforeClass
public static void startSpring() {
applicationContext = SpringApplication.run(Application. class );
}
@State ( "available shows" )
public void testDefaultState() {
System.out.println( "hi" );
} } 请注意,在这个简单的示例中,我们从./pacts下的文件系统上的文件夹中提取合同
一旦我们完成了以消费者为导向的合同测试,我们就可以更轻松地对我们的服务进行更改。 有关此示例的工作示例,请参见backend-v2服务的示例以及提供程序Orders服务 。
金丝雀/滚动发布到新服务
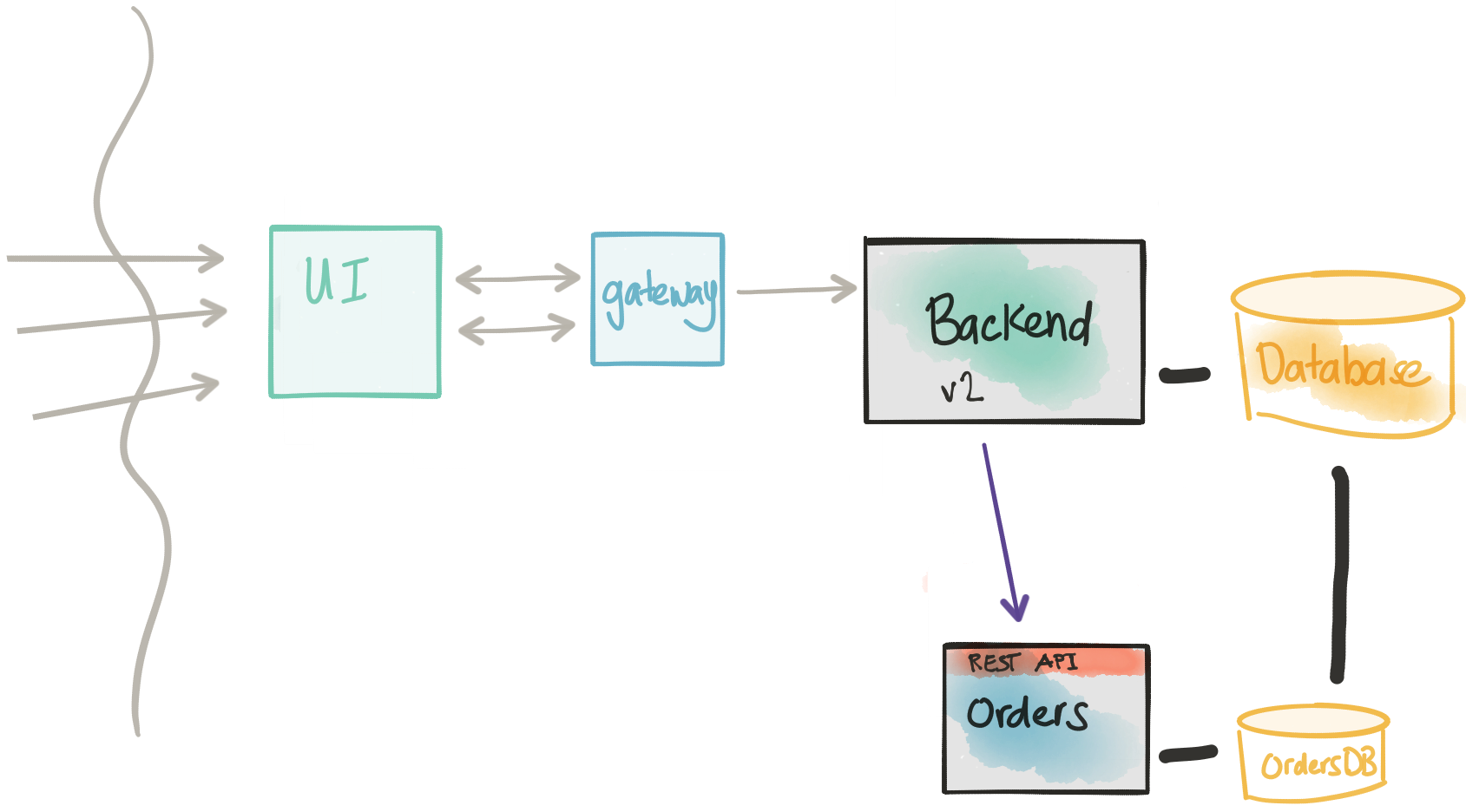
重新考虑注意事项
- 我们可以识别同类群组并将实时交易流量发送到我们的新微服务
- 我们仍然需要直接连接到整体数据库,因为在一段时间内交易仍将同时到达两个代码路径
- 将所有流量移至微服务后,我们应该可以淘汰旧功能
- 请注意,一旦我们将实时流量发送到新服务,就必须考虑到回滚到旧代码路径这一事实会带来一些困难和协调
此方案的另一个重要部分是,我们需要一种方法,通过具有功能标记的新部署仅发送少量流量。 我们可以使用Istio精确控制要调用的后端。 例如,我们已经部署了backend-v1 ,该版本已完全发布并承担了生产负荷。 当我们部署具有控制新代码路径的功能标志的backend-v2 ,我们可以使用Istio对其进行释放,类似于上一篇文章中的操作 。 我们只能发送1%的流量,然后慢慢增加(5%,25%等)并观察效果。 我们还可以切换功能,以便同时启用旧代码路径和新代码路径。 这是一项非常强大的技术,它使我们能够显着降低更改和向微服务架构迁移的风险。 这是一个Istio路由规则示例,它可以为我们完成此任务:
apiVersion: config.istio.io/v1alpha2 kind: RouteRule metadata:
name: backend-v2 spec:
destination:
name: backend
precedence: 20
route:
- labels:
version: v1
weight: 99
- labels:
version: v2
weight: 1 需要注意的一些事情:在这一点上,新的Orders服务通过合成交易启用了旧路径和新代码路径。 到目前为止,所描述的金丝雀将适用于1%的流量,而不管它们是谁。 首先释放给内部用户或一小部分外部用户,然后通过实时Orders服务(即非合成流量)实际发送给他们,这可能会很有用。 通过基于用户的外科手术路由和将用户分组的FF4j配置的组合,我们可以启用到新Orders服务的完整代码路径(实时流量,非综合事务性工作负载)。 但是,关键是一旦将用户定向到Orders的实时代码路径,就应该始终以这种方式将其发送给以后的调用。 这是因为一旦使用新服务下了订单,就不会在整体数据库中看到它。 该用户对该订单的所有查询/更新现在都应该始终通过新服务。
在这一点上,我们可以观察流量模式/服务行为,并确定增加释放Kong。 最终,我们获得了前往新服务的100%流量。
如何处理数据不在整体中的情况? 您可能不选择执行任何操作–新的Orders服务现在是Orders / Booking逻辑+数据的合法所有者。 如果您觉得这些新订单的整体组件之间需要某种集成,则可以选择使用新的Orders详细信息发布来自新Orders服务的事件。 然后,巨石可以捕获这些事件并将其存储在巨石数据库中。 其他服务也可以针对这些事件进行侦听并对它们做出反应。 事件发布机制将很有用。
同样,此博客文章过长! 剩下两个部分“离线数据ETL /迁移”和“断开/解耦数据存储”。 我想对这些部分进行适当的处理,所以我必须在这里结束并进行第四部分! 第五部分将是显示所有这些工作的网络广播/视频/演示。
翻译自: https://www.javacodegeeks.com/2017/10/low-risk-monolith-microservice-evolution-part-iii.html

















 8772
8772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









