





根据Gartner的预测 ,到2020年,四分之一的互联汽车将构成物联网的主要组成部分。 互联车辆预计每小时可产生25GB数据,可对其进行分析以提供实时监控和应用程序,并将带来新的出行和车辆使用概念。 当前,利用大数据发挥卓越优势的10个主要领域之一是改善城市。 例如,对GPS汽车数据的分析可以使城市根据实时交通信息优化交通流量。
优步正在使用大数据来完善其流程 ,从计算优步的定价到寻找汽车的最佳定位以最大化利润。 在本系列博客文章中,我们将使用公共Uber行程数据来讨论构建用于分析和监视汽车GPS数据的实时示例。 使用实时数据的机器学习通常分为两个阶段:
- 数据发现 :第一阶段涉及对历史数据进行分析以构建机器学习模型。
- 使用模型进行分析 :第二阶段在现场活动的生产中使用模型。 (请注意,Spark确实提供了一些流机器学习算法,但是您仍然经常需要对历史数据进行分析。)
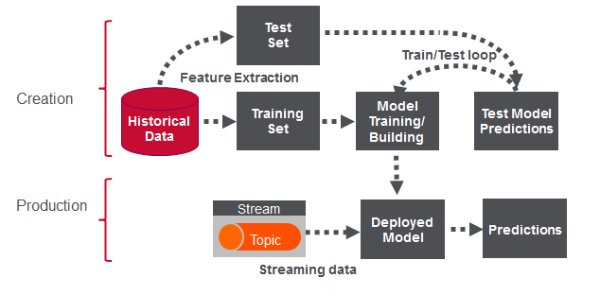
在第一篇文章中,我将帮助您开始使用Apache Spark的机器学习K-means算法根据位置对Uber数据进行聚类。
聚类
Google新闻使用一种称为聚类的技术,根据标题和内容将新闻文章分为不同的类别。 聚类算法发现数据集合中出现的分组。
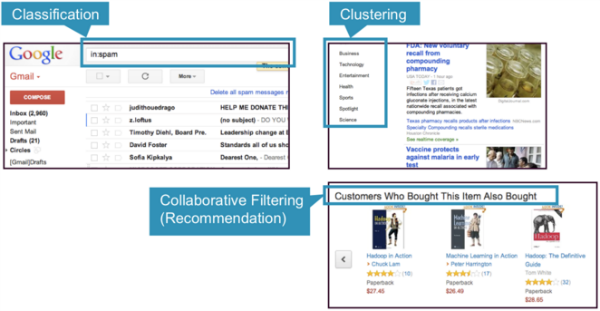
在聚类中,一种算法通过分析输入示例之间的相似性将对象分为类别。 群集用途的示例包括:
- 搜索结果分组
- 客户分组
- 异常检测
- 文字分类

聚类使用无监督算法,该算法没有预先的输出(标记的数据)。
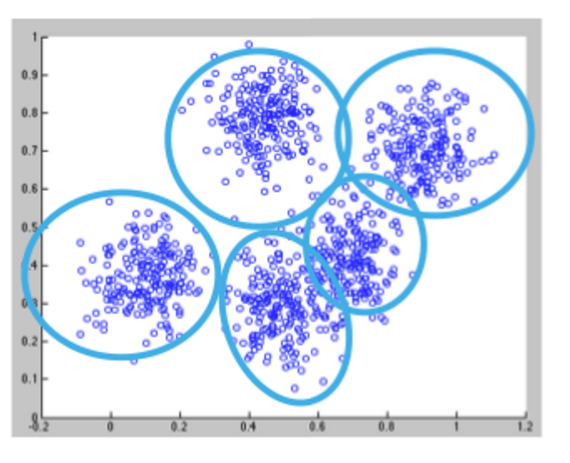
K均值是最常用的聚类算法之一,它将数据点聚集成预定数量的聚类(k)。 使用K均值算法的聚类首先将所有坐标初始化为k个质心。 每次使用算法时,都会基于某个距离度量(通常是欧几里得距离)将每个点分配给它最近的质心。 然后将质心更新为该遍中分配给它的所有点的“中心”。 重复此过程,直到中心的变化最小。
用例数据集示例
示例数据集是Uber出行数据,FiveThirtyEight从纽约市出租车和豪华轿车委员会获得 。 在此示例中,我们将基于经度和纬度发现Uber数据的群集,然后我们将按日期/时间分析群集中心。 数据集具有以下架构:
- 日期/时间 :Uber取车的日期和时间
- 纬度 :优步皮卡的纬度
- 朗 :优步皮卡的经度
- 基地 :隶属于优步皮卡的TLC基地公司
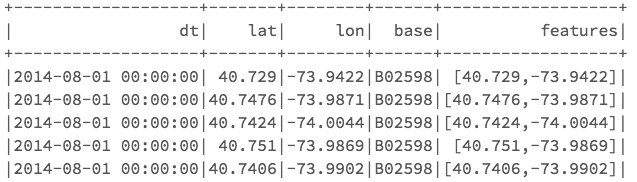
数据记录为CSV格式。 示例行如下所示:
2014-08-01 00:00:00,40.729,-73.9422,B02598
示例用例代码
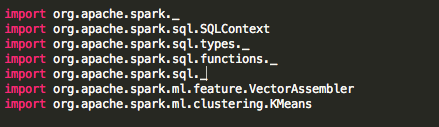
首先,我们导入Spark ML K-means和SQL所需的包。
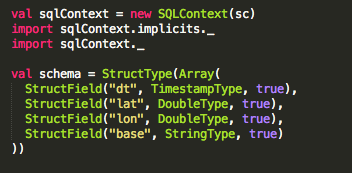
我们使用Spark Structype指定架构(请注意,如果您使用的是笔记本,则不必创建SQLContext)。
接下来,我们将数据从CSV文件加载到Spark DataFrame中。
使用Spark 1.6和–packages com.databricks:spark-csv_2.10:1.5.0,我们从CSV 文件数据源创建DataFrame并应用架构。

或使用Spark 2.0,我们可以指定要加载到DataFrame中的数据源和架构,如下所示 :
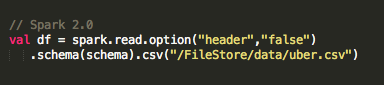
请注意,对于Spark 2.0,在将数据加载到DataFrame中时指定架构将提供比架构推断更好的性能 。
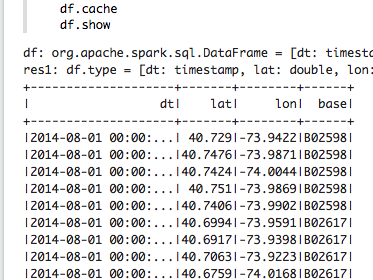
在Zeppelin笔记本中运行后,DataFrame printSchema()以树形格式将模式打印到控制台,如下所示:

DataFrame show()显示前20行:
定义要素数组
为了让机器学习算法使用特征,对特征进行转换并将其放入特征向量,这些向量是代表每个特征值的数字向量。 在下面,使用VectorAssembler来转换和返回带有向量列中所有功能列的新DataFrame。


df2.show的输出:
接下来,我们创建一个KMeans对象,设置参数以定义聚类数和最大迭代数以确定聚类,然后将模型拟合到输入数据。


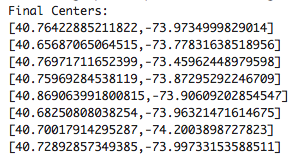
模型clusterCenters的输出:
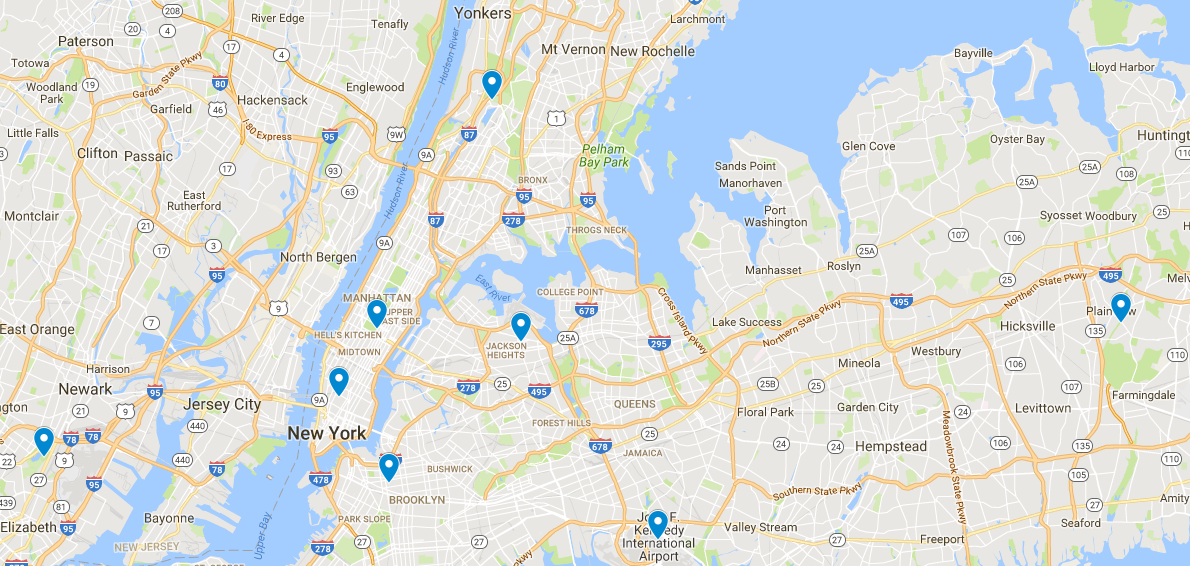
下面,聚类中心显示在Google地图上:
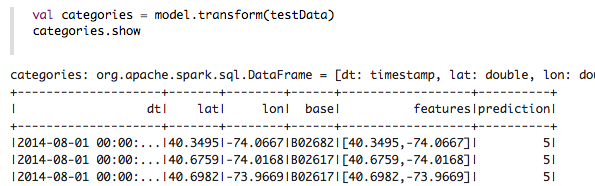
接下来,我们使用该模型获取测试数据的聚类,以进一步分析聚类。

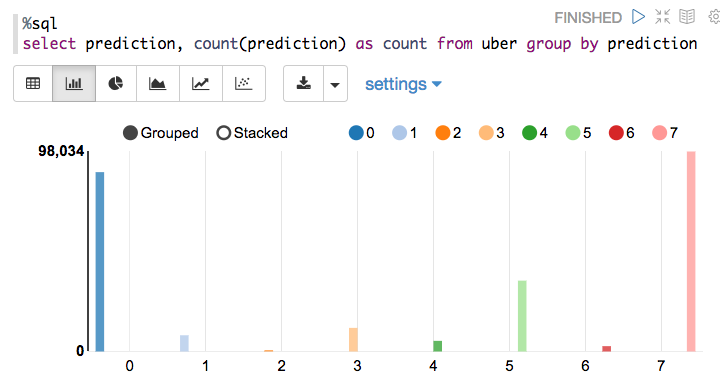
现在我们可以问一些问题,例如“一天中的哪个小时以及哪个集群的接机次数最多?”
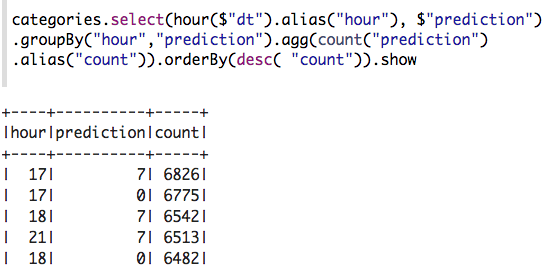
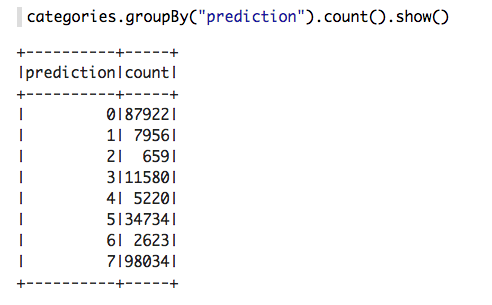
每个群集中发生了多少次接机?
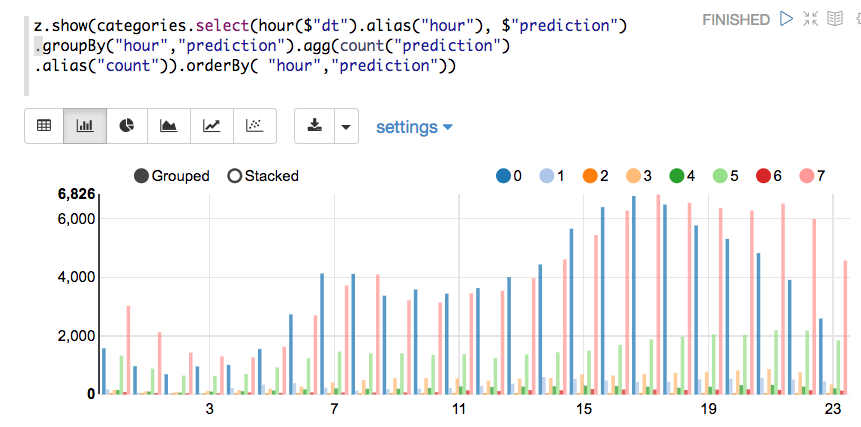
使用Zeppelin笔记本,我们还可以在条形图或图形中显示查询结果。 x轴下方是小时,y轴下方是计数,而颜色是不同的簇。
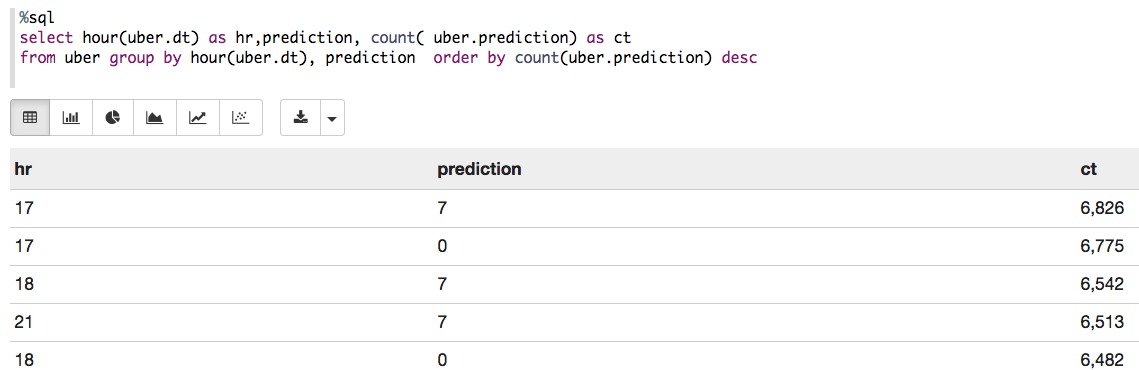
您可以使用给定名称将DataFrame注册为临时表,例如:df.registerTempTable(“ uber”),然后使用sqlContext提供的SQL方法运行SQL语句。 下面以Zeppelin笔记本为例。
可以将模型持久保存到磁盘,如下所示,以便以后使用(例如,使用Spark Streaming)。

软件
本教程将在Spark 1.6.1上运行
- 您可以从此处下载代码,数据和自述文件以运行此示例: https : //github.com/caroljmcdonald/spark-ml-kmeans-uber
- 这篇文章中的示例可以在Spark外壳或Zeppelin笔记本中运行。 如使用Mapr Sandbox上的Spark入门所述 ,使用密码为userid user01的用户登录到MapR Sandbox。 按照自述文件中的说明,使用scp将示例数据文件复制到沙箱主目录/ user / user01。
- 要作为独立应用程序运行,请按照自述文件中的说明,使用scp将jar文件复制到集群,然后使用以下命令运行:
- $ spark-submit – com.sparkml.uber.ClusterUber类–master local [2] – com.databricks:spark-csv_2.10:1.5.0 spark-kmeans-1.0.jar包
- 要在Spark Shell中运行,请使用以下命令启动Spark Shell:$ spark-shell –master local [1]
- 然后从ClusterUber.scala文件中复制/粘贴代码
在此博客文章中,我们介绍了如何开始使用Apache Spark的机器学习K-means进行集群。 在下一篇博客文章中,我们将研究在Spark Streaming应用程序中使用该模型。
想了解更多?
- 免费的按需培训:Apache Spark,带有Kafka API的MapR流,HBase
- MapR和Spark
- Apache Spark ML概述
- Apache Spark机器学习教程
- 使用Apache Spark和事件流进行实时信用卡欺诈检测
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









