





您是否曾经想过如何在SQL中表达如下“感觉”的谓词:
WHERE Var1 OR Var2 IN (1, 2, 3) / u / CyBerg90在reddit上具有 。 这个想法是创建一个谓词,只要Var1和Var2值都Var2 1、2或3,就产生真。
规范的解决方案
规范的解决方案显然是将其全部写为:
WHERE Var1 = 1 OR Var1 = 2 OR Var1 = 3
OR Var2 = 1 OR Var2 = 2 OR Var2 = 3但是,有很多重复。
使用IN谓词
大多数读者只会将两个IN谓词联系起来:
WHERE Var1 IN (1, 2, 3)
OR Var2 IN (1, 2, 3)或聪明的人可能会这样颠倒谓词,以形成等价物:
WHERE 1 IN (Var1, Var2)
OR 2 IN (Var1, Var2)
OR 3 IN (Var1, Var2)使用EXISTS和JOIN的更好的解决方案
所有先前的解决方案在某种程度上都需要语法/表达式重复。 尽管这可能不会对性能产生重大影响,但在表达长度方面,它肯定会爆炸。 更好的解决方案(从该角度来看)利用EXISTS谓词,构造当Var1和Var2得出1、2或3时非空的临时集合。
下面是EXISTS与JOIN
WHERE EXISTS (
SELECT 1
FROM (VALUES (Var1), (Var2)) t1(v)
JOIN (VALUES (1), (2), (3)) t2(v)
ON t1.v = t2.v
)此解决方案构造了两个表,每个表都有一个单一值,并将它们联接到该值上:
+------+ +------+
| t1.v | | t2.v |
+------+ +------+
| Var1 | | 1 |
| Var2 | | 2 |
+------+ | 3 |
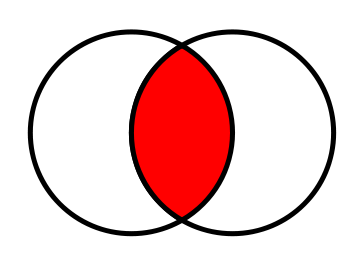
+------+ 查看维恩图 ,很容易看出JOIN将如何只产生两个集合中同时存在的来自t1和t2那些值:
使用EXISTS和INTERSECT的最佳解决方案
但是,人们在阅读JOIN时可能不会想到一个设定的交集。 那么,为什么不通过INTERSECT使用实际的交集呢? 我认为以下是最好的解决方案:
WHERE EXISTS (
SELECT v
FROM (VALUES (Var1), (Var2)) t1(v)
INTERSECT
SELECT v
FROM (VALUES (1), (2), (3)) t2(v)
) 观察一下,SQL语句的长度如何随O(m + n) (或简单地为O(N) ,其中m, n = number of values in each set ,而使用IN的原始解决方案随O(m * n) (或简称为O(N 2 ) )。
流行的RDBMS中的INTERSECT支持
在SQL标准以及jOOQ支持的以下任何RDBMS中, INTERSECT均得到广泛支持:
- BR
- DB2
- 德比
- H2
- 汉娜
- 数据库
- Informix
- 英格利斯
- 甲骨文
- PostgreSQL的
- SQLite的
- SQL服务器
- Sybase ASE
- Sybase SQL Anywhere
实际上,以下数据库也支持较少使用的INTERSECT ALL ,它不会从结果包中删除重复的值(另请参见UNION与UNION ALL )。
- BR
- PostgreSQL的
相交愉快!
翻译自: https://www.javacodegeeks.com/2015/08/intersect-the-underestimated-two-way-in-predicate.html















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









