





在这篇文章中,我将提到RDD论文,“ 弹性分布式数据集:内存中群集计算的容错抽象” 。 如果您没有阅读有关Spark的文章,我强烈建议您从这里阅读: Spark:带有工作集的集群计算 。
RDD抽象
RDD是一种分布式内存抽象,它利用了应用程序的性能,因为它以容错的方式适用于迭代算法和交互式数据挖掘工具。 其他集群计算框架(例如MapReduce和Dryad)缺乏利用分布式内存的抽象概念。 因此,这使得它们对于需要重用中间结果的操作效率低下。 数据重用在许多迭代式机器学习和图形算法中很常见,即K表示聚类,逻辑回归和PageRank。
RDD是只读的,不可变的,分区的记录集合。 RDD提供基于粗粒度转换(例如,映射,过滤和联接)的接口,以提高容错效率,并在Spark中实现。 要使用Spark,开发人员需要编写驱动程序,并将其连接到一组工作程序。 驱动程序定义一个或多个RDD,并对其调用操作,并且驱动程序上的Spark代码跟踪RDD的沿袭。
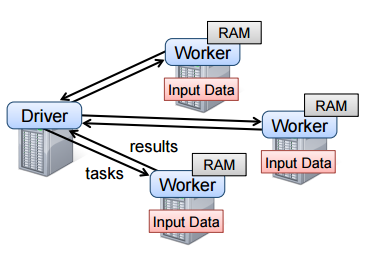
RDD模型的优点
由于RDD是分布式内存抽象,因此可以将其与DSM(分布式共享内存)系统进行比较。 RDD具有足够的信息,它是如何从其他数据集中获得的,因此程序无法引用在故障后无法重建的RDD。 RDD不具有DSM系统所具有的类似检查点的机制,并且由于故障的原因,RDD丢失的分区仅需要重新计算即可在不同节点上并行执行。
运行时基于批量操作中的数据局部性来调度任务,以提高性能。 同样,当RAM上没有足够的内存时,它们可以存储在磁盘上,这将提供与当前数据并行系统类似的性能。
不适合RDD的应用
RDD最适合将相同操作应用于数据集所有元素的批处理应用程序。 RDD将不太适合对共享状态进行异步细粒度更新的应用程序,即用于Web应用程序的增量Web搜寻器或存储系统。
评价
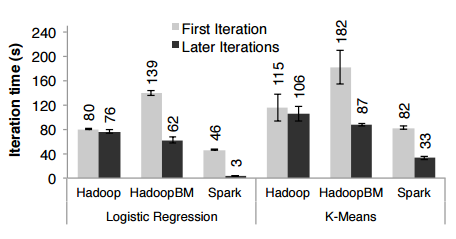
迭代机器学习应用程序的性能比较结果:
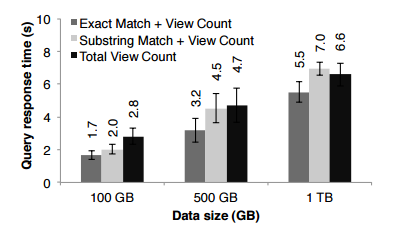
交互式查询响应时间比较:
结论
RDD是集群计算中一种高效,通用且容错的数据共享抽象,适用于迭代式机器学习算法。 RDD提供了一个基于粗粒度转换的API ,可以使用lienage恢复数据。 在迭代应用程序中,Spark中实现的RDD的性能要比Hadoop高出20倍,并且可以交互地用于查询大量数据。
翻译自: https://www.javacodegeeks.com/2015/06/resilient-distributed-datasets-rdds.html















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









