





总览
Apache Hive是Hadoop生态系统的组成部分。 Hive可以定义为类似于软件的数据仓库,该软件可促进对HDFS(Hadoop分布式文件系统)的查询和大数据管理。 必须记住,Hive不是数据仓库软件,它提供了某种机制来管理分布式环境中的数据并使用类似于SQL的语言称为HiveQL或HIVE查询语言进行查询。 Hive脚本可以定义为捆绑在一起的一组Hive命令,以减少执行时间。 在本文中,我将讨论Hive脚本及其执行。
介绍
HDFS或Hadoop分布式文件系统提供了可扩展且容错的数据存储。 HIVE提供了一种简单的SQL之类的查询语言– HIVE QL。 HIVE QL允许传统的地图精简开发人员插入其自定义的映射程序和精简程序,以进行更复杂的分析。
HIVE的局限性
HIVE查询的延迟通常很高,这是因为作业提交和计划中的大量开销。 Hive不提供实时查询和行级别更新。 最好用于日志分析。
HIVE数据单位
配置单元数据分为以下四类:
- 数据库:这由命名空间组成,这些命名空间将表和其他数据单元分开,以避免名称冲突。
- 表格:这些是具有通用架构的同类数据单元。 一个常见的示例可能是页面视图表,其中每一行可以包含以下列:
- 用户身份
本示例列出了个人用户使用网站或应用程序的记录。
- 分区:分区确定数据的存储方式。 每个表可以具有一个或多个分区。 分区还可以帮助用户有效地识别满足特定选择条件的行。
- 存储桶或群集:每个分区中的数据可以进一步细分为存储桶或群集或块。 上面示例中的数据可以基于用户ID或ip地址或页面url列进行聚类。
HIVE数据类型
根据需要,HIVE支持原始和复杂的数据类型,如下所述:
- 基本类型:
- 整合者
HIVE脚本
与任何其他脚本语言相似,HIVE脚本用于集体执行一组HIVE命令。 HIVE脚本帮助我们减少了手动编写和执行单个命令所花费的时间和精力。 HIVE 0.10.0或更高版本的HIVE中支持HIVE脚本。 要编写和执行HIVE脚本,我们需要为Hadoop CDH4安装Cloudera发行版。
编写HIVE脚本
首先,在您的Cloudera CDH4发行版中打开一个终端,并提供以下命令来创建Hive脚本。
gedit sample.sql与任何其他查询语言类似, Hive脚本文件应以.sql扩展名保存。 这样可以执行命令。 现在,在“编辑”模式下打开文件,并编写将使用此脚本执行的Hive命令。 在此示例脚本中,我们将依次执行以下任务(创建,描述并将数据加载到表中,然后从表中检索数据)。
在Hive中创建表“产品”
create table product_dtl ( product_id: int, product-name: string, product_price: float, product_category: string) rows format delimited fields terminated by ‘,’ ;这里{product_id,product-name,product_price,product_category}是“ product_dtl”表中各列的名称。 “以','终止的字段 ”表示输入文件中的列由','分隔符分隔。 您还可以根据需要使用其他定界符。 例如,我们可以考虑输入文件中用新行('\ n')字符分隔的记录。
描述表
describe product_dtl;将数据加载到表中
现在,让我们检查数据加载部分。 创建一个输入文件,其中包含需要插入表中的记录。
sudo gedit input.txt现在,让我们在输入文本文件中创建一些记录,如下图所示:
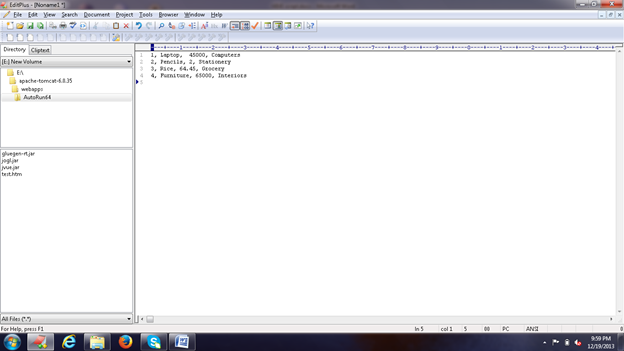
图1:输入文件。
因此,我们的输入文件将如下所示:
1, Laptop, 45000, Computers
2, Pencils, 2, Stationery
3, Rice, 64.45, Grocery
4, Furniture, 65000, Interiors要从该文件加载数据,我们需要执行以下命令:
load data local inpath ‘/home/cloudera/input.txt’ into table product_dtl;检索数据:要检索数据,我们使用简单的select语句,如下所示:
select * from product_dtl;上面的命令将执行并从表“ product”中获取所有记录。
该脚本将如下图所示:
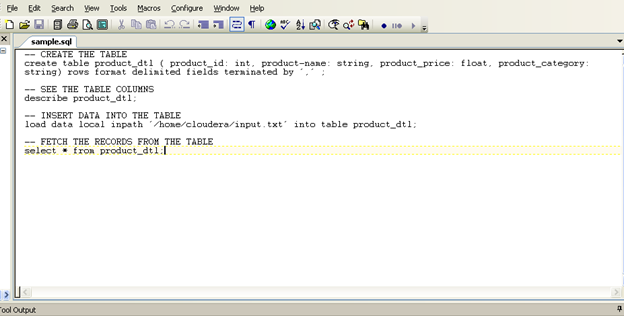
图2:示例SQL文件
保存此sample.sql文件并运行以下命令:
hive –f /home/cloudera/sample.sql执行脚本时,请提及脚本location的整个路径 。 这里的示例脚本位于当前目录中 ; 我没有提供脚本的完整路径。
下图显示所有命令已成功执行。
以下输出显示该表已创建,样本输入文件中的数据已存储在数据库中。
| 1个 | 笔记本电脑 | 45000 | 电脑 |
| 2 | 铅笔 | 2 | 文具 |
| 3 | 白饭 | 64.45 | 杂货 |
| 4 | 家具类 | 65000 |
摘要
在结束讨论之前,我们必须注意以下几点
- Apache HIVE是HDFS不可或缺的一部分
- HIVE是一种类似SQL的查询语言
- HIVE脚本易于理解和实施
- Hive支持原始数据类型和复杂数据类型。
翻译自: https://www.javacodegeeks.com/2015/07/how-to-create-your-first-hive-script.html















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









