





适用于将推文存储在Couchbase中的AWS Serverless Lambda计划的事件说明了如何使用AWS Serverless Lambda将推文存储在Couchbase中。 现在,此Lambda函数已经运行了几天,并已从@realDonaldTrump收集了269条推文。 这个博客的灵感来自Twitter上的SQL:使用N1QL轻松进行分析,将展示如何使用N1QL来分析这些推文。 
N1QL是Couchbase中的一种类似SQL的查询语言,可用于JSON文档。 N1QL和SQL差异提供了N1QL和SQL之间的差异。 让我们使用N1QL从@realDonaldTrump的推文中揭示一些有趣的信息。
非常感谢N1QL小组的Sitaram协助破解了查询。
多少条推文
第一个查询是找出数据库中有多少条推文。 查询非常简单:
查询:
SELECT COUNT(*) tweet_count
FROM twitter; 如您所见,语法与SQL非常相似。 SELECT , COUNT和FROM子句是您已经从SQL语法熟悉的内容。 tweet_count是为返回结果定义的别名。 twitter是存储所有JSON文档的存储桶。
结果:
[
{
"tweet_count": 269
}
]结果也是JSON文档。
推文样本JSON文档
为了在JSON文档上编写查询,您需要了解文档的结构。 下一个查询将为您提供。
查询:
SELECT *
FROM twitter
LIMIT 1; 这里介绍的新子句是LIMIT 。 这允许限制在SELECT结果集中返回的对象的数量。
结果:
[
{
"twitter": {
"accessLevel": "0",
"contributors": [],
"createdAt": "1480828438000",
"currentUserRetweetId": "-1",
"displayTextRangeEnd": "-1",
"displayTextRangeStart": "-1",
"favoriteCount": "116356",
"favorited": false,
"geoLocation": null,
"hashtagEntities": [],
"id": "805278955150471168",
"inReplyToScreenName": null,
"inReplyToStatusId": "-1",
"inReplyToUserId": "-1",
"lang": "en",
"mediaEntities": [],
"place": null,
"possiblySensitive": false,
"quotedStatus": null,
"quotedStatusId": "-1",
"rateLimitStatus": null,
"retweet": false,
"retweetCount": "28330",
"retweeted": false,
"retweetedByMe": false,
"retweetedStatus": null,
"scopes": null,
"source": "<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>",
"symbolEntities": [],
"text": "Just tried watching Saturday Night Live - unwatchable! Totally biased, not funny and the Baldwin impersonation just can't get any worse. Sad",
"truncated": false,
"urlentities": [],
"user": {
"accessLevel": "0",
"biggerProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_bigger.jpg",
"biggerProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_bigger.jpg",
"contributorsEnabled": false,
"createdAt": "1237383998000",
"defaultProfile": false,
"defaultProfileImage": false,
"description": "President-elect of the United States",
"descriptionURLEntities": [],
"email": null,
"favouritesCount": "46",
"followRequestSent": false,
"followersCount": "19294404",
"friendsCount": "42",
"geoEnabled": true,
"id": "25073877",
"lang": "en",
"listedCount": "52499",
"location": "New York, NY",
"miniProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_mini.jpg",
"miniProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_mini.jpg",
"name": "Donald J. Trump",
"originalProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2.jpg",
"originalProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2.jpg",
"profileBackgroundColor": "6D5C18",
"profileBackgroundImageURL": "http://pbs.twimg.com/profile_background_images/530021613/trump_scotland__43_of_70_cc.jpg",
"profileBackgroundImageUrlHttps": "https://pbs.twimg.com/profile_background_images/530021613/trump_scotland__43_of_70_cc.jpg",
"profileBackgroundTiled": true,
"profileBannerIPadRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/ipad_retina",
"profileBannerIPadURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/ipad",
"profileBannerMobileRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/mobile_retina",
"profileBannerMobileURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/mobile",
"profileBannerRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/web_retina",
"profileBannerURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/web",
"profileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_normal.jpg",
"profileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_normal.jpg",
"profileLinkColor": "0D5B73",
"profileSidebarBorderColor": "BDDCAD",
"profileSidebarFillColor": "C5CEC0",
"profileTextColor": "333333",
"profileUseBackgroundImage": true,
"protected": false,
"rateLimitStatus": null,
"screenName": "realDonaldTrump",
"showAllInlineMedia": false,
"status": null,
"statusesCount": "34269",
"timeZone": "Eastern Time (US & Canada)",
"translator": false,
"url": "https://t.co/mZB2hymxC9",
"urlentity": {
"displayURL": "https://t.co/mZB2hymxC9",
"end": "23",
"expandedURL": "https://t.co/mZB2hymxC9",
"start": "0",
"text": "https://t.co/mZB2hymxC9",
"url": "https://t.co/mZB2hymxC9"
},
"utcOffset": "-18000",
"verified": true,
"withheldInCountries": null
},
"userMentionEntities": [],
"withheldInCountries": null
}
}
]前5个推特日
在基本查询结束之后,让我们现在看一些有趣的数据。
@realDonaldTrump发推文的前5天和发推数的时间是多少?
查询:
SELECT SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 0, 10) tweet_date,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 0, 10)
ORDER BY COUNT(1) DESC
LIMIT 5; 通常的GROUP BY和ORDER BY SQL子句执行相同的功能。
N1QL函数将函数应用于值。 createdAt字段返回一个数字作为字符串。 TO_NUM函数将String转换为数字。 MILLIS_TO_STR函数将字符串转换为日期。 最后, SUBSTR函数提取日期的相关部分。
结果:
[
{
"tweet_count": 13,
"tweet_date": "2017-01-17"
},
{
"tweet_count": 12,
"tweet_date": "2017-01-06"
},
{
"tweet_count": 11,
"tweet_date": "2016-12-04"
},
{
"tweet_count": 10,
"tweet_date": "2017-01-03"
},
{
"tweet_count": 10,
"tweet_date": "2017-01-04"
}
]2017年1月17日是发布最多的日子。 现在,此结果当然仅限于存储在数据库中的JSON文档中的数据。
是否有人拥有更全面的@realDonaldTrump tweets数据库?
鸣叫频率
好的,我们的数据库显示一天最多可发送13条推文。我如何确定@realDonaldTrump发了多少次发了若干次?
查询:
SELECT a.tweet_count, count(1) days FROM (
SELECT SUBSTR(millis_to_str(to_num(createdAt)), 0, 10) tweet_date,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(millis_to_str(to_num(createdAt)), 0, 10)
) a
GROUP BY a.tweet_count
ORDER BY a.tweet_count DESC;使用N1QL嵌套查询很容易实现。
结果:
[
{
"days": 1,
"tweet_count": 13
},
{
"days": 1,
"tweet_count": 12
},
{
"days": 1,
"tweet_count": 11
},
{
"days": 2,
"tweet_count": 10
},
{
"days": 1,
"tweet_count": 9
},
{
"days": 7,
"tweet_count": 8
},
{
"days": 3,
"tweet_count": 7
},
{
"days": 7,
"tweet_count": 6
},
{
"days": 5,
"tweet_count": 5
},
{
"days": 5,
"tweet_count": 4
},
{
"days": 11,
"tweet_count": 3
},
{
"days": 3,
"tweet_count": 2
},
{
"days": 1,
"tweet_count": 1
}
] 在47天内,只有一天只有一条推文。 tweet_count的总和表明没有一天没有tweet
一天中最常见的鸣叫时间
@realDonaldTrump已知在凌晨3点发推文 。 让我们看一下他最常发的鸣叫时间。
查询:
SELECT SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 11, 2) tweet_hour,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 11, 2)
ORDER BY tweet_count DESC
LIMIT 5;结果:
[
{
"tweet_count": 39,
"tweet_hour": "13"
},
{
"tweet_count": 27,
"tweet_hour": "12"
},
{
"tweet_count": 26,
"tweet_hour": "11"
},
{
"tweet_count": 20,
"tweet_hour": "14"
},
{
"tweet_count": 15,
"tweet_hour": "00"
}
] 现在看来,有争议的推文是凌晨3点发布的。 但是东部时间下午1点有39条鸣叫,可能是在午餐后和吃甜点时 
一周中的普通日
让我们找出一周中最常见的鸣叫时间。
查询:
SELECT DATE_PART_STR(MILLIS_TO_STR(TO_NUM(createdAt)), "day_of_week") day_of_week,
COUNT(1) tweet_count
FROM twitter
GROUP BY DATE_PART_STR(MILLIS_TO_STR(TO_NUM(createdAt)), "day_of_week")
ORDER BY tweet_count DESC; DATE_PART_STR是一个新函数,它返回日期中日期的一部分。 进一步的day_of_week属性用于获取星期几。
结果:
[
{
"day_of_week": 2,
"tweet_count": 49
},
{
"day_of_week": 3,
"tweet_count": 40
},
{
"day_of_week": 0,
"tweet_count": 40
},
{
"day_of_week": 5,
"tweet_count": 38
},
{
"day_of_week": 4,
"tweet_count": 36
},
{
"day_of_week": 6,
"tweet_count": 33
},
{
"day_of_week": 1,
"tweet_count": 33
}
]似乎星期二是最普通的鸣叫日。 然后是周日和周三处于同一水平。 演出趋向于在周末接近。
这是一个显示相同趋势的漂亮图表:
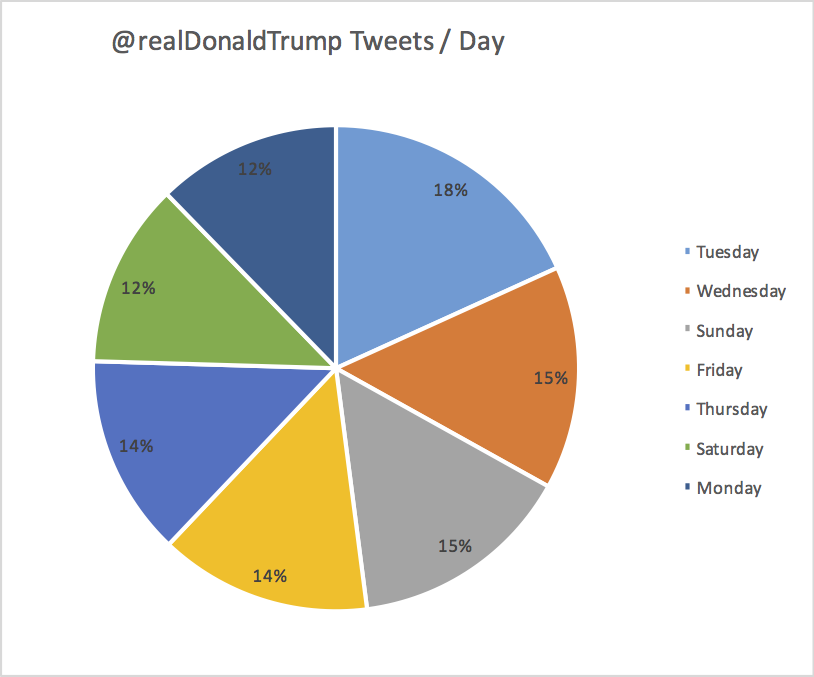
#22417应该允许以英语报告工作日部分。
推文中的前5条提及
查询:
SELECT COUNT(1) user_count, ue.screenName
FROM twitter
UNNEST userMentionEntities ue
GROUP by ue.screenName
ORDER by user_count DESC
LIMIT 5; userMentionEntities是JSON文档中的嵌套数组。 UNNEST概念上执行嵌套数组与其父对象的连接。 每个产生的连接对象成为查询的输入。
结果:
[
{
"screenName": "realDonaldTrump",
"user_count": 11
},
{
"screenName": "FoxNews",
"user_count": 7
},
{
"screenName": "CNN",
"user_count": 6
},
{
"screenName": "NBCNews",
"user_count": 5
},
{
"screenName": "DanScavino",
"user_count": 5
}
]不用说,他在推文中最多提到自己的名字! 还有他最喜欢的两个电视台福克斯新闻和CNN 。
带有RT的前5条推文
Lambda Function每3小时唤醒一次,并获取最新的tweet。 因此,数据库是推文和相关信息(例如RT和收藏夹)的快照。 因此,根据推文的存档时间,RT和收藏夹可能不是准确的表示形式。 但是,鉴于此信息,让我们看一下大多数RT的推文。
查询:
SELECT retweetCount, text
FROM twitter
ORDER BY retweetCount
LIMIT 5;非常直接的查询。
结果:
[
{
"retweetCount": "10110",
"text": "the American people. I have no doubt that we will, together, MAKE AMERICA GREAT AGAIN!"
},
{
"retweetCount": "10140",
"text": "Thank you to all of the men and women who protect & serve our communities 24/7/365! \n#LawEnforcementAppreciationDay… https://t.co/aqUbDipSgv"
},
{
"retweetCount": "10370",
"text": "We had a great News Conference at Trump Tower today. A couple of FAKE NEWS organizations were there but the people truly get what's going on"
},
{
"retweetCount": "10414",
"text": "these companies are able to move between all 50 states, with no tax or tariff being charged. Please be forewarned prior to making a very ..."
},
{
"retweetCount": "10416",
"text": "Somebody hacked the DNC but why did they not have \"hacking defense\" like the RNC has and why have they not responded to the terrible......"
}
]原始版vs RTs
有多少条推文被撰写与转发?
查询:
SELECT retweet, count(1) count
FROM twitter
GROUP BY retweet;结果:
[
{
"count": 253,
"retweet": false
},
{
"count": 15,
"retweet": true
}
]大多数推文都是原创的,只有少数RT。
推文中最常见的单词
查询:
SELECT COUNT(1) count, word
FROM twitter
UNNEST SPLIT(text) word
GROUP BY word
ORDER BY count DESC; 此查询使用的SPLIT函数
结果:
[
{
"count": 189,
"word": "the"
},
{
"count": 151,
"word": "to"
},
{
"count": 115,
"word": "and"
},
. . .
{
"count": 1,
"word": "presented...Trump's"
},
{
"count": 1,
"word": "jobs."
},
{
"count": 1,
"word": "Doing"
}
]推文中“媒体”,“假冒”和“美国”一词的出现频率
查询:
SELECT COUNT(1) count, LOWER(w) word
FROM twitter
UNNEST SPLIT(text) w
WHERE LOWER(w) IN [ "media", "fake", "america"]
GROUP by LOWER(w)
ORDER BY count DESC; LOWER函数用于比较大小写无关的单词。
结果:
[
{
"count": 12,
"word": "media"
},
{
"count": 9,
"word": "fake"
},
{
"count": 8,
"word": "america"
}
]Lambda函数将继续在数据库中存储推文。
自己尝试这些查询?
- 启动Couchbase服务器
- 按照将数据还原到Couchbase中所述使用存档twitter-backups-2017-01-20-06-07-49.tar
- 使用查询工作台激发查询
N1QL参考
翻译自: https://www.javacodegeeks.com/2017/01/analyze-donald-trump-tweets-couchbase-n1ql.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









