





Ivan Linhares是Chaordic的工程经理。 他已经担任首席工程师和软件开发人员超过15年。 他热衷于发展优秀的团队并解决具有挑战性的技术问题。 在Chaordic,他领导数据平台团队扩展其针对电子商务领域的个性化解决方案。
Chaordic是巴西基于大数据的电子商务个性化解决方案的领导者。 该国最大的在线零售商 ,例如Saraiva,沃尔玛和Centauro,使用我们的解决方案向其用户提出个性化的购物建议。 Chaordic的数据平台提供了一个公共数据层和在多个产品之间共享的服务。
三年前, Chaordic经历了指数级增长。 从一开始,我们的业务就以收集尽可能多的相关信息为基础。 当核心数据库解决方案MySQL努力保持增长速度时,我已经加入公司。 到那时,还不清楚哪种解决方案将在被炒作的NoSQL领域占据领先地位。 尽管今天我们使用混合数据架构,但Cassandra是使Chaordic持续增长的关键技术。
阶段1:寻找最佳位置
一些现代的数据存储解决方案倾向于易于使用,其他的则提供具有MapReduce或Search的集成环境,而另一些则在性能和数据一致性方面进行了投资(请参阅CAP定理 )。 因此,找到与我们的用例匹配的技术的最佳位置是第一步。
当我们考虑当时面临的挑战时,许多事情变得更加清晰:
- 垂直扩展数据库已经达到了顶峰:当时我们拥有最大的AWS实例,这对于我们的主从部署来说还不够。
- 我们希望避免手动分片数据和避免集群数据重新平衡的复杂性。
- 使我们的能力增长和增加一倍应该是直接而快捷的。
- 数据存储区应该非常适合我们的写密集型模式。
- 应该避免甚至计划的停机时间,并采用具有挑战性的SLA。
- 还应避免专有数据存储和提供商特定的技术。
- 模式更改需要减轻痛苦:长期的维护操作(例如ALTER TABLE)已经限制了我们。
当我们考虑这些因素并在当时作为其他参与者的基准时,Cassandra的选择对于我们的情况而言是很自然的。 线性可伸缩性,写优化,易于管理,可调整的一致性和不断增长的社区之间的平衡产生了影响。 到那时Cassandra的发展势头(包括Netflix的早期采用 )以及我们尝试新事物的自然本能也很重要。
阶段2:边做边学
我们认为最合乎逻辑的方法是从MySQL 逐步迁移 。 在此过程中存在许多不确定性,不同的建模方式以及需要学习的知识。 我们首先建立一个6个节点的单区域Cassandra集群,然后首先迁移性能最敏感的实体。
我们的策略包括一种使迁移向前发展的方法,以及在出现问题时进行回滚的方法。 实践证明,这非常有效,因为我们仍在学习在Cassandra中表示数据的最佳方法。 我们的平台已经使用REST API设计,因此内部客户端不会受到迁移的影响。 我们的分层体系结构只要求为每个实体实现一个新的Cassandra数据访问对象,并在某些情况下调整业务逻辑。
了解如何在Cassandra中高效建模是一个循序渐进的过程。 常见错误之一是导致群集中出现负载热点。 Cassandra基于一致的密钥哈希来平衡数据分布 。 因此,通过对分区键(即最大客户的所有产品的单个键)进行错误选择,负载将集中在同一副本组中,并且这些特定节点将饱和。 在选择Cassandra中的主键时,应考虑平衡数据分布和列集群的分区。 另一方面,集群键可以非常有效地检索行,还可以用于对数据进行索引和排序。
Cassandra众所周知的二级索引限制是我们很难学到的。 如果您阅读这些文档,其好处可能会引起您的注意。 它们在低基数数据下可以很好地工作,但是在许多情况下并非如此。 当我们迁移一个主要实体以利用该优势时,按客户创建产品列表时,性能下降,我们不得不回滚。 解决方案是为每个所需查询创建一个新表(或一个实体化视图 ),并在应用程序层中管理更新。 好消息是Cassandra 3.0将支持此内置版本 。
我们犯的另一个错误是,在没有表模式的情况下,使用同一张表存储不同的实体。 在0.8倍上有一个神话建议,避免使用过多的表,因此我们重用了一些表以不同的存储格式( 特别是宽而窄的分区)存储行。 这最终使页面缓存和其他存储优化陷入混乱。 到目前为止,在CQL中对数据进行建模已经可以避免这种不良做法,但是在CQL之前,这一点还不清楚。 建议是在同一张表中混合使用不同的实体或读/写模式通常不是一个好主意。
阶段3:运营优化
如果您的集群大小正在Swift变化,那么掌握Cassandra操作非常重要: 自动化节点替换和添加过程将节省大量时间。 我们从Puppet开始,然后转移到Chef来自动执行节点配置。 当集群足够大时,还必须自动执行滚动重启以进行配置调整和版本升级 。
了解卡桑德拉(Cassandra)的特性,例如维修 , 暗示的移交和清理,也是保持数据一致性的关键。 例如,一旦我们在集群中获得僵尸数据,是因为当节点宕机时间超过gc_grace_seconds并最终重新出现数据时,删除操作(参见逻辑删除 )不会被复制。 修复操作可以解决该问题。
随着我们开发新产品的成长,我们必须决定是使用整体式群集还是部署新的群集。 我们认为后者是实现实验和模块化的更好选择。 然后,我们使用支持虚拟节点的较新版本的Cassandra(当时为1.2)来滚动集群。 我们从旋转基于磁盘的节点开始,但很快就迁移到了新的SSD支持的实例 。 最后一步,即使使用更少的机器来补偿成本,也可以将写入延迟降低到50%,将读取延迟提高80%! 更好的是,它使我们可以从堆栈中删除Memcached,从而降低了成本和复杂性,尤其是在多区域部署中(请参阅此处的基准测试 )。
Cassandra性能的另一个关键方面是选择正确的压缩策略 。 由于Cassandra对磁盘的写入是不可变的(SSTables),因此数据更新会累积在新的SSTables文件中。 这样可以提供出色的写入性能,但是读取未顺序存储在磁盘上的数据意味着要进行多次磁盘寻道并降低性能。 为了克服这个问题,压缩过程合并并合并数据,逐出墓碑并将SSTables合并到新的合并文件中。 我们从默认的SizeTieredCompactionStrategy (STCS)开始,它非常适合于写入密集型工作负载。 对于读取更频繁且数据经常更新的情况 ,我们迁移到LeveledCompactionStrategy (LCS)。 在许多情况下,这有助于更快地删除逻辑删除,并减少每次读取的SSTables数量,从而改善了读取延迟(请参见下面的内容)。
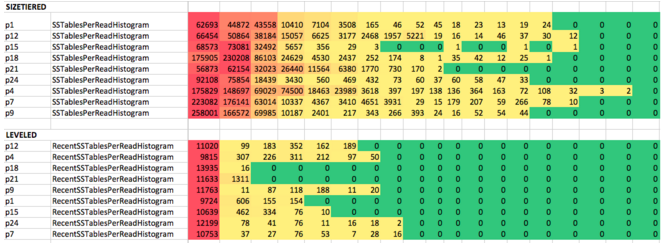
节点每次读取的SSTables(大小分层与分层压缩策略)
配置压缩还对存储空间产生巨大影响。 对于存档或不经常读取的数据,Deflate压缩可为我们节省60%至70%的磁盘空间。 对于某些用例( 请参阅此处 ),由于减少了IO时间,因此压缩甚至可以提高读取性能。
对于监视而言 ,使用哪种工具(Librato,OpsCenter,Grafana等)并不重要,只要您熟悉并完成理解和观察关键指标的作业即可。 Cassandra的构建基于JMX的广泛工具。 根据我们的经验,坚持使用较少的基于时间的指标,并在仪表板上一致地组织您可以轻松发现异常,这比拥有所有指标更为重要。 一系列关键指标将包括更通用的指标(延迟,每秒事务数)以及系统指标(负载,网络I / O,磁盘,内存),JVM指标(堆使用率,gc时间)以及更深层次的指标。卡桑德拉的细节。 对于压缩,请查找PendingTasks和TotalCompactionsCompleted; 读/写超时和丢弃的突变通常会预见到容量问题; Exceptions.count可以发现一般错误,TotalHints和RepairedBackground将有助于诊断不一致之处。
保持步伐
得益于活跃的社区和Datastax对频繁发布的承诺,即使是少量的Cassandra 升级也可能会因性能改进,功能和配置调整而感到惊讶。 因此,我们建议将群集升级到最新的稳定版本。 选择最佳稳定版本进行升级的经验法则是观看最新的DataStax Enterprise的Cassandra版本。
这篇文章概述了Chaordic的数据平台团队如何采用Cassandra并支持公司的发展。 克服采用非关系型数据库的最初障碍可能并不容易,但是,要获得一个健壮且可扩展的解决方案,这是值得的投资。
*特别感谢DataStax工程师 Paulo Motta 和Chaordic工程师 Flavio Santos 对本文的撰写和审阅。
翻译自: https://www.javacodegeeks.com/2016/01/transitioning-mysql-cassandra-chaordic.html















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









